在 KubeSphere 中部署高可用 Redis 集群
作者:余生大大,大数据开发工程师,云原生爱好者,KubeSphere 社区用户。
前言
Redis 是在开发过程中经常用到的缓存中间件,在生产环境中为了考虑稳定性和高可用一般为集群模式的部署。
常规部署在虚拟机上的方式配置繁琐并且需要手动重启节点,而使用 K8s 进行 Redis 集群的部署有以下优点:
- 安装便捷:使用镜像或者
yaml配置文件即可一件安装 - 自动调度:容器挂掉后会自动调度重启和资源分配
- 缩扩容方便:在
扩容、缩容方面的优点无需多说,一键伸缩 - 稳定高效:
K8s在整个集群上进行调度,只要整个集群不挂掉总会调度到合适节点重启容器服务
安装 Redis 集群
我这里新建了一个 test-project 的项目空间来做 Redis 集群所有安装资源的放置,后续在 DNS 上会用到项目空间名称,会标注这一部分,需要注意用自己的项目空间名。
安装集群大概分为以下几步:
- 配置
redis.conf字典; - 创建
redis服务; - 容器组配置;
- 存储设置;
- 高级设置。
现在从第一步开始。
1.1 配置 redis.conf 字典
在项目空间的 配置 → 配置字典 → 创建 进行配置字典的创建。
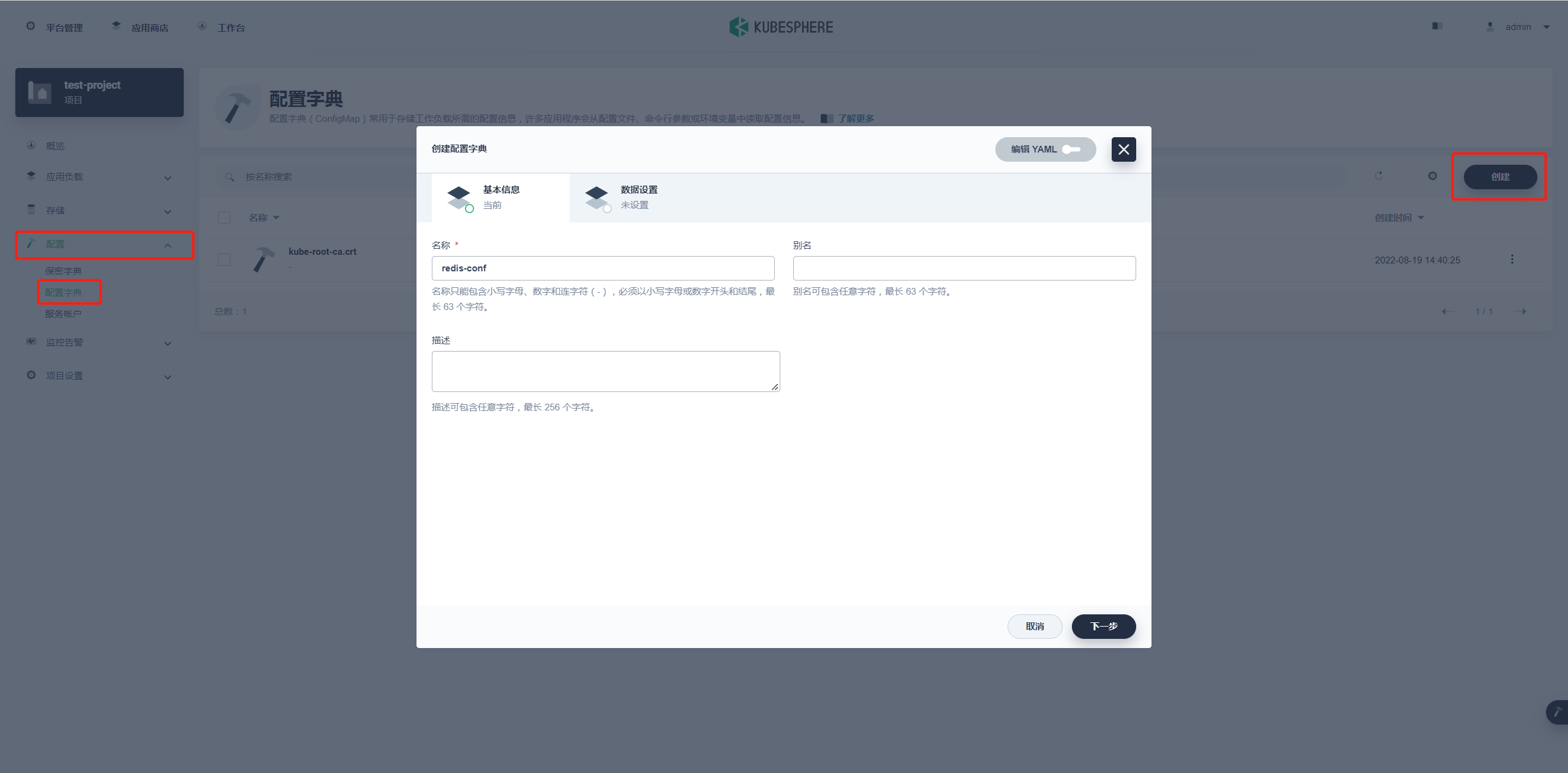
名称就叫 redis-conf 然后下一步 添加键值对数据。
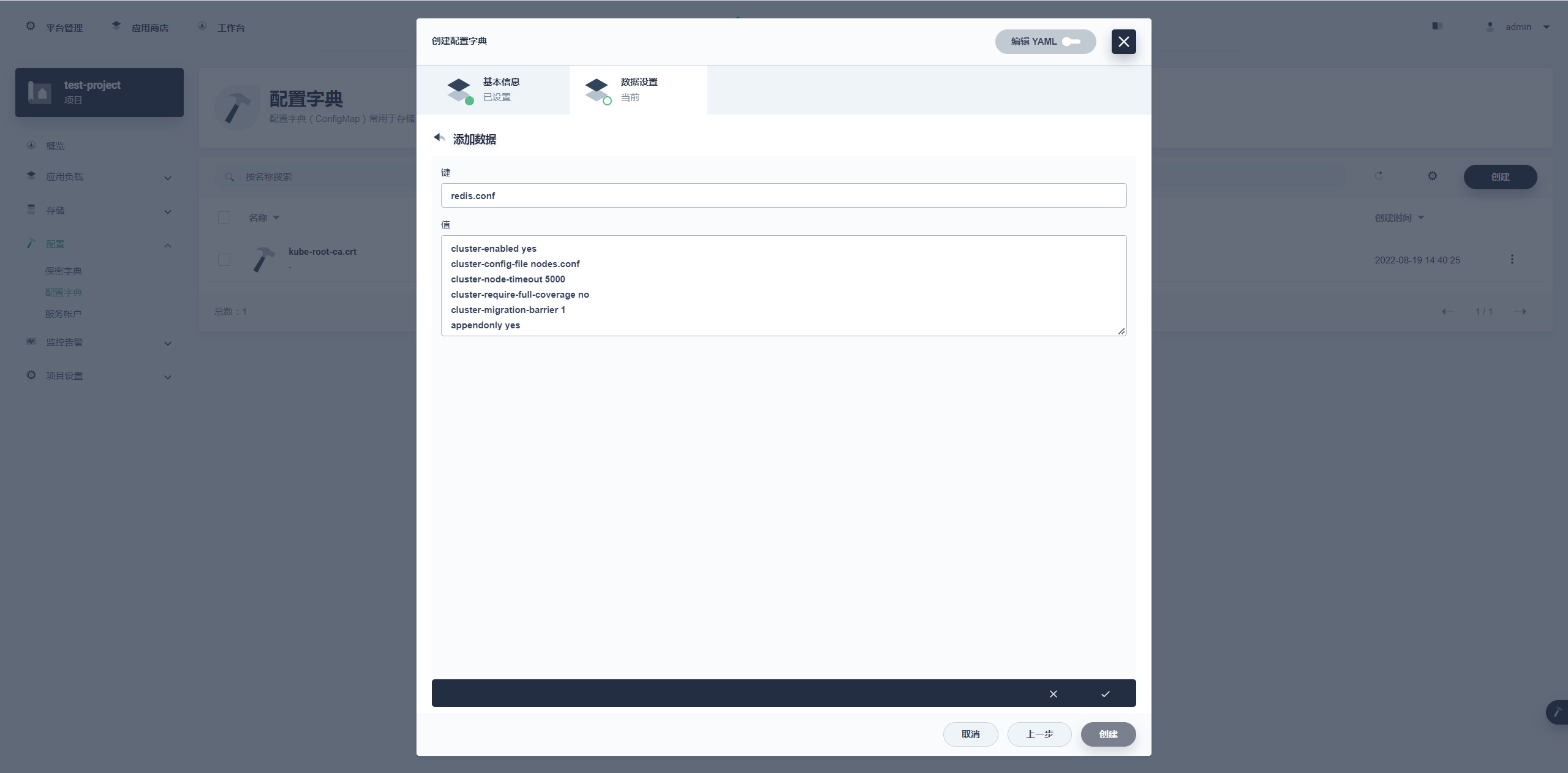
key 值的内容为 redis.conf,value 值为:
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-require-full-coverage no
cluster-migration-barrier 1
appendonly yes
创建 Redis 服务
在项目空间的 应用负载 → 服务 → 创建 进行 Redis 服务的创建。
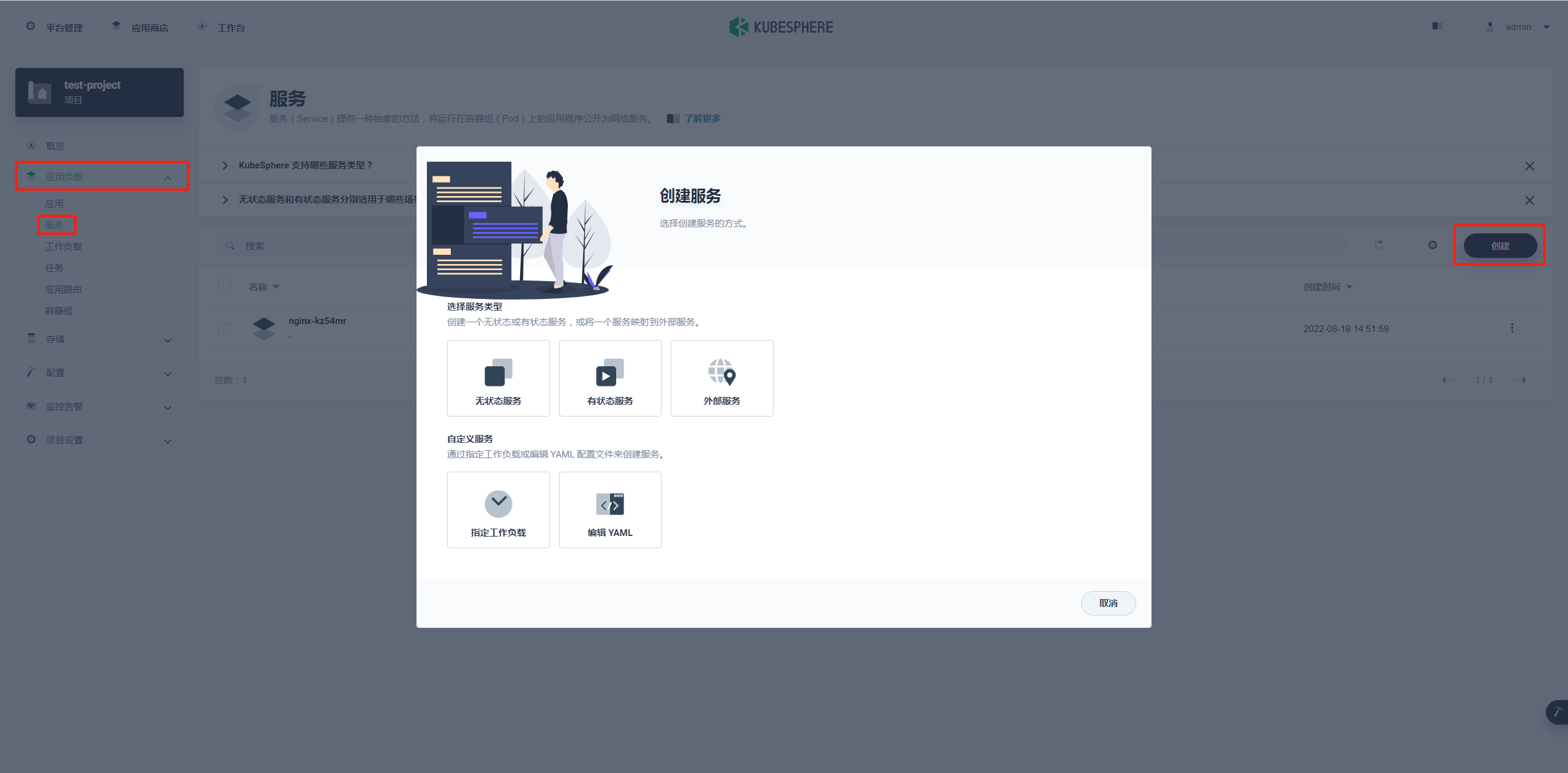
选择有状态服务,需要数据存储的服务基本都是有状态的服务。
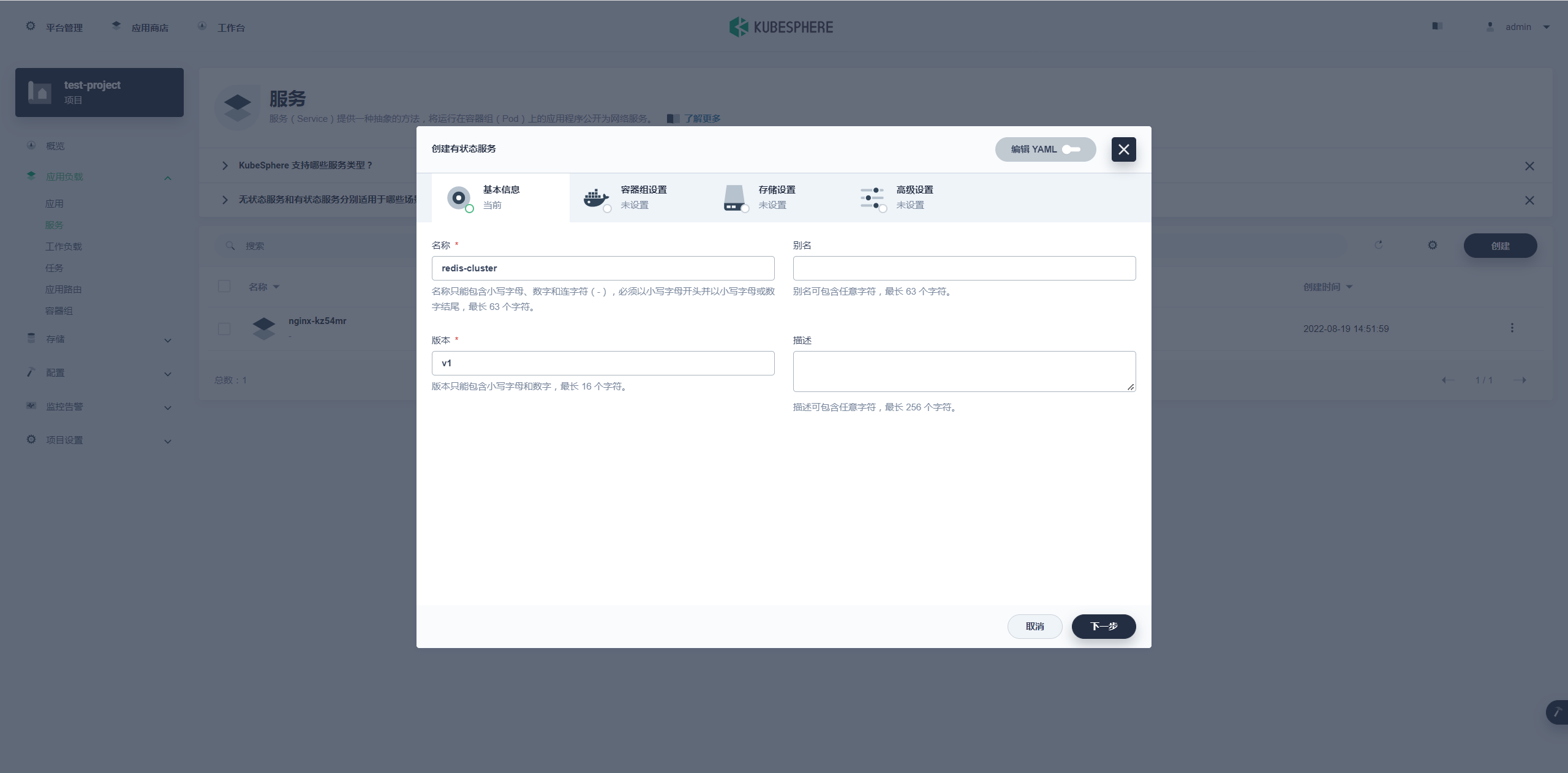
基本设置里名称就叫 redis-cluster 然后进行重头戏,下一步的容器组配置。
容器组配置
这一步的核心就是配置 Redis 的容器,集群数量就选择常规的三主三从,那容器的副本数量就是 6 个。
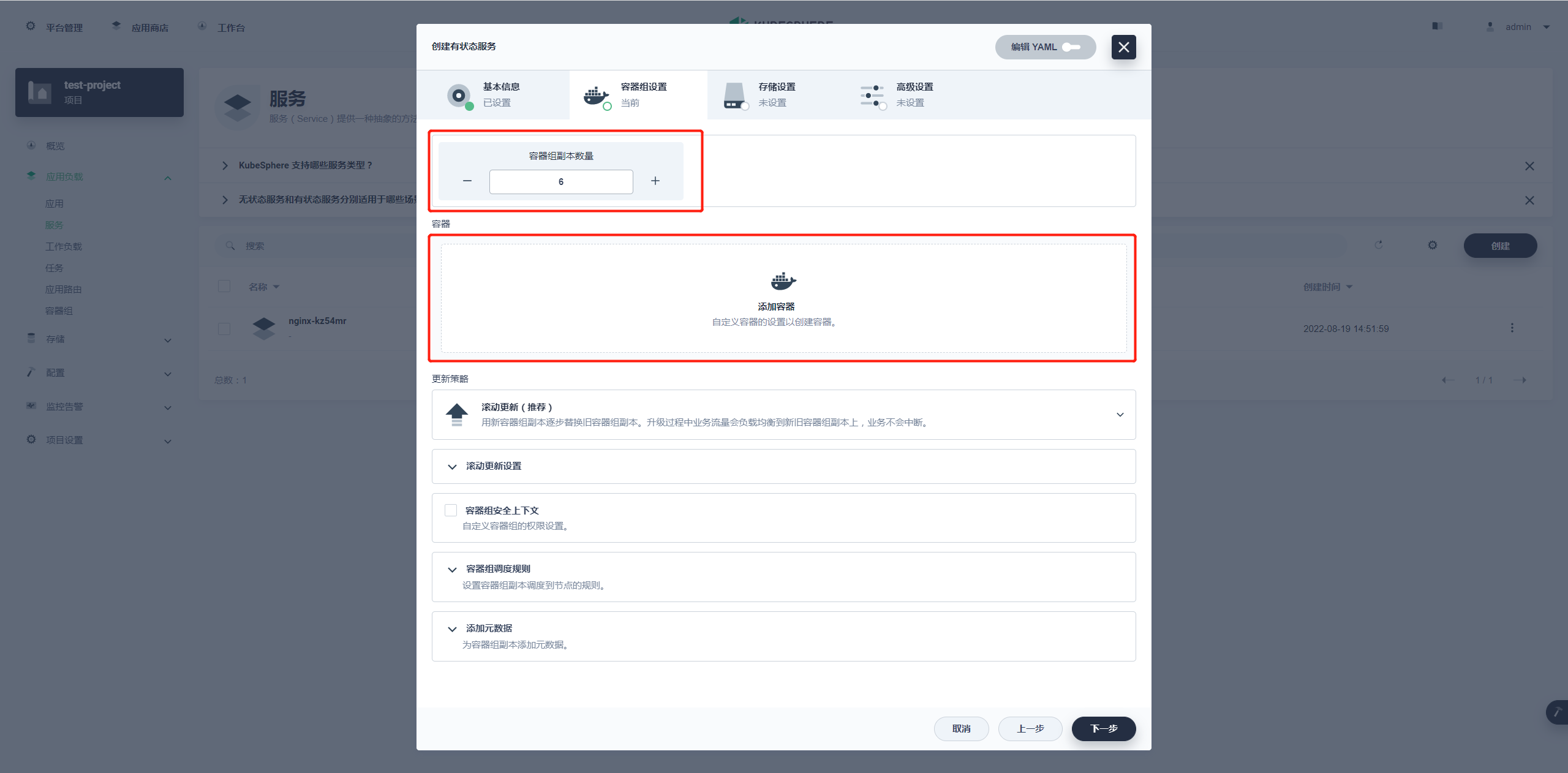
容器组副本数量调到 6 个,点击添加容器。
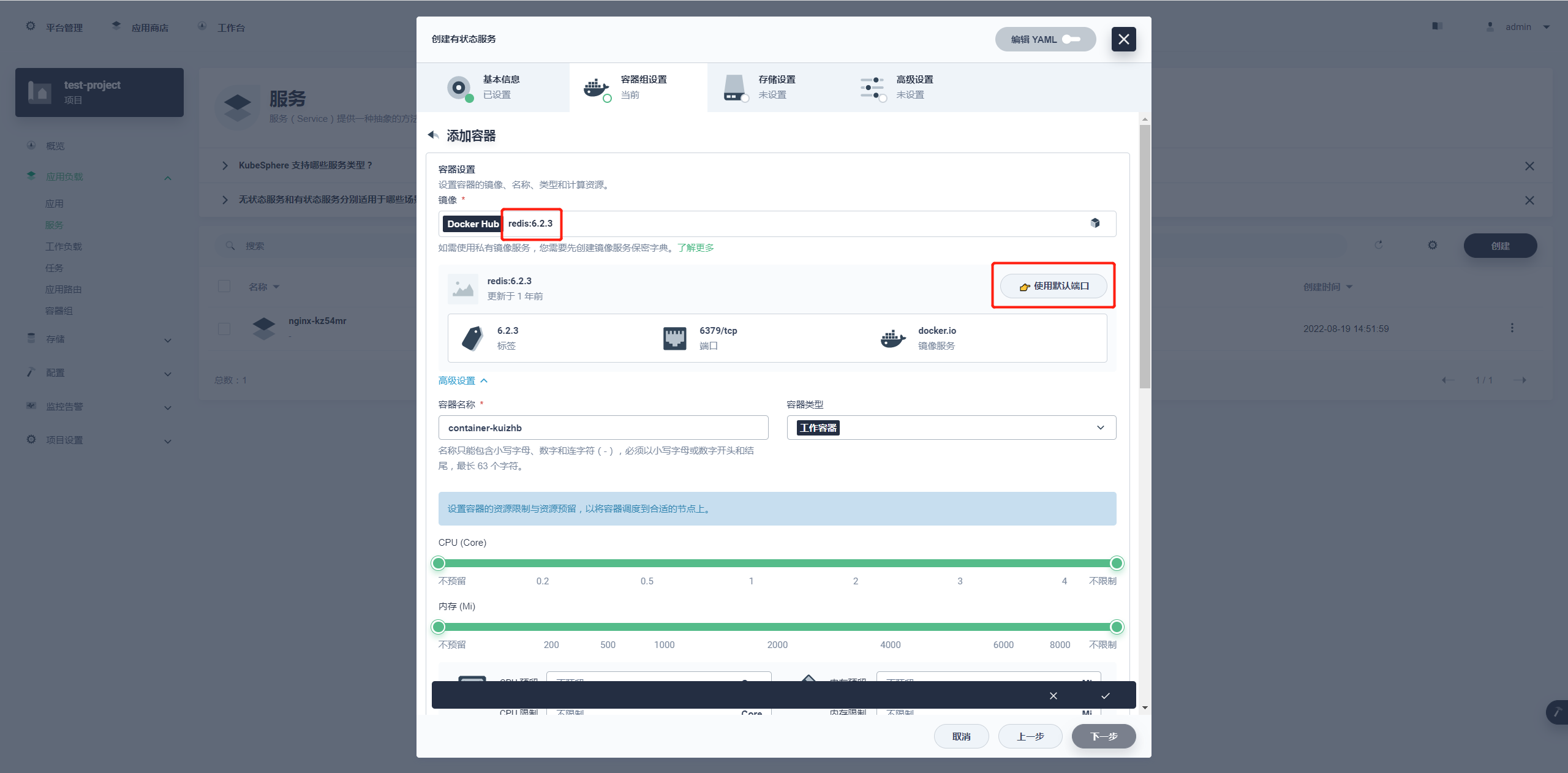
