ubantu18.04下Hadoop安装与伪分布式配置
1 下载
下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/stable2/
2 解压
将文件解压到 /usr/local/hadoop
cd ~/下载 tar -zxf hadoop-2.9..tar.gz sudo mv ./hadoop-2.9./ /usr/local/hadoop cd /usr/local/hadoop
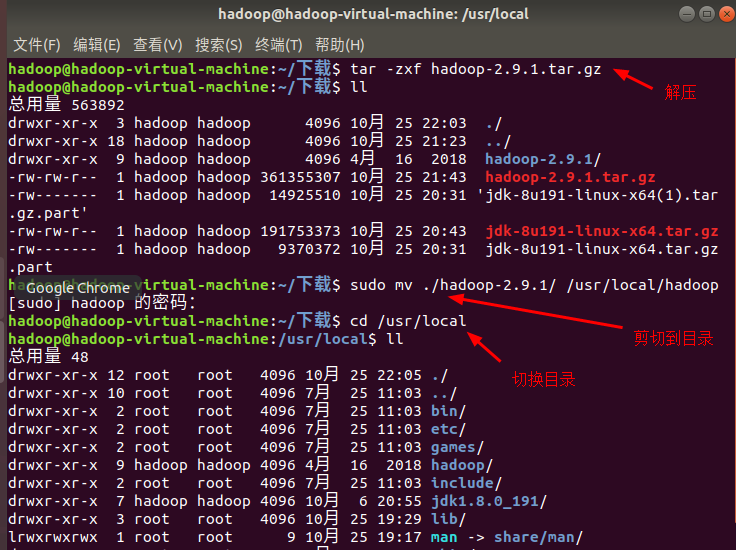
此时可以查看Hadoop版本信息:
./bin/hadoop version

3 hadoop伪分布式配置
3.1 配置hadoop中的JAVA_HOME
到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“ export JAVA_HOME=/usr/local/jdk1.8.0_191”,然后,再次启动Hadoop。

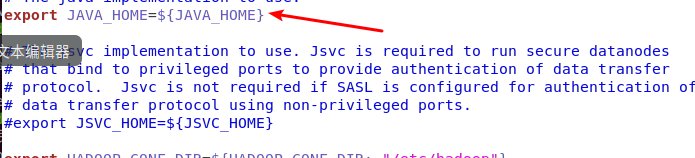
修改后:

令文件生效:

3.2 ssh登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost ssh-keygen -t rsa # 会有提示,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加入授权
3.3 配置HADOOP_HOME
在 ~/.bashrc 中,增加如下内容(设置过程与 JAVA_HOME 变量一样,其中 HADOOP_HOME 为 Hadoop 的安装目录)
#hadoop
export HADOOP_HOME=/usr/local/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME$/bin export PATH=$PATH:$HADOOP_HOME$/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
修改后如下图所示:

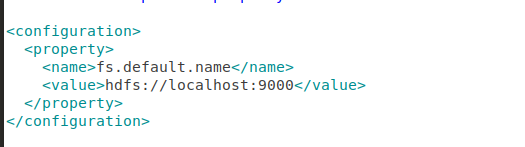
修改/usr/local/hadoop/etc/hadoop/core-site.xml文件配置:
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
修改为一下内容:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改YARN-site.xml文件配置:
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
修改为以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>

复制文件:
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
然后进行编辑:
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
修改为以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置hdfs-site.xml文件:
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
修改为以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
3.4 格式化
配置完成后,执行 NameNode 的格式化,执行以下命令:
创建namenode数据存放目录:
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
创建爱你datanode数据存放目录:
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
将Hadoop目录的所有者更改为chb:
sudo chown chb:chb -R /usr/local/hadoop
格式化:
hadoop namenode -format
运行上述命令之后,出现“successfully formatted.“则证明格式化成功。

启动HDFS:
start-dfs.sh
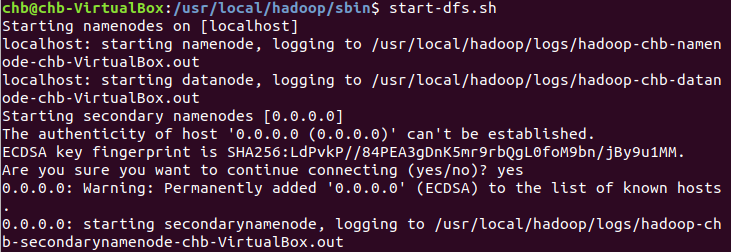
启动Hadoop MapReduce框架的Yarn:

当然,也可以同时启动上述两者:
start-all.sh
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
jps#可不是jsp
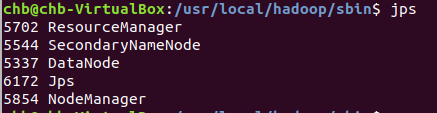
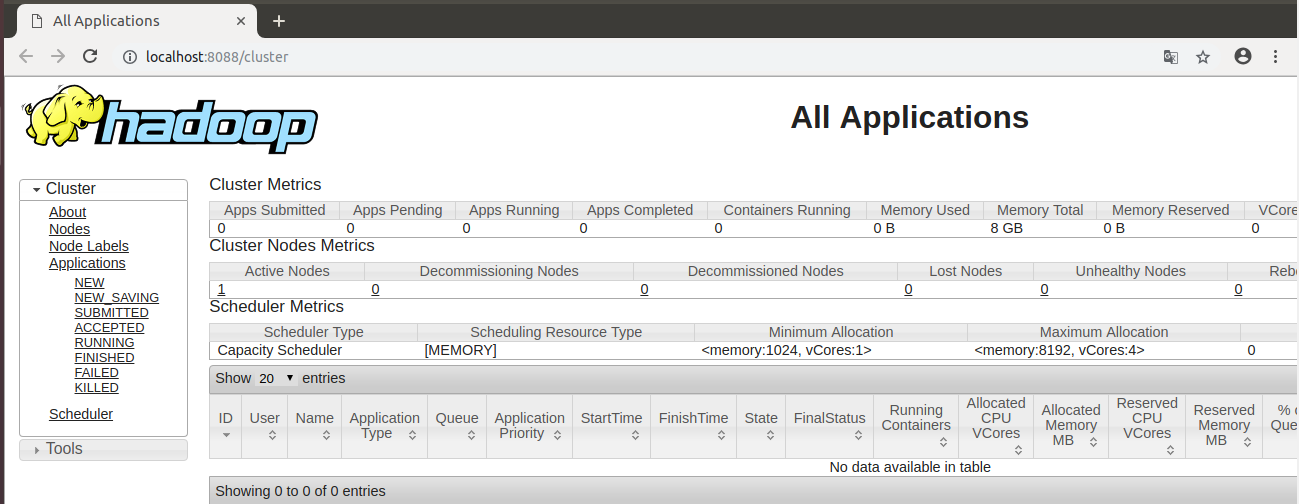
打开浏览器,输入地址:http://localhost:8088/可以看到如下界面:
ubantu18.04下Hadoop安装与伪分布式配置的更多相关文章
- Win10环境下Hadoop(单节点伪分布式)的安装与配置--bug(yarn的8088端口打不开+)
一.本文思路 [1].配置java环境–JDK12(Hadoop的底层实现语言是java,hadoop运行需要JDK环境) [2].安装Hadoop 1.解压hadop 2.配置hadoop环境变量 ...
- Hadoop安装-单机-伪分布式简单部署配置
最近在搞大数据项目支持所以有时间写下hadoop随笔吧. 环境介绍: Linux: centos7 jdk:java version "1.8.0_181 hadoop:hadoop-3.2 ...
- CentOS7 下 Hadoop 单节点(伪分布式)部署
Hadoop 下载 (2.9.2) https://hadoop.apache.org/releases.html 准备工作 关闭防火墙 (也可放行) # 停止防火墙 systemctl stop f ...
- Ubuntu14.04或16.04下Hadoop及Spark的开发配置
对于Hadoop和Spark的开发,最常用的还是Eclipse以及Intellij IDEA. 其中,Eclipse是免费开源的,基于Eclipse集成更多框架配置的还有MyEclipse.Intel ...
- Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
一.准备 1.1创建hadoop用户 $ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell $ sudo pass ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- 新手推荐:Hadoop安装教程_单机/伪分布式配置_Hadoop-2.7.1/Ubuntu14.04
下述教程本人在最新版的-jre openjdk-7-jdk OpenJDK 默认的安装位置为: /usr/lib/jvm/java-7-openjdk-amd64 (32位系统则是 /usr/lib/ ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04(转)
http://www.powerxing.com/install-hadoop/ http://blog.csdn.net/beginner_lee/article/details/6429146 h ...
随机推荐
- 5: EL 表达式小结
1.EL表达式的语法格式很简单: 以前编写jsp代码时,如果要获取表单中的用户名,一般使用 <%=request.getParameter("name")%> ,这样 ...
- Linux上安装node和npm
说明:最近工作中需要用到react前端框架使得可以前后分离,在安装react之前呢我是需要先安装node,和npm的 由于npm是依赖于node 的,所以我这边只要安装了node后,npm也就安装完成 ...
- 洛谷P1140 相似基因 (DP)
洛谷P1140 相似基因 题目背景 大家都知道,基因可以看作一个碱基对序列.它包含了44种核苷酸,简记作A,C,G,TA,C,G,T.生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物. ...
- LeetCode 8 有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效. 有效字符串需满足: 左括号必须用相同类型的右括号闭合. 左括号必须以正确的顺序闭合. 注意空字符串可被认 ...
- 成员变量与局部变量的区别--------java基础总结
- node.js原生后台进阶(一)
后台对于我们前端来说可能真的有点陌生,下面我来理清一下思绪吧. 一个基本的后台要求有如下功能: 1.与前端的数据交互 2.操作数据库(增删改查) 3.操作服务器文件(也大概是增删改查) 本次我们先讨论 ...
- SQL记录-PLSQL运算符
PL/SQL运算符 运算符是一个符号,告诉编译器执行特定的数学或逻辑操作. PL/SQL语言有丰富的内置运算符,运算符提供的以下几种类型: 算术运算符 关系运算符 比较运算符 逻辑运算符 字符串运算符 ...
- SQL记录-PLSQL异常
PL/SQL异常 程序执行过程中出现错误情况被称为在PL/SQL异常. PL/SQL支持程序员在程序中使用异常块捕获这样的条件并采取适当的动作应对错误情况.有两种类型的异常: 系统定义的异常 用户 ...
- windows10 升级1803后,远程错误提示“出现身份验证错误,要求的函数不受支持 CredSSP 加密 Oracle修正”的解决办法
远程出现错误提示:出现身份验证错误,要求的函数不受支持 CredSSP 加密 Oracle修正 运行 gpedit.msc 本地组策略: 计算机配置>管理模板>系统>凭据分配> ...
- ActiveMQ基础教程----简单介绍与基础使用
概述 ActiveMQ是由Apache出品的,一款最流行的,能力强劲的开源消息总线.ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,它非常快速,支持多 ...