8.2Solr API使用(Facet查询)
转载请出自出处:http://eksliang.iteye.com/blog/2165882
一)概述
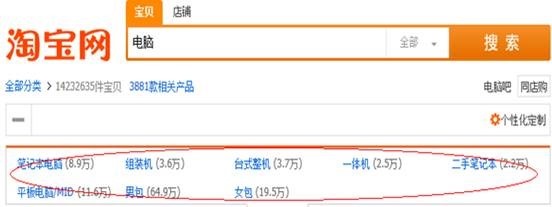
Facet是solr的高级搜索功能之一,可以给用户提供更友好的搜索体验.在搜索关键字的同时,能够按照Facet的字段进行分组并统计。例如下图所示,你上淘宝,输入“电脑”进行搜索,就会出现品牌分类,价格范围等分类,这个就叫Facet。
二)Solr Facet类型
Solr提供了4种类型的Fact
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>
1. facet_queries:代表自定义条件查询facet,类似数据库的count函数
2. facet_fields :代表根据字段分组查询,类似数据库的group by count的组合
3. facet_dates :根据日期区间分组查询
4. facet_ranges:当然了,日期有区间,数字也有,这个就是根据数字分组查询
三)Solr Facet组件
Solr的默认requestHandler已经包含了Facet组件(solr.FacetComponent).如果自定义requestHandler或者对默认的requestHandler自定义组件列表,那么需要将Facet加入到组件列表中去.
四)facet query
Facet Query 用户自定义条件查询facet,他提供了非常灵活的Facet.通过facet.query参数,可以对任意字段进行筛选.下面通过实例来阐述。基本上他的用法,都会在我实例中体现出来
例一:日期区间查询
&facet=true
&facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]
&facet.query=date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z]
返回结果如下:
<lst name="facet_counts">
<lst name="facet_queries">
<int name="date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]">5</int>
<int name="date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z]">3</int>
</lst>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
</lst>
例2:数字区间统计
&facet=on
&facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]
&facet.query=price:[* TO 5000]
返回结果
<lst name="facet_counts">
<lst name="facet_queries">
<int name="date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]">5</int>
<int name="price:[* TO 5000]">116</int>
</lst>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
</lst>
例3:自定义条件
&facet=true
&facet.query=brand:联想 AND price:1100
返回结果
"facet_counts":{
"facet_queries":{
"brand:联想 AND price:1100":1},
"facet_fields":{},
"facet_dates":{},
"facet_ranges":{}}}
五)Field Facet
Facet字段通过在请求中加入facet.field参数加以声明,如果需要对多个字段进行Facet查询,那么将该参数声明多次.这就是类似于数据库的group by 加上count的功能,非常的灵活。
实例一:最简单的field facet
&facet=true
&facet.field=brand
&facet.field=price
返回结果如下
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"brand":[
"苹果",4,
"联想",3,
"惠普",2],
"price":[
"1100.0",2,
"2200.0",2,
"3300.0",2,
"1200.0",1,
"2100.0",1,
"4400.0",1]},
"facet_dates":{},
"facet_ranges":{}}}
从返回结果可以看出各个field字段互不影响;而且可以针对,下面实例会体现
每个Facet字段设置查询参数.以下介绍的参数既可以应用于所有的Facet字段,也可以应用于每个单独的Facet字段.应用于单独的字段时通过下面语法实现
1. f.字段名.参数名=参数值
例如:将facet.prefix参数应用于brand字段,可以采用如下形式
&facet.field=brand
&facet.field=price
&f.brand.facet.prefix=联
返回结果如下:
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"brand":[
"联想",3],
"price":[
"1100.0",2,
"2200.0",2,
"3300.0",2,
"1200.0",1,
"2100.0",1,
"4400.0",1]},
"facet_dates":{},
"facet_ranges":{}}}
温馨提示:上面的facet.prefix就是一个参数名,这个很容易误解为两个,因为他中间有个点
上面介绍了facet.field参数,下面介绍field fact的其他参数
1).facet.prefix
表示Facet字段值的前缀.比如facet.field=cpu&facet.prefix=Intel,那么对cpu字段进行Facet查询,返回的cpu都是以“Intel”开头的。
2).facet.sort
表示Facet字段值以哪种顺序返回.可接受的值为true(count)|false(index,lex). true(count)表示按照count降序; false(index,lex)表示按照字段值升序(字母,数字的顺序)排列.默认情况下为true(count).当facet.limit值为负数时,默认facet.sort= false(index,lex).
3).facet.limit
限制Facet字段返回的结果条数.默认值为100.如果此值为负数,表示不限制.
4).facet.offset
返回结果集的偏移量,默认为0.它与facet.limit配合使用可以达到分页的效果.
5).facet.mincount
限制了Facet字段值的最小count,默认为0.合理设置该参数可以将用户的关注点集中在少数比较热门的领域.相当于group by having
6).facet.missing
默认为””,如果设置为true或者on,那么将统计那些该Facet字段值为null的记录.
