Spark 分布式调试工具
0. 说明
编写工具类,考察 Spark 分布式程序的执行地点
1. 工具类编写
[ JMX ]
Java Management Extend , Java 管理扩展服务。
主要用于运维和监控。
【测试 JMX】
开启 nc,参考 [Linux] nc
nc -lk 8888
通过 Client 模式运行 Spark
spark-shell --master spark://s101:7077 --deploy-mode client
在 Spark Shell 下通过 :paste 执行以下代码
def sendInfo(obj:Object ,m:String , param:String)= {
val ip = java.net.InetAddress.getLocalHost.getHostAddress
val pid = java.lang.management.ManagementFactory.getRuntimeMXBean.getName.split("@")(0)
val tname = Thread.currentThread().getName
val classname = obj.getClass.getSimpleName
val objHash = obj.hashCode()
val info = ip + "/" + pid + "/" + tname + "/" + classname + "@" + objHash + "/" + m + "("+param+")" + "\r\n"
//发送数据给nc 服务器
val sock = new java.net.Socket("s101" , 8888)
val out = sock.getOutputStream
out.write(info.getBytes())
out.flush()
out.close()
}
再执行以下命令
sendInfo(this, "method001" , "argument001")
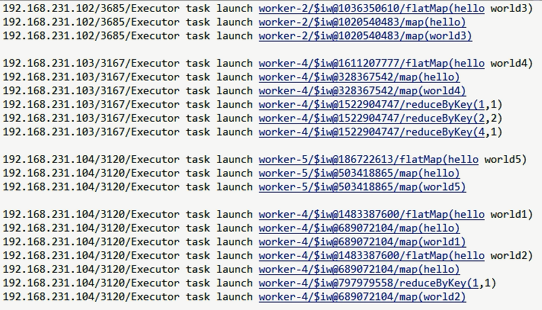
在 nc 端监听到的数据如下

IP 进程id 线程 对象id 方法(参数 )
2. WordCount
通过 Client 模式运行 Spark
spark-shell --master spark://s101:7077 --deploy-mode client
在 Spark Shell 下通过 :paste 执行以下代码
val rdd1 = sc.textFile("/user/centos/data/11.txt" , 4)
val rdd2 = rdd1.flatMap(line=>{
sendInfo(this , "flatMap" , line)
line.split(" ")}
)
val rdd3 = rdd2.map(word=>{
sendInfo(this , "map" , word)
(word,1)
})
val rdd4 = rdd3.reduceByKey((a,b)=>{
sendInfo(this, "reduceByKey", a + "," + b)
a + b
})
val arr = rdd4.collect()
nc 监听到的数据(参考 [Linux] nc)
Spark 分布式调试工具的更多相关文章
- 深度剖析Spark分布式执行原理
让代码分布式运行是所有分布式计算框架需要解决的最基本的问题. Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有很多,但是介绍Spark如 ...
- Spark分布式执行原理
Spark分布式执行原理 让代码分布式运行是所有分布式计算框架需要解决的最基本的问题. Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有 ...
- Spark 分布式环境--连接独立集群管理器
Spark 分布式环境:master,worker 节点都配置好的情况下 : 却无法通过spark-shell连接到 独立集群管理器 spark-shell --master spark://soyo ...
- Spark分布式编程之全局变量专题【共享变量】
转载自:http://www.aboutyun.com/thread-19652-1-1.html 问题导读 1.spark共享变量的作用是什么?2.什么情况下使用共享变量?3.如何在程序中使用共享变 ...
- Spark 分布式SQL引擎
SparkSQL作为分布式查询引擎:两种方式 SparkSQL作为分布式查询引擎:Thrift JDBC/ODBC服务 SparkSQL作为分布式查询引擎:Thrift JDBC/ODBC服务 Spa ...
- 【异常检测】Isolation forest 的spark 分布式实现
1.算法简介 算法的原始论文 http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf .python的sklearn中已经实现 ...
- Spark Standalone Mode 单机启动Spark -- 分布式计算系统spark学习(一)
spark是个啥? Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发. Spark和Hadoop有什么不同呢? Spark是基于map reduce算法实现的分布式计算,拥 ...
- Spark实战--搭建我们的Spark分布式架构
Spark的分布式架构 如我们所知,spark之所以强大,除了强大的数据处理功能,另一个优势就在于良好的分布式架构.举一个例子在Spark实战--寻找5亿次访问中,访问次数最多的人中,我用四个spar ...
- Spark分布式安装
三台 服务器 n0,n2,n3 centos 6.4 X64 JDK, SCALA 2.11 Hadoop 2.2.0 spark-0.9.1-bin-hadoop2.tgz 说明: 1.所有机器上安 ...
随机推荐
- mysql命令行查看建表语句
命令如下: SHOW CREATE TABLE tbl_name 例子: mysql> SHOW CREATE TABLE t\G . row ************************* ...
- zoj 1760 Doubles(set集合容器的应用)
题目链接: http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=1760 题目描述: As part of an arithmet ...
- zoj 1109 Language of FatMouse(map映照容器的典型应用)
题目连接: acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=1109 题目描述: We all know that FatMouse doe ...
- .5-浅析webpack源码之入口函数
从convert-argv出来后,目前进度在这: yargs.parse(process.argv.slice(2), (err, argv, output) => { // ... // 从这 ...
- C# Quartz的配置
1. 介绍 Quartz为后台工作者提供了得便利,我们下面介绍一下它的配置.本文配置主要针对服务程序的配置. 但是在做下面配置之前,要安装包 Install-Package Quartz 2. Qua ...
- [Angularjs]ng-bind-html指令
摘要 在为html标签绑定数据的时,如果绑定的内容是纯文本,你可以使用{{}}或者ng-bind.但在为html标签绑定带html标签的内容的时候,angularjs为了安全考虑,不会将其渲染成htm ...
- MVC初级教程(一)
演示产品源码下载地址:http://www.jinhusns.com/Products/Download
- $.ajax()参数详解及标准写法(转)
1.url: 要求为String类型的参数,(默认为当前页地址)发送请求的地址. 2.type: 要求为String类型的参数,请求方式(post或get)默认为get.注意其他http请求方法,例如 ...
- 关于eclipse的项目前有感叹号和errors exist in required project相关问题
一般来说 项目运行中 各个类的信息中并没有报错 但在运行中会出现errors exist in required project 且有时候运行也会成功.这种情况是由于项目中其他的类存在问题未解决 导 ...
- Java读取excel(兼容03和07格式)
读取excel,首先需要下载POI的jar,可以去官网下,也可以在这里下载 一.简单说明 excel2003和excel2007区别比较大,最直观的感受就是扩展名不一样,哈哈 不过,使用POI的API ...