[转帖]Kubernetes及容器编排的总体介绍【译】
Kubernetes及容器编排的总体介绍【译】

翻译自The New Stack《Kubernetes 生态环境》
作者:JANAKIRAM MSV和 KRISHNAN SUBRAMANIAN
仅仅在几年前,无论是旧的cgroup还是流行的Docker或者CNCF rkt,最可能发挥Linux容器功能的地方还是在一些开发人员笔记本上的隔离的沙盒环境中。通常它还只是一个实验环境,最多是个开发平台,根本就不是数据中心的一部分。
而今天,容器已经成为在生产环境中部署新的、基于云的应用程序的实际选择。在3到4年的时间内,现代应用程序部署的方式已经从虚拟的基于机器的云平台转变为有规模的有组织的容器群。
在本章中,我们将讨论在容器生态系统中的调度编排器(包括Kubernetes),介绍市场上的一些主要的编制工具,并描述它们的各种优点。
Kubernetes的来历
容器化的想法并不新鲜。某种形式的虚拟隔离,无论是出于安全性还是多租户的目的,自上世纪70年代以来就一直被用于数据中心里。
从chroot系统调用的出现开始,首先是在Unix,后来在BSD中,容器化的思想已经成为企业IT的通行做法的一部分。从FreeBSD的Jails到Solaris的zones到Warden到LXC,容器一直在不断发展,所有的过程都越来越接近成为采用的主流方案。
在容器在开发人员中流行之前,谷歌在Linux容器中运行它的一些核心web服务。2014年,Kubernetes创始人之一的Joe Beda在GlueCon的一次演讲中声称,谷歌在一周内启动了超过20亿个容器。谷歌管理容器的能力的秘密在于它的内部数据中心管理工具:Borg。
谷歌将Borg改造成一个通用的容器编排调度器,于2014年将其发布到开源社区,并将其捐赠给2015年Linux基金会的云计算基础(CNCF)项目。Red Hat、CoreOS、微软、中兴、Mirantis、华为、富士通、Weaveworks、IBM、Engine Yard和SOFTICOM都是该项目的主要贡献者。
在2013年Docker出现以后,容器的采用率发生了爆炸式增长,成为了那些想要实现IT基础设施现代化的企业的焦点。这种爆发的趋势有四个主要原因:
- 封装:Docker解决了容器的用户体验问题,使它们更容易打包应用程序。在Docker之前,处理容器是非常困难的(Warden是个例外,它是由云计算平台抽象出来的)。
- 分发:自从云计算的出现以来,现代应用程序体系结构逐渐变得更加分散。无论是初创公司还是大型组织机构,都受到DevOps这种新方法和合作精神的启发。近年来它们都已将注意力转向了微服务架构。容器比迄今为止的其他各种体系结构设计得更模块化,更适合于支持微服务。
- 可移植性:开发人员喜欢在任何地方构建应用程序并运行它——将代码从他们的笔记本电脑推向生产环境,并期望它们在没有重大修改的情况下以完全相同的方式工作。随着Docker周围广泛积累了更多的工具,其功能的广度和深度更有助于开发人员采用容器。
- 速度:尽管在Docker之前已经存在了容器化的形式,但它们在最初的实现中却启动非常缓慢——在LXC的情况下,经常会花费几分钟,而使用Docker则把时间缩短为几秒钟。
自2015年7月发布以来,Kubernetes已经成为最受欢迎的容器编排引擎。四大公共云服务提供商中有三家——谷歌、IBM和微软——都提供了一个基于Kubernetes的服务平台(CaaS)平台。而第四名亚马逊,则刚刚加入了CNCF,并有自己的计划来支持这个平台。尽管Amazon以EC2容器服务的形式拥有自己的托管容器平台,但是AWS以运行了最多Kubernetes集群而闻名。大型企业,如教育出版商Pearson,飞利浦的物联网设备部门,TicketMaster,eBay和纽约时报等公司都正在生产环境中运用了Kubernetes技术。
什么是编排?
