大数据入门第二十五天——elasticsearch入门
一、概述
推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html
官网:https://www.elastic.co/cn/products/elasticsearch
精品博文:https://blog.csdn.net/laoyang360/article/details/52244917
1.es是什么
官网的中文介绍:
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
权威指南的入门介绍:
Elasticsearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用
2.特征
查询、分析、速度、可拓展性、弹性、灵活
// 更多详细特征介绍,参考官网
二、安装
安装es需要先安装JDK,这里我们安装es5.6,提请安装一下JDK8
1.下载
https://www.elastic.co/cn/downloads/elasticsearch
选择一个合适的版本,下载即可
2.解压
#es启动时需要使用非root用户!如果非要使用,另行配置,这里暂不展开
[hadoop@mini1 ~]$ tar -zxvf elasticsearch-5.6..tar.gz -C /es
// 相应的目录需要有权限
3.修改配置
[hadoop@mini1 config]$ vim elasticsearch.yml
主要需要修改的项如下:
#集群名称,通过组播的方式通信,通过名称判断属于哪个集群
cluster.name: es
#节点名称,要唯一
node.name: es-
#数据存放位置
path.data: /es/data
#日志存放位置
path.logs: /es/log
#es绑定的ip地址
network.host: 192.168.137.128
#初始化时可进行选举的节点
discovery.zen.ping.unicast.hosts: ["mini1", "mini2", "mini3"]
4.拷贝到其他节点
[hadoop@mini1 es]$ scp -r elasticsearch-5.6./ mini2:/es/
[hadoop@mini1 es]$ scp -r elasticsearch-5.6./ mini3:/es/
5.修改其他节点配置
需要修改的有node.name和network.host
6.启动
bin/elasticsearch -h查看帮助文档)
bin/elasticsearch -d
启动时会报:Cannot allocate memory,原因是内存不足,ES默认JVM内存为2G
解决方案参考自:https://blog.csdn.net/qq942477618/article/details/53414983
其他也会有一些启动问题,根据日志与博文排查即可:https://blog.csdn.net/feinifi/article/details/73633235?utm_source=itdadao&utm_medium=referral
7.验证
根据以上两篇博文排查完问题后就可以启动了,启动后访问默认的9200端口即可:mini1:9200
{
"name" : "es-1",
"cluster_name" : "es",
"cluster_uuid" : "qO0_NjifRiOnPUnWA-9W-Q",
"version" : {
"number" : "5.6.9",
"build_hash" : "877a590",
"build_date" : "2018-04-12T16:25:14.838Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
8.停止
可以通过jps查看到其PID,也可以直接使用kill一步到位:
kill `ps -ef | grep Elasticsearch | grep -v grep | awk '{print $2}'`
当然,通过Jps也是可以轻松找出es的pid的:
jps | grep Elasticsearch | awk '{print $1}'
那停止命令也可以长这样:
kill - `jps | grep Elasticsearch | awk '{print $1}'`
9.一键启动脚本
如果要编写一个一键启动脚本,那一个简单的示例如下:
#!/bin/bash
SERVERS="192.168.137.128 192.168.137.138 192.168.137.148"
echo "start es..."
for SERVER in $SERVERS
do
ssh $SERVER "source /etc/profile&&/es/elasticsearch-5.6.9/bin/elasticsearch -d"
done
chmod +x以后就可以启动了
10.安装head管理插件
在线安装:
bin/plugin install mobz/elasticsearch-head
离线安装需要先去github下载
./plugin install file:///home/bigdata/elasticsearch-head-master.zip
这里通过查看es-head的github,发现已经不支持5.x了:
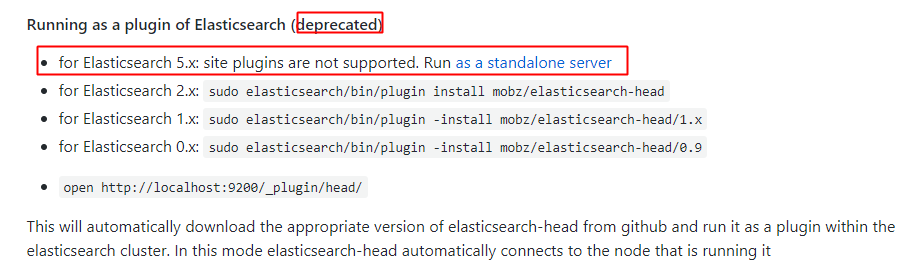
独立server安装方式,参考:https://blog.csdn.net/xgjianstart/article/details/78780176
三、基本概念
和之前的lucene是比较类似的,主要概念如下:
node/cluster:Node是集群的节点,cluster表示集群;
Index:数据管理的顶层单位叫index(索引),概念上类似数据库;
Document:数据库中的记录就叫Document,一条条document组成了一个index;
Type:Document的逻辑虚拟分组,概念上类似表,主要用来过滤Document;
完整参考:http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
四、基本操作
es提供RESTful形式的操作,基本形式如下:
http://localhost:9200/<index>/<type>/[<id>]
// 其中[]为可选,<>为必选
1.新建与删除index
使用linux的curl来完成,新增index:
[hadoop@mini1 elasticsearch-5.6.]$ curl -X PUT '192.168.137.128:9200/weather'
删除同样简单,换成DELETE请求即可
[hadoop@mini1 elasticsearch-5.6.]$ curl -X DELETE '192.168.137.128:9200/weather'
2.安装IK中文分词器
https://github.com/medcl/elasticsearch-analysis-ik
使用在线安装即可(安装博文参考:http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html)
###更多操作,待更新
大数据入门第二十五天——elasticsearch入门的更多相关文章
- 大数据入门第二十五天——logstash入门
一.概述 1.logstash是什么 根据官网介绍: Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据.转换数据,然后将数据发送到您最喜欢的 “存储库” 中.(我们的存储库 ...
