YOLO end-to-end
1.YOLO: You Only Look Once:Unified, Real-Time Object Detection
YOLO是一个可以一次性预测多个Box位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。事实上,目标检测的本质就是回归,因此一个实现回归功能的CNN并不需要复杂的设计过程。YOLO没有选择滑窗或提取proposal的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用proposal训练方式的Fast-R-CNN常常把背景区域误检为特定目标。当然,YOLO在提升检测速度的同时牺牲了一些精度。下图所示是YOLO检测系统流程:1.将图像Resize到448*448;2.运行CNN;3.非极大抑制优化检测结果。有兴趣的童鞋可以按照http://pjreddie.com/darknet/install/的说明安装测试一下YOLO的scoring流程,非常容易上手。接下来将重点介绍YOLO的原理。

1.1 一体化检测方案
YOLO的设计理念遵循端到端训练和实时检测。YOLO将输入图像划分为S*S个网络,如果一个物体的中心落在某网格(cell)内,则相应网格负责检测该物体。在训练和测试时,每个网络预测B个bounding boxes,每个bounding box对应5个预测参数,即bounding box的中心点坐标(x,y),宽高(w,h),和置信度评分。这里的置信度评分(Pr(Object)*IOU(pred|truth))综合反映基于当前模型bounding box内存在目标的可能性Pr(Object)和bounding box预测目标位置的准确性IOU(pred|truth)。如果bouding box内不存在物体,则Pr(Object)=0。如果存在物体,则根据预测的bounding box和真实的bounding box计算IOU,同时会预测存在物体的情况下该物体属于某一类的后验概率Pr(Class_i|Object)。假定一共有C类物体,那么每一个网格只预测一次C类物体的条件类概率Pr(Class_i|Object), i=1,2,...,C;每一个网格预测B个bounding box的位置。即这B个bounding box共享一套条件类概率Pr(Class_i|Object), i=1,2,...,C。基于计算得到的Pr(Class_i|Object),在测试时可以计算某个bounding box类相关置信度:Pr(Class_i|Object)*Pr(Object)*IOU(pred|truth)=Pr(Class_i)*IOU(pred|truth)。如果将输入图像划分为7*7网格(S=7),每个网格预测2个bounding box (B=2),有20类待检测的目标(C=20),则相当于最终预测一个长度为S*S*(B*5+C)=7*7*30的向量,从而完成检测+识别任务,整个流程可以通过下图理解。

1.1.1 网络设计
YOLO网络设计遵循了GoogleNet的思想,但与之有所区别。YOLO使用了24个级联的卷积(conv)层和2个全连接(fc)层,其中conv层包括3*3和1*1两种Kernel,最后一个fc层即YOLO网络的输出,长度为S*S*(B*5+C)=7*7*30.此外,作者还设计了一个简化版的YOLO-small网络,包括9个级联的conv层和2个fc层,由于conv层的数量少了很多,因此YOLO-small速度比YOLO快很多。如下图所示我们给出了YOLO网络的架构。

1.1.2 训练
作者训练YOLO网络是分步骤进行的:首先,作者从上图网络中取出前20个conv层,然后自己添加了一个average pooling层和一个fc层,用1000类的ImageNet数据与训练。在ImageNet2012上用224*224d的图像训练后得到的top5准确率是88%。然后,作者在20个预训练好的conv层后添加了4个新的conv层和2个fc层,并采用随即参数初始化这些新添加的层,在fine-tune新层时,作者选用448*448图像训练。最后一个fc层可以预测物体属于不同类的概率和bounding box中心点坐标x,y和宽高w,h。Boundingbox的宽高是相对于图像宽高归一化后得到的,Bounding box的中心位置坐标是相对于某一个网格的位置坐标进行过归一化,因此x,y,w,h均介于0到1之间。
在设计Loss函数时,有两个主要的问题:1.对于最后一层长度为7*7*30长度预测结果,计算预测loss通常会选用平方和误差。然而这种Loss函数的位置误差和分类误差是1:1的关系。2.整个图有7*7个网格,大多数网格实际不包含物体(当物体的中心位于网格内才算包含物体),如果只计算Pr(Class_i),很多网格的分类概率为0,网格loss呈现出稀疏矩阵的特性,使得Loss收敛效果变差,模型不稳定。为了解决上述问题,作者采用了一系列方案:
1.增加bounding box坐标预测的loss权重,降低bounding box分类的loss权重。坐标预测和分类预测的权重分别是λcoord=5,λnoobj=0.5.