镜像选择 docker hub 中 redis 的 6.2.3 版本,并选择使用默认端口,CPU 和内存可以选择性预留,如果不预留就是调度公共资源。
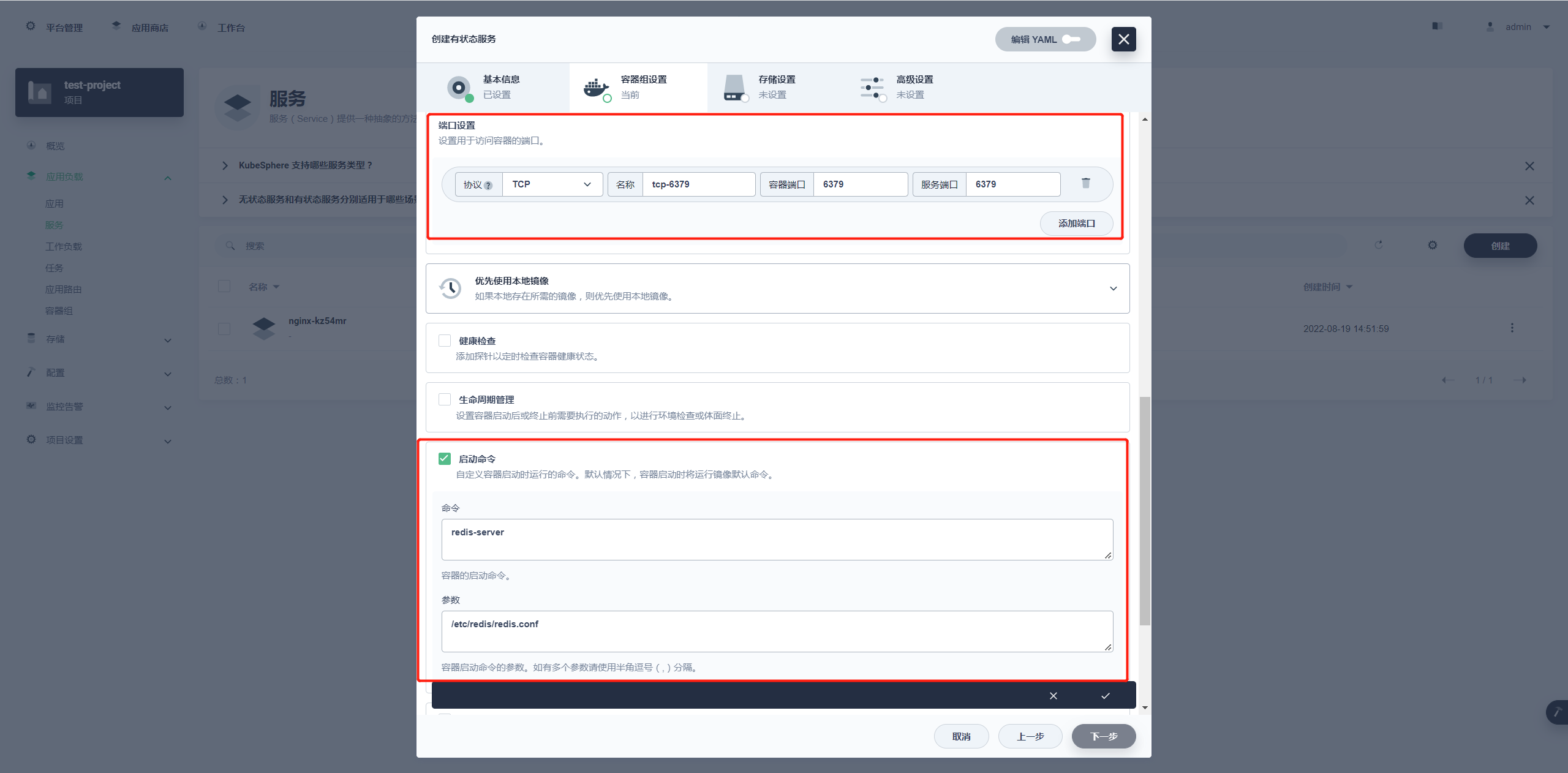
选择使用默认端口的话下面的端口设置就是如上图一样都会使用 6379,还有就是配置启动命令。
如上图配置:
- 命令:
redis-server - 参数:
/etc/redis/redis.conf
参数指向的就是之前字典配置的内容,但是需要下一步存储设置里进行配置字典才能使用。
其他内容没有什么需要配置的,选择对勾完成容器配置。
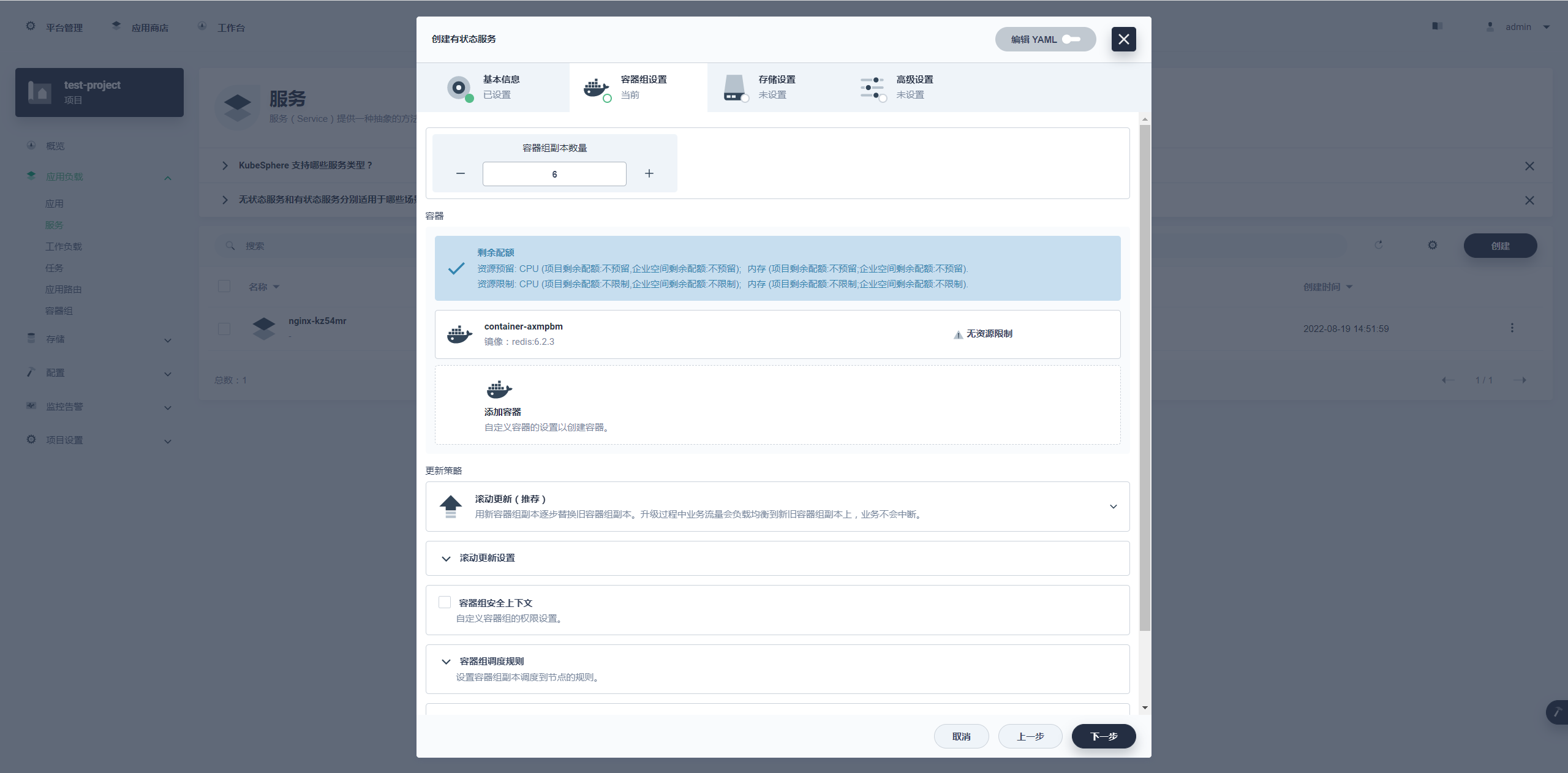
更新策略就是推荐的滚动更新,其他也没什么需要修改的,点击下一步配置存储设置。
存储设置
在这一步有两个操作
添加持久卷声明模板挂载配置字典
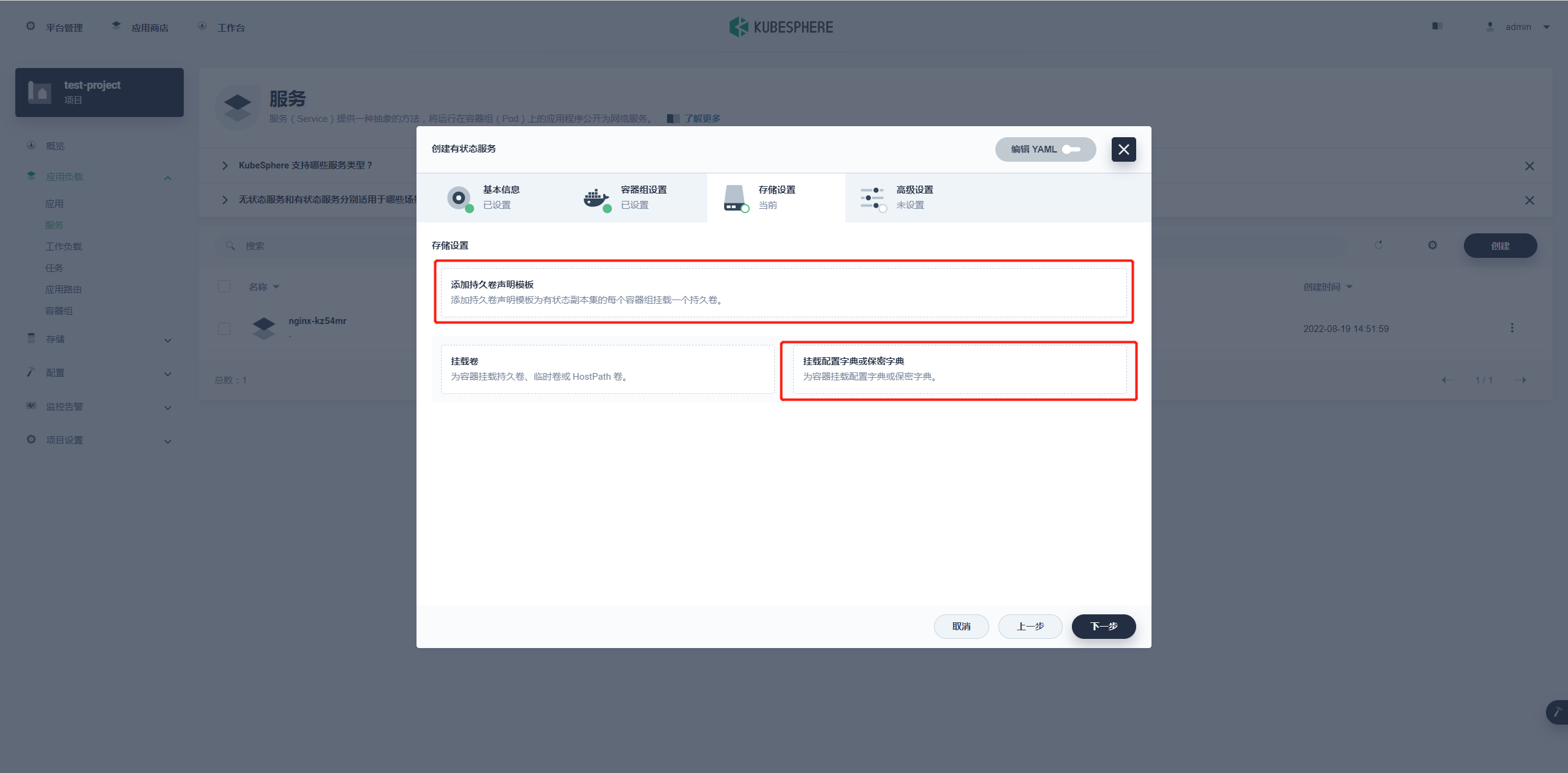
添加持久卷声明模板
PVC 名称前缀:redis-pvc
容量:10G
挂载路径:
权限:读写
地址:/data
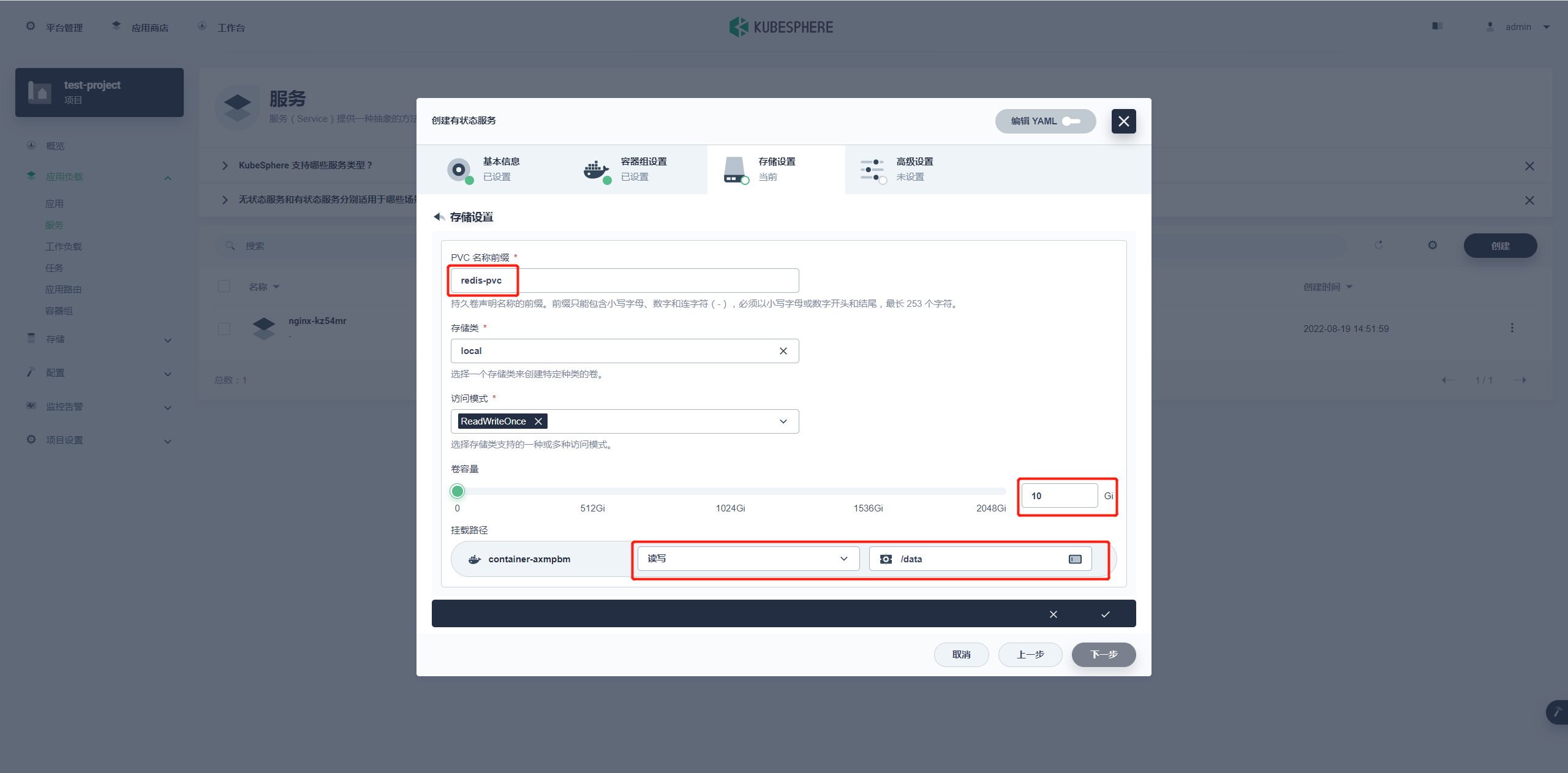
主要是挂载路径选好,配置好后点击对勾完成配置
挂载配置字典
这一步是挂载我们之前配置的字典 redis-conf,也是我们 redis 启动命令的参数内容。
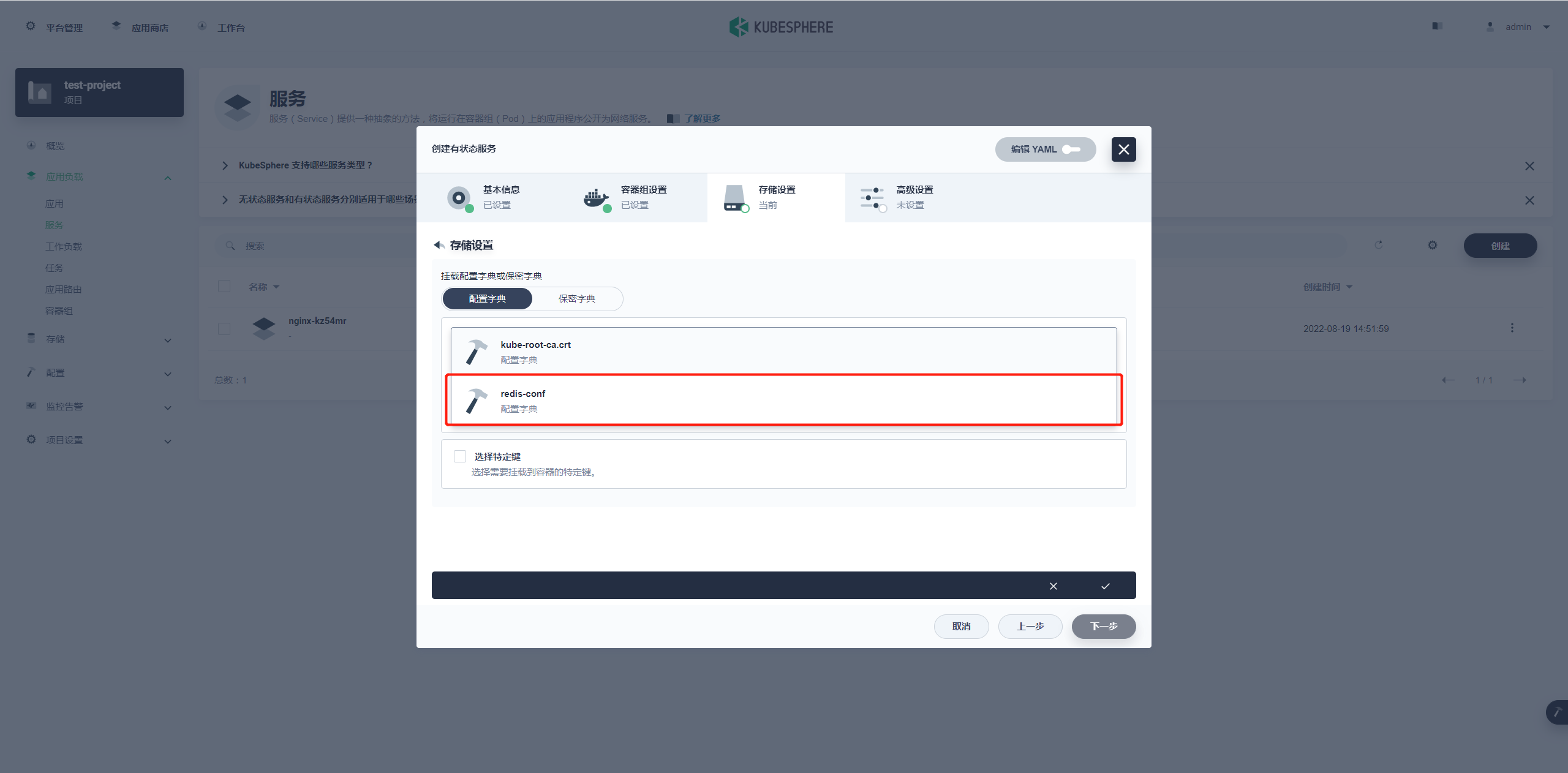
选择 redis 的配置字典。
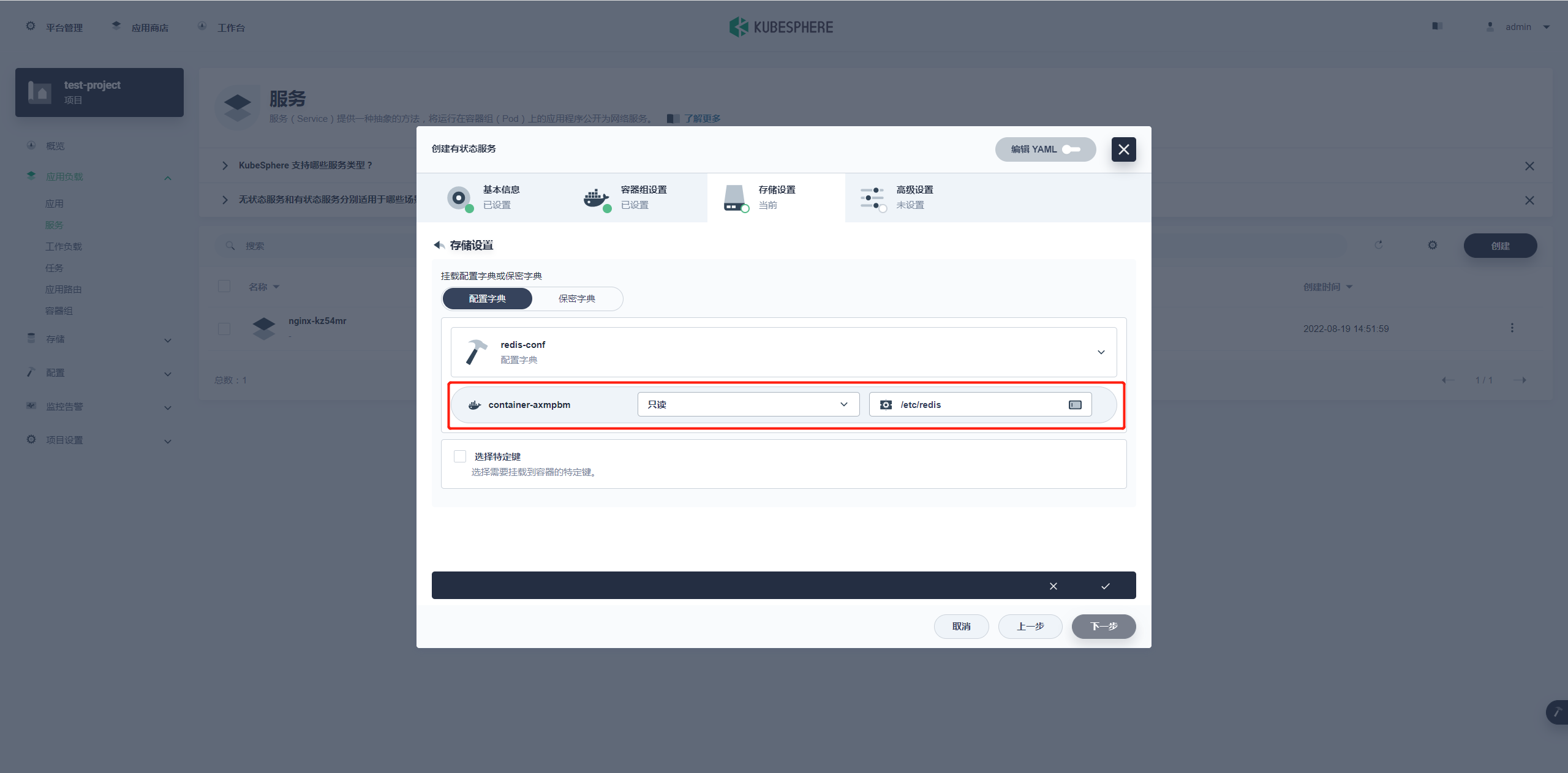
挂载权限为:只读,地址为:/etc/redis;跟上面的命令参数的配置相对应。
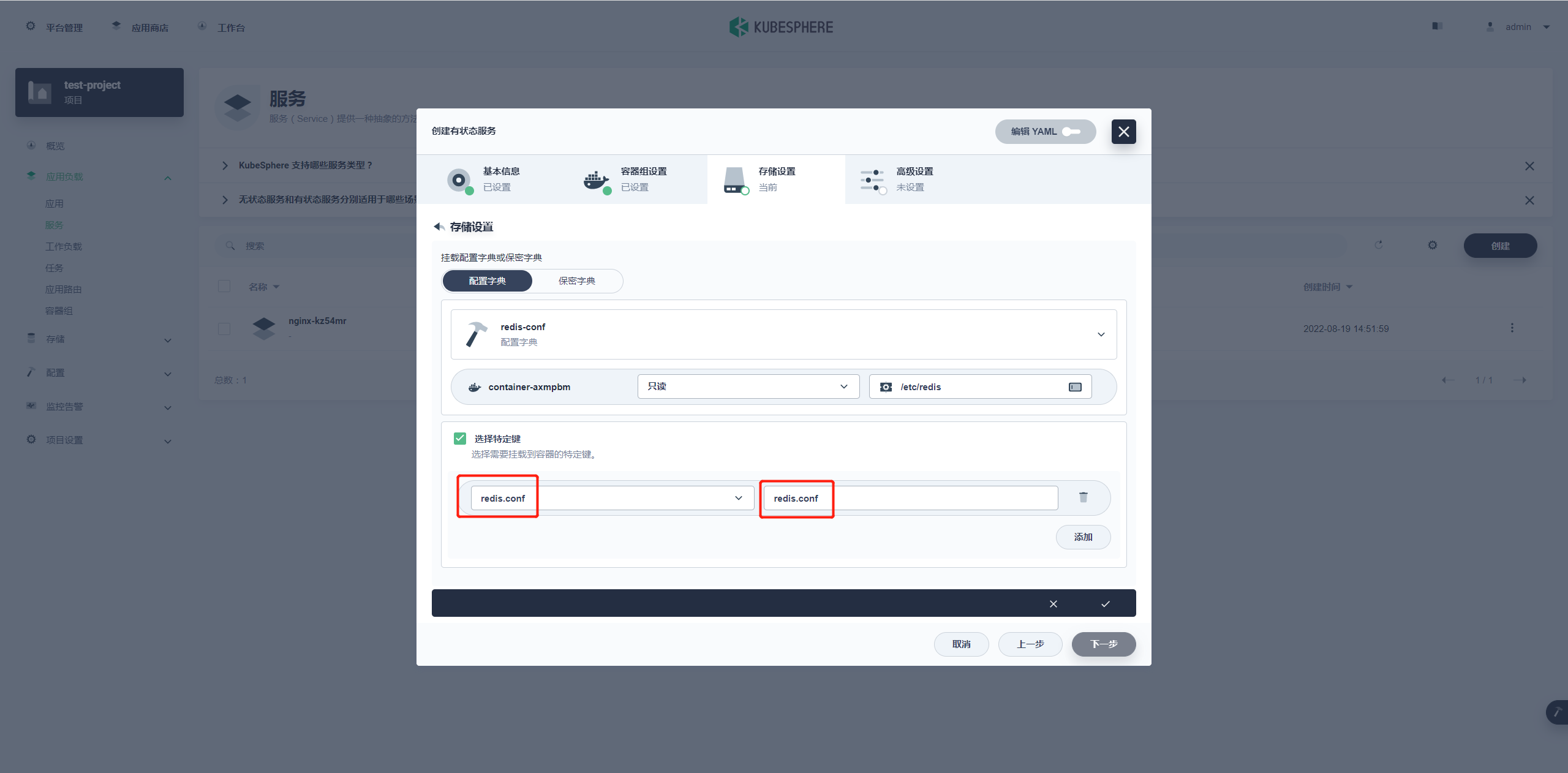
特定键选择 redis.conf 后面同名 redis.conf,完成后点击对勾回到存储设置。
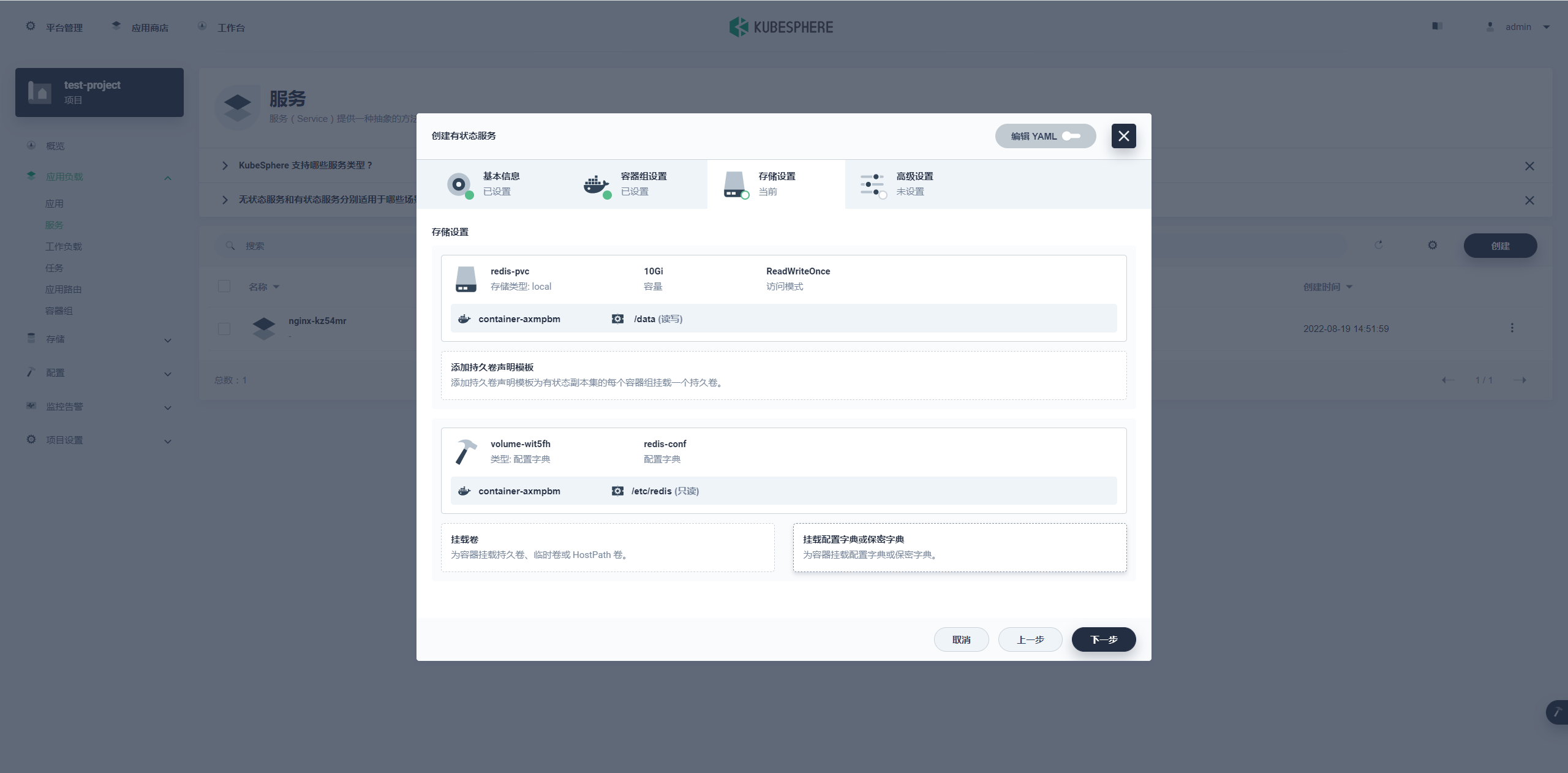
配置好后就入上图,点击下一步进入最后的高级设置。
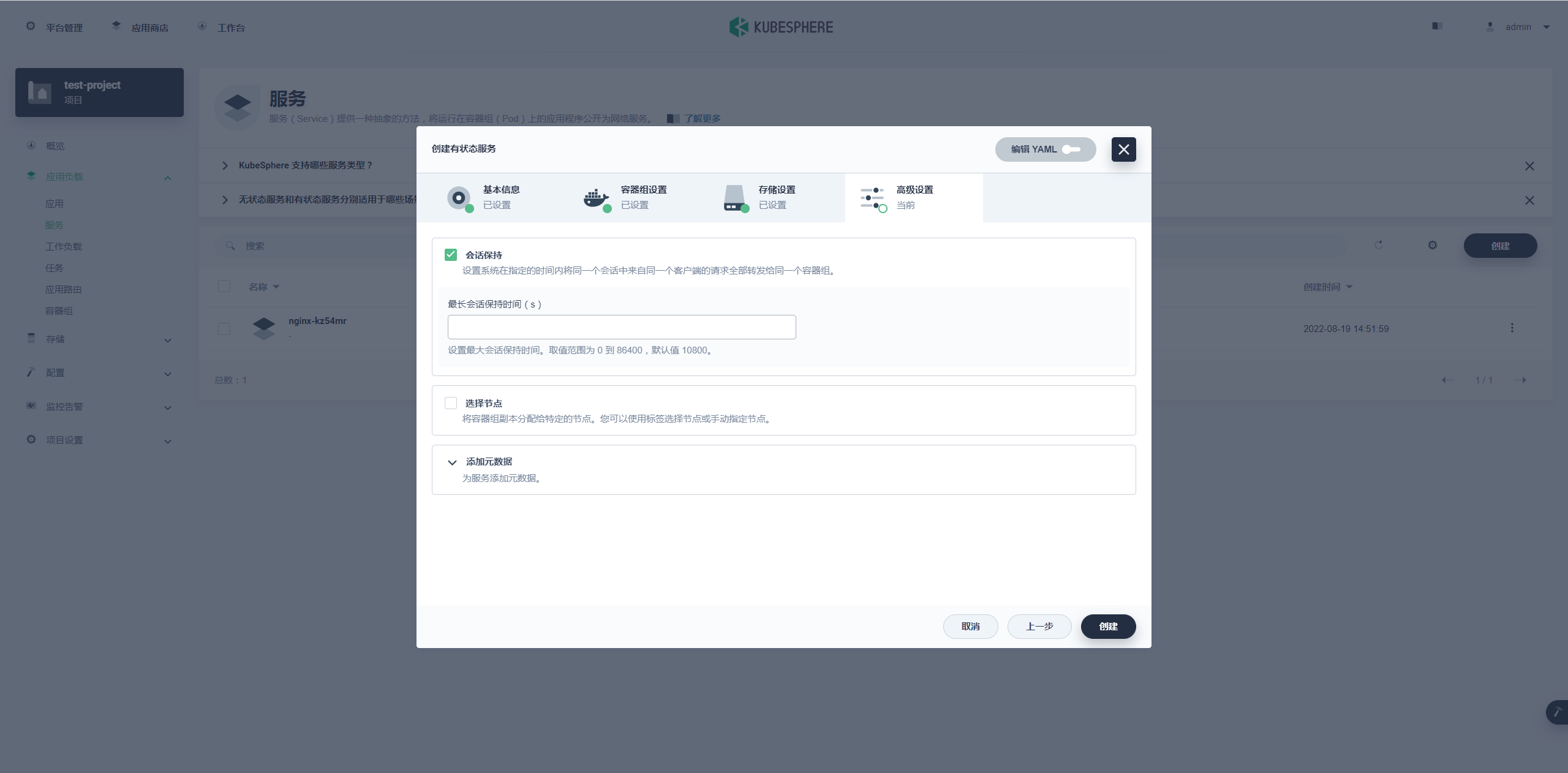
高级设置里是一些额外配置,可以根据自己场景选择调整配置,调成完成后点击创建 进行 Redis 集群容器的创建。
初始化 Redis 集群
创建完 Redis 服务后点击 redis 的服务名称进入 redis 服务详情,详情如下图:
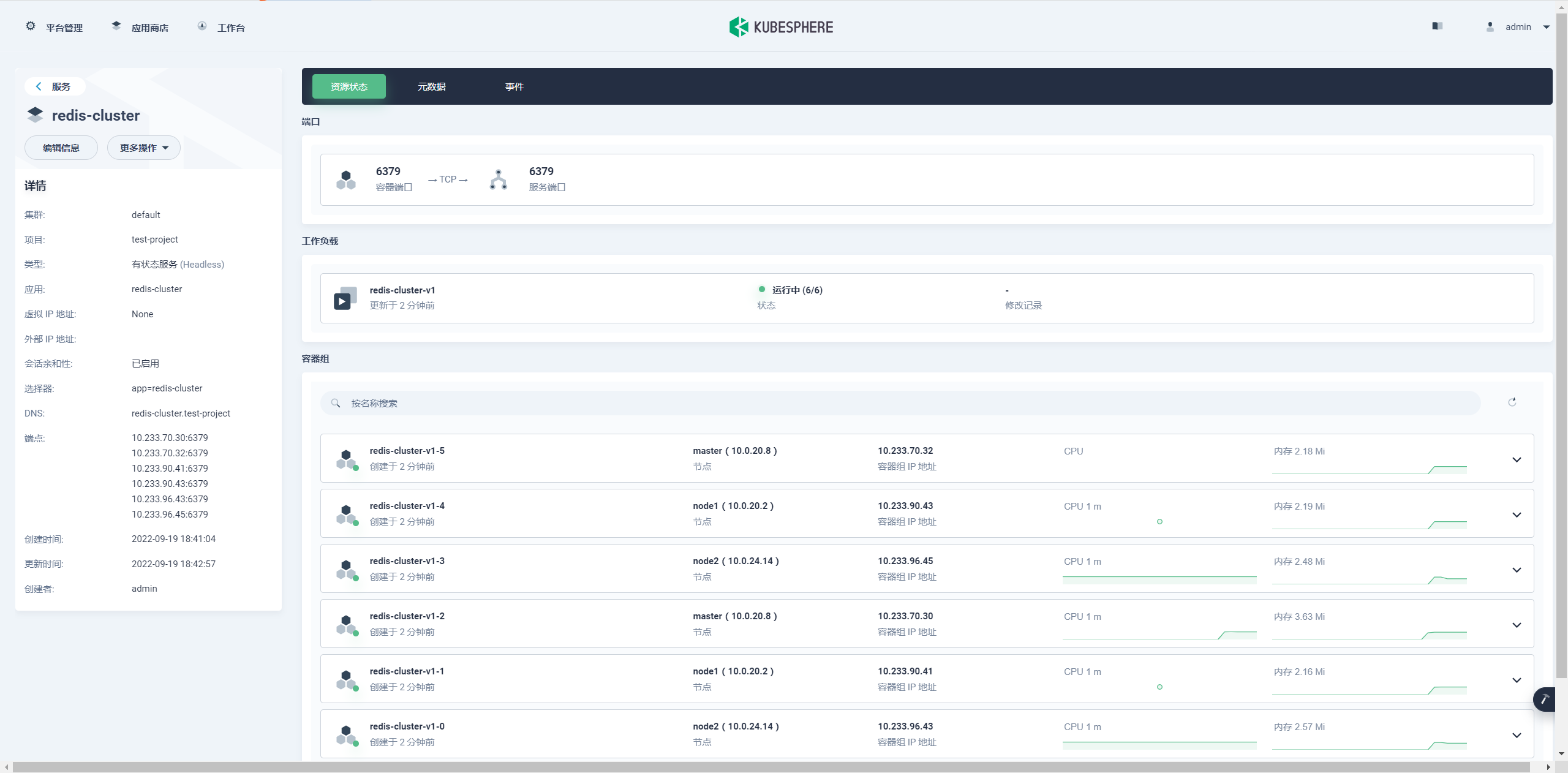
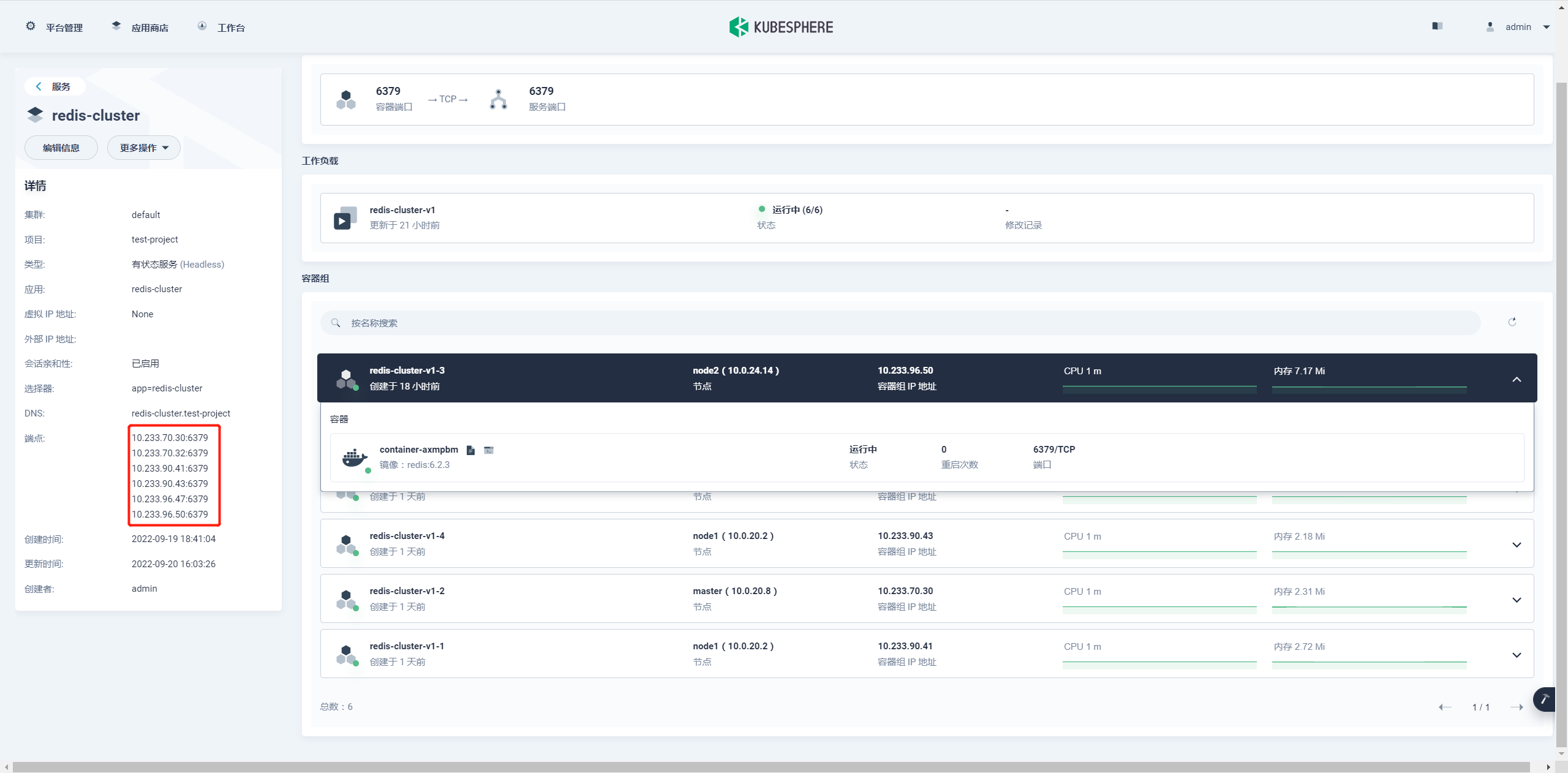
