python 阿狸的进阶之路(5)
一.模块
1.什么是模块:
包含了一组功能的python文件,文件名是xxx.py,模块名是module.
可以使用 import module,四个通用的类别:
(1)用python编写的py文件
(2)已经编译为共享库或DLL的c或c++扩展
(3)把一系列模块组织到一起的文件夹(一般在文件夹下设置__init__.py,该文件夹称之为包)
(4)使用c编写并且连接到python解释器的内置模块
2.模块的使用场景
(1)从文件级别组织程序,更方便管理
(2)拿来主义,节省时间,提升开发效率
3.如何使用模块
import 模块名(spam)
<1>.第一次导入模块发生的事件
(1)先产生一个新的命名空间
(2)运行源文件(spam)代码,产生的名字都存放于(1)的名称空间中,
运行过程中global的关键字指向的就是该命名空间
即在全局的命名空间中,开辟出一个模块名(spam)的命名空间,
(3)在当前的名称空间拿到一个名字spam,该名字指向1的命名空间
引用spam.py中的名称的方式: spam.xxx
(4)重复导入模块 import spam 重新引用的意思,并不会重新执行。
重点:被导入的模块在执行过程中使用自己独立的名称空间作为全局名称空间
<2>.别名: import spam as sm
(1)用途一:模块名字太长可以进行缩短
(2)用途二:利用别名进行判断
<3>.可以在一行导入多个模块:import time,os
- engine =input ('>>:')
- if engine == 'myslq':
- import mysql as sql
- elif engine == 'oracle':
- import orcle as sql
- sql.parse()
<4>.如何使用模块--》from 模块名 import 名字
优点,引用时不用加前缀,简单
缺点,有可能跟当前名称空间的名字冲突
from spam import money as m
from spam import * (用于模块太多的时候,但是你不知道你导入的都是什么模块)
(而且*包含了除了下划线开头的以外的所有的名字)
可以在模块的文件中写入一个列表: __all__ = ['read1', 'read2']
这时候 import * 导入的就是__all__ 列表中的变量或者函数了。
4. python 为每个文件都内置了一个变量 print (__name__)
一个python文件的两种用途
<1>当做脚本执行: __name__ == ' __main__'
<2>当做模块被导入使用: __name__ == '模块名'
可以使用测试功能:(控制文件的两种用途)
- if __name__ == '__main__': #利用文件__name__属性,如果当做脚本运行,则打印read1函数
- print(read1())
6.模块的搜索路径
内存----》内置模块---》sys.path(环境变量) (以执行文件为准)
- import sys
- print(sys.path) #打印当前的环境变量
- ['F:\\pycharm\\python\\day5', 'F:\\pycharm', 'F:\\Python30\\python36.zip', 'F:\\Python30\\DLLs', 'F:\\Python30\\lib', 'F:\\Python30', 'F:\\Python30\\lib\\site-packages']
打印出来是个列表,如果想要新加入环境变量,则可以sys.path.append() 加入之后就可找到模块
内置模块如果没有导入,则不会出现在内存中。
- import package1
- print(package1.x)
- import sys
- print('time' in sys.modules)
- import time
- print('time' in sys.modules)
- print('package1' in sys.modules )
查看包有没有导入成功
ps: sys.modules是一个字典,模块名字为key
二.包
1.什么是包
包就是包含了__init__.py 文件的文件夹(可以往该文件夹下放一堆子模块)
python2 中必须有 __init__.py
python3中可以没有这个文件
__init__.py文件说明:
- 相当于package的名称空间
这个文件的作用是将文件夹下的模块,进行组合- 当在一个文件中导入包时,先在本目录下找包的名字,然后直接进入 __init__文件查找,
- 在__init__.py 中可以写变量,函数,也可以写路径,即在__init__.py文件
中能导入的模块(导包时写全路径,即从执行文件开始直接找路径),
其他文件在能找到__init__.py的前提下也能导入。
example:
文件关系如下,import为执行文件,package1文件夹下有__init__.py m1.py 和package2文件夹,package2文件夹下有__init__.py n1.py
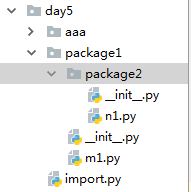
- import package1
- print(package1.m1)
- print(package1.m1.funcm)
- print(package1.package2)
- print(package1.package2.n1.funcn)
import.py(执行文件)
- x =1
- from package1 import m1
- from package1 import package2
package1下的__init__.py
- x= 10000000
- def funcm():
- print('m1m1m1m1m1m1m1m1')
package1下的m1.py
- from package1.package2 import n1
package2下的__init__.py
- def funcn():
- print('n1n1n1n1n1n1n1n1n1')
package2下的n1.py
2.相对导入和绝对导入
相对导入用 ‘’ .‘’ 一个点表示本文件的顶级目录,之后以此类推。例如 from .package2 import m1
绝对导入 直接写全用户路径 例如:from package1.package2 import m1 (注意:'.'的左边必须是包)
3. 如果包和执行文件不在一个地方,在执行文件中,将包的文件夹导入环境变量即可
可能用到的模块,sys os.path.abspath(__file__)当前文件的绝对路径,__file__为内置变量,
os.path.dirname(“文件的路径”) 文件的目录
4.软件开发规范
python 阿狸的进阶之路(5)的更多相关文章
- python 阿狸的进阶之路(9)
tcp传输: 传输需要ack回应,然后才清空缓存,服务端先起来. tcp流式协议,tcp的Nagle的优化算法,会将时间间隔短,数据量小的打包成一个,然后发送给对方,减少发送的次数. UDP协议: 不 ...
