用scrapy爬取京东的数据
本文目的是使用scrapy爬取京东上所有的手机数据,并将数据保存到MongoDB中。
一、项目介绍
主要目标
1、使用scrapy爬取京东上所有的手机数据
2、将爬取的数据存储到MongoDB
环境
win7、python2、pycharm
技术
1、数据采集:scrapy
2、数据存储:MongoDB
难点分析
和其他的电商网站相比,京东的搜索类爬取主要有以下几个难点:
1、搜索一个商品时,一开始显示的商品数量为30个,当下拉这一页 时,又会出现30个商品,这就是60个商品了,前30个可以直接 从原网页上拿到,后30个却在另一个隐藏链接中,要访问这两个 链接,才能拿到一页的所有数据。
2、隐藏链接的构造,发现最后的那个show_items字段其实是前30 个商品的id。
3、直接反问隐藏链接被拒绝访问,京东的服务器会检查链接的来源, 只有来自当前页的链接他才会允许访问。
4、前30个商品的那一页的链接page字段的自增是1、3、5。。。这 样的,而后30个的自增是2、4、6。。。这样的。
下面看具体的分析。
二、网页分析
首先打开京东的首页搜索“手机”:
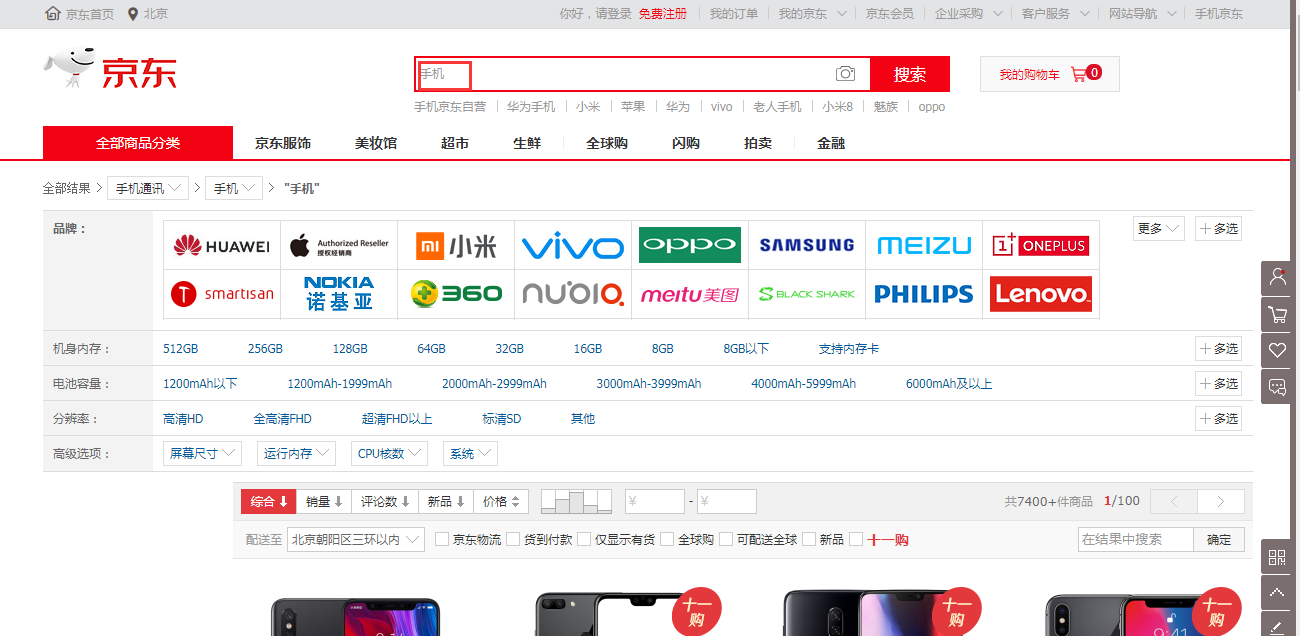
一开始他的地址是这样的:
转到第2页,会看到,他的地址变成这样子了:

后面的字段全变了,那么第2页的url明显更容易看出信息,主要修改的字段其实就是keyword,page,其实还有一个wq字段,这个得值和keyword是一样的。
那么我们就可以使用第二页的url来抓取数据,可以看出第2页的url中page字段为3。
但是查看原网页的时候却只有30条数据,还有30条数据隐藏在一个网页中:

从这里面可以看到他的Request url。
再看一下他的response:

里面正好就是我们需要的信息。
看一下他的参数请求:
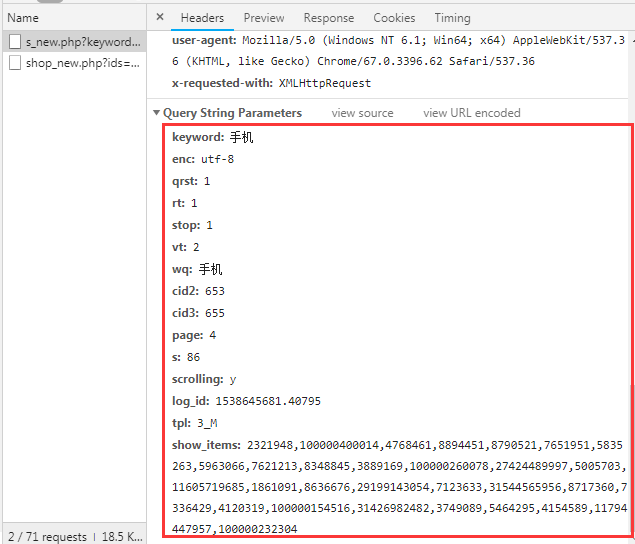
这些参数不难以构造,一些未知的参数可以删掉,而那个show_items参数,其实就是前30个商品的id:
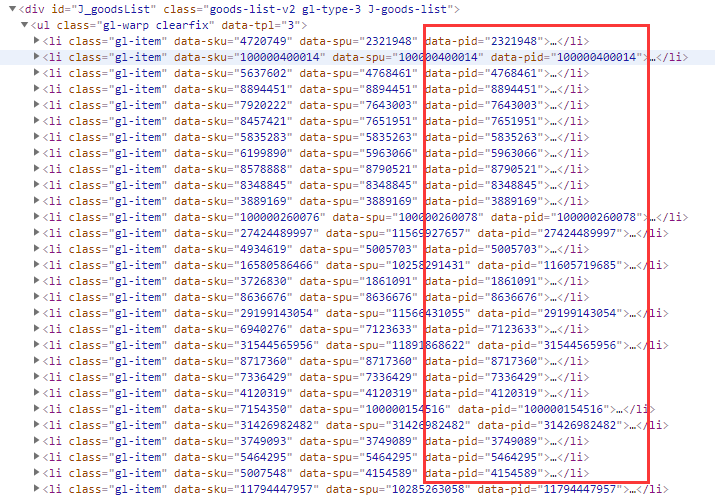
准确来说是data-pid
此时如果我们直接在浏览器上访问这个Request url,他会跳转到https://www.jd.com/?se=deny页面,并没有我们需要的信息,其实这个主要是请求头中的referer参数
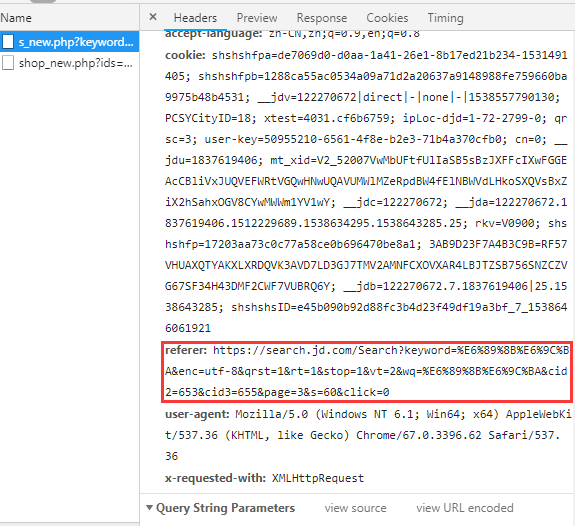
这个参数就是在地址栏上的那个url,当然在爬取的时候我们还可以加个user-agent,那么分析完毕,我们开始敲代码。
三、爬取
创建一个scrapy爬虫项目:
scrapy startproject jdphone
生成一个爬虫:
scrapy genspider jd jd.com
文件结构:
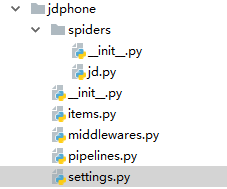
items: items.py
# -*- coding: utf-8 -*-
import scrapy class JdphoneItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 标题 price = scrapy.Field() # 价格 comment_num = scrapy.Field() # 评价条数 url = scrapy.Field() # 商品链接 info = scrapy.Field() # 详细信息
spiders: jd.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import JdphoneItem