6 个 redis 的容器组都启动成功了,接下来就是初始化集群;因为我们配置的 redis 的服务是有状态服务 (Headless) 所以访问模式可以通过内部 DNS,访问格式是:(容器名称).( 容器 DNS).svc.cluster.local。
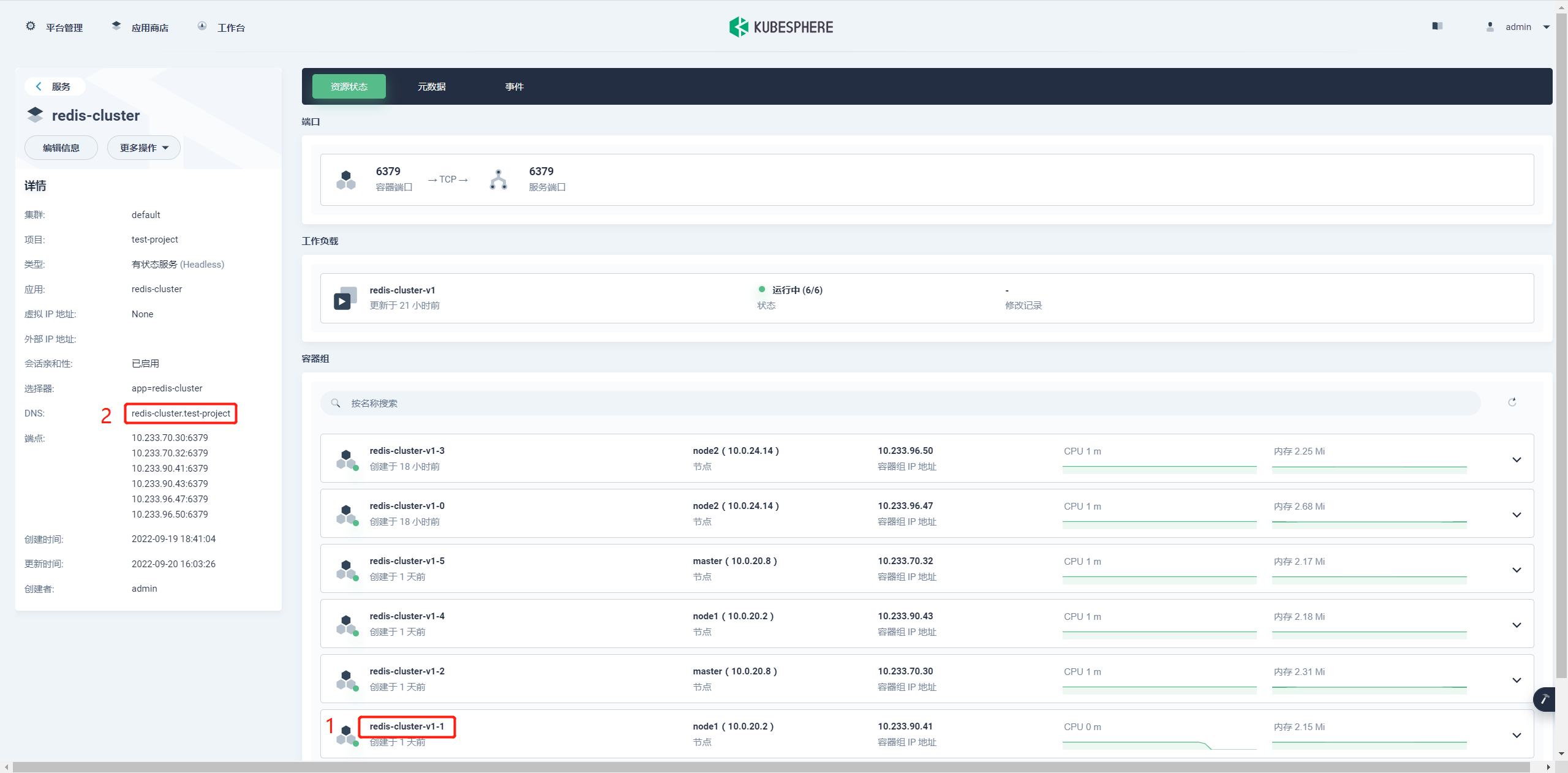
按上图示例 比如访问集群 1 节点访问地址就是 redis-cluster-v1-1 加 DNS 地址 redis-cluster.test-project 加 svc.cluster.local,完整地址如下:
redis-cluster-v1-1.redis-cluster.test-project.svc.cluster.local
在 redis 集群的非第一节点的其他节点终端内通过这个地址进行访问验证他们是否互通,进入 3 节点的终端,如下图:
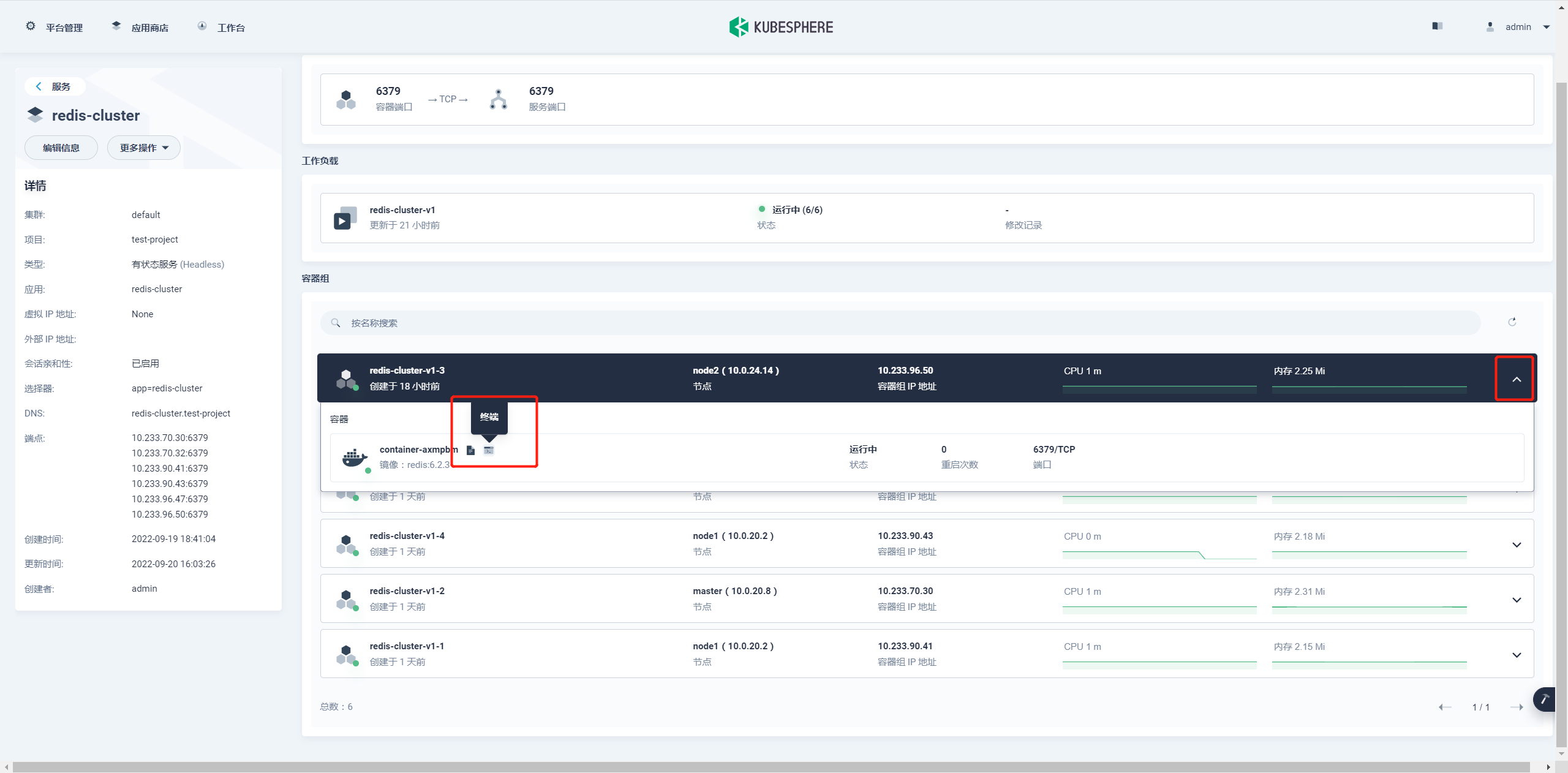
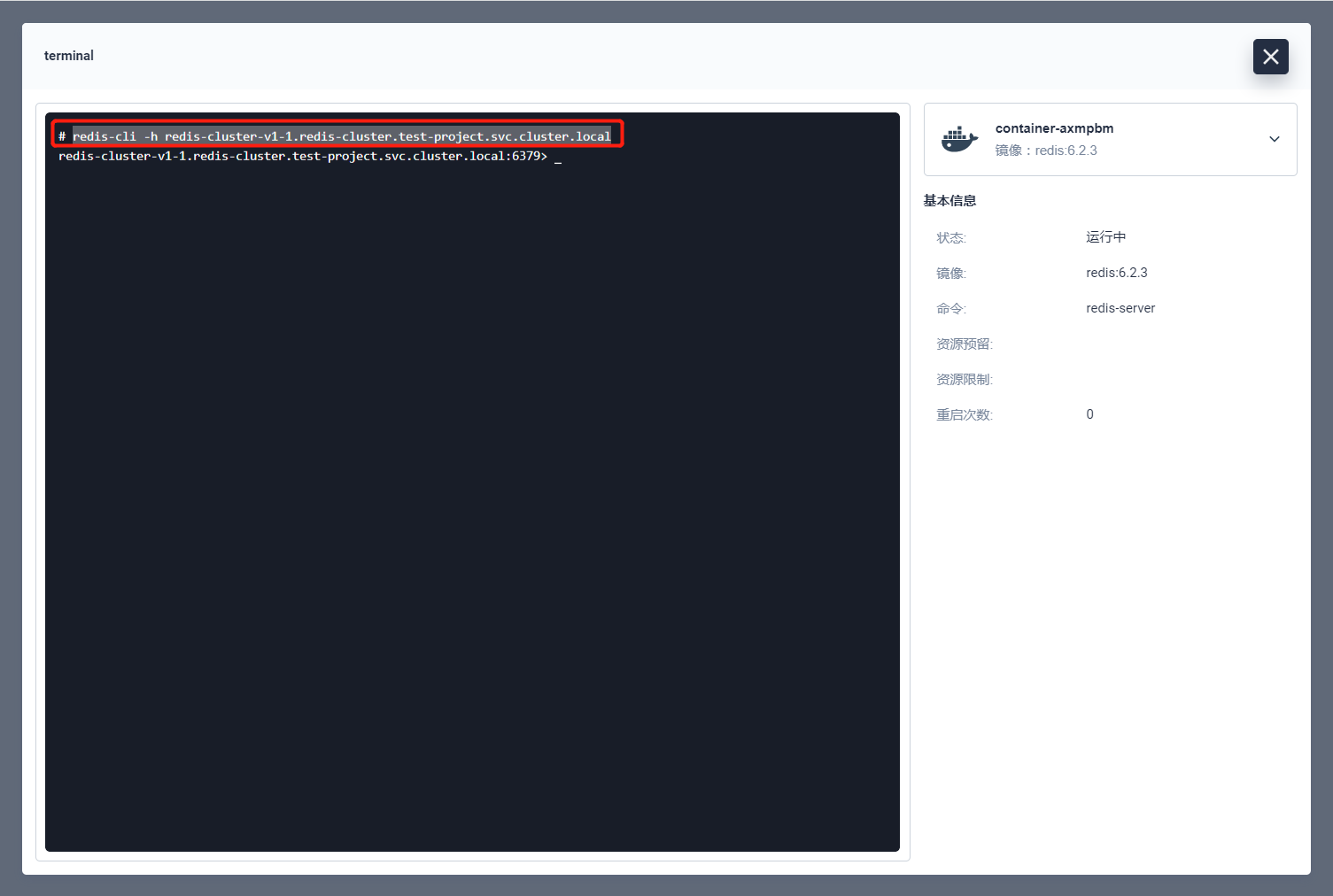
进入终端,执行命令:
redis-cli -h redis-cluster-v1-1.redis-cluster.test-project.svc.clusterredis.local
如果能如下图一样跳转到 v1-1 的节点上就代表这两个节点互通。
执行命令:cluster info 查看节点的集群情况。
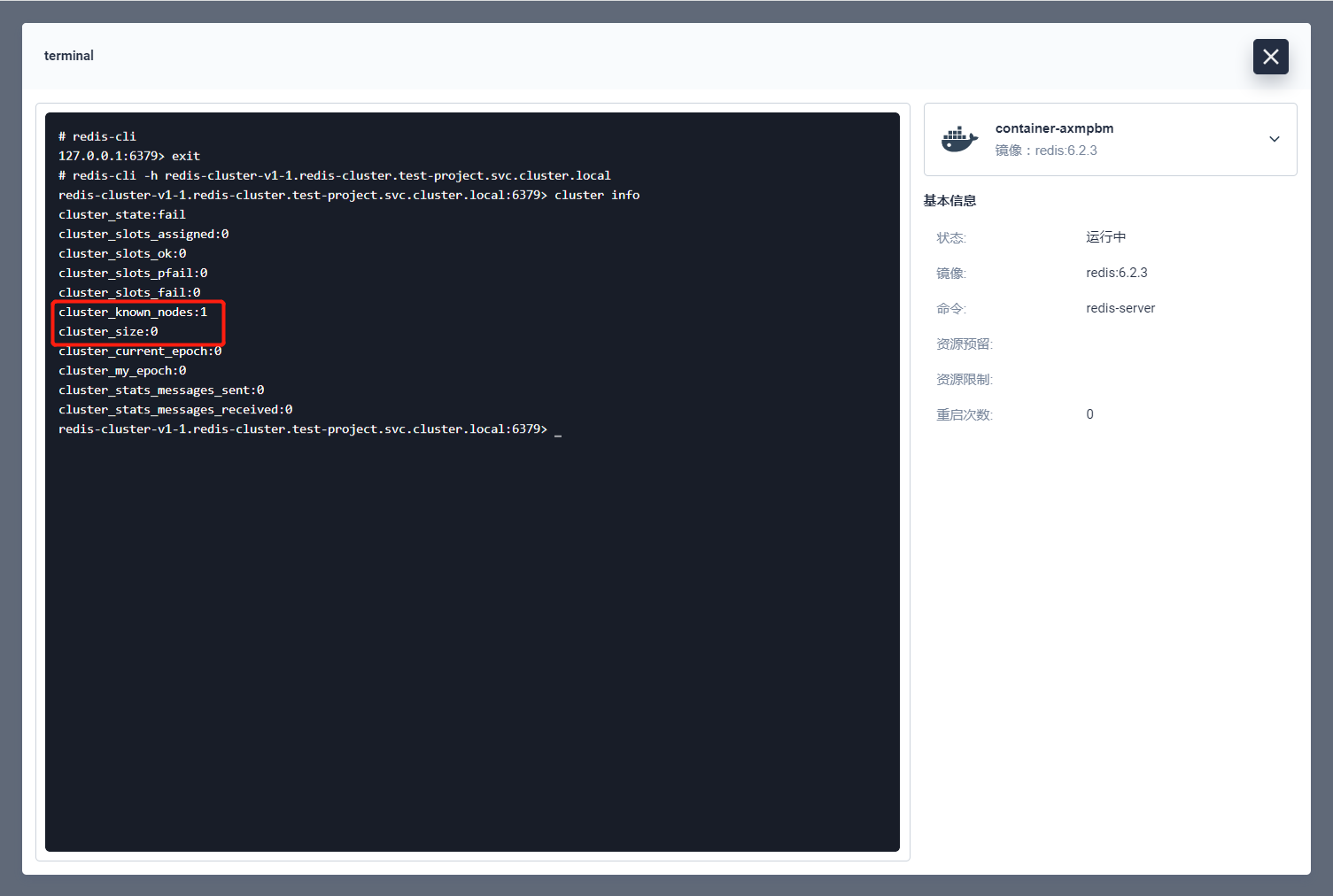
主要看上图的这两个参数,nodes 为 1 表明当前节点只有 1 个,cluster_size 表明当前没有 master 节点,所以目前还不是集群结构,info 属性的详解在此列出:
cluster_state:ok 状态表示集群可以正常接受查询请求。fail 状态表示,至少有一个哈希槽没有被绑定(说明有哈希槽没有被绑定到任意一个节点),或者在错误的状态(节点可以提供服务但是带有 FAIL 标记),或者该节点无法联系到多数 master 节点。cluster_slots_assigned:已分配到集群节点的哈希槽数量(不是没有被绑定的数量)。16384 个哈希槽全部被分配到集群节点是集群正常运行的必要条件。cluster_slots_ok:哈希槽状态不是 FAIL 和 PFAIL 的数量。cluster_slots_pfail:哈希槽状态是 PFAIL 的数量。只要哈希槽状态没有被升级到 FAIL 状态,这些哈希槽仍然可以被正常处理。PFAIL 状态表示我们当前不能和节点进行交互,但这种状态只是临时的错误状态。cluster_slots_fail: 哈希槽状态是 FAIL 的数量。如果值不是 0,那么集群节点将无法提供查询服务,除非 cluster-require-full-coverage 被设置为 no。