虽然容器有助于提高开发人员的生产力,但编排工具为寻求优化DevOps和Ops投资的团队提供了许多好处。容器编制的一些好处包括:
- 高效的资源管理。
- 服务的无缝扩展。
- 高可用性。
- 在规模上操作开销较低。
- 一个声明式模型(对于大多数编制工具)减少了对更加自治化管理的阻碍。
- 操作式基础设施即服务(IaaS),但又具备类似平台即服务(PaaS) 可管理的功能。
容器解决了开发人员的生产力问题,使DevOps工作流变得可以无缝连接。开发人员可以创建Docker镜像、运行Docker容器并在该容器中开发代码。然而,对开发人员生产力的提升并不能自动转化为生产环境中的效率。
从开发人员的笔记本电脑的本地环境中分离出的生产环境比原有的规模要大得多。无论您运行成规模的多级应用程序或基于微服务的应用程序,管理大量的容器和支持它们的节点集群并非易事。编制是实现规模所需的组件,因为规模需要自动化。
云计算的分布式特性带来了我们如何感知虚拟机基础结构的典型转换。“牛与宠物”的观点——把一个容器当做牲畜类似的使用单元,而不是最喜欢的动物——帮助重塑了人们对基础设施根本的观念。把这个观念付诸实践,容器在规模上扩展和完善了收缩和资源可用性的定义。
典型的容器编排平台的基本特征包括:
- 调度
- 资源管理
- 服务发现
- 健康检查
- 自动伸缩
- 更新和升级
目前容器编排市场由开源软件主导。在本文出版的时候,Kubernetes依然是领导者。但在我们深入研究Kubernetes之前,我们应该花一点时间将其与市场上其他主要的编制工具进行比较。
Docker Swarm
Docker公司是负责最受欢迎的容器产品的公司,它提供Docker Swarm作为容器的编制工具。在Docker中,所有容器都是标准化的。在操作系统级别的每个容器的执行由runc处理,这是遵循Open Container Initiative(OCI)规范的实现。Docker与另一个开源组件“containerd”一起工作,以管理由runc在特定主机上执行的容器的生命周期。在一个主机操作系统上,Docker、containerd和runc执行程序负责处理容器操作。
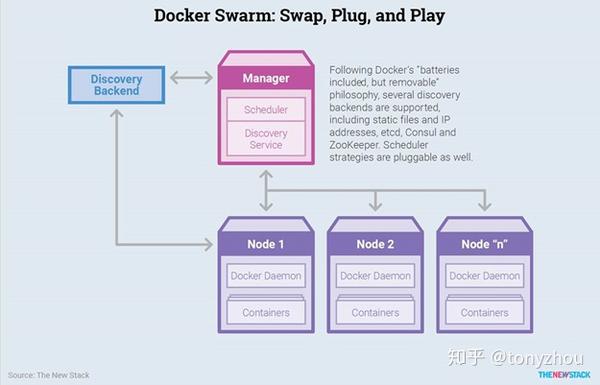 图1.1:典型的Docker Swarm主节点与工作节点之间的配置关系
图1.1:典型的Docker Swarm主节点与工作节点之间的配置关系
简单地说,Swarm——由Docker Swarm编排——是一组运行Docker的节点。如图1.1所示。Swarm中的一个节点充当其他节点的管理器,并包括调度程序和服务发现组件的容器。
Docker的理念要求在容器级别进行标准化,并使用Docker应用程序编程接口(API)来处理业务流程,包括底层基础设施的使用。Docker Swarm使用现有的Docker API和网络框架,而不扩展它们,结合Docker Compose工具而更适合构建多容器应用程序。它使开发人员和操作人员更容易将一个应用程序从5个或6个容器扩展到数百个。
注意:Docker Swarm使用Docker API,使它可以轻松地适应现有的容器环境。采用Docker Swarm可能意味着要在Docker上孤注一掷,目前,Swarm的调度器选项是有限的。
Apache Mesos
Apache
Mesos是一个开放源码的集群管理器,它的出现早于Docker Swarm和Kubernetes。再加上Marathon,一个用于基于容器的应用程序的编排框架,它为Docker Swarm和Kubernetes提供了一个有效的替代方案。Mesos也可以使用其他框架来同时支持容器化和非容器化的工作负载。
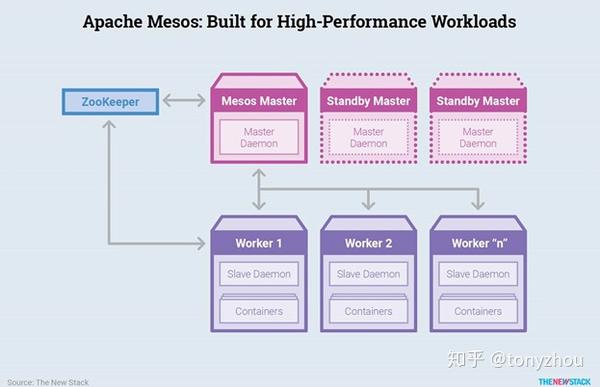 图1.2:Apache Mesos,构建多种多样、高性能的工作负载
图1.2:Apache Mesos,构建多种多样、高性能的工作负载
Mesos的平台,如图1.2所示,显示了节点之间的主/从关系。在这个方案中,分布式应用程序通过一个称为ZooKeeper的组件在集群之间进行协调。这个ZooKeeper的工作就是为一个集群选择控制节点,或者分配备用控制节点,并用代理逐步分配给每个其它节点。这些代理建立了主/从关系。在Master中,主守护进程建立了所谓的“框架”,它像桥梁一样,在主节点和工作节点之间延伸。运行在这个框架上的调度器确定了哪些工作节点可以接受资源,而守护进程则设置了要共享的资源。这是一个复杂的方案,但它的优点是能够适应多种类型和分布式负载的标准,而不仅仅是容器。
