在使用Kettle的集群排序中 Carte的设定——(基于Windows)
本片文章主要是关于使用Kettle的UI界面:
Spoon来实现基于集群的对数据库中的数据表数据进行排序的试验。
以及在实验过程中所要开启的Carte服务的一些配置文件的设置,
还有基于Windows cmd 的相关Carte命令。
文章主要分为六个部分:
1.介绍carte
2.carte相关配置文件的设定
3.carte服务的开启命令
4.在kettle的图形界面中对集群进行相关的设定
5.使用kettle集群模式对相关的数据进行排序
6.有关于集群调用子服务器的java源代码调用实现
1.介绍carte
carte是由kettle所提供的web server的程序,
carte也被叫做子服务器(slave) 在kettle调用集群(cluster)来进行分布式分发、处理任务的时候,
可以开启多个carte服务进程 来进行分发ETL(master)任务和接收,运行,提交ETL任务(slave)。
就像是《pentaho kettle solutions》中对Carte的定义:
"Carte a lightweight server process allows for remote monitoring and enables the transformation clustering capabilities ".
"Carte是一个轻量级的服务器进程,可以远程监控和开启转换集群的能力".
2.carte相关配置文件的设定
与hadoop的结点设置类似,本实验将要实现的是基于一台主机,
开启四个carte服务,其中一台为Master另外三台为Slave,
来实现在Kettle的Spoon中对数据库中数据表读取后 以集群的方式来执行排序的过程。
开启的carte服务所显示的命令窗口都是一样的,但是究竟哪一个是主服务哪些又是子服务呢?
对于集群中的主服务器还是子服务器的设定,
我们仍旧引用《pentaho kettle solutions》书中的一段话进行说明(因为很权威的):
"A cluster schema consists of one master server that is being used as a controller
for the cluster , and a number of non-master slave servers. In short, we refer to
the controlling Carte server as the master and the other Carte servers as slaves"
LZ在不考虑到句式主 谓 宾 定 状 补的条件下,对上述介绍的理解是这样的。
"一个集群实体是由 一个 用来主控整个集群的主节点
和多个 不是主节点
(也就是主节点除外,即配置文件中 属性<master>N</master>对应的值置为N的对应结点)
的子服务器所构成的。
简而言之,我们把开启的主控Carte 服务器 叫做 主节点 而其他的Carte 服务器叫做 从结点"。
关于Carte的服务器是主还是从是由相关的配置文件:carte-config.xml中的
属性<master></master>中是"Y"还是"N" 所设定的,
其实这个和hadoop通过相关的XML配置文件来设定是主节点还是从节点是很神似的。
配置文件吧,其实根据计算机不同,以及计算机中的环境变量的不同而千差万别。
主要说一下LZ关于配置文件的设定过程吧,
若想让Carte程序可以成功运行的话,首先就应该设定它的配置文件,
配置文件所在的路径,如下图所示:

(carte-config.xml 截图)
在这里LZ在正常进行配置的时候cmd窗口报错,说是在kokia/Acer/user/acer/
的下面找不到pwd文件夹(kokia是LZ的计算机名称)
所以LZ根据提示将kettle安装解压路径下的pwd文件夹复制了一份到提示信息的路径下,
才使得Carte正常运行,不过要让LZ说是什么原理嘛,其实LZ也不知道的,
或许默认Carte服务启动的时候会到该路径下自行寻找相关的配置文件吧......
pwd这个文件夹下面默认存放的是关于Carte的一些配置文件以及登陆用户名以及密码等等,
它所在的kettle安装包的路径就是./data-integration/pwd 这个下面的。
下面是关于主服务器(master:carte-config-master-8080.xml)配置文件进行相关注释说明:
<slave_config> <slaveserver>
<name>master1</name>
<hostname>localhost</hostname>
<port>8080</port>
<master>Y</master>
</slaveserver> </slave_config> <!--
even though called master node , it is a instance of the slaveserver <name> attribute is used to define the name of the slaveserver
<hostname> in this conf file is the localhost which equal
to the "127.0.0.1" IP address
当然,对于这个hostname的话,在Linux的环境中, 在对应的配置文件中 有相关的IP地址与主机名称相对应的, 在Windows下面,LZ并不知道相关的配置文件在哪里, 所以如果是集群的节点所在的并不是基于一台主机的话,
<hostname>这个属性的值可以使用该节点所在的主机IP地址所代替。
<port> 8080 , in carte the port of 8080 is regarded
as the port of the master node in default <master> : Y which talked about above , attribute value = Y
means that the current slaveserver is regarded as the master node
in the cluster.
