利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中
我们先来看一下通过浏览器的方式来筛选某些特定的电影:

我们把URL来复制出来分析分析:
https://movie.douban.com/tag/#/?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD,%E9%BB%91%E5%B8%AE
有3个字段是非常重要的:
1.sort=T
2.range=0,10
3.tags=%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD,%E9%BB%91%E5%B8%AE
具体分析方法如下:
1.sort:表示排序方式,可以看到它有3中排序方式
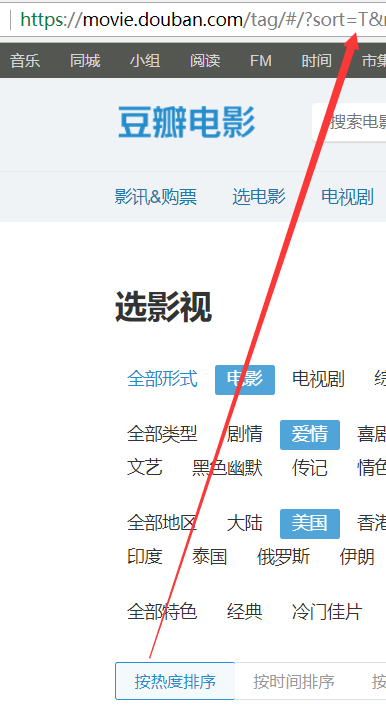

根据上图可以直到每个字母表示的含义:
T:热度排序,
R:时间排序,
S:评价排序:
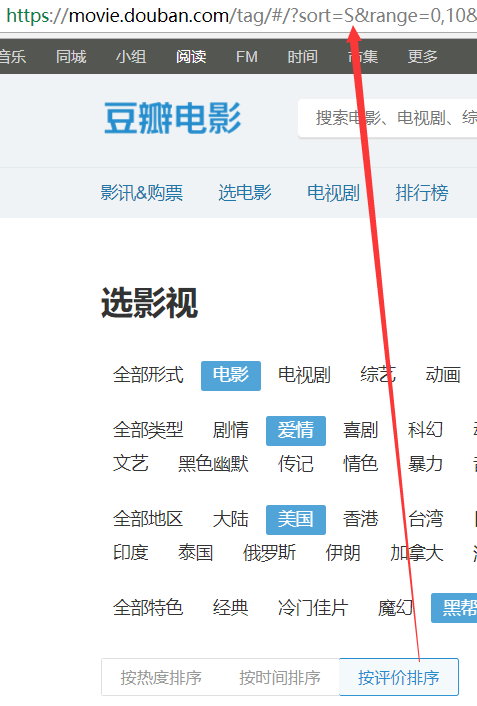
2.range=0,10;表示一个范围,具体是什么范围呢?
range参数我们也搞定了,它就是表示评分区间!
默认评分区间是:0-10
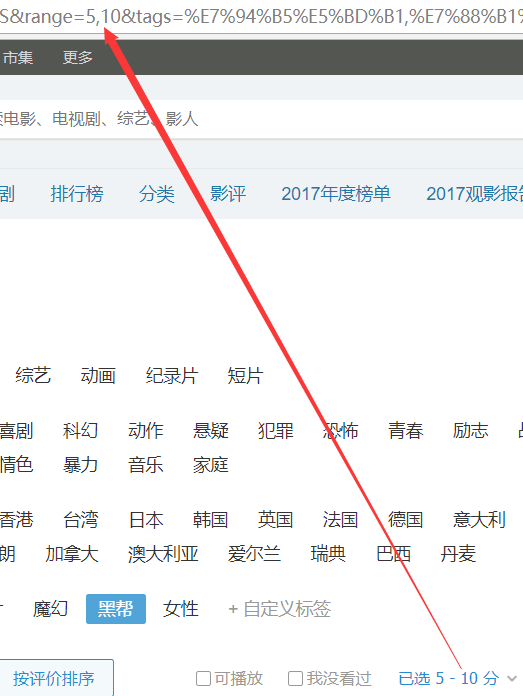
3.tags:同样的原理,这是一个标签
我们选中的标签有:电影,爱情,美国,黑帮4个标签,但是在tags里面我们看到的不是这写汉字,而是被编码过的形式!