import sys reload(sys)
sys.setdefaultencoding("utf-8") class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com'] # 有的时候写个www.jd.com会导致search.jd.com无法爬取
keyword = "手机"
page = 1
url = 'https://search.jd.com/Search?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%s&cid2=653&cid3=655&page=%d&click=0'
next_url = 'https://search.jd.com/s_new.php?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%s&cid2=653&cid3=655&page=%d&scrolling=y&show_items=%s' def start_requests(self):
yield scrapy.Request(self.url % (self.keyword, self.keyword, self.page), callback=self.parse) def parse(self, response):
"""
爬取每页的前三十个商品,数据直接展示在原网页中
:param response:
:return:
"""
ids = []
for li in response.xpath('//*[@id="J_goodsList"]/ul/li'):
item = JdphoneItem() title = li.xpath('div/div/a/em/text()').extract() # 标题
price = li.xpath('div/div/strong/i/text()').extract() # 价格
comment_num = li.xpath('div/div/strong/a/text()').extract() # 评价条数
id = li.xpath('@data-pid').extract() # id
ids.append(''.join(id)) url = li.xpath('div/div[@class="p-name p-name-type-2"]/a/@href').extract() # 需要跟进的链接 item['title'] = ''.join(title)
item['price'] = ''.join(price)
item['comment_num'] = ''.join(comment_num)
item['url'] = ''.join(url) if item['url'].startswith('//'):
item['url'] = 'https:' + item['url']
elif not item['url'].startswith('https:'):
item['info'] = None
yield item
continue yield scrapy.Request(item['url'], callback=self.info_parse, meta={"item": item}) headers = {'referer': response.url}
# 后三十页的链接访问会检查referer,referer是就是本页的实际链接
# referer错误会跳转到:https://www.jd.com/?se=deny
self.page += 1