-->
下面是关于子服务器(slave)的配置文件进行相关注释说明:
<slave_config> <masters> <slaveserver> <name>master1</name>
<hostname>localhost</hostname>
<port>8080</port>
<username>cluster</username>
<password>cluster</password>
<master>Y</master>
</slaveserver> </masters> <report_to_masters>Y</report_to_masters> <slaveserver>
<name>slave1-8081</name>
<hostname>localhost</hostname>
<port>8081</port>
<username>cluster</username>
<password>cluster</password>
<master>N</master>
</slaveserver> </slave_config>
从节点的配置文件照比主节点的配置文件要稍微多一些内容的,
首先,多的是<masters>这个属性,其中包含的是关于一个<slaveserver>实体的设定,
其实也就是相应的在其中引入了主节点的相关设定的属性值。
然后有一个属性是<report_to_masters>这个属性是用来设定:
slave1-8081这个节点已经是主节点的子节点了,但是是否向主节点提交信息还是不知道的,
所以要通过这个属性对其进行相关的设定。
接下来就是对从节点进行相关的设定,关于IP地址,端口号,节点名称,登录用户名以及密码,
又因为该节点是子节点,所以<master>这个属性值对应的是"N".
需要注意的是,如果是在开启carte或是Spoon的时候进行相关的配置文件 进行设定的话呢,
需要退出程序之后再次进入才能是相关的配置文件生效。
3.carte服务的开启命令
Carte 有着针对不同系统可以正常运行的不同脚本文件,
对于Windows有着:Carte.bat
对于Linux有着:carte.sh