与Docker Swarm不同,Mesos和Marathon都有自己的API,这使得它们比其他编配工具更复杂。
然而,Mesos在支持Docker容器和虚拟机(如VMware vSphere和KVM)方面更加灵活。Mesos还支持支持大数据和高性能工作负载框架。
注意: Apache Mesos是混合环境的完美编配工具,它包含容器和非容器的工作负载。尽管Apache Mesos是稳定的,但许多人认为它为容器用户提供了更陡峭的学习曲线。
Kubernetes
Kubernetes最初是由谷歌发起的开源项目,现在是云计算基础(CNCF)的一部分,它可以用很低的运行开销对容器进行互联网级规模的无缝管理。
Kubernetes并不固定要求容器的格式,并且使用它自己的API和命令行接口(CLI)来进行容器编排。
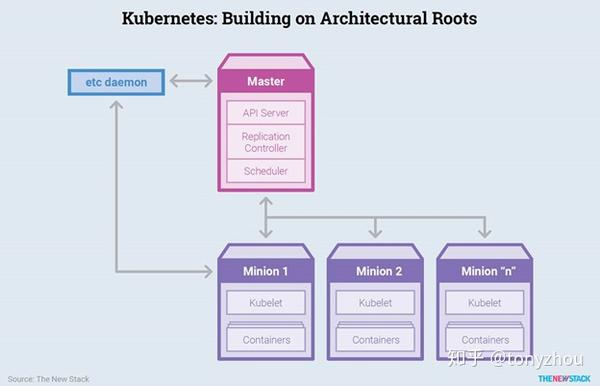 图1.3:Kubernetes的控制器与节点之间的关系,以前也称为“minions”
图1.3:Kubernetes的控制器与节点之间的关系,以前也称为“minions”
它支持多种容器格式,不只是包括Docker的,也支持rkt——最初由CoreOS创建,现在是CNCF托管的项目。该系统也是高度模块化且易于定制的,允许用户选择任何调度器、网络系统、存储系统和监控工具集。它以单个集群开始,并可以无缝地扩展到大规模的 Web应用。
我们之前提到的一个编排器的六个主要特征体现在Kubernetes中的以下方面中:
- 调度:Kubernetes调度程序确保在任何时候都可以满足对基础设施上的资源的需求。
- 资源管理:在Kubernetes的环境中,资源是编排器可以实例化和管理的逻辑结构,例如服务或应用程序部署。
- 服务发现:Kubernetes支持共享系统的服务,可以通过名称来发现。这样,包含服务的pods可以在整个物理基础结构中分布运行,而不必保留网络服务来定位它们。
- 健康检查:Kubernetes利用称为“活性探针”和“就绪探针”的功能,给编排器提供应用程序状态的周期性的指示。
- 自动伸缩:使用Kubernetes,当一个pod的指定CPU资源未被充分利用时,pod自动伸缩器能自动生成更多的副本。
- 更新/升级:一个自动化的滚动升级系统使每个Kubernetes的部署保持更新和稳定。
注意:Kubernetes是由一个非常活跃的社区建立的。它为用户提供了更多的选择来扩展编排引擎以满足他们的需求。由于它使用了自己的API,所以更熟悉Docker的用户将会遇到一些学习难点。
Kubernetes 体系结构
现在一个打包为一组容器的应用程序需要一个足够健壮的基础设施来处理集群的需求和动态编排的压力。这样的基础设施应该为跨主机的调度、监视、升级和重新定位容器提供支撑。它必须将底层的计算、存储和网络原语作为资源池来处理。每个容器的工作负载应该能够充分利用提供给它的资源,包括CPU内核、存储单元和网络。
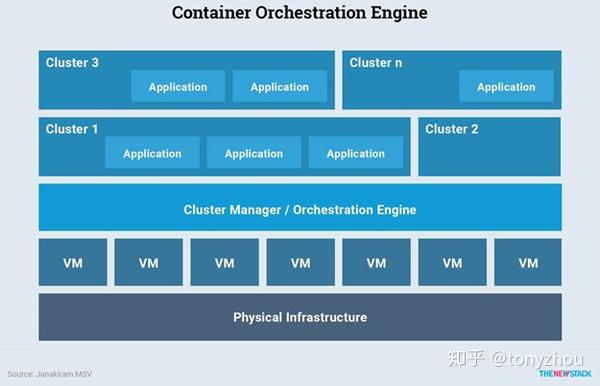 图1.4:从容器编制引擎的角度来看的系统资源层
图1.4:从容器编制引擎的角度来看的系统资源层
Kubernetes是一个开放源码的集群管理器,它封装了底层的物理基础设施,使其更容易在很大规模上运行容器应用程序。一个应用程序,通过Kubernetes的整个生命周期管理,是由一组pod成集合作并协调成一个单元工作的。一个高效的集群管理器层让Kubernetes能够有效地将这个应用程序与它的支持基础结构分离开来,如图1.4所示。一旦Kubernetes基础结构被完全配置好,DevOps团队就可以专注于管理已部署的工作负载,而不是管理底层资源池。
Kubernetes API可以用来创建提供微服务的关键构建块的组件。这些组件是自主的,这意味着它们独立于其他组件存在。它们被设计为松散耦合、可扩展和适用于各种工作负载。API为内部组件提供了这种扩展性,以及在Kubernetes上运行扩展组件和容器。
Pod