cluster_known_nodes:集群中节点数量,包括处于握手状态还没有成为集群正式成员的节点。cluster_size:至少包含一个哈希槽且能够提供服务的 master 节点数量。cluster_current_epoch:集群本地 Current Epoch 变量的值。这个值在节点故障转移过程时有用,它总是递增和唯一的。cluster_my_epoch:当前正在使用的节点的 Config Epoch 值。这个是关联在本节点的版本值。cluster_stats_messages_sent:通过 node-to-node 二进制总线发送的消息数量。cluster_stats_messages_received:通过 node-to-node 二进制总线接收的消息数量。
IP 地址初始化集群
先尝试使用 ip + port 的方式初始化集群,但是在 K8s 中启动服务 ip 都会变化,所以最终的结果还是要用 DNS 方式进行集群初始化。
执行本步后再想修改为 DNS 地址初始化需要从来一遍,如果不想麻烦的同学可以直接跳过。
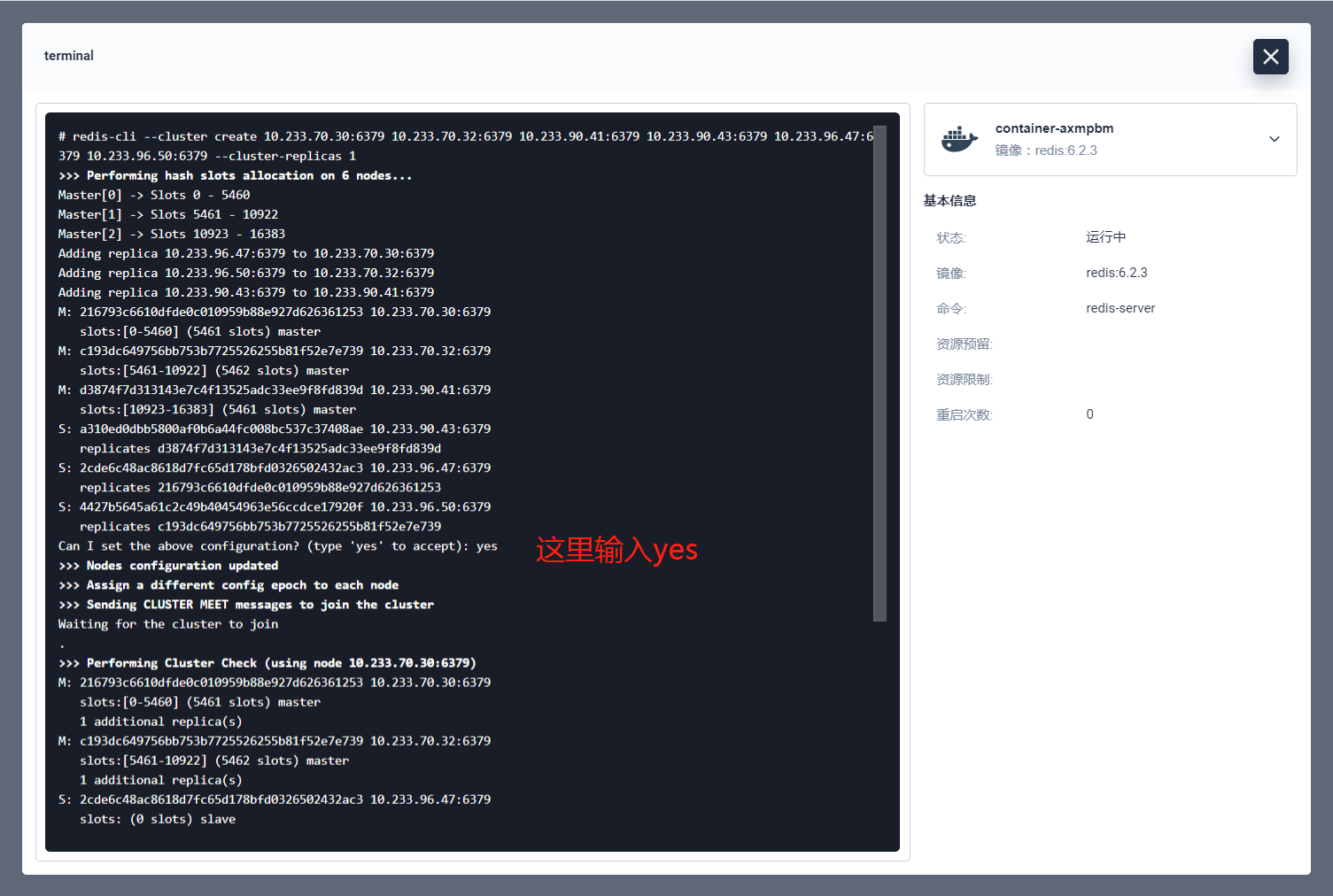
记录 redis 集群的所有 ip+port,初始化命令如下:
redis-cli --cluster create 10.233.70.30:6379 10.233.70.32:6379 10.233.90.41:6379 10.233.90.43:6379 10.233.96.47:6379 10.233.96.50:6379 --cluster-replicas 1
进入 redis 集群随意一个节点的终端执行上面的命令。
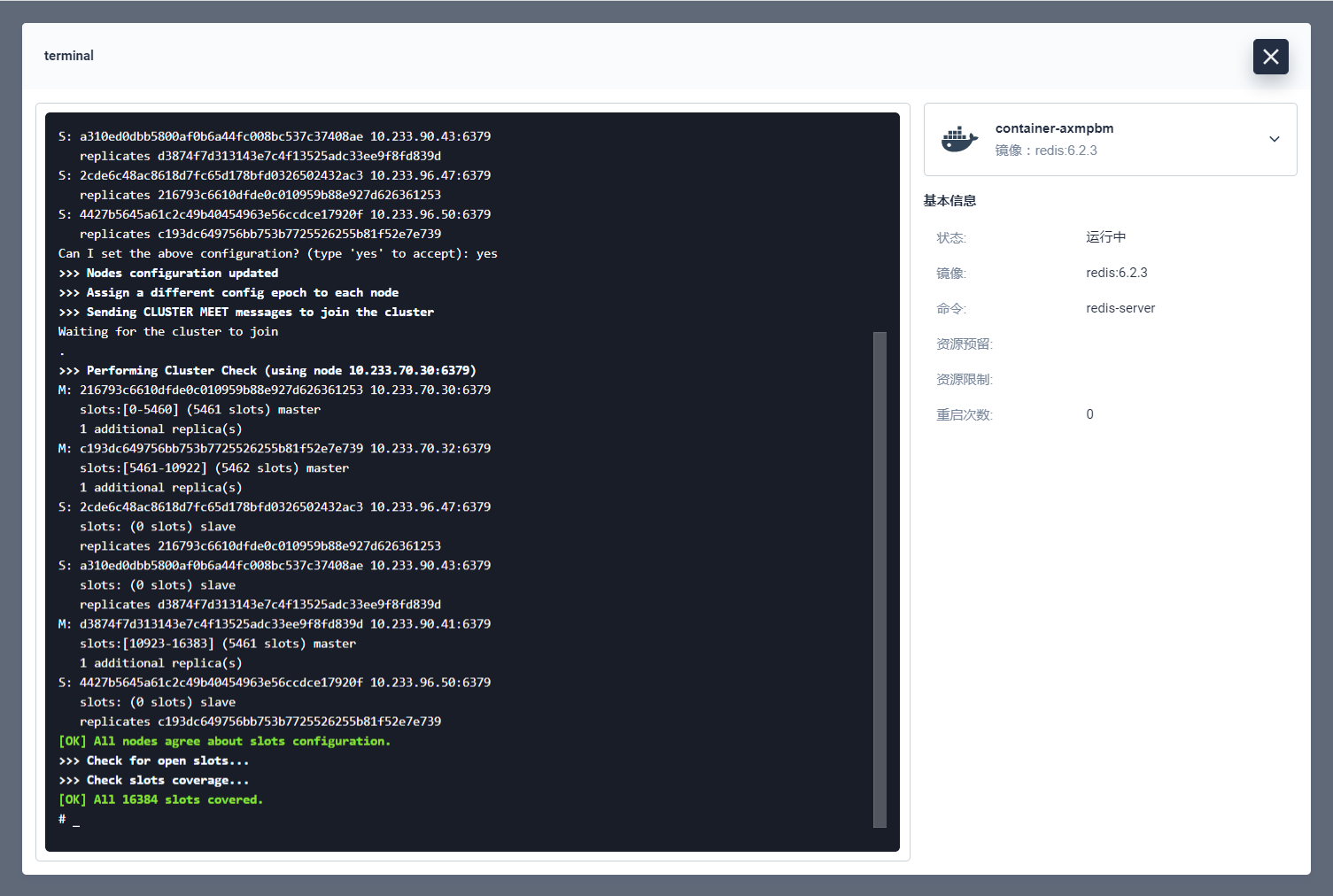
如上图集群初始化就完成了,再输入命令 redis-cli 进入命令端,再执行 cluster info 查看集群信息。

现在我们的集群节点有了 6 个,master 节点也有了三个,集群建立完成,后面的操作选择 master 节点进行操作。
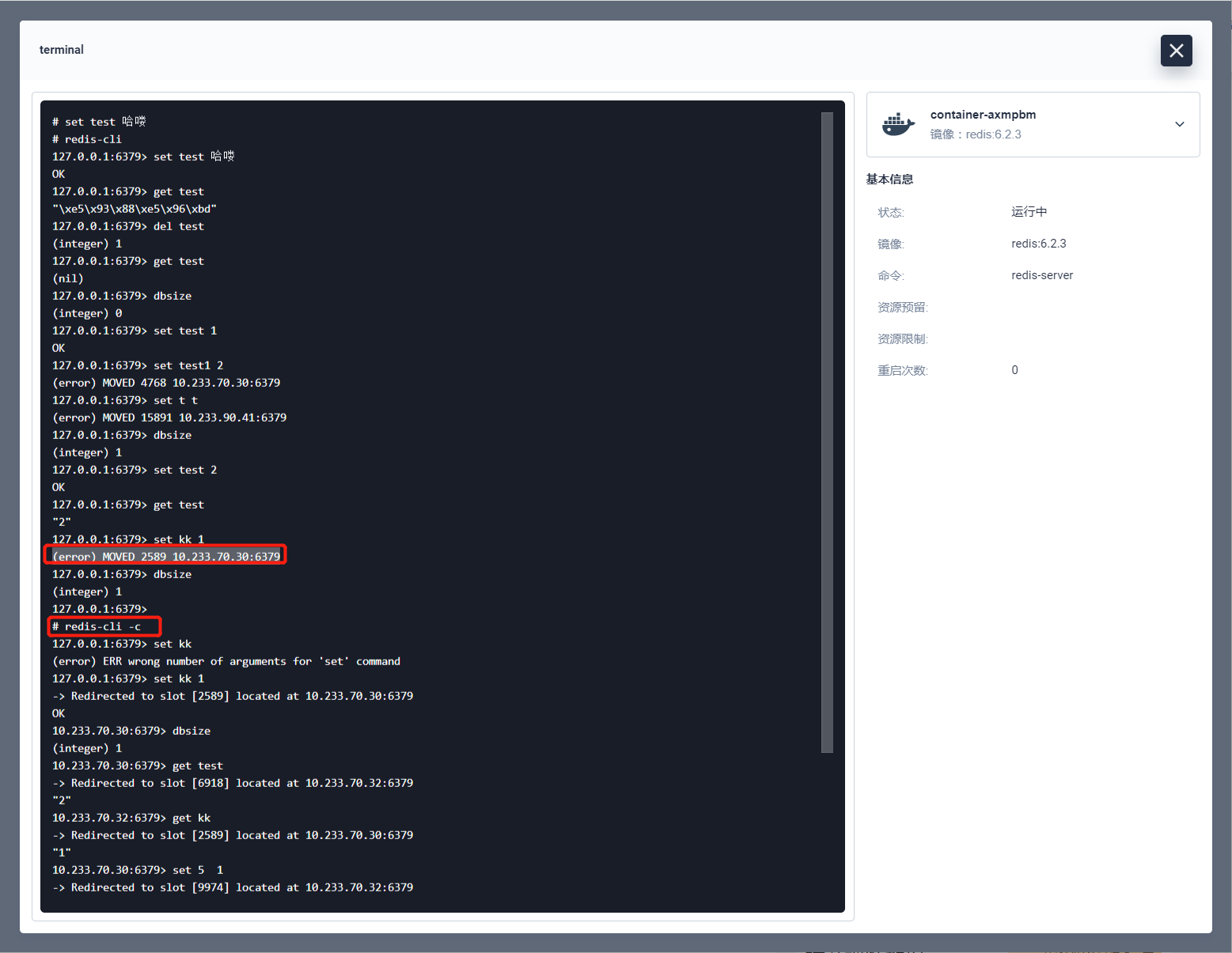
在对集群节点进行验证的时候如果遇到上图的错误 (error) MOVED 2589 10.233.70.30:6379 是因为 redis-cli 没有开启集群模式,将命令修改为 redis-cli -c 就切换为集群模式了。
使用内部 DNS 初始化
使用 ip 地址的方式在每次 K8s 调度 redis 后 ip 都会发生变化,所以在 K8s 集群中使用 ip 方式初始化集群并不太合适,但是如果使用内部 DNS 直接跟上面一样初始化集群会出现错误,因为 redis 对域名的支持并不太好,所以这时候可以用 Redis-tribe。