本文主要讨论的是基于Windows的运行。
首先,打开cmd控制台窗口:
然后(LZ的cmd 运行有一些问题,因为LZ的计算机是64bit的,
所以需要右键单击cmd:选择这个"以管理员的身份运行"这个选项,
才能保证carte的正确运行,不然权限不够启动会出错的)
Windows下,运行Carte:
./Carte.bat IP address port
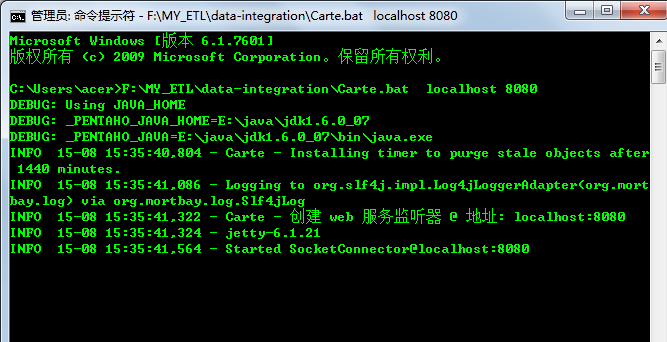
如截图所示:master node是8080端口,下面开启master node:
如下图所示,代表的是本地的主节点(port=8080)Carte服务已经被成功开启了,
4.在kettle的图形界面中对集群进行相关的设定
首先,应该开启Spoon程序,进入到图形界面中后,创建一个转换,
然后选择左边选项树的的左选项:主对象树,
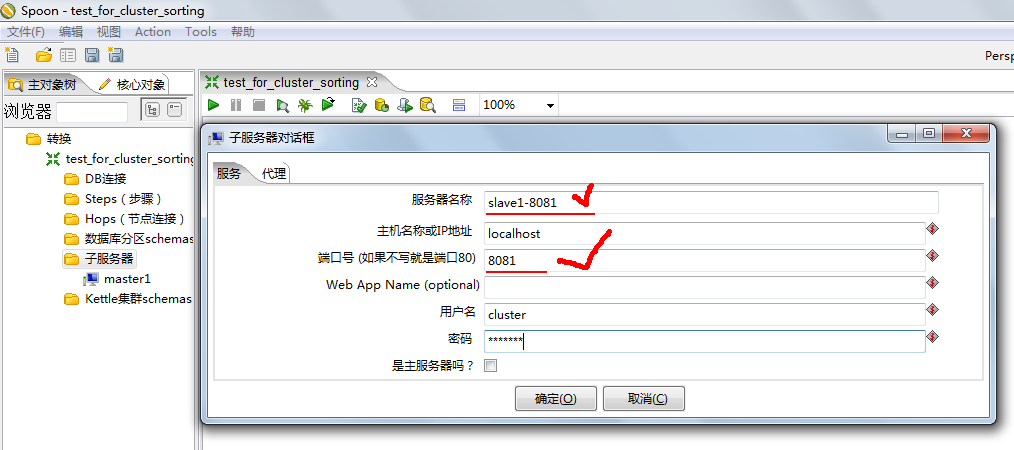
然后找到子服务器右击选择新建,如下图所示配置好主节点。
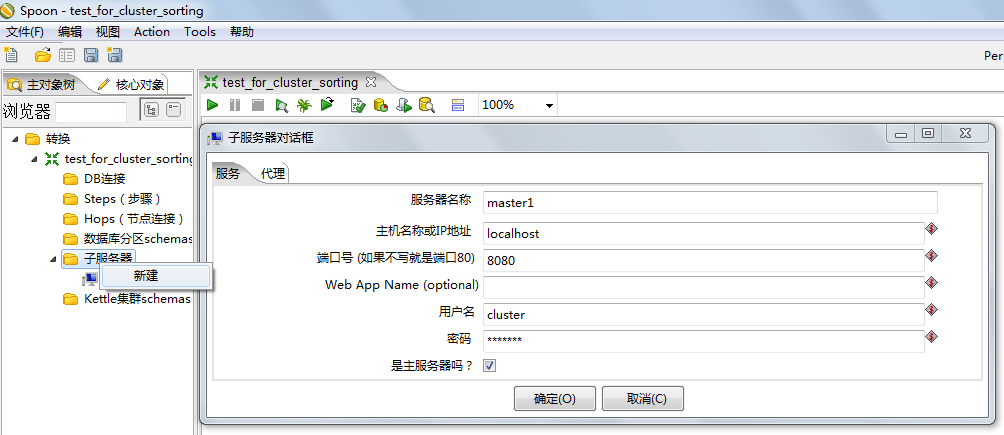
需要注意的是:
1.服务器的名称一定要与pwd文件夹下面的配置文件<name>属性所对应的值是一致的
2.所新建的子服务器一定要在pwd文件夹下面要有对应的配置文件才可以,
否则即便在Spoon中进行相关的设定也不会在集群中作为一个节点所运行的。
因为配置文件决定的是Carte服务的启动运行,而Spoon中需要调用到Carte服务。
如果一开始配置文件中没有该节点的话,就无法启动Carte服务,
在Spoon中也就无法调用该Carte作为子服务器,更不用说是将该子服务器作为集群中的节点了。
当然LZ也试着在Spoon界面中创建相关的子服务器,然后存盘该.ktr文件,
然后到相应的pwd文件夹下面寻找是否有相关的配置文件生成,但没有找到。
所以今后在Spoon中设定配置子服务器的时候,一定要先配置好Carte的配置文件才好。
下面的截图是,将要作为集群的一个子节点在pwd文件夹下的配置文件信息:
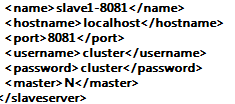
