【Redis数据库】再有人问你CAP理论是什么,就把这篇文章发给他
CAP是Consistency(一致性),Availability(可用性),Partition tolerance(分区容错性)的缩写。在学习redis过程中看到这个名词,查找各位大佬的文章发现这篇讲得很简单清晰,文章来自公众号:codewill。
CAP 定理(CAP theorem)又被称作布鲁尔定理,是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。2002 年,麻省理工学院的赛斯·吉尔伯特(Seth Gilbert)和南希·林奇(Nancy Lynch)发表了布鲁尔猜想的证明,使之成为分布式计算领域公认的一个定理。
对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。
为了更好地解释 CAP 理论,我特意去大佬的博客看了下,的文章作为参考基础。(http://robertgreiner.com/about)
Robert Greiner 对 CAP 的理解也经历了一个过程,他写了两篇文章来阐述 CAP 理论,第一篇被标记为“outdated”(网上绝大部分解锁都止于第一篇)。
我们先看下第一版和第二版的差异
第一版
Any distributed system cannot guaranty C, A, and P simultaneously.
对于一个分布式计算系统,不可能同时满足一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三个设计约束。
1. 一致性(Consistency)
All nodes see the same data at the same time.
所有节点在同一时刻都能看到相同的数据。
2. 可用性(Availability)
Every request gets a response on success/failure.
每个请求都能得到成功或者失败的响应。
3. 分区容忍性(Partition Tolerance)
System continues to work despite message loss or partial failure.
出现消息丢失或者分区错误时系统能够继续运行。
第二版
In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed.
在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
1. 一致性(Consistency)
A read is guaranteed to return the most recent write for a given client.
对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
2. 可用性(Availability)
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
3. 分区容忍性(Partition Tolerance)
System continues to work despite message loss or partial failure.
当出现网络分区后,系统能够继续“履行职责”。
我们来详细看下具体的差异
首先概念上第二版定义了什么才是 CAP 理论探讨的分布式系统,强调了两点:interconnected 和 share data,为何要强调这两点呢? 因为分布式系统并不一定会互联和共享数据。最简单的例如 Memcache 的集群,相互之间就没有连接和共享数据,因此 Memcache 集群这类分布式系统就不符合 CAP 理论探讨的对象;而 MySQL 集群就是互联和进行数据复制的,因此是 CAP 理论探讨的对象。
第二版强调了 write/read pair,这点其实是和上一个差异点一脉相承的。也就是说,CAP 关注的是对数据的读写操作,而不是分布式系统的所有功能。例如,ZooKeeper 的选举机制就不是 CAP 探讨的对象。
1. 一致性(Consistency)
第一版强调同一时刻拥有相同数据(same time + same data),第二版并没有强调这点。
因此第一版的解释“All nodes see the same data at the same time”是不严谨的。而第二版强调 client 读操作能够获取最新的写结果就没有问题,因为事务在执行过程中,client 是无法读取到未提交的数据的,只有等到事务提交后,client 才能读取到事务写入的数据,而如果事务失败则会进行回滚,client 也不会读取到事务中间写入的数据。
2. 可用性(Availability)
第一版的 success/failure 的定义太泛了,几乎任何情况,无论是否符合 CAP 理论,我们都可以说请求成功和失败,因为超时也算失败、错误也算失败、异常也算失败、结果不正确也算失败;即使是成功的响应,也不一定是正确的。例如,本来应该返回 100,但实际上返回了 90,这就是成功的响应,但并没有得到正确的结果。相比之下,第二版的解释明确了不能超时、不能出错,结果是合理的,
3. 分区容忍性(Partition Tolerance)
第一版用的是 work,第二版用的是 function。
work 强调“运行”,只要系统不宕机,我们都可以说系统在 work,返回错误也是 work,拒绝服务也是 work;而 function 强调“发挥作用”“履行职责”,这点和可用性是一脉相承的。也就是说,只有返回 reasonable response 才是 function。相比之下,第二版解释更加明确。
CAP到底改怎么选
虽然 CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。如果我们选择了 CA 而放弃了 P,那么当发生分区现象时,为了保证 C,系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A 冲突了,因为 A 要求返回 no error 和 no timeout。因此,分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
让我们举个栗子
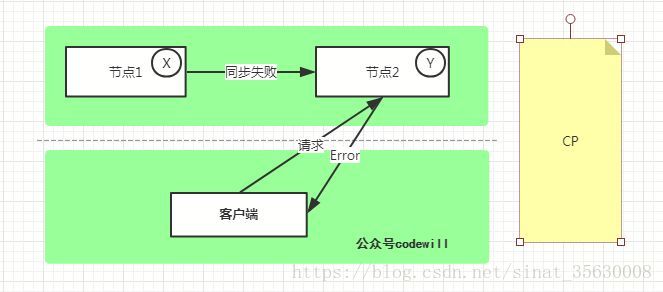
1.CP - Consistency/Partition Tolerance
如下图所示,为了保证一致性,当发生分区现象后, 节点1上的数据无法同步到 节点2, 节点2上的数据还是 Y。这时客户端 C 访问 节点2时,节点2 需要返回 Error,提示客户端 “系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
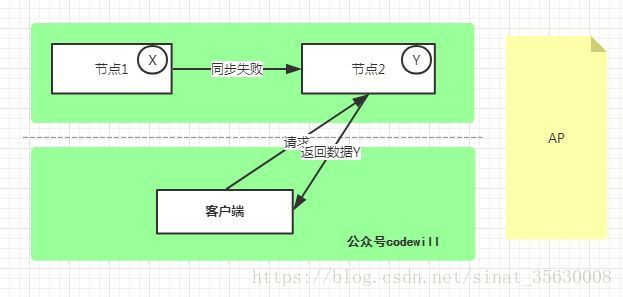
2.AP - Availability/Partition Tolerance
如下图所示,为了保证可用性,当发生分区现象后, 节点1上的数据无法同步到 节点2, 节点2上的数据还是 Y。这时客户端 访问 节点2 时,节点2 将当前自己拥有的数据 Y 返回给客户端,而实际上当前最新的数据已经是 X了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。
【Redis数据库】再有人问你CAP理论是什么,就把这篇文章发给他的更多相关文章
- 再有人问你synchronized是什么,就把这篇文章发给他
在再有人问你Java内存模型是什么,就把这篇文章发给他.中我们曾经介绍过,Java语言为了解决并发编程中存在的原子性.可见性和有序性问题,提供了一系列和并发处理相关的关键字,比如synchronize ...