%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD,%E9%BB%91%E5%B8%AE)
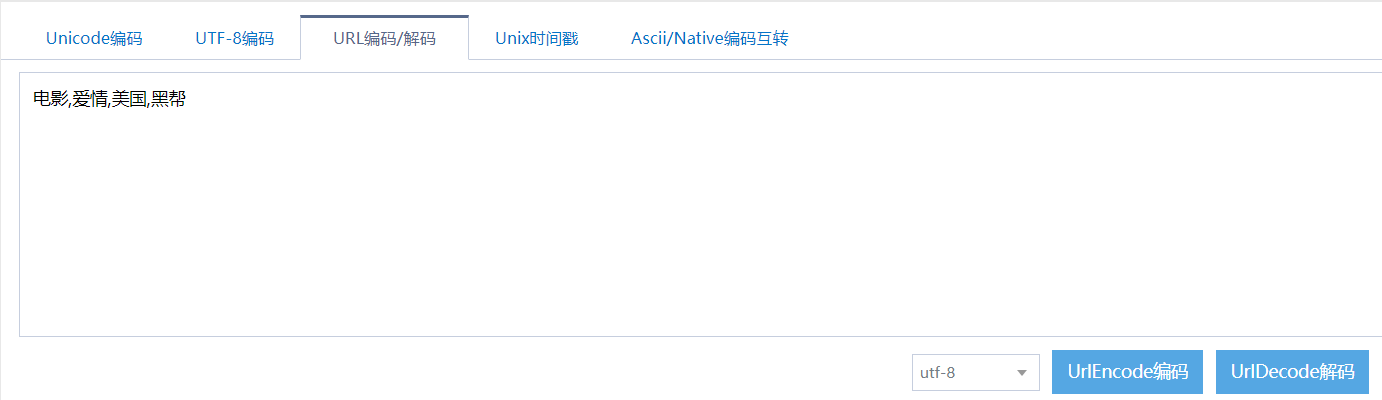
那如何知道这些字符是表示什么呢?
我们可以到网上进行解码看看正不正确?

4.那么还有没有可以选择的参数呢?
我们还有2个参数可以选择!
playbale=1:表示可播放
unwatched=1:表示还没看过的
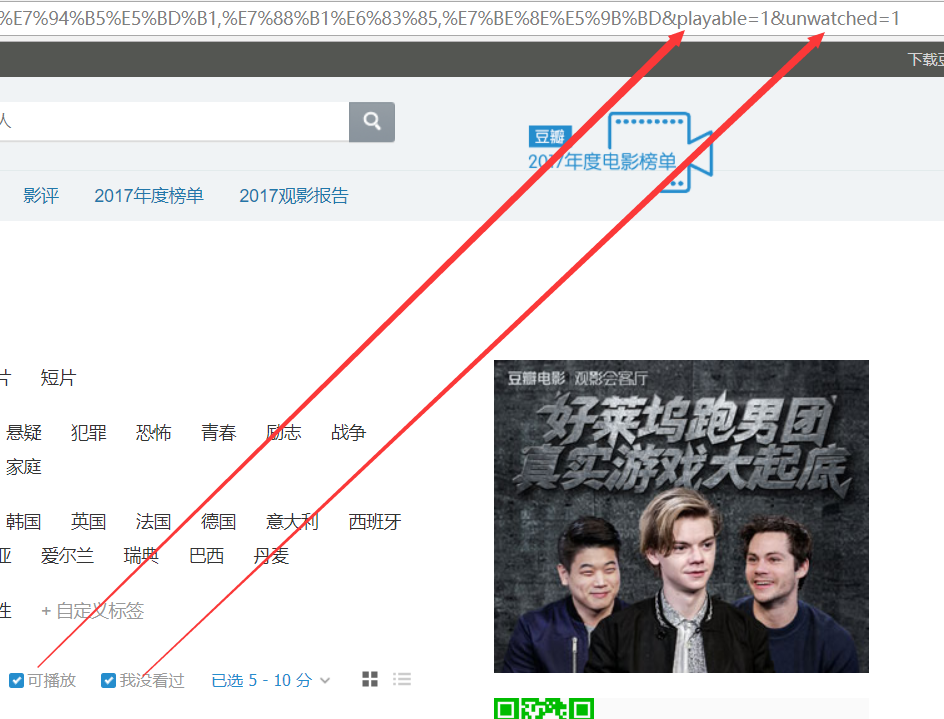
至此,我们就已经把URL中的查询参数全都弄明白了!