可以看到的是,对应的<name>属性的值是:slave1-8081
所以在Spoon中设定子服务器作为子节点的时候,
最好是要保证二者(Spoon中的子服务器设定和配置文件)的一致性才好:
接下来的其余子节点就不进行一一演示了。
在"是主服务器吗?"这个选项中,因为它不是主服务器,所以不对其进行勾选。
接下来将各个子服务器导入到集群中去,
选择左对象树,然后右键单击:Kettle集群schemas->新建。
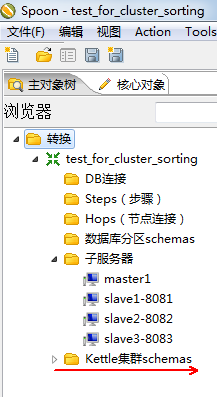
接下来选中相关的子服务器:
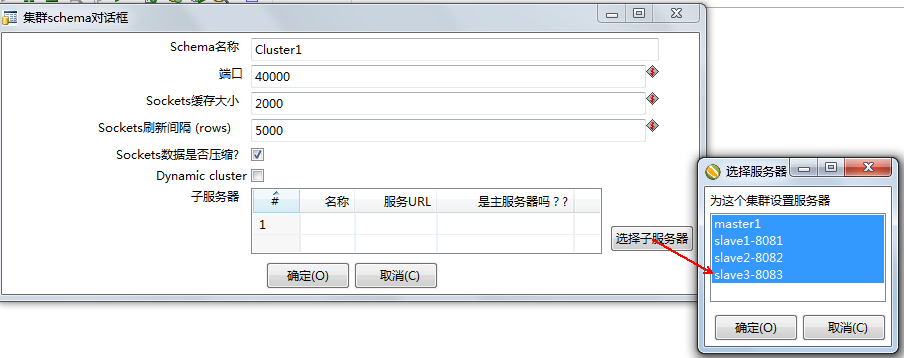
选中所有的要加入到cluster中的子服务器之后,点击确定。
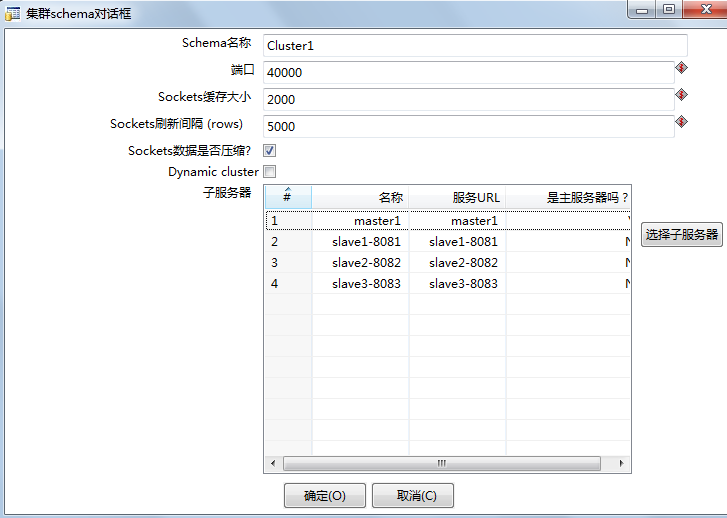
接下来就可以在集群schema对话框中看到相应的选中的服务器了,如下图所示:
感觉这篇文章的内容有一点多了呢,估计后面的两个主题也会涉及到很多的东西呢,
所以5、6这 两个主题就留到接下来的一篇文章中来介绍吧~
5.使用kettle集群模式对相关的数据进行排序
http://www.cnblogs.com/inuyasha1027/p/kettle_cluster_sorting2.html
6.有关于集群调用子服务器的java源代码实现
在使用Kettle的集群排序中 Carte的设定——(基于Windows)的更多相关文章
- Kettle的集群排序 2——(基于Windows)
5.使用kettle集群模式对相关的数据进行排序 既然,基于Carte服务程序所搭建的集群已经在Spoon中设定好了, 可以首先,先来启动四个节点: "以管理员身份运行"打开 四个 ...
- docker swarm英文文档学习-12-在集群模式中的Raft共识
Raft consensus in swarm mode 在集群模式中的Raft共识 当Docker引擎在集群模式下运行时,manager节点实现Raft 共识算法来管理全局集群状态.Docker s ...