- python 阿狸的进阶之路(6)
常用模块 json # 序列化 #将内存的数据存到硬盘中,中间的格式,可以被多种语言识别,跨平台交互数据 #json 可以将字典之类的数据类型存到字典中 import json dic = {&quo ...
- day3 python 阿狸的进阶之路
函数概念: 1.为什要有函数 组织结构不清晰,可读性差,代码冗余,可扩展性差. 2.什么是函数 具备某一个功能的工具--->函数 事先准备工具->函数的定义 拿来就用. ...
- python 阿狸的进阶之路(8)
异常处理 http://www.cnblogs.com/linhaifeng/articles/6232220.html(转) 网络编程socket http://www.cnblogs.com/li ...
- python 阿狸的进阶之路(7)
面向对象 转自林海峰的博客 http://www.cnblogs.com/linhaifeng/articles/6182264.html 面向对象的理解: 将数据分类,比如学生类.数据有关的函数, ...
- python 阿狸的进阶之路(4)
装饰器 #1.开放封闭原则:对扩展开放,对修改是封闭#2.装饰器:装饰它人的,器指的是任意可调用对象,现在的场景装饰器->函数,被装饰的对象也是->函数#原则:1.不修改被装饰对象的源代码 ...
- Python 从入门到进阶之路(一)
人生苦短,我用 Python. Python 无疑是目前最火的语言之一,在这里就不再夸他的 NB 之处了,本着对计算机编程的浓厚兴趣,便开始了对 Python 的自学之路,并记录下此学习记录的心酸历程 ...
- Python 从入门到进阶之路(七)
之前的文章我们简单介绍了一下 Python 中异常处理,本篇文章我们来看一下 Python 中 is 和 == 的区别及深拷贝和浅拷贝. 我们先来看一下在 Python 中的双等号 == . == 是 ...
- Python 从入门到进阶之路(六)
之前的文章我们简单介绍了一下 Python 的面向对象,本篇文章我们来看一下 Python 中异常处理. 我们在写程序时,有可能会出现程序报错,但是我们想绕过这个错误执行操作.即使我们的程序写的没问题 ...
随机推荐
- react事件中的this指向
在react中绑定事件处理函数的this指向一共有三种方法,本次主要总结这三种方式. 项目创建 关于项目的创建方法,在之前的文章中有记录,这里不再赘述,项目创建成功后,按照之前的目录结构对生成的项目进 ...
- Heap堆分析(堆转储、堆分析)
一.堆直方图 减少内存使用时一个重要目标,在堆分析上最简单的方法是利用堆直方图.通过堆直方图我们可以快速看到应用内的对象数目,同时不需要进行完整的堆转储(因为堆转储需要一段时间来分析,而且会消耗大量磁 ...
- spring4.0之八:Groovy DSL
4.0的一个重要特征就是完全支持Groovy,Groovy是Spring主导的一门基于JVM的脚本语言(动态语言).在spring 2.x,脚本语言通过 Java scripting engine在S ...
- Jmeter(九)JDBC连接池
JDBC为java访问数据库提供通用的API,可以为多种关系数据库提供统一访问.因为SQL是关系式数据库管理系统的标准语言,只要我们遵循SQL规范,那么我们写的代码既可以访问MySQL又可以访问SQL ...
- [UE4]Task的定义与使用
在Task蓝图里面可以像普通蓝图一样添加函数.变量. 也可以通过使用“set blackboard value as”设置黑板变量,使用“get blackboard value as”获得黑板变量值 ...
- c#类的继承与包含的关系
基础例子 class Dept { private string name; private Emp emp; public string getName() { return this.name; ...
- CentOS之Shell文件编写基础
shell文件以.sh结尾,这是一种习惯而已.第一行以#! /bin/bash开头:表示该文件使用的是bash语法: 如果不设置该行,你的shell脚本也可以执行,但是不符合规范.#表示注释. # v ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- lambda详解
1:lambda表示方法 auto lambda = [](){}; lambda(); sizeof(lambda) = 1; 等价于类 class lambda{ pulic operator() ...
- JavaScript Best Practices (w3cschool)
JavaScript Best Practices (w3cschool) Local Variables: · 总是在前面集中定义变量,(包括 for 的i).(strict mode) ...