yield scrapy.Request(self.next_url % (self.keyword, self.keyword, self.page, ','.join(ids)),
callback=self.next_parse, headers=headers) def next_parse(self, response):
"""
爬取每页的后三十个商品,数据展示在一个特殊链接中:url+id(这个id是前三十个商品的id)
:param response:
:return:
"""
for li in response.xpath('//li[@class="gl-item"]'):
item = JdphoneItem()
title = li.xpath('div/div/a/em/text()').extract() # 标题
price = li.xpath('div/div/strong/i/text()').extract() # 价格
comment_num = li.xpath('div/div/strong/a/text()').extract() # 评价条数
url = li.xpath('div/div[@class="p-name p-name-type-2"]/a/@href').extract() # 需要跟进的链接 item['title'] = ''.join(title)
item['price'] = ''.join(price)
item['comment_num'] = ''.join(comment_num)
item['url'] = ''.join(url) if item['url'].startswith('//'):
item['url'] = 'https:' + item['url']
elif not item['url'].startswith('https:'):
item['info'] = None
yield item
continue yield scrapy.Request(item['url'], callback=self.info_parse, meta={"item": item}) if self.page < 200:
self.page += 1
yield scrapy.Request(self.url % (self.keyword, self.keyword, self.page), callback=self.parse) def info_parse(self, response):
"""
链接跟进,爬取每件商品的详细信息,所有的信息都保存在item的一个子字段info中
:param response:
:return:
"""
item = response.meta['item']
item['info'] = {}
type = response.xpath('//div[@class="inner border"]/div[@class="head"]/a/text()').extract()
name = response.xpath('//div[@class="item ellipsis"]/text()').extract()
item['info']['type'] = ''.join(type)
item['info']['name'] = ''.join(name) for div in response.xpath('//div[@class="Ptable"]/div[@class="Ptable-item"]'):
h3 = ''.join(div.xpath('h3/text()').extract())
if h3 == '':
h3 = "未知"
dt = div.xpath('dl/dt/text()').extract()