2.平方和误差对于大和小的bounding box的权重是相同的,作者为了降低不同大小bounding box宽高预测的方差,采用了平方根形式计算宽高预测loss,即sqrt(w)和sqrt(h)。
训练Loss组成形式较为复杂,这里不作列举,如有兴趣可以参考作者原文慢慢理解体会。
1.1.3 测试
作者选用PASAL VOC图像测试训练得到的YOLO网络,每幅图会预测得到98个(7*7*2)个bouding box及相应的类概率。通常一个cell可以直接预测出一个物体对应的bounding box,但是对于某些尺寸较大或靠近图像边界的物体,需要多个网格预测的结果通过非极大抑制处理生成。虽然YOLO对于非极大抑制的依赖不及R-CNN和DPM,但非极大抑制确实可以将mAP提高2到3个点。
1.2 方法对比
作者将YOLO目标检测与识别方法与其他几种经典方案进行比较可知:
DPM(Deformable parts models): DPM是一种基于滑窗方式的目标检测方法,基本流程包括几个独立的环节:特征提取,区域划分,基于高分值区域预测bounding box。YOLO采用端到端的训练方式,将特征提取、候选框预测,非极大抑制及目标识别连接在一起,实现了更快更准的检测模型。
R-CNN:R-CNN方案分需要先用SeletiveSearch方法提取proposal,然后用CNN进行特征提取,最后用SVM训练分类器。如此方案,诚繁琐也!YOLO精髓思想与其类似,但是通过共享卷积特征的方式提取proposal和目标识别。另外,YOLO用网格对proposal进行空间约束,避免在一些区域重复提取Proposal,相较于SeletiveSearch提取2000个proposal进行R-CNN训练,YOLO只需要提取98个proposal,这样训练和测试速度怎能不快?
Fast-R-CNN、Faster-R-CNN、Fast-DPM: Fast-R-CNN和Faster-R-CNN分别替换了SVMs训练和SelectiveSeach提取proposal的方式,在一定程度上加速了训练和测试速度,但其速度依然无法和YOLO相比。同理,将DPM优化在GPU上实现也无出YOLO之右。
1.3 实验
1.3.1 实时检测识别系统对比

1.3.2 VOC2007准确率比较
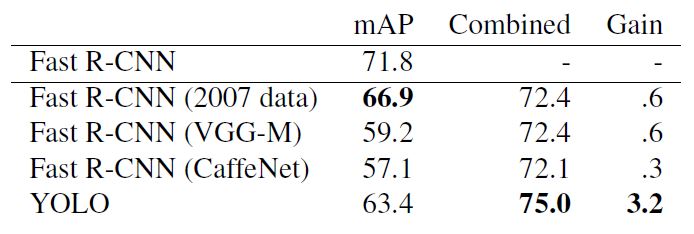
1.3.3 Fast-R-CNN和YOLO错误分析

如图所示,不同区域分别表示不同的指标:
Correct:正确检测和识别的比例,即分类正确且IOU>0.5
Localization:分类正确,但0.1<IOU<0.5
Similar:类别相似,IOU>0.1
Other:分类错误,IOU>0.1
Background: 对于任何目标IOU<0.1