但是,又有一个问题了,当我们在浏览器中点击"加载更多"按钮时,这个地址栏中的URL并没有发生变化,但是电影信息可以加载出来了!这是为什么?
如果知道AJAX加载技术的读者可能知道这个原理,实际上就是异步加载,服务器不需要刷新整个网页,只需要刷新局部网页就可以把数据展示到网页中,这样不仅可以加快速度,也可以减少服务器的压力.
重点来了:
抓包结果:
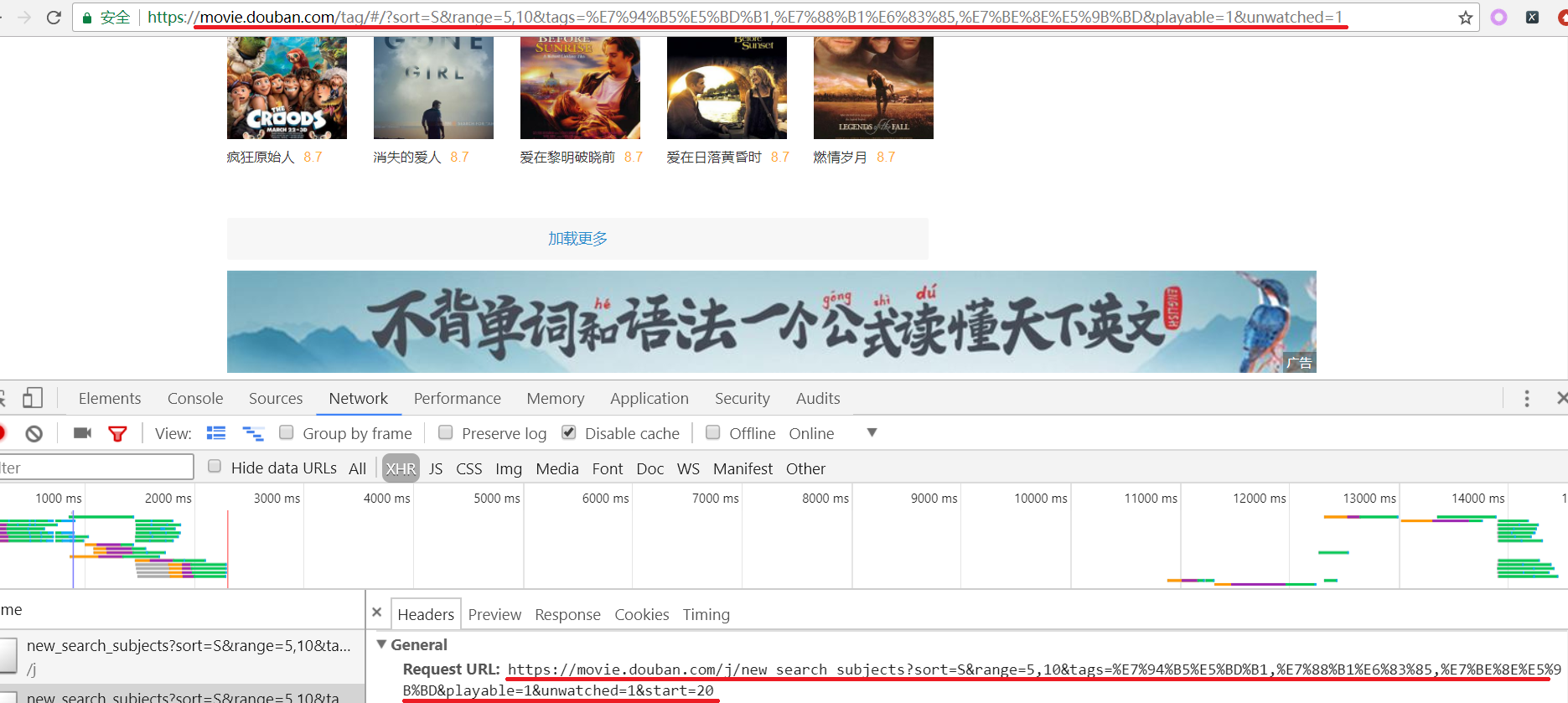
看看浏览器地址栏的URL与Request URL有什么不一样的地方?