创建 Redis-tribe 服务
创建自定义服务,选择编辑 YAML。
参数 namespace 就写项目名称:
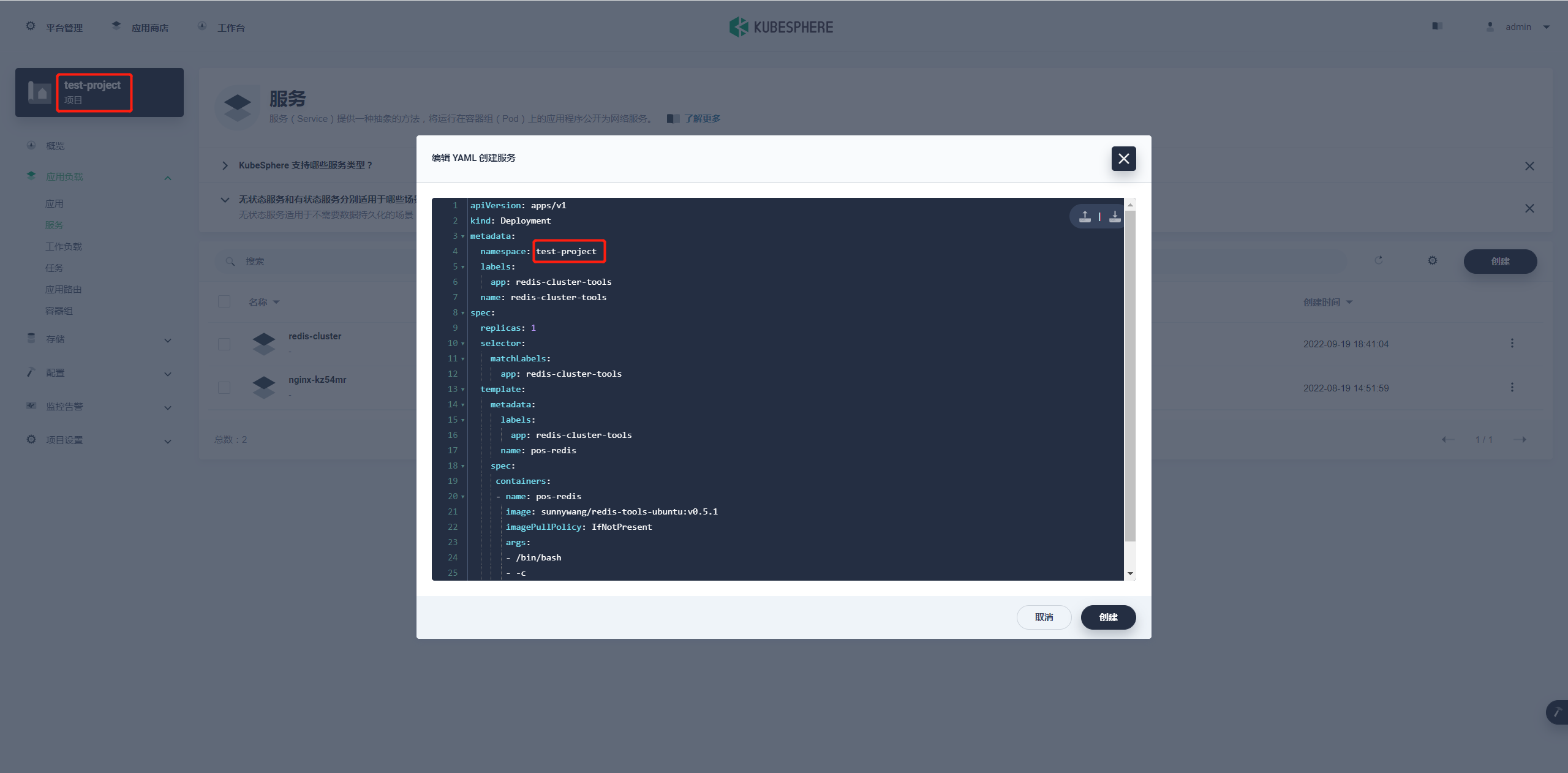
具体 YAML 内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: test-project
labels:
app: redis-cluster-tools
name: redis-cluster-tools
spec:
replicas: 1
selector:
matchLabels:
app: redis-cluster-tools
template:
metadata:
labels:
app: redis-cluster-tools
name: pos-redis
spec:
containers:
- name: pos-redis
image: sunnywang/redis-tools-ubuntu:v0.5.1
imagePullPolicy: IfNotPresent
args:
- /bin/bash
- -c
- sleep 3600
创建好后在容器组内找到 redis-cluster-tools。
初始化集群
点击容器名称进入容器详情再进入到终端里。
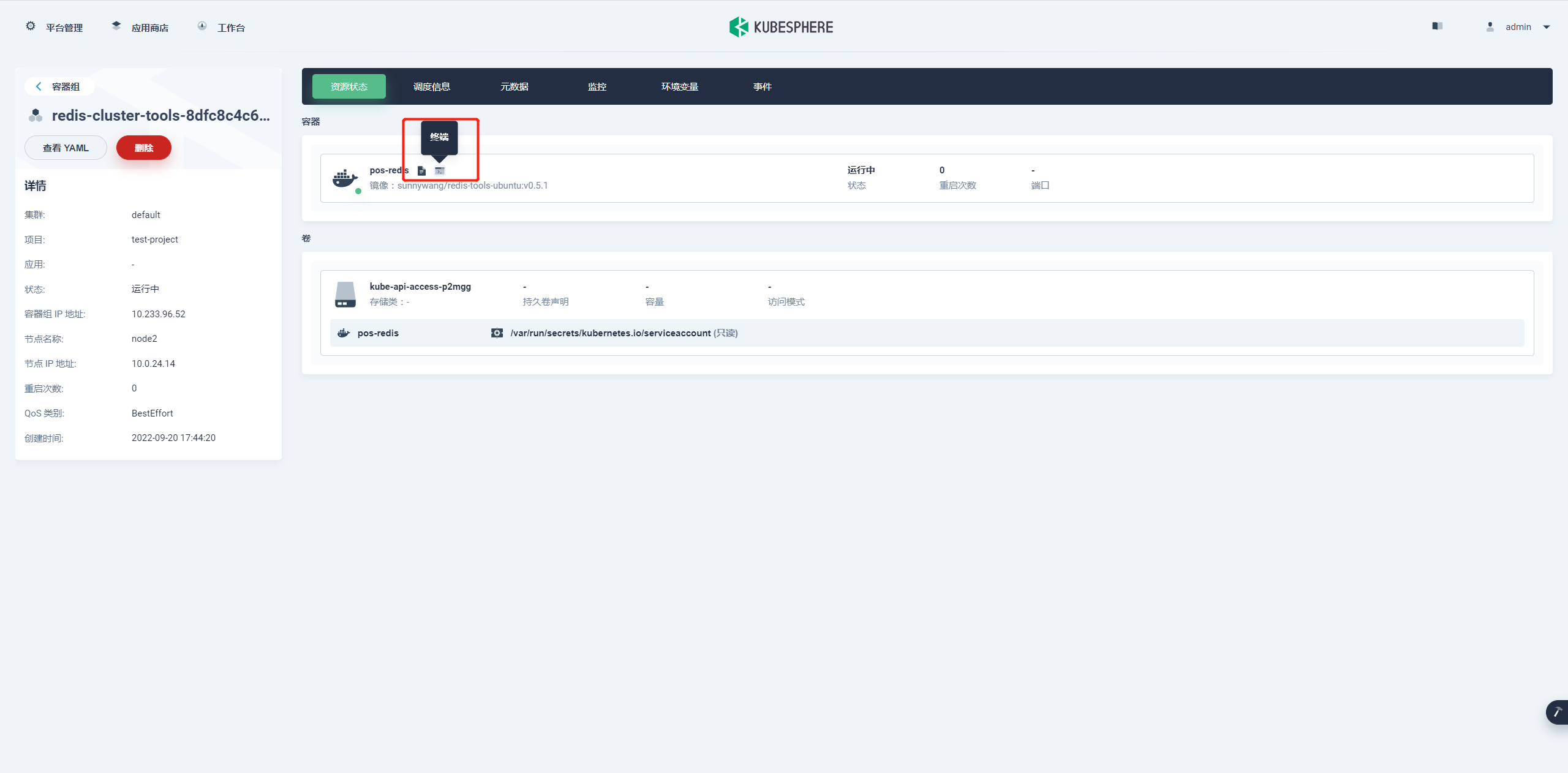
先执行以下命令初始化 master 节点,这时候之前的内部 DNS 的域名就有用了。
redis-trib.py create `dig +short redis-cluster-v1-0.redis-cluster.test-project.svc.cluster.local`:6379 `dig +short redis-cluster-v1-1.redis-cluster.test-project.svc.cluster.local`:6379 `dig +short redis-cluster-v1-2.redis-cluster.test-project.svc.cluster.local`:6379
执行结果如下图:
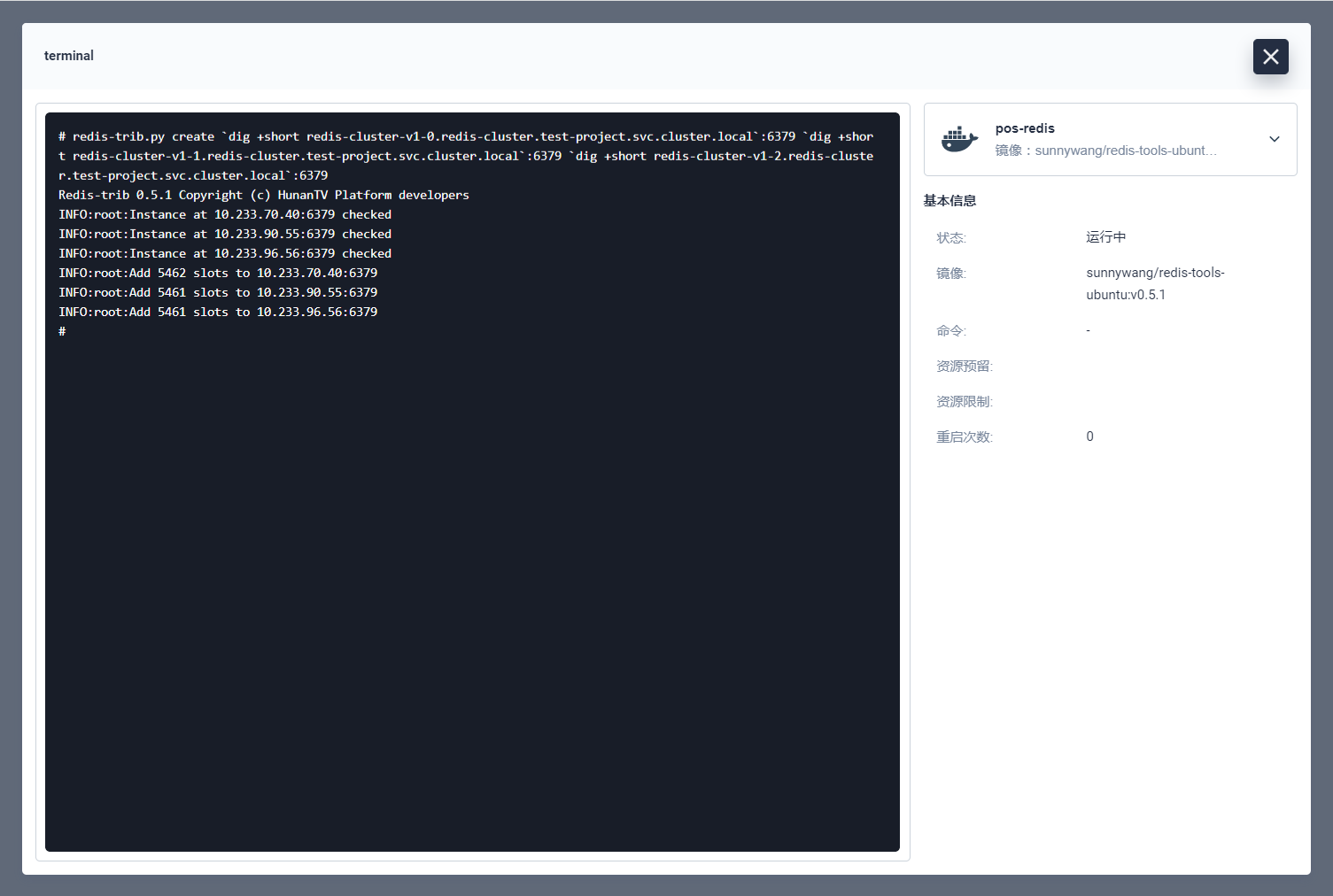
接下来给每个 master 节点绑定对应的副本节点,总共三个:
0 节点->3 节点
redis-trib.py replicate --master-addr `dig +short redis-cluster-v1-0.redis-cluster.test-project.svc.cluster.local`:6379 --slave-addr `dig +short redis-cluster-v1-3.redis-cluster.test-project.svc.cluster.local`:6379