可以看出,YOLO在定位目标位置时准确度不及Fast-R-CNN。YOLO的error中,目标定位错误占据的比例最大,比Fast-R-CNN高出了10个点。但是,YOLO在定位识别背景时准确率更高,可以看出Fast-R-CNN假阳性很高(Background=13.6%,即认为某个框是目标,但是实际里面不含任何物体)。
1.3.4 VOC2012准确率比较
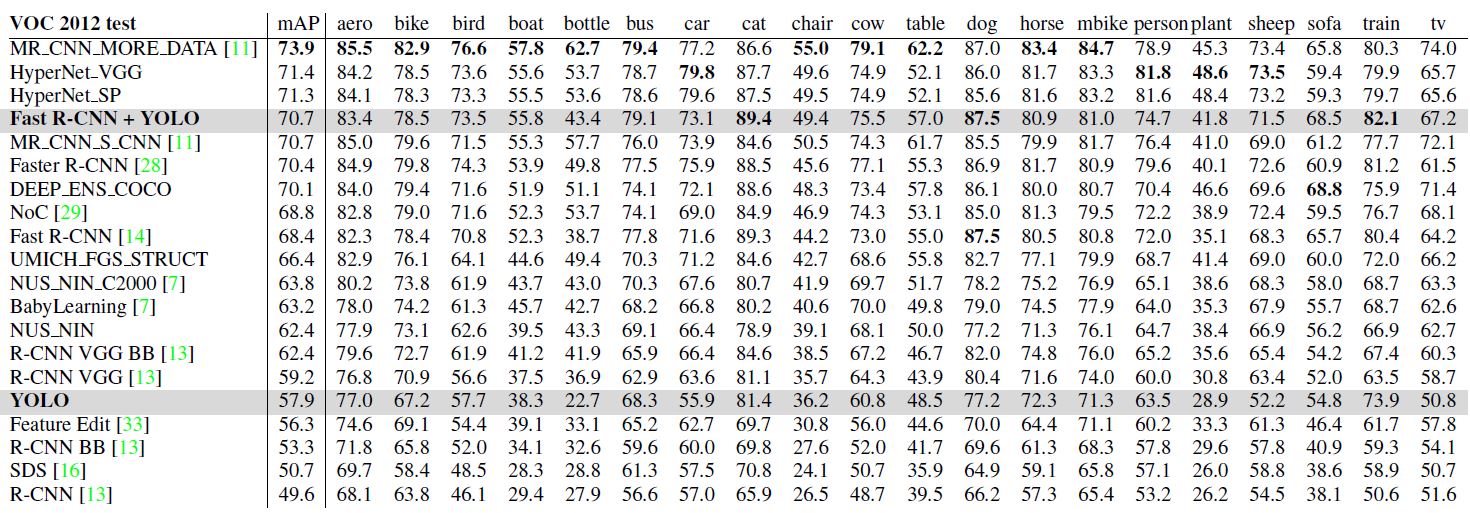
由于YOLO在目标检测和识别是处理背景部分优势更明显,因此作者设计了Fast-R-CNN+YOLO检测识别模式,即先用R-CNN提取得到一组bounding box,然后用YOLO处理图像也得到一组bounding box。对比这两组bounding box是否基本一致,如果一致就用YOLO计算得到的概率对目标分类,最终的bouding box的区域选取二者的相交区域。Fast-R-CNN的最高准确率可以达到71.8%,采用Fast-R-CNN+YOLO可以将准确率提升至75.0%。这种准确率的提升是基于YOLO在测试端出错的情况不同于Fast-R-CNN。虽然Fast-R-CNN_YOLO提升了准确率,但是相应的检测识别速度大大降低,因此导致其无法实时检测。
使用VOC2012测试不同算法的mean Average Precision,YOLO的mAP=57.9%,该数值与基于VGG16的RCNN检测算法准确率相当。对于不同大小图像的测试效果进行研究,作者发现:YOLO在检测小目标时准确率比R-CNN低大约8~10%,在检测大目标是准确率高于R-CNN。采用Fast-R-CNN+YOLO的方式准确率最高,比Fast-R-CNN的准确率高了2.3%。
1.4 总结
YOLO是一种支持端到端训练和测试的卷积神经网络,在保证一定准确率的前提下能图像中多目标的检测与识别。
[1] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection. In CVPR 2016
[2] Najibi M, Rastegari M, Davis L S. G-CNN: an Iterative Grid Based Object Detector. In CVPR 2016
[3] Gidaris S, Komodakis N. LocNet: Improving Localization Accuracy for Object Detection. In CVPR 2016
YOLO end-to-end的更多相关文章
- YOLO: Real-Time Object Detection
YOLO detection darknet框架使用 YOLO 训练自己的数据步骤,宁广涵详细步骤说明
- paper 111:图像分类物体目标检测 from RCNN to YOLO
参考列表 Selective Search for Object Recognition Selective Search for Object Recognition(菜菜鸟小Q的专栏) Selec ...