我们在浏览器地址栏中看到的URL是:
https://movie.douban.com/tag/#/?
sort=S&range=5,10&tags=%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD&playable=1&unwatched=1
实际浏览器发送的Request URL是:
https://movie.douban.com/j/new_search_subjects?
sort=S&range=5,10&tags=%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD&playable=1&unwatched=1&start=0
除了被红色标记的地方不同之外,其他地方都是一样的!那我们发送请求的时候应该是用哪一个URL呢?
在上面我就已提到了,在豆瓣电影中,是采用异步加载的方式来加载数据的,也就是说在加载数据的过程中,地址栏中的URL是一直保持不变的,那我们还能用这个URL来发送请求吗?当然不能了!
既然不能用地址栏中的URL来发送请求,那我们就来分析一下浏览器实际发送的Request URL:
我们把这个URL复制到浏览器中看看会发生什么情况!

我们可以看到这个URL的响应结果恰恰就是我们想要的数据,采用json格式.在Python中,我们可以利用一些工具把它转换成字典格式,来提取我们想要的数据.
距离我们成功还有一小步:
在这个URL中,我们看到还有一个参数:start,这个是干嘛的呢?
这个数值表示偏移量,来控制每一次加载的偏移位置是在哪里!比如我们把它设置成20,表示一次请求的电影数量.那么得到的结果如下:

到这里,该案例的思路,难点就已经全都捋清楚了,剩下的就是代码的事情了!
项目结构:
完整的代码如下:
settings.py
User_Agents =[
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
]
mongoHelper.py
import pymongo class MongoDBHelper:
"""数据库操作""" def __init__(self, collection_name=None):
# 启动mongo
self._client = pymongo.MongoClient('localhost', 27017)
# 使用test数据库
self._test = self._client['test']
# 创建指定的集合
self._name = self._test[collection_name] def insert_item(self, item):
"""插入数据"""
self._name.insert_one(item) def find_item(self):
"""查询数据"""
data = self._name.find()
return data def main():
mongo = MongoDBHelper('collection')
mongo.insert_item({'a': 1}) if __name__ == '__main__':
main()
douban.py
import logging
import random
import string
import requests
import time
from collections import deque
from urllib import parse from settings import User_Agents
from MongDBHelper import MongoDBHelper class DoubanSpider(object):
"""豆瓣爬虫"""
def __init__(self):
# 基本的URL
self.base_url = 'https://movie.douban.com/j/new_search_subjects?'