Pod是Kubernetes的工作负载管理的核心单元,它充当了共享相同运行环境和资源的容器的逻辑边界。将相关的容器分组到pod中,就可以弥补由于容器化取代了第一代虚拟化所带来的配置挑战,从而使其能够一起运行多个相互依赖的进程。
每个pod是一个或多个使用远程过程调用(RPC)进行通信的容器的集合,共享存储和网络堆栈。适用的场景是一些容器需要耦合和共存的应用——例如,一个web服务器容器和一个缓存容器。它们很容易被包装在一个pod里。一个pod可以手动伸缩,也可以通过称为水平pod自动伸缩(HPA)的特性来定义。通过这种方法,pod内包装的容器数量按比例增加。
Pod支持开发和部署之间的功能分离。当开发人员专注于他们的代码时,操作人员可以将注意力集中在更广阔的视角上,考虑相关容器可能被组合成一个功能单元。这样有助于达到可移植性的最佳数量,因为一个pod只是多个容器镜像像管理的一个清单。
服务
Kubernetes的服务模型依赖于微服务的最基本、最重要的方面:发现机制。
一个单独的pod或一个副本集(稍后解释)可以通过服务暴露给内部或外部客户,该服务将一组带有特定标准的pod联起来。任何其标签匹配选择器的pod将自动被服务发现。该体系结构提供了一种灵活的、松散耦合的服务发现机制。
当一个pod被创建时,它被分配一个只有在集群内访问的IP地址。但不能保证pod的IP地址在整个生命周期中保持不变。Kubernetes可以在运行时迁移或重新实例化pod,从而为pod提供一个新的IP地址。
为了解决这种不确定性,服务能确保路由到集群中适当的pod,而不考虑它的调度节点,每个服务公开一个IP地址,也可能公开一个DNS地址,这两个入口都不会改变。需要与一组pod进行通信的内部或外部用户将使用该服务的IP地址,或者更常见的DNS地址。这样,服务就充当了连接pod与其他pod的粘合剂的角色。
服务发现
Kubernetes中的任何API对象,包括一个节点或一个pod,都可能具有与其相关的键值对--用于标识和组合共享一个公共特征或属性的对象的附加的元数据。Kubernetes引用这些键值对作为标签。
选择器是用来查询与标签值匹配的Kubernetes对象的一种标准。这种强大的技术支持对象的松散耦合。可以生成新的对象,其标签与选择器的值相匹配。标签和选择器形成了Kubernetes的主要分组机制,用于标识操作应用的组件。
一个副本集依赖于标签和选择器来决定哪个pod将参与缩放操作。在运行时,可以通过副本集对pod进行缩放,确保每次部署都运行所需数量的pod。每个副本集始终维护一个预定义的pod集。
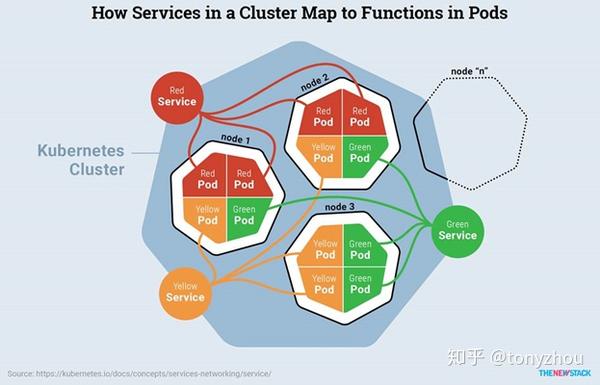 图1.5:Kubernetes集群关注的是pod,而它们以服务的方式提供给外面的世界
图1.5:Kubernetes集群关注的是pod,而它们以服务的方式提供给外面的世界
任何标签与服务定义的选择器相匹配的pod将可以被终端公开访问。当一个缩放操作由一个副本集发起时,由该操作创建的新pod将立即开始接收流量。然后,服务通过在匹配的pod中路由流量提供基本的负载平衡。
图1.5描述了服务发现如何在Kubernetes集群中工作。这里有三种类型的pod,由红、绿、黄相间的盒子代表。一个副本控制器已经扩展了这些pod,以在所有可用节点上运行实例。每个类的pod都通过一个由彩色圆圈表示的服务向客户发布。假设每个pod都有color=value的标签,它的相关服务将有一个匹配它的选择器。
当客户到达红色服务时,请求被路由到任何与标签color=red匹配的pod中。如果一个新的红色pod被缩放调度器产生,那么它将立即被服务发现,因为它的具有匹配的标签和选择器。
可以将服务配置为将pod公开给内部和外部的使用者。一个暴露给内部的服务可以通过一个ClusterIP地址获得,这个地址只能在集群中路由。不需要暴露给外部的数据库pod和其他敏感资源,可以配置为使用ClusterIP。当一个服务需要被外部访问时,它可能通过每个节点的特定端口来发布,这被称为NodePort。在公共云环境中,Kubernetes可以提供自动配置的负载平衡器,以便将流量路由到相应的节点。
Master控制节点
与大多数现代分布式计算平台一样,Kubernetes利用了一个主/从架构。 如图1.6所示,master封装了从API中运行应用程序的节点,这些节点是与编排调度器进行通信的。