7).facet.method
取值为enum或fc,默认为fc.该字段表示了两种Facet的算法,与执行效率相关.
enum适用于字段值比较少的情况,比如字段类型为布尔型,或者字段表示中国的所有省份.Solr会遍历该字段的所有取值,并从filterCache里为每个值分配一个filter(这里要求solrconfig.xml里对filterCache的设置足够大).然后计算每个filter与主查询的交集.
fc(表示Field Cache)适用于字段取值比较多,但在每个文档里出现次数比较少的情况.Solr会遍历所有的文档,在每个文档内搜索Cache内的值,如果找到就将Cache内该值的count加1.
8).facet.enum.cache.minDf
当facet.method=enum时,此参数其作用,minDf表示minimum document frequency.也就是文档内出现某个关键字的最少次数.该参数默认值为0.设置该参数可以减少filterCache的内存消耗,但会增加总的查询时间(计算交集的时间增加了).如果设置该值的话,官方文档建议优先尝试25-50内的值.
六) Date Facet
日期类型的字段在文档中很常见,如商品上市时间,货物出仓时间,书籍上架时间等等.某些情况下需要针对这些字段进行Facet.不过时间字段的取值有无限性,用户往往关心的不是某个时间点而是某个时间段内的查询统计结果. Solr为日期字段提供了更为方便的查询统计方式.当然,字段的类型必须是DateField(或其子类型)。
需要注意的是,使用Date Facet时,字段名,起始时间,结束时间,时间间隔这4个参数都必须提供.与Field Facet类似,Date Facet也可以对多个字段进行Facet.并且针对每个字段都可以单独设置参数。
简单实例参考
&facet.date=birthday
&facet.date.start=2014-01-00T09:15:00Z
&facet.date.end=2014-12-00T09:15:00Z
&facet.date.gap=%2B1MONTH
返回结果如下所示
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_dates":{
"birthday":{
"2013-12-31T09:15:00Z":0,
"2014-01-31T09:15:00Z":0,
"2014-02-28T09:15:00Z":0,
"2014-03-28T09:15:00Z":0,
"2014-04-28T09:15:00Z":0,
"2014-05-28T09:15:00Z":0,
"2014-06-28T09:15:00Z":0,
"2014-07-28T09:15:00Z":0,
"2014-08-28T09:15:00Z":0,
"2014-09-28T09:15:00Z":1,
"2014-10-28T09:15:00Z":5,
"2014-11-28T09:15:00Z":3,
"gap":"+1MONTH",
"start":"2013-12-31T09:15:00Z",
"end":"2014-12-28T09:15:00Z"}},
"facet_ranges":{}}}
Date Facet参数说明
1).facet.date
该参数表示需要进行Date Facet的字段名,与facet.field一样,该参数可以被设置多次,表示对多个字段进行Date Facet.
2).facet.date.start
起始时间,时间格式为1995-12-31T23:59:59Z
3).facet.date.end
结束时间.
4).facet.date.gap
时间间隔.如果start为2009-1-1,end为2010-1-1.gap设置为+1MONTH表示间隔1个月,那么将会把这段时间划分为12个间隔段.
注意+因为是特殊字符所以应该用%2B代替.
5).facet.date.hardend
取值可以为true|false,默认为false.它表示gap迭代到end处采用何种处理.举例说明start为2009-1-1,end为2009-12-25,gap为+1MONTH,
hardend为false的话最后一个时间段为2009-12-1至2010-1-1;
hardend为true的话最后一个时间段为2009-12-1至2009-12-25.
6).facet.date.other
取值范围为before|after|between|none|all,默认为none,before会对start之前的值做统计,after会对end之后的值做统计,between会对start至end之间所有值做统计.如果hardend为true的话,那么该值就是各个时间段统计值的和.none表示该项禁用.all表示before,after,all都会统计.
实例参考,演示fact.date.other、跟单独对某个字段起作用
&facet.date=birthday
&facet.date.start=2014-01-00T09:15:00Z
&facet.date.end=2014-12-00T09:15:00Z
&facet.date.gap=%2B1MONTH
&facet.date.other=all
&f.birthday.facet.mincount=3 --单独对某个字段起作用,把统计值小于3的过滤掉
返回结果如下:
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_dates":{
"birthday":{
"2014-10-28T09:15:00Z":5,
"2014-11-28T09:15:00Z":3,
"gap":"+1MONTH",
"start":"2013-12-31T09:15:00Z",
"end":"2014-12-28T09:15:00Z",
"before":0,
"after":0,
"between":9}},
"facet_ranges":{}}}
七)Facet Range
范围统计分组统计,跟Date Facet一样,只是他们定位的字段的类型不同,Data Fact是做日期的分组统计的,而Fact Range是做数字分组统计的,在次强调,是做数字分组统计的,对于字符串,日期是不可以的。
参数跟上面的Date Facet基本一致,如下,就不做解释了,参考Date Facet的各个参数
1. facet.range
2. facet.range.start
3. facet.range.end
4. facet.range.gap
5. facet.range.hardend
6. facet.range.other
7. facet.range.include
参考实例
&facet.range=price
&facet.range.start=1000
&facet.range.end=5000
&facet.range.gap=1000
&f.price.facet.mincount=2--单独对某个字段起作用,把统计值小于2的过滤掉
返回结果如下:
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_dates":{},
"facet_ranges":{
"price":{
"counts":[
"1000.0",3,
"2000.0",3,
"3000.0",2],
"gap":1000.0,
"start":1000.0,
"end":5000.0}}}}
八)key 操作符
上面已经介绍了facet的四类统计,下面介绍一下key,什么是key?