1 节点->4 节点
redis-trib.py replicate --master-addr `dig +short redis-cluster-v1-1.redis-cluster.test-project.svc.cluster.local`:6379 --slave-addr `dig +short redis-cluster-v1-4.redis-cluster.test-project.svc.cluster.local`:6379
2 节点->5 节点
redis-trib.py replicate --master-addr `dig +short redis-cluster-v1-2.redis-cluster.test-project.svc.cluster.local`:6379 --slave-addr `dig +short redis-cluster-v1-5.redis-cluster.test-project.svc.cluster.local`:6379
执行结果如下:
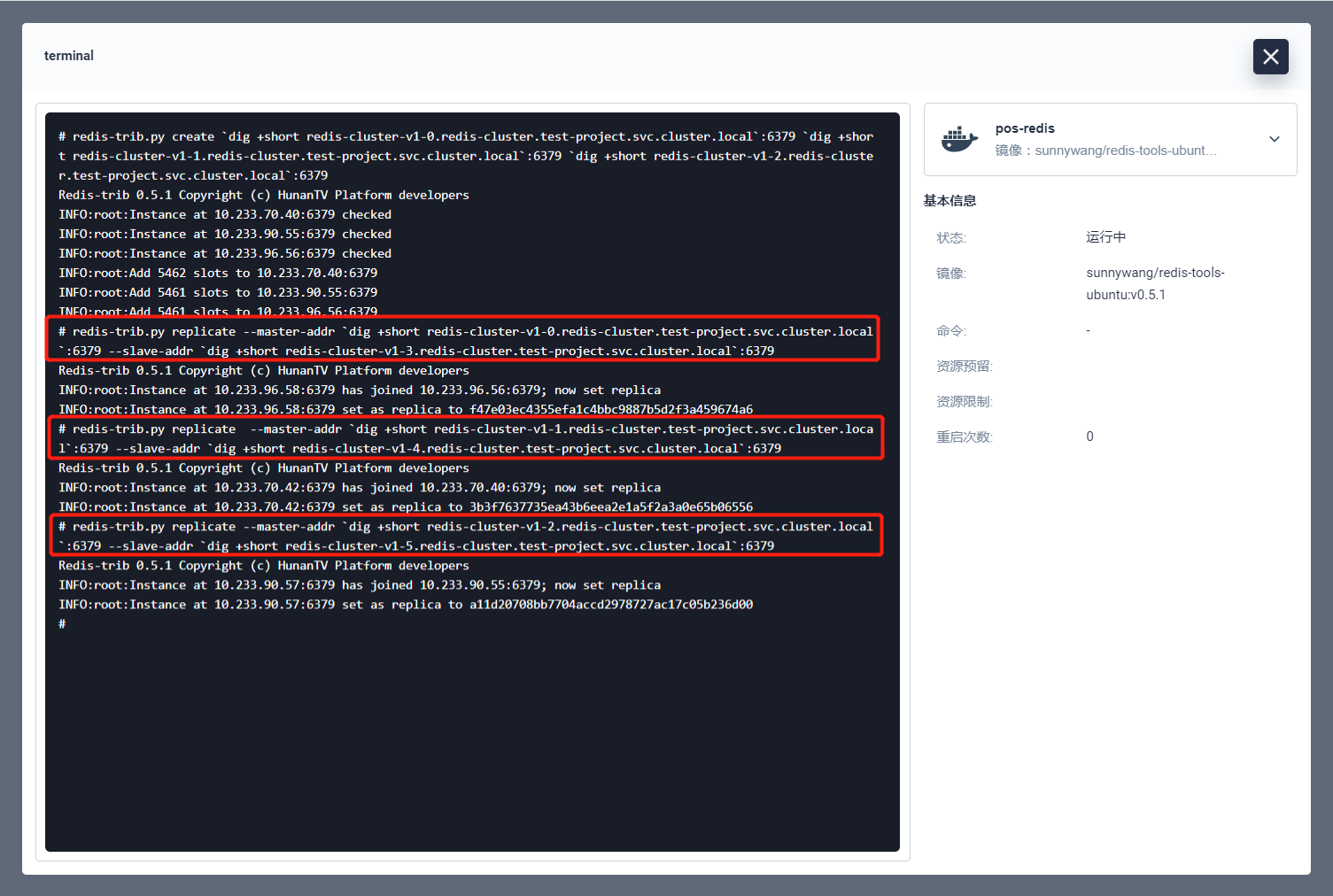
验证
随便进入一个集群节点的终端,还是执行 cluster info 命令,查看集群信息。
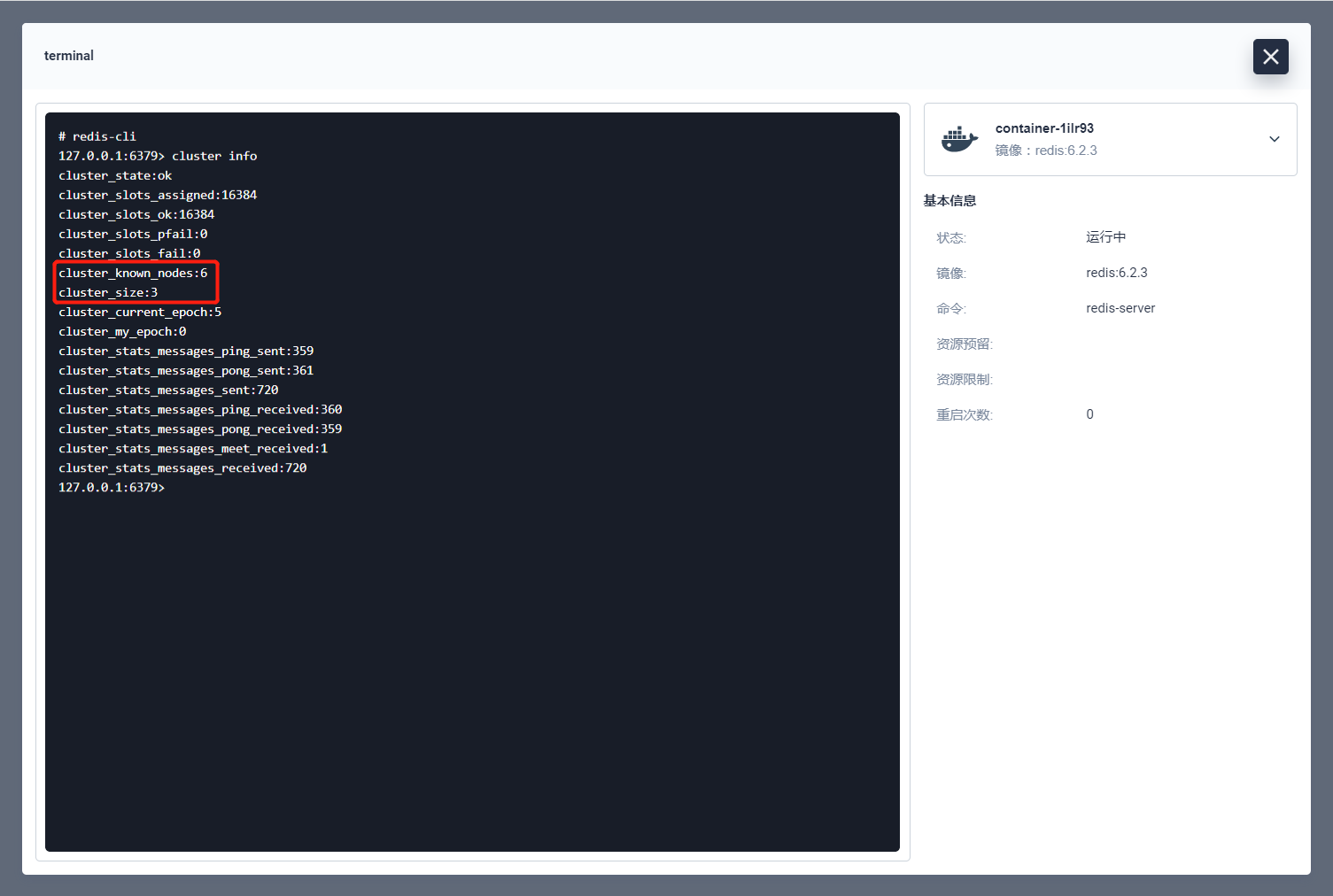
使用基础命令进行验证,验证集群模式的 redis-cli 需要加-c。
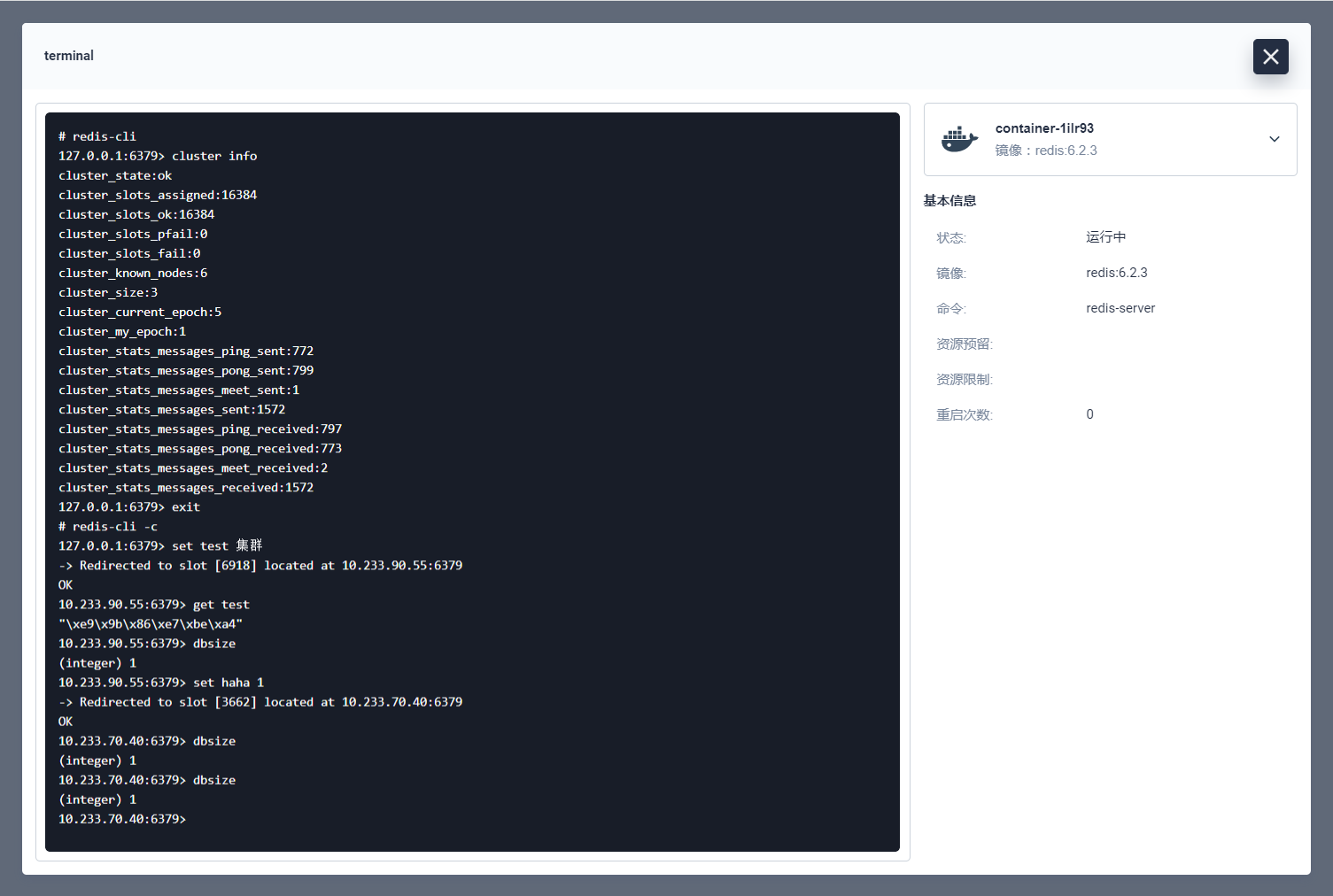
验证集群模式可以正常使用。
本文由博客一文多发平台 OpenWrite 发布!
在 KubeSphere 中部署高可用 Redis 集群的更多相关文章
- 使用Docker Compose部署基于Sentinel的高可用Redis集群
使用Docker Compose部署基于Sentinel的高可用Redis集群 https://yq.aliyun.com/articles/57953 Docker系列之(五):使用Docker C ...
- 基于kubeasz部署高可用k8s集群
在部署高可用k8s之前,我们先来说一说单master架构和多master架构,以及多master架构中各组件工作逻辑 k8s单master架构 提示:这种单master节点的架构,通常只用于测试环境, ...
- 【云原生 · Kubernetes】部署高可用kube-scheduler集群
