DQN(Deep Reiforcement Learning) 发展历程(三)
不基于模型(Model-free)的预测
- 无法事先了解状态转移的概率矩阵
蒙特卡罗方法
从开始状态开始,到终结状态,找到一条完整的状态序列,以求解每个状态的值。相比于在整个的状态空间搜索,是一种采样的方法。
- 对于某一状态在同一状态序列中重复出现的,有以下两种方法:
- 只选择第一个状态进行求解,忽略之后的所有相同状态
- 考虑所有的状态,求平均值
- 对于求解每个状态的值,使用平均值代表状态值,根据大数定理,状态数足够多的条件下,该平均值等于状态值。平均值求解有两种方法:
- 存储所有状态后求平均:消耗大量存储空间
- 每次迭代状态都更新当前平均值:
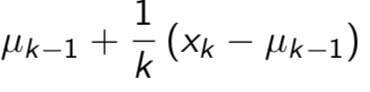
时序差分方法
- 蒙特卡罗方法需要获得从开始到终结的一条完整的状态序列,以求解每个状态的值,时序差分方法则不需要。根据贝尔曼不等式,只需要从当前状态到下一状态求解。
- 时序差分方法每步都更新状态值,而蒙特卡罗方法需要等到所有状态结束才更新。
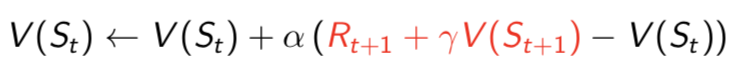
- 蒙特卡罗方法使用最后的目标来求解状态值,而时序差分使用下一状态的估计在每一步调整状态值。
- 蒙特卡罗方法是无偏估计方差较大,时序差分则是有篇估计但估计方差小。
多步的时序差分方法
- 时序差分方法使用当前状态值和下一状态值更新当前状态值,如果使用当前状态值和之后多步的状态值更新当前状态值,就是多步的时序差分方法。
- 当步数到最后的终结状态时,便是蒙特卡罗方法。
- 当步数到下一状态时,便是时序差分方法。
- 多步的时序差分方法,分为前向和后向的时序差分方法。
参考
david siver 课程
https://home.cnblogs.com/u/pinard/
DQN(Deep Reiforcement Learning) 发展历程(三)的更多相关文章
- DQN(Deep Reiforcement Learning) 发展历程(五)
目录 值函数的近似 DQN Nature DQN DDQN Prioritized Replay DQN Dueling DQN 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) ...
- DQN(Deep Reiforcement Learning) 发展历程(四)
目录 不基于模型的控制 选取动作的方法 在策略上的学习(on-policy) 不在策略上的学习(off-policy) 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发 ...
- DQN(Deep Reiforcement Learning) 发展历程(二)
目录 动态规划 使用条件 分类 求解方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展历程(五) 动态规划 动态规划给出了求解强化学习的一种 ...
- DQN(Deep Reiforcement Learning) 发展历程(一)
目录 马尔可夫理论 马尔可夫性质 马尔可夫过程(MP) 马尔可夫奖励过程(MRP) 值函数(value function) MRP求解 马尔可夫决策过程(MDP) 效用函数 优化的值函数 贝尔曼等式 ...
- Deep Reinforcement Learning 基础知识(DQN方面)
Introduction 深度增强学习Deep Reinforcement Learning是将深度学习与增强学习结合起来从而实现从Perception感知到Action动作的端对端学习的一种全新的算 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- C#与C++的发展历程第三 - C#5.0异步编程巅峰
系列文章目录 1. C#与C++的发展历程第一 - 由C#3.0起 2. C#与C++的发展历程第二 - C#4.0再接再厉 3. C#与C++的发展历程第三 - C#5.0异步编程的巅峰 C#5.0 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- Deep Reinforcement Learning: Pong from Pixels
这是一篇迟来很久的关于增强学习(Reinforcement Learning, RL)博文.增强学习最近非常火!你一定有所了解,现在的计算机能不但能够被全自动地训练去玩儿ATARI(译注:一种游戏机) ...
随机推荐
- 使用PHPExcel实现数据批量导出为excel表格
首先需要下载PHPExecel类文件,帮助文档可以参考PHPExcel中文帮助手册|PHPExcel使用方法. 下面直接上例子,是我自己写的一个简单的批量导出数据为excel的例子 前台页面 比较简单 ...
- 为JavaScript正名--读你不知道的JavaScript(持续更新..)
你不知道的JavaScript上卷 JavaScript和Java的关系就像Carnival和Car的关系一样,八竿子打不着. JavaScript易上手,但由于其本身的特殊性,相比其他语言能真正掌握 ...
- ArcGIS JavaScript API 4.x中热度图渲染的使用注意事项
要使用ArcGIS JavaScript API 4.x的热度图渲染器来渲染要素图层,需要注意几点前提条件: 1.需要使用ArcGIS Server 10.6.1或更高版本发布GIS服务. 2.只支持 ...
- 使用thumbnailator不按照比例,改变图片的大小
我们在平时的开发中,偶尔也会遇到图片处理的问题,比如图片的压缩,按比例改变图片的大小,不按比例改变图片的大小等等. 如果要自己去开发这样一套工具,我觉得大多数人都是做不到的,所以还是学会站在巨人的肩膀 ...
- python 实现线程安全的单例模式
单例模式是一种常见的设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场. 比如,服务器的配置信息写在一个文件中online. ...
- spring boot(18)-servlet、filter、listener
servlet.filter.listener的用法就不讲了,只讲如何在spring boot中配置它们.有两种方式,一种是从servlet3开始提供的注解方式,另一种是spring的注入方式 ser ...
- 【SPL标准库专题(5)】 Datastructures:SplStack & SplQueue
这两个类都是继承自SplDoublyLinkedList,分别派生自SplDoublyLinkedList的堆栈模式和队列模式:所以放在一起来介绍: 堆栈SplStack # 类摘要 SplStack ...
- LevelDB源码分析--Cache及Get查找流程
本打算接下来分析version相关的概念,但是在准备的过程中看到了VersionSet的table_cache_这个变量才想起还有这样一个模块尚未分析,经过权衡觉得leveldb的version相对C ...
- 为何SQL SERVER使用sa账号登录还原数据库BAK文件失败,但是使用windows登录就可以
今天发现一个问题,就是公司开发服务器上的sql server使用sa账号登录后,还原一个数据库bak文件老是报错,错误如下: TITLE: Microsoft SQL Server Managemen ...
- 表迁移工具的选型-复制ibd的方法-传输表空间
1.1. 场景 有的时候开放人员自己的库需要帮忙导一些数据,但是表的数据量又很大.虽然说使用mysqldump或mysqlpump也可以导.但是这耗时需要比较久. 记得之前建议开放人员可以直接使用na ...