dd = div.xpath('dl/dd[not(@class)]/text()').extract()
item['info'][h3] = {}
for t, d in zip(dt, dd):
item['info'][h3][t] = d
yield item
item pipeline: pipelines.py
# -*- coding: utf-8 -*-
from scrapy.conf import settings
from pymongo import MongoClient class JdphonePipeline(object):
def __init__(self):
# 获取setting中主机名,端口号和集合名
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbname = settings['MONGODB_DBNAME']
col = settings['MONGODB_COL'] # 创建一个mongo实例
client = MongoClient(host=host,port=port) # 访问数据库
db = client[dbname] # 访问集合
self.col = db[col] def process_item(self, item, spider):
data = dict(item)
self.col.insert(data)
return item
setting: setting.py
# -*- coding: utf-8 -*-
BOT_NAME = 'jdphone' SPIDER_MODULES = ['jdphone.spiders']
NEWSPIDER_MODULE = 'jdphone.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # 主机环回地址
MONGODB_HOST = '127.0.0.1'
# 端口号,默认27017
MONGODB_POST = 27017
# 设置数据库名称
MONGODB_DBNAME = 'JingDong'
# 设置集合名称
MONGODB_COL = 'JingDongPhone' ITEM_PIPELINES = {
'jdphone.pipelines.JdphonePipeline': 300,
}
其他的文件都不做改变。
运行爬虫:
scrapy crawl jd
等待几分钟后,数据都存储到了MongoDB中了,现在来看一看MongoDB中的数据。
四、检查数据
在命令行中开启mongo:
看一下数据库:
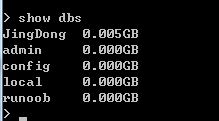
发现JingDong中有5M数据。
看一下具体状态:
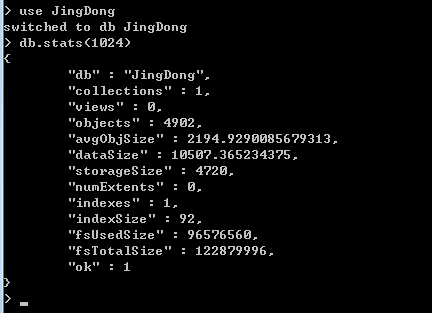
硬盘上的数据大小为4720KB,共4902条数据
最后来看一下数据:

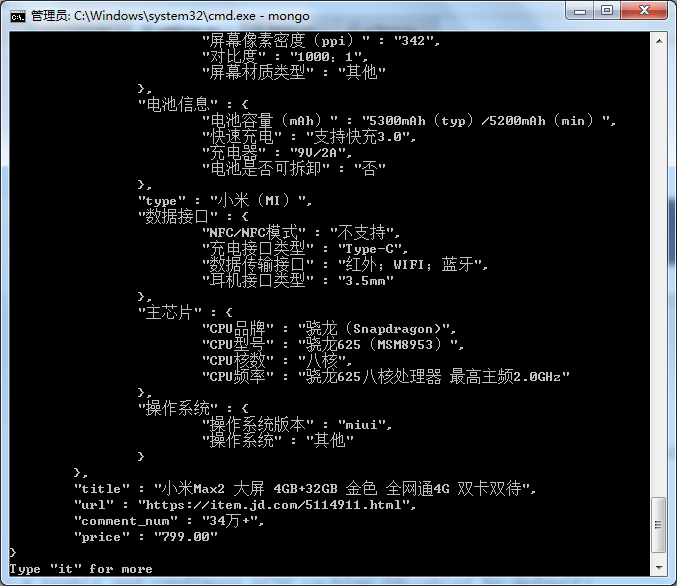
数据保存成功!
用scrapy爬取京东的数据的更多相关文章
- Java实现爬取京东手机数据
Java实现爬取京东手机数据 最近看了某马的Java爬虫视频,看完后自己上手操作了下,基本达到了爬数据的要求,HTML页面源码也刚好复习了下,之前发布两篇关于简单爬虫的文章,也刚好用得上.项目没什么太 ...
- webMagic+RabbitMQ+ES爬取京东建材数据
本次爬虫所要爬取的数据为京东建材数据,在爬取京东的过程中,发现京东并没有做反爬虫动作,所以爬取的过程还是比较顺利的. 为什么要用WebMagic: WebMagic作为一款轻量级的Java爬虫框架,可 ...