个人名片: 因为云计算成为了监控工程师 个人博客:念舒_C.ying CSDN主页️:念舒_C.ying 部署高可用kube-scheduler集群 13.1 创建 kube-scheduler 证 ...
- 【云原生 · Kubernetes】部署高可用 kube-controller-manager 集群
个人名片: 因为云计算成为了监控工程师 个人博客:念舒_C.ying CSDN主页️:念舒_C.ying 部署高可用 kube-controller-manager 集群 12.1 创建 kube- ...
- Docker化高可用redis集群
最近遇到部分系统因为redis服务挂掉,导致部分服务不可用.所以希望搭建一个redis集群镜像,把原先散落各处的redis服务器统一管理起来,并且保障高可用和故障自动迁移. 一:redis集群分类 大 ...
- redis高可用 - redis集群
redis-sentinel方案提供了单点的高可用解决方案,但是当数据量和业务量极速增长时,单点的reids不可能无限的纵向扩容(增大内存),这个时候就需要redis有集群的能力来扛. redis集群 ...
- 基于saltstack自动化部署高可用kubernetes集群
SaltStack自动化部署HA-Kubernetes 本项目在GitHub上,会不定期更新,大家也可以提交ISSUE,地址为:https://github.com/skymyyang/salt-k8 ...
- Rancher 2.2.2 - HA 部署高可用k8s集群
对于生产环境,需以高可用的配置安装 Rancher,确保用户始终可以访问 Rancher Server.当安装在Kubernetes集群中时,Rancher将与集群的 etcd 集成,并利用Kuber ...
- kubeadm部署高可用K8S集群(v1.14.2)
1. 简介 测试环境Kubernetes 1.14.2版本高可用搭建文档,搭建方式为kubeadm 2. 服务器版本和架构信息 系统版本:CentOS Linux release 7.6.1810 ( ...
- hype-v上centos7部署高可用kubernetes集群实践
概述 在上一篇中已经实践了 非高可用的bubernetes集群的实践 普通的k8s集群当work node 故障时是高可用的,但是master node故障时将会发生灾难,因为k8s api serv ...
随机推荐
- 给大家降降火 —— AI养殖是否夸大功效 —— 深大学生用AI养乌骨鸡增产6万只
看到一个新闻: 地址: https://export.shobserver.com/baijiahao/html/705726.html 这个新闻里面说的就是这个腾讯的对口培养的大学生搞了一个AI养殖 ...