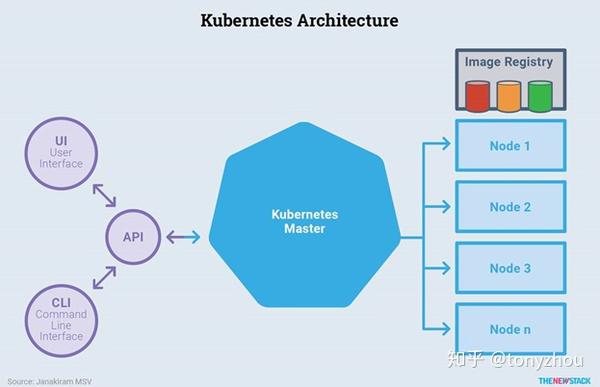 图1.6:Master 在Kubernetes体系结构中的位置
图1.6:Master 在Kubernetes体系结构中的位置
Master负责提供Kubernetes API,调度工作负载的部署,管理集群,并控制整个系统的通信。如图1.6所示,Master监视每个节点上运行的容器以及所有注册节点的健康状态。容器镜像作为可部署的构件,必须通过私有或公共的镜像(image)仓库让Kubernetes集群可以访问使用。负责调度和运行应用程序的节点从镜像仓库中获得应用服务的镜像。
如图1.7所示,Kubernetes Master运行以下组件,它们组成了控制面板:
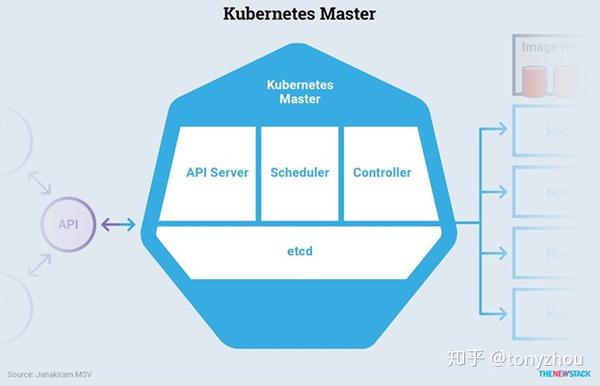 图1.7:Kubernetes Master的组件
图1.7:Kubernetes Master的组件
etcd
etcd是由CoreOS开发的,它是一个持久的、轻量级的、分布式的、键值的数据存储服务,它维护集群的配置数据。它表示在任何时间点上集群的总体状态,作为唯一的事实数据来源。其他各种组件和服务监视对etcd存储进行更改,以保持应用程序达到期望的状态。该状态由声明式策略(实际上是一个声明该应用程序的最佳环境的文件)定义,因此编排调度器可以通过一系列工作来获得该环境。该策略定义了编排调度器如何处理应用程序的各种属性,例如实例数量、存储需求和资源分配。
API Server
API服务器通过HTTP协议以JSON方式发布Kubernetes API,为编排调度器的内部和外部端点提供REST接口。CLI、web UI或其他工具可能向API服务器发出请求。服务器处理并验证请求,然后更新etcd中API对象的状态。这使得客户终端能够跨工作节点来配置工作负载和容器。
Scheduler 调度器
调度器基于对资源可用性评估来为每个pod选择运行的节点,然后跟踪资源利用率,以确保pod不会超过它分配的限额。它维护和跟踪资源需求、资源可用性以及各种其他用户提供的约束和策略指标;例如,服务质量(QoS)、亲和/反亲和性需求和局部性数据。操作团队可以声明式的定义资源模型。调度器将这些声明解释为为每个工作负载提供和分配正确资源集的指令。
Controller 控制器
控制器是Kubernetes体系结构的一部分,是Master的一部分。控制器的职责是确保集群始终保持节点和pod的期望状态。通过我们所说的期望状态,达到由pods的YAML配置文件所声明和请求使用的资源和系统的当前需求和约束的平衡。
控制器通过不断地监视集群的健康状况和部署在集群上的工作负载来维护节点和pod的稳定状态。例如,当一个节点变得不健康时,在该节点上运行的那些pod可能无法访问。在这种情况下,控制器的任务是在不同的节点中调度相同数量的新pod提供服务。这个活动确保集群在任何时间点都保持预期状态。
Kubernetes控制器在生产中运行容器化的工作负载时起着至关重要的作用,这使得一个团队可以部署和运行容器化的应用程序,这些应用程序复杂程度远远超出了典型的无状态和扩展的场景。控制器管理者负责管理核心Kubernetes控制器:
- ReplicationController(ReplicaSet) 维护集群中特定部署的pod数目。它保证任何时候都能有指定数量的pod在系统的节点上运行。
- StatefulSet有状态集类似于副本集,是对于需要持久性和定义良好的标识符的pod的定义。
- DaemonSet确保包在一个pod里的一个或多个容器被运行在集群的每个节点中。这是一种特殊类型的控制器,它强制一个pod在每个节点上运行。作为DaemonSet的一部分运行中的pod的数量与节点的数量成正比。
- Job和cron job 控制器处理后台进程和批处理进程。
这些控制器与API服务器通信,以创建、更新和删除它们管理的资源,如pod和服务节点。
关键型应用程序需要更高级别的资源可用性。通过使用一个副本集,Kubernetes确保了预定义的pod数量一直在运行。但这些pod是无状态的,短暂的。由于以下原因,很难运行有状态的工作负载,例如数据库集群或大数据栈:
- 每个pod在运行时分配一个任意名称。