- 深入探讨在集群环境中使用 EhCache 缓存系统
EhCache 缓存系统简介 EhCache 是一个纯 Java 的进程内缓存框架,具有快速.精干等特点,是 Hibernate 中默认的 CacheProvider. 下图是 EhCache 在应用 ...
- Oracle rac集群环境中的特殊问题
备注:本文摘抄于张晓明<大话Oracle RAC:集群 高可用性 备份与恢复> 因为集群环境需要多个计算机协同工作,要达到理想状态,必须要考虑在集群环境下面临的新挑战. 1.并发控制 在集 ...
- 在集群环境中使用 EhCache 缓存系统|RMI 集群模式
RMI 是 Java 的一种远程方法调用技术,是一种点对点的基于 Java 对象的通讯方式.EhCache 从 1.2 版本开始就支持 RMI 方式的缓存集群.在集群环境中 EhCache 所有缓存对 ...
- (转)深入探讨在集群环境中使用 EhCache 缓存系统
简介: EhCache 是一个纯 Java 的进程内缓存框架,具有快速.精干等特点,是 Hibernate 中默认的 CacheProvider.本文充分的介绍了 EhCache 缓存系统对集群环境的 ...
- Akka(12): 分布式运算:Cluster-Singleton-让运算在集群节点中自动转移
在很多应用场景中都会出现在系统中需要某类Actor的唯一实例(only instance).这个实例在集群环境中可能在任何一个节点上,但保证它是唯一的.Akka的Cluster-Singleton提供 ...
- 在 WebSphere Application Server V7 集群环境中管理 HTTP session[阅读]
http://www.ibm.com/developerworks/cn/websphere/library/techarticles/1012_dingsj_wascluster/1012_ding ...
- 手把手教你搭建FastDFS集群(中)
手把手教你搭建FastDFS集群(中) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/u0 ...
随机推荐
- leetcode面试准备: Jump Game II
1 题目 Given an array of non-negative integers, you are initially positioned at the first index of the ...
- 通过Delphi获得qq安装路径
procedure TForm1.Button2Click(Sender: TObject); var Reg:TRegistry; Val:TStrings; ii:System.Integer; ...
- c++学习笔记(2)类的声名与实现的分离及内联函数
一.类的声名与实现的分离: 和c函数声明与实现分离类似 有.h : 类的声明 .cpp : 类的实现 在在一个类的cpp中应该包含本类的.h文件 在cpp中类的使用:例: //Circle类 //Ci ...
- CSU 1511 残缺的棋盘 第十届湖南省赛题
题目链接:http://acm.csu.edu.cn/OnlineJudge/problem.php?id=1511 题目大意:在一个8*8的棋盘中,给你一个起点位置和一个终点位置,同时也给你一个陷阱 ...
- 2013=7=12 ACM培训第一天
ACM培训第一天,尽管我嘴上说是来打酱油的,但我非常想学好.1.一定要多思考,多总结:2.多问同学 :3.学会向女生说话,大胆,自信.(今天有女生向我说话了,很高兴.她很大胆,我要向她学习...... ...
- Torque2D MIT 学习笔记(27) ---- ImageFont的使用以及字体ImageAsset的工具生成
前言 ImageFont继承于SceneObject,是一个场景对象,支持例如旋转,缩放,移动加速度以及物理碰撞等一切Torque中场景对象的一切功能. ImageFont只支持ASCII编码表中的3 ...
- 让x86的android模拟器能模拟arm架构系统
网上介绍共计三种模拟器比较常用,分别是bluestacks.andy和Genymotion,前者支持ARM架构,中者支持远程控制,后者启动速度快,各有优缺点. 如果要用genymotion模拟arm的 ...
- Google表单
本博文的主要内容有 .Google表单的介绍 https://www.google.com/intl/zh-CN/forms/about/ 自行去注册Google账号,不多,赘述.
- Dubbo xml配置 和注解配置 写法
<?xml version="1.0" encoding="UTF-8"?><!-- - Copyright 1999-2011 Alibab ...
- java 新手
public class hello{ public static void main(String args[]){ int a=23,b=32,c=34; int s=Math.max(a,c); ...