- 【转载】 取消idea双击shift时出现的全局搜索 (使用pycharm IDE时出现的问题)
原文地址: https://blog.csdn.net/hxy199421/article/details/83030603 最近在使用pycharm的时候出现文章标题的问题,由于以前写的代码都是比较 ...
- OpenAI内讧更多细节曝光:奥特曼离间董事会失败
参考: https://www.thepaper.cn/newsDetail_forward_25512687 ============================== 根据 https://ww ...
- gym库中from gym.wrappers import FlattenObservation的理解
看代码的过程中看到有这样的调用: from gym.wrappers import FlattenObservation if sinstance(env.observation_space, gym ...
- 纪念IE浏览器退役,哈哈哈!!!
网址: https://haokan.baidu.com/v?pd=wisenatural&vid=16024148879625055169 ========================= ...
- 纯css美化滚动条样式
https://www.emperinter.info/2020/09/20/scrollbar-in-browser/ 自己完善自己博客再Ipad等移动端的菜单时选用了左右滑动的菜单模式!当然就会使 ...
- Dapr v1.14 版本已发布
Dapr是一套开源.可移植的事件驱动型运行时,允许开发人员轻松立足云端与边缘位置运行弹性.微服务.无状态以及有状态等应用程序类型.Dapr能够确保开发人员专注于编写业务逻辑,而不必分神于解决分布式系统 ...
- Go plan9 汇编:手写汇编
原创文章,欢迎转载,转载请注明出处,谢谢. 0. 前言 在 Go plan9 汇编: 打通应用到底层的任督二脉 一文中介绍了从应用程序到汇编指令的转换.本文将结合汇编和 Go 程序实现手写基本的汇编指 ...
- DB\redis\zookeeper分布式锁设计
redis 参考目录: 生产级Redis 高并发分布式锁实战1:高并发分布式锁如何实现 https://www.cnblogs.com/yizhiamumu/p/16556153.html 生产级Re ...
- 后缀数组,SA
主要是 \(O(n\log n)\) 倍增求 SA. (为什么这么短) const int N = 1e6 + 9; int n; int sa[N], sa_tmp[N], rk[N], ork[N ...