- 在任何可用节点上都可以安排一个pod,除非使用关联规则,在这种情况下,pod只能在有特定标签或在规则中指定的标签的节点上调度。
- 在任何时间点都可以重新启动和重新定位。
- 一个pod可能永远不会被它的名称或IP地址直接引用。
从1.5版本开始,Kubernetes引入了有状态集(由StatefulSets表示)的概念,用于运行高可用的工作负载。参与有状态集的有状态pod具有以下属性:
- 一个稳定的主机名,它将永远由DNS解析。
- 一个序数索引号,用来表示副本集中的pod的顺序位置。
- 与主机名和序号相关联的稳定存储。
稳定的主机名及其序号索引号使一个pod能够以可预测和一致的方式与另一个pod进行通信。这是无状态pod和有状态pod之间的根本区别。
Node
节点是Kubernetes集群的工作站,负责运行容器化的工作负载;日志、监视和服务发现;和可选的附加组件。它的目的是向应用程序公开计算、网络和存储资源。每个节点包括一个容器运行时,例如Docker或rkt,以及与控制器Master通信的代理。节点可以是在云中运行的虚拟机(VM),也可以是数据中心内的实体机服务器。
如图1.8所示,每个节点包含以下内容:
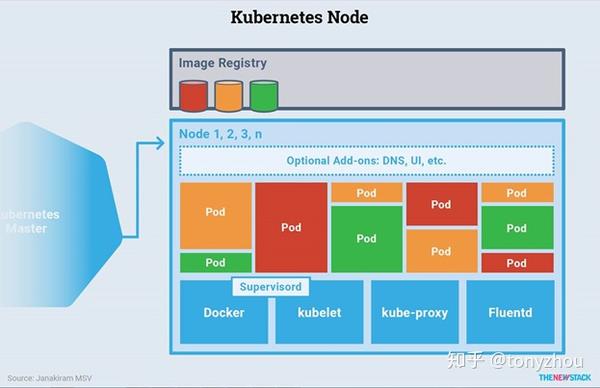 图1.8:显示了Kubernetes节点中的大量组件的一个分解视图
图1.8:显示了Kubernetes节点中的大量组件的一个分解视图
容器运行器
容器运行器负责在节点中运行的每个容器的生命周期管理。在节点上安排了一个pod之后,容器运行器就会从镜像仓库中拉取出pod所指定的镜像。当一个pod被终止时,运行器将杀死属于该pod的容器。Kubernetes可以与任何兼容OCI的容器运行器进行通信,包括Docker和rkt。
Kubelet
kubelet是确保节点上所有容器都健康运行的组件。它与容器运行器进行通信,以执行诸如启动、停止和维护容器等操作。
每个kubelet还监测pod的状态。当一个pod不满足副本控制器定义的理想状态时,它可能在相同的节点上被重新启动。节点的状态每隔几秒通过心跳消息传递给控制器。如果控制器检测到节点故障,副本控制器会观察到这个状态的变化,并将这些pod安排到其他健康的节点上。
Kube-proxy
kube-proxy组件是作为一个网络代理和负载均衡器来实现的。它根据IP地址和传入请求的端口号将流量路由到合适的容器。它还利用了基于os的特定网络功能,通过操作iptables定义的策略和规则。每个kube-proxy都可以与特定容器的网络层集成,如flannel和Calico。
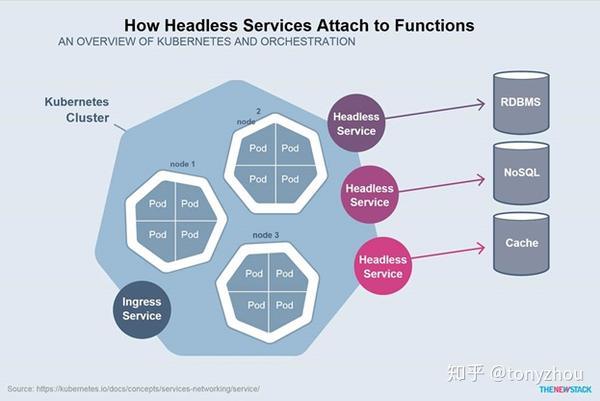 图1.9:headless服务提供状态数据库和服务之间的连接点
图1.9:headless服务提供状态数据库和服务之间的连接点
可以使用一个名为headless服务的东西直接将pod用于外部服务,如缓存、对象存储和数据库。如图1.9所示,这本质上与服务是一样的,但不需要使用kube-proxy或负载平衡。对headless服务的调用将解析为服务专门选择的集群的IP地址。通过这种方式,您可以使用自定义的逻辑来选择IP地址,绕过正常的路由。
Logging Layer
编排调度器经常使用日志记录作为在每个节点上收集资源使用和性能指标的方法,例如CPU、内存、文件和网络使用。CNCF定义了一个统一的日志层,用于Kubernetes或其他的编排调度器,称为Fluentd。该组件产生的原因是Kubernetes 主节点控制器需要跟踪可用的集群资源,以及整个基础设施的健康状态。
Add-Ins
Kubernetes支持附加插件形式的服务。这些可选的服务(如DNS和仪表板)与其他应用程序一样部署,但与诸如Fluentd和kube-proxy等节点上的其他核心组件集成。例如,仪表板外接程序从Fluentd提取指标,以充分的显示资源利用率。DNS插件通过名称解析扩展了kube-proxy。
区分各种Kubernetes平台
自从云计算成为现代企业的规范以来,系统架构师一直困惑如何平衡云平台应该采用的封装方式。适当的封装可以提高操作效率,同时提高开发人员的生产力。