- YOLO: Real-Time Object Detection 安装和测试
1.下载darknet git clone https://github.com/pjreddie/darknet.git 2.修改make GPU= CUDNN= OPENCV= DEBUG= 3. ...
- [目标检测]YOLO原理
1 YOLO 创新点: 端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测 1.1 创新点 (1) 改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回 ...
- YOLO 算法框架的使用一(初级)
YOLO官方框架使用C写的,性能杠杠的,YOLO算法,我就不做过多介绍了.先简单介绍一下这个框架如何使用.这里默认是yolo2,yolo1接近过时.环境 推荐ubuntu 或者centos YOLO是 ...
- 读论文系列:Object Detection CVPR2016 YOLO
CVPR2016: You Only Look Once:Unified, Real-Time Object Detection 转载请注明作者:梦里茶 YOLO,You Only Look Once ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- TensorFlow + Keras 实战 YOLO v3 目标检测图文并茂教程
运行步骤 1.从 YOLO 官网下载 YOLOv3 权重 wget https://pjreddie.com/media/files/yolov3.weights 下载过程如图: 2.转换 Darkn ...
- YOLO: 3 步实时目标检测安装运行教程 [你看那条狗,好像一条狗!]
封面图是作者运行图,我在 ubuntu 环境下只有文字预测结果. Detection Using A Pre-Trained Model 使用训练好的模型来检测物体 运行一下命令来下载和编译模型 gi ...
- 【深度学习】目标检测算法总结(R-CNN、Fast R-CNN、Faster R-CNN、FPN、YOLO、SSD、RetinaNet)
目标检测是很多计算机视觉任务的基础,不论我们需要实现图像与文字的交互还是需要识别精细类别,它都提供了可靠的信息.本文对目标检测进行了整体回顾,第一部分从RCNN开始介绍基于候选区域的目标检测器,包括F ...
随机推荐
- PS合成的5个要点:场景、对比、氛围、模糊、纹理
是否觉得做合成打开PS之后无处下手,做完之后总觉得缺少故事情节?这一次分享的5个要点,是个人觉得需要重视的,每一点都有一个案例来让作品变得多一份惊喜.(申明:文中素材均来自网络,这里仅作分享交流作用) ...
- Java中 i++ 是线程安全的么?为什么?
问题 在 int i = 0; i = i++; 语句中,i = i++是线程安全的么?如果不安全,请说明上面操作在JVM中的执行过程,为什么不安全?说出JDK中哪个类能达到以上的效果,并且是线程安全 ...
- mapreduce的输入格式 --- InputFormat
InputFormat 接口决定了mapreduce如何切分输入文件. InputFormat 由getspilit和createRecordReader组成,getspilit主要是标记分片的初始位 ...
- keepalived配虚拟ip(vip)的作用
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议. 虚拟路由冗余协议,可以认为是实现路由器高可用的 ...
- Win 10 关闭了.net framework 3.5后再开启不成功
背景: Win10 想要使用IETester来测试下页面的浏览器兼容性.在“控制面板”里关闭了.net framework 3.5,再重新开启. 问题: 在重新开启的时候,提示不成功.错误代码0x80 ...
- windows下忘记mysql的root密码
1.停止mysql 2.命令行启动mysqlmysqld --defaults-file="c:\mysql\mysql server 5.1\my.ini" --console ...
- 20155312 张竞予 2006-2007-2 《Java程序设计》第四周学习总结
20155312 2006-2007-2 <Java程序设计>第四周学习总结 课堂笔记 Ctrl+shift+T调出三个窗口,分别是"vi编写代码","jav ...
- C#中的String类2
深入C# String类 C#中的String类 他是专门处理字符串的(String),他在System的命名空间下,在C#中我们使用的是string 小写的string只是大写的String的一个别 ...
- 建库,建表,添加数据 SQL命令
create database ssm default character set utf8; use ssm; create table flower( id int(10) primary key ...
- 深度优先搜索DFS和广度优先搜索BFS
DFS简介 深度优先搜索,一般会设置一个数组visited记录每个顶点的访问状态,初始状态图中所有顶点均未被访问,从某个未被访问过的顶点开始按照某个原则一直往深处访问,访问的过程中随时更新数组visi ...