self.full_url = self.base_url + '{query_params}'
# 从User-Agents中选择一个User-Agent
self.headers = {'User-Agent': random.choice(User_Agents)}
# 影视形式(电影, 电视剧,综艺)
self.form_tag = None # 类型
self.type_tag = None # 地区
self.countries_tag = None # 特色
self.genres_tag = None
self.sort = 'T' # 排序方式,默认是T,表示热度
self.range = 0, 10 # 评分范围
self.playable = ''
self.unwatched = ''
# 连接数据库,集合名为douban_movies
self.db = MongoDBHelper('douban_movies') def get_query_parameter(self):
"""获取用户输入信息"""
# 获取tags参数
self.form_tag = input('请输入你想看的影视形式(电影|电视剧|综艺...):')
self.type_tag = input('请输入你想看的影视类型(剧情|爱情|喜剧|科幻...):')
self.countries_tag = input('请输入你想看的影视地区(大陆|美国|香港...):')
self.genres_tag = input('请输入你想看的影视特色(经典|冷门佳片|黑帮...):') def get_default_query_parameter(self):
"""获取默认的查询参数"""
# 获取 sort, range, playable, unwatched参数
self.range = input('请输入评分范围[0-10]:')
self.sort = input('请输入排序顺序(热度:T, 时间:R, 评价:S),三选一:').upper()
self.playable = input('请选择是否可播放(默认不可播放):')
self.unwatched = input('请选择是否为我没看过(默认是没看过):') def encode_query_data(self):
"""对输入信息进行编码处理"""
if not (self.form_tag and self.type_tag and self.countries_tag and self.genres_tag):
all_tags = ''
else:
all_tags = [self.form_tag, self.type_tag, self.countries_tag, self.genres_tag]
query_param = {
'sort': self.sort,
'range': self.range,
'tags': all_tags,
'playable': self.playable,
'unwatched': self.unwatched,
} # string.printable:表示ASCII字符就不用编码了
query_params = parse.urlencode(query_param, safe=string.printable)
# 去除查询参数中无效的字符
invalid_chars = ['(', ')', '[', ']', '+', '\'']
for char in invalid_chars:
if char in query_params:
query_params = query_params.replace(char, '')
# 把查询参数和base_url组合起来形成完整的url
self.full_url = self.full_url.format(query_params=query_params) + '&start={start}' def download_movies(self, offset):
"""下载电影信息
:param offset: 控制一次请求的影视数量
:return resp:请求得到的响应体"""
full_url = self.full_url.format(start=offset)
resp = None
try:
resp = requests.get(full_url, headers=self.headers)
except Exception as e:
# print(resp)
logging.error(e)
return resp def get_movies(self, resp):
"""获取电影信息
:param resp: 响应体
:return movies:爬取到的电影信息"""
if resp:
if resp.status_code == 200:
# 获取响应文件中的电影数据
movies = dict(resp.json()).get('data')
if movies:
# 获取到电影了,
print(movies)
return movies
else:
# 响应结果中没有电影了!
# print('已超出范围!')
return None
else:
# 没有获取到电影信息
return None def save_movies(self, movies, id):
"""把请求到的电影保存到数据库中
:param movies:提取到的电影信息
:param id: 记录每部电影
"""
if not movies:
print('save_movies() error: movies为None!!!')