在云计算的早期,虚拟机是计算的基本单元。最终用户被迫在所谓的IaaS+平台之间进行选择,比如AWS,以及像Heroku、Engine Yard、Cloud Foundry和OpenShift这样的PaaS平台。封装级别决定了开发人员对平台底层基础结构的直接控制程度。更深层次的封装意味着开发人员需要使用平台提供的API来驱动编码。
现在,容器作为计算的基本单元出现了,用户也面临着类似的问题,关于选择正确封装级别的需求。正如下面的表格所示,在容器编排领域有许多不同类型的Kubernetes发行版。用户的需求——包括工作环境、专业知识的可用性以及用户正在处理的特定场境——将确定是把容器作为服务(CaaS)还是封装的平台的重要考虑因素。没有一个简单明了的框架能够保证完美的满足一切需求。但表1.1可能是一个开始。
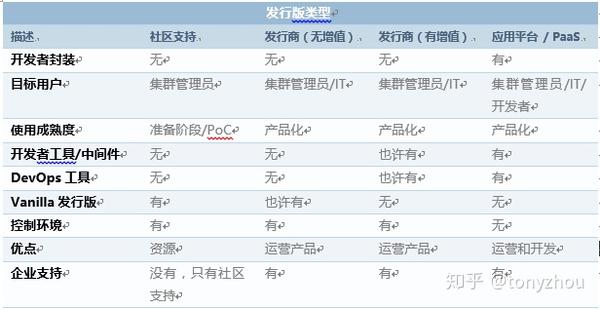 表1.1:Kubernetes发行类型的比较,从完全社区生产到完全商业化
表1.1:Kubernetes发行类型的比较,从完全社区生产到完全商业化
一个CaaS平台包括Kubernetes项目,和为其部署和管理提供所需的额外工具。一个封装好的平台,在规模化的另一端,远远超出了CaaS提供的运营效率,专注于提高开发人员的生产力。在CaaS中,开发人员需要将他们自己的代码打包到一个容器中,以便它可以部署在集群中。尽管基于docker的容器在开发人员的名义上解决了这个打包问题,封装好的应用程序平台还可以在内部完全封装构建容器映像的过程——自动化过程,而不是由开发人员那样手动控制。一旦他把他的代码Push到像GitHub这样的源代码控制工具上,或者像Jenkins这样的持续集成/持续交付(CI/ CD)系统里,开发人员的任务就停止了,而交给平台做其余的事情。
通过设计,CaaS与Kubernetes开源项目紧密地结合在一起,帮助它大规模的运行和管理容器。但CaaS模型希望开发人员能够处理所有应用程序的依赖项。从文化的角度来看,DevOps模型遵循了Dev和Ops一起与跨功能知识协同工作的文化。在这个场景中,两个团队都知道的是完成一件事是需要依赖很长的列表。
封装好的应用程序平台使用Kubernetes作为核心组件,帮助它以比CaaS更少的开销运行容器。开发人员不必担心管理运行时或任何应用程序依赖项。相反,他们可以专注于编写应用程序代码并将其推送到源代码控制存储库或CI/CD系统。封装好的平台提高了开发人员的生产力,同时削减了底层组件的控制。可以说DevOps仍然是这个模型的中心。但由于封装,并不需要这种跨功能的知识——它变成了冗余的繁杂工作。开发人员不需要了解Kubernetes的基础,也不需要了解如何管理它。
正如我们前面提到的,在CaaS和封装好平台之间选择不存在简单的框架。您的选择取决于您的团队希望达到的开发生产力水平和您所能预见的团队的特定需求集合。
开始使用Kubernetes
这里有一些方法可以开始Kubernetes的部署:
- 注册一个托管的CaaS服务。
- 下载并安装一个单处理器的安装程序,用于在单个PC上测试Kubernetes,比如CoreOS’Tectonic Sandbox。
- 通过克隆Kubernetes GitHub repo建立一个本地集群
- 尝试一下Kubernetes集群,Play withKubernetes,这将给你一个完整的Kubernetes环境,你可以从你的浏览器运行。
包括IBM Bluemix、谷歌云平台和微软Azure在内的公共云服务提供商提供了托管的Kubernetes作为服务。通过免费的积分和试用优惠,我们很容易就能把一个小的Kubernetes集群用来进行测试。有关在Kubernetes部署第一个应用程序的详细信息,请参阅您选择的服务的文档。
Minikube是一个单节点Kubernetes集群,用于学习和探索环境。它是强烈推荐给过去没有经验的初学者。
在功能更强大的主机上,Kubernetes可以被配置为基于Vagrant的多节点集群。GitHub repo有关于设置Vagrant boxes的说明。
[转帖]Kubernetes及容器编排的总体介绍【译】的更多相关文章
- 三小时学会Kubernetes:容器编排详细指南
三小时学会Kubernetes:容器编排详细指南 如果谁都可以在三个小时内学会Kubernetes,银行为何要为这么简单的东西付一大笔钱? 如果你心存疑虑,我建议你不妨跟着我试一试!在完成本文的学习后 ...