- scrapy爬取京东iPhone11评论(一)
咨询行业中经常接触到文本类信息,无论是分词做词云图,还是整理编码分析用,都非常具有价值. 本文将记录使用scrapy框架爬取京东IPhone11评论的过程,由于一边学习一边实践,更新稍慢请见谅. 1. ...
- 爬虫(十七):Scrapy框架(四) 对接selenium爬取京东商品数据
1. Scrapy对接Selenium Scrapy抓取页面的方式和requests库类似,都是直接模拟HTTP请求,而Scrapy也不能抓取JavaScript动态谊染的页面.在前面的博客中抓取Ja ...
- Scrapy爬取豆瓣图书数据并写入MySQL
项目地址 BookSpider 介绍 本篇涉及的内容主要是获取分类下的所有图书数据,并写入MySQL 准备 Python3.6.Scrapy.Twisted.MySQLdb等 演示 代码 一.创建项目 ...
- 用scrapy爬取京东商城的商品信息
软件环境: gevent (1.2.2) greenlet (0.4.12) lxml (4.1.1) pymongo (3.6.0) pyOpenSSL (17.5.0) requests (2.1 ...
- C#爬取京东手机数据+PowerBI数据可视化展示
此系列博文链接 C#爬虫基本知识 Html Agility Pack解析html TODO: EF6中基本认识. EF6操作mysql MySQL乱码问题 C#爬虫 在开头贴一下github仓库地址, ...
- Scrapy爬取到的中文数据乱码问题处理
Scrapy爬取到中文数据默认是 Unicode编码的,于是显示是这样的: "country": ["\u56fd\u4ea7\u6c7d\u8f66\u6807\u5f ...
- scrapy爬取booking酒店评论数据
# scrapy爬取酒店评论数据 -- 代码 here:github地址:https://github.com/760730895/scrapy_Booking-- 采用scrapy爬取酒店评论数据 ...
随机推荐
- 【洛谷P1462】通往奥格瑞玛的道路
题目大意:给定一个 N 个点,M 条边的无向图,求从 1 号节点到 N 号节点的路径中,满足路径长度不大于 B 的情况下,经过顶点的点权的最大值最小是多少. 题解:最大值最小问题一般采用二分答案.这道 ...
- vue单页面应用项目优化总结(转载)
转载自:https://blog.csdn.net/qq_42221334/article/details/81907901这是之前在公司oa项目优化时罗列的优化点,基本都已经完成,当时花了点心思整理 ...
- 短视频如何制作?如何下载短视频?常用的短视频录制和剪辑App有哪些?
当下,娱乐圈最火的是什么?当然是短视频了. 那么,短视频如何制作?短视频如何挣钱?如何下载免费短视频呢?这篇文章就收录了一些相关的短视频文章,加入收藏哦,小编会持续更新本文. 1. iPhone手机上 ...
- JIRA项目管理搭建
部署JIRA 7.2.2 for Linux 转自:http://www.yfshare.vip/2017/05/09/%E9%83%A8%E7%BD%B2JIRA-7-2-2-for-Linux/ ...
- 第10月第1天 storyboard uitableviewcell
1. 如图,我们在Cell的属性界面对其进行了注册,identifier 为"TableViewCell" 不需要在 ViewDidLoad 对其进行注册了,如果进行注册的话,则对 ...
- Docker01 CentOS配置Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制,相互之间不会有任何 ...
- 【Pyhon】获取文件MIME类型,根据文件类型自定义文件后缀
场景 下载样本,都是MD5命名的无后缀文件,需要自己手动查询然后修改文件后缀. 根据文件类型自定义后缀可以很方便地根据后缀判断用什么工具分析. 使用说明 libmagic 地址:https://pyp ...
- mysql Keepalived 实践
Keepalived 是一种高性能的服务器高可用或热备解决方案,Keepalived可以用来防止服务器单点故障(单点故障是指一旦某一点出现故障就会导致整个系统架构的不可用)的发生,通过配合Nginx可 ...
- php扩展Redis功能
php扩展Redis功能 1 首先,查看所用php编译版本V6/V9 在phpinfo()中查看 2 下载扩展 地址:https://github.com/nicolasff/phpredis/dow ...
- python基础-pthon
1)python 由Guido开发 2)编译(compile)型:通过编译器把代码直接生成一个可执行文件. 比如把英语书一次性翻译成中文书.语言有:c,C++等 解释型:边编译边执行.语言如:java ...