- 【转】再有人问你Http协议是什么,把这篇文章发给他
一.HTTP简介 1.HTTP协议,即超文本传输协议(Hypertext transfer protocol).是一种详细规定了浏览器和万维网(WWW = World Wide Web)服务器之间互相 ...
- 如果有人问你ZooKeeper是什么,就把这篇文章发给他。
前言 提到ZooKeeper,相信大家都不会陌生.Dubbo,Kafka,Hadoop等等项目里都能看到它的影子.但是你真的了解 ZooKeeper 吗?如果面试官让你给他讲讲 ZooKeeper 是 ...
- [转] 以后再有人问你selenium是什么,你就把这篇文章给他
本文转自:https://blog.csdn.net/TestingGDR/article/details/81950593 写在最前面:目前自动化测试并不属于新鲜的事物,或者说自动化测试的各种方法论 ...
- 如果有人问你CAP理论是什么,就把这篇文章发给他。
绝对和你在网上看到的CAP定理介绍不一样. CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric B ...
- 再有人问你HashMap,把这篇文章甩给他!
声明:本文以jdk1.8为主! 搞定HashMap 作为一个Java从业者,面试的时候肯定会被问到过HashMap,因为对于HashMap来说,可以说是Java==集合中的精髓==了,如果你觉得自己对 ...
- 再有人问你HashMap,把这篇文章甩给他
搞定HashMap 作为一个Java从业者,面试的时候肯定会被问到过HashMap,因为对于HashMap来说,可以说是Java==集合中的精髓==了,如果你觉得自己对它掌握的还不够好,我想今天这篇文 ...
- 再有人问你Java内存模型是什么,就把这篇文章发给他
前几天,发了一篇文章,介绍了一下JVM内存结构.Java内存模型以及Java对象模型之间的区别.有很多小伙伴反馈希望可以深入的讲解下每个知识点.Java内存模型,是这三个知识点当中最晦涩难懂的一个,而 ...
- 面试官再问你 HashMap 底层原理,就把这篇文章甩给他看
前言 HashMap 源码和底层原理在现在面试中是必问的.因此,我们非常有必要搞清楚它的底层实现和思想,才能在面试中对答如流,跟面试官大战三百回合.文章较长,介绍了很多原理性的问题,希望对你有所帮助~ ...
随机推荐
- Linux 数据重定向
名称 描述 代码 表示 stdin 标准输入 0 < 或 << stdout 标准输出 1 > 或 >> stderr 标准错误输出 2 2> 或 2> ...
- js便签笔记(10) - 分享:json.js源码解读笔记
1. 如何理解“json” 首先应该意识到,json是一种数据转换格式,既然是个“格式”,就是个抽象的东西.它不是js对象,也不是字符串,它只是一种格式,一种规定而已. 这个格式规定了如何将js对象转 ...
- 一次完整的HTTP接口请求过程及针对优化
客户端发起http请求,基本的经历过程如下: 域名解析 -> TCP三次握手 -> 建立TCP连接后发起HTTP请求 -> Nginx反向代理 -> 应用层 -> 服务层 ...
- Linux 卸载 openjdk
1 卸载 openjdk sudo apt-get purge openjdk*
- 浅析 JavaScript 链式调用
对$函数你已经很熟悉了.它通常返回一个html元素或一个html元素的集合,如下: function$(){ var elements = []; for(vari=0,len=arguments.l ...
- map映照容器(常用的使用方法总结)
map映照容器的数据元素是由一个键值和一个映照数据组成的,键值和映照数据之间具有一一对应的关系.map与set集合容器一样,不允许插入的元素的键值重复. /*关于C++STL中map映照容器的学习,看 ...
- C#图片处理类
转载來源:简书 转载作者:幻凌风 转载来源:https://www.jianshu.com/p/e1bab83e87ce using System; using System.Collections; ...
- 排查CentOS7.0的联网情况
1.ifconfig命令. 查看网络配置是否有问题 在/etc/sysconfig/network-scripts/ifcfg-ens33里面配置好网络,记住onboot=on这个选项一定要设置,不然 ...
- spring装配注解(IOC容器加载控制)ComponentScan及ComponentScans使用
ComponentScan,只写入value,可扫描路径下装配的@Contrller.@Service.@Repository @ComponentScan(value = "com.tes ...
- java.lang.ExceptionInInitializerError异常
今天在开发的过程中,遇到java.lang.ExceptionInInitializerError异常,百度查了一下,顺便学习学习,做个笔记 静态初始化程序中发生意外异常的信号,抛出Exception ...