- [转载]三小时学会Kubernetes:容器编排详细指南
原翻译by梁晓勇 原英文:Learn Kubernetes in Under 3 Hours: A Detailed Guide to Orchestrating Containers 我很奇怪,为什 ...
- kubernetes(k8s)容器编排工具基础概念
Kubernetes (K8s): 中文社区:https://www.kubernetes.org.cn/replication-controller-kubernetes 官网:https://ku ...
- docker kubernetes Swarm容器编排k8s CICD部署
1docker版本 docker 17.09 https://docs.docker.com/ appledeAir:~ apple$ docker version Client: Docker En ...
- kubernetes容器编排系统介绍
版权声明:本文由turboxu原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/152 来源:腾云阁 https://www. ...
- 一文带你看透kubernetes 容器编排系统
本文由云+社区发表 作者:turboxu Kubernetes作为容器编排生态圈中重要一员,是Google大规模容器管理系统borg的开源版本实现,吸收借鉴了google过去十年间在生产环境上所学到的 ...
- K8s(一)----容器编排工具基础概念
kubernetes(k8s)容器编排工具基础概念 Kubernetes (K8s): 中文社区:https://www.kubernetes.org.cn/replication-controlle ...
- K8S - 容器编排工具Kubernetes简介
1 - Kubernetes Kubernetes(简称K8s,用8代替8个字符"ubernete")是Google开源的一个容器编排引擎. 目前最为广泛且流行的容器编排调度系统, ...
- [转帖]两大容器管理平台,Kubernetes与OpenShift有什么区别?
两大容器管理平台,Kubernetes与OpenShift有什么区别? https://www.sohu.com/a/327413642_100159565 原来openshift 就是 k8s的一个 ...
随机推荐
- Lr原理初识-hc课堂笔记
showslow web服务器-apache.ngix devops 需求调研-占1/3的时间. 架构拓扑图 APP端测试工具:JT.Vtest 进程是管理单元.线程是执行单元. 虚拟用户和真实用户是 ...
- OC4J Configuration issue. /u01...dbhome_1/oc4j/j2ee/OC4J_DBConsole_orcl-db-01_orcl not found.
emctl start dbconsole 报错信息: OC4J Configuration issue. /u01/app/Oracle/product/11.2.0/dbhome_1/oc4j/j ...
- collate字段详细讲解
collate可以在库级别上,表级别上,列级别上设计:意思就是“排列规则”;通常和charset结合使用: 例如: 建议使用utf8mb4而不是utf8,因为utf8最多支持3字节得长度,但是有些字符 ...
- android 7.0以上共享文件(解决调用系统照相和图片剪切出现的FileUriExposedException崩溃问题)
在android7.0开始试共享“file://”URI 将会导致引发 FileUriExposedException. 如果应用需要与其他应用共享私有文件,则应该使用 FileProvider, F ...
- Xcode 备忘
一. 打印一堆乱七八糟的东西: Edit Scheme... --> Run --> Arguments,在 Environment Variables 里添加 OS_ACTIVITY_M ...
- Android SurfaceView概述
简介:SurfaceView继承自View,但它与View不同,View是在UI主线程中更新画面,而SurfaceView是在一个新线程中更新画面,View的特性决定了其不适合做动画,因为如果更新画面 ...
- EF(EF Core)中的NotMappedAttribute(转载)
NotMapped特性可以应用到EF实体类的属性中,Code-First默认的约定,是为所有带有get,和set属性选择器的属性创建数据列..NotManpped特性打破了这个约定,你可以使用NotM ...
- ubuntu14.04上设置默认python命令是执行python3而不是Python2
update-alternatives --install /usr/bin/python python /usr/bin/python2 100 update-alternatives --inst ...
- Redis Replication
Replication 官网说明:http://www.redis.io/topics/replication Redis使用异步复制; 一个Master可以有多个Slaves; Slaves可以接收 ...
- 20155222卢梓杰 实验五 MSF基础应用
实验五 MSF基础应用 1.一个主动攻击实践,如ms17_010_eternalblue漏洞; 本次攻击目标是win7虚拟机 首先进行相应配置 然后点launch 就成功了 针对win7的漏洞还是相对 ...