return all_movies = self.find_movies()
if len(all_movies) == 0:
# 数据库中还没有数据,
for movie in movies:
id += 1
movie['_id'] = id
self.db.insert_item(movie)
else:
# 保存已经存在数据库中的电影标题
titles = []
for existed_movie in all_movies:
# 获取数据库中的电影标题
titles.append(existed_movie.get('title')) for movie in movies:
# 判断数据库中是否已经存在该电影了
if movie.get('title') not in titles:
id += 1
movie['_id'] = id
# 如果不存在,那就进行插入操作
self.db.insert_item(movie)
else:
print('save_movies():该电影"{}"已经在数据库了!!!'.format(movie.get('title'))) def find_movies(self):
"""查询数据库中所有的电影数目
:return: 返回数据库中所有的电影
"""
all_movies = deque()
data = self.db.find_item()
for item in data:
all_movies.append(item)
return all_movies def main():
"""豆瓣电影爬虫程序入口"""
# 1. 初始化工作,设置请求头等
spider = DoubanSpider()
# 2. 与用户交互,获取用户输入的信息
spider.get_query_parameter()
ret = input('是否需要设置排序方式,评分范围...(Y/N):')
if ret.lower() == 'y':
spider.get_default_query_parameter()
# 3. 对信息进行编码处理,组合成有效的URL
spider.encode_query_data()
id = offset = 0
while True:
# 4. 下载影视信息
reps = spider.download_movies(offset)
# 5.提取下载的信息
movies = spider.get_movies(reps)
# 6. 保存数据到MongoDB数据库
# spider.save_movies(movies, id)
offset += 20
id = offset
# 控制访问速速
time.sleep(5) if __name__ == '__main__':
main()
小结:在本次案例中,主要的难点有:查询参数的组合那部分和了解异步加载的原理从而找到真正的URL!查询参数的设置主要用到urlencode()方法,当我们不要把ASCII字符编码的时候,我们要设置safe参数为string.printable,这样只要把一些非ASCII字符编码就好了,同样quote()也是用来编码的,也有safe参数;那么本例中为什么要使用urlencode()方法呢?主要是通过观察URL是key=value的形式,所以才选用它!当我们把数据插入到数据库中时,如果是有相同的名字的电影,我们就不插入,这样也是处于对性能的考虑,合理利用资源!
利用Python爬取豆瓣电影的更多相关文章
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- Python 爬取豆瓣电影Top250排行榜,爬虫初试
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # ...
- 《团队-Python 爬取豆瓣电影top250-成员简介及分工》
杨继尧,没有什么擅长的,会一点python,一点c#,爬取利用数据库,有些用法不太会,但是会在实现项目中查资料.
- 利用selenium爬取豆瓣电影Top250
这几天在学习selenium,顺便用selenium + python写了一个比较简陋的爬虫,现附上源码,有时间再补充补充: from selenium import webdriver from s ...
随机推荐
- 撩课-Web大前端每天5道面试题-Day32
1.module.export.import是什么,有什么作用? module.export.import是ES6用来统一前端模块化方案的设计思路和实现方案. export.import的出现统一了前 ...
- Django REST framework基础:版本、认证、权限、限制
1 认证.权限和限制 2 认证 2.1 自定义Token认证 2.1.1 表 2.1.2 定义一个登录视图: 2.1.3 定义一个认证类 2.1.4 视图级别认证 2.1.5 全局级别 ...
- 用node.js模拟服务器和客户端
服务器 代码 var net = require("net") var server = net.createServer(); server.listen(12306," ...
- SQLServer 学习笔记之超详细基础SQL语句 Part 12(The End)
Sqlserver 学习笔记 by:授客 QQ:1033553122 -----------------------接Part 11------------------- 现在,我们希望从 " ...
- LeetCode题解之Copy List with Random Pointer
1.题目描述 2.问题分析 首先要完成一个普通的单链表的深度复制,然后将一个旧的单链表和新的单链表的节点使用map对应起来,最后,做一次遍历即可. 3.代码 RandomListNode *copyR ...
- centos7安装mysql5.7修改设置密码策略
centos7操作系统在安装mysql5.7社区版之后会有默认密码,通过grep命令在mysqld.log文件中即可找到,如下所示: 标识位置即在初始化安装时mysql的默认密码,然后通过mysql ...
- IE中操作粘贴板复制和粘贴
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- quarz时间配置
Cron表达式的格式:秒 分 时 日 月 周 年(可选). 字段名 允许的值 允许的特殊字符 秒 ...
- 插入图片新方式:data:image
我们在使用<img>标签和给元素添加背景图片时,不一定要使用外部的图片地址,也可以直接把图片数据定义在页面上.对于一些“小”的数据,可以在网页中直接嵌入,而不是从外部文件载入. 如何使用 ...
- centos7 安装ldap
ldap首先我们要知道这个ldap的概念, LDAP是轻量目录访问协议(Lightweight Directory Access Protocol)的缩写 目录是一个为查询.浏览和搜索而优化的专业分布 ...