- 大数据入门第十五天——HBase整合:云笔记项目
一.功能简述 1.笔记本管理(增删改) 2.笔记管理 3.共享笔记查询功能 4.回收站 效果预览: 二.库表设计 1.设计理念 将云笔记信息分别存储在redis和hbase中. redis(缓存):存 ...
- 大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎 Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序.可以看成是Hive到MapReduce的映射器. Hive ...
- Spring入门第二十五课
使用具名参数 直接看代码: db.properties jdbc.user=root jdbc.password=logan123 jdbc.driverClass=com.mysql.jdbc.Dr ...
- 孤荷凌寒自学python第二十五天初识python的time模块
孤荷凌寒自学python第二十五天python的time模块 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 通过对time模块添加引用,就可以使用python的time模块来进行相关的时间操 ...
- 无废话ExtJs 入门教程十五[员工信息表Demo:AddUser]
无废话ExtJs 入门教程十五[员工信息表Demo:AddUser] extjs技术交流,欢迎加群(201926085) 前面我们共介绍过10种表单组件,这些组件是我们在开发过程中最经常用到的,所以一 ...
- NeHe OpenGL教程 第二十五课:变形
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- javaSE第二十五天
第二十五天 399 1:如何让Netbeans的东西Eclipse能访问. 399 2:GUI(了解) 399 (1)用户图形界面 399 (2)两个包: 399 (3) ...
- Bootstrap入门(十五)组件9:面板组件
Bootstrap入门(十五)组件9:面板组件 虽然不总是必须,但是某些时候你可能需要将某些 DOM 内容放到一个盒子里.对于这种情况,可以试试面板组件. 1.基本实例 2.带标题的面板 3.情景效果 ...
随机推荐
- 《Spring实战》第4章--面向切面的Spring--处理通知中的参数(经验总结)
今天学习<Spring实战>第4章<面向切面的Spring>,根据4.3.3小节写出如下切面类: package proxy; import java.util.HashMap ...
- android画板笔锋实现
前言 在安卓绘图中,path是一个很常用的类,使用它可以实现基本的画线功能,但是自己用path画出来的同一条线段大小是不会改变的.如果做书写类型的软件,当然想要实现更好的逼真的书写效果,在实际书写过程 ...
- mybatis-generator 详细配置及使用,爬坑记录
mybatis-generator 详细配置及使用,爬坑记录 提示:如果不成功一定是项目路径和 数据库配置出问题,本篇基于 MySQL 8.0.13,调试没有问题. 如果失败,建议使用相同的项目结构, ...
- Python笔记(六):推导数据
(一) 准备工作 创建1个文件记录运动员的跑步成绩 james.txt 2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22 (二) 要求 在屏幕上输出运动员最 ...
- jdk1.8配置环境变量
1. 准备好jdk安装文件,选择地址,假设使用默认地址 2. 安装jdk,此时跳出安装 jre 的地址 3. 等待安装 4.找到安装路径,选择jdk 5. 复制文件夹下的bin 6. 点击我的电脑右键 ...
- SELECT查询结果集INSERT到数据表
简介 将查询语句查询的结果集作为数据插入到数据表中. 一.通过INSERT SELECT语句形式向表中添加数据 例如,创建一张新表AddressList来存储班级学生的通讯录信息,然后这些信息恰好存在 ...
- xml 注意事项
<?xml version="1.0" encoding="GB2312"?> xml区分大小写,只能有一个根元素,属性值必须放在引号中,空格不 ...
- MSChart 设置饼图颜色 图例背景色 图例显示位置
chartField.Series.Clear(); chartField.ChartAreas.Clear(); chartField.Legends.C ...
- IIS 安全设置
这近网站中毒,以下把IIS安全设置记录一下,以便查阅. 1.对于不需要执行的目录,将处理程序映射中的编辑功能权限中的脚本去掉,这样即使上传了木马文件在此目录,也是无法执行的. 删除IIS默认的匿名用户 ...
- November 02nd, 2017 Week 44th Thursday
Knowledge is weightless, a treasure you can always carry easily. 知识没有重量,她是我们可以很容易携带的珍宝. Knowledge is ...