答:key操作符可以为Facet字段取一个别名。哦原来如此简单!
参考实例:
参数
&facet=true
&facet.query=brand:联想 AND price:1100
返回结果
"facet_counts":{
"facet_queries":{
"brand:联想 AND price:1100":1},
"facet_fields":{},
"facet_dates":{},
"facet_ranges":{}}}
参数
&facet=true
&facet.query={!key=联想}brand:联想 AND price:1100
返回结果
"facet_counts":{
"facet_queries":{
"联想":1},
"facet_fields":{},
"facet_dates":{},
"facet_ranges":{}}}
从上面可以看出来,这样可以让字段名统一起来,方便我们拿到请求数据后,封装成自己的对象
九)tag操作符和ex操作符
这个也非常的重要,看下应用场景,当查询使用filter query 或者q的时候,如果filter query的字段正好是Facet字段,那么查询结果往往被限制在某一个值内.
参考实例
&fq=price:[1000 TO 2000]
&facet.field=price
返回结果
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"price":[
"1100.0",2,
"1200.0",1,
"2100.0",0,
"2200.0",0,
"3300.0",0,
"4400.0",0]},
"facet_dates":{},
"facet_ranges":{}}}
从返回的结果可以看到fq将查询的结果集限制在了price 在1000 至 2000之间,其他范围的统计没有实际意义。
有些时候,用户希望把结果限制在某一个范围以内,又希望查看该范围外的概况,像上述情况,用户想把结果限制在(price)1000~2000之间,但是又想查看其他价格区间有多少产品。这个时候需要用到tag和ex操作符.tag就是把一个filter标记起来,ex(exclude)是在Facet的时候把标记过的filter排除在外.
参考实例
&fq={!tag=aa}price:[1000 TO 2000]
&facet.field={!ex=aa}price
返回结果
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"price":[
"1100.0",2,
"2200.0",2,
"3300.0",2,
"1200.0",1,
"2100.0",1,
"4400.0",1]},
"facet_dates":{},
"facet_ranges":{}}}
这样其它价格区间的统计信息就有意义了.
十)Facet 字段设计
一、Facet字段的要求
Facet的字段必须被索引.一般来说该字段无需分词,无需存储.
无需分词是因为该字段的值代表了一个整体概念,如电脑的品牌”联想”代表了一个整体概念,如果拆成”联”,”想”两个字都不具有实际意义.另外该字段的值无需进行大小写转换等处理,保持其原貌即可.
无需存储是因为一般而言用户所关心的并不是该字段的具体值,而是作为对查询结果进行分组的一种手段,用户一般会沿着这个分组进一步深入搜索.
二、特殊情况
对于一般查询而言,分词和存储都是必要的.比如CPU类型“Intel 酷睿2双核 P7570”,拆分成“Intel”,“酷睿”,“P7570”这样一些关键字并分别索引,可能提供更好的搜索体验.但是如果将CPU作为Facet字段,最好不进行分词.这样就造成了矛盾,解决方法为,将CPU字段设置为不分词不存储,然后建立另外一个字段为它的COPY,对这个COPY的字段进行分词和存储.
<types>
<fieldType name="string" class="solr.StrField" omitNorms="true"/>
<fieldType name="tokened" class="solr.TextField" >
<analyzer>
……
</analyzer>
</fieldType>
</types>
<fields>
<field name="cpu" type="string" indexed="true" stored="false"/>
<field name="cpuCopy” type=" tokened" indexed="true" stored="true"/>
</fields>
<copyField source="cpu" dest="cpuCopy"/>
官网API: http://wiki.apache.org/solr/SimpleFacetParameters
8.2Solr API使用(Facet查询)的更多相关文章
- SolrNet高级用法(分页、Facet查询、任意分组)
前言 如果你在系统中用到了Solr的话,那么肯定会碰到从Solr中反推数据的需求,基于数据库数据生产索引后,那么Solr索引的数据相对准确,在电商需求中经常会碰到菜单.导航分类(比如电脑.PC的话会有 ...
- Solr学习总结(六)SolrNet的高级用法(复杂查询,分页,高亮,Facet查询)
上一篇,讲到了SolrNet的基本用法及CURD,这个算是SolrNet 的入门知识介绍吧,昨天写完之后,有朋友评论说,这些感觉都被写烂了.没错,这些基本的用法,在网上百度,资料肯定一大堆,有一些写的 ...
- Dynamics CRM 2015/2016 Web API:聚合查询
各位小伙伴们,今天是博主2016年发的第一篇文章.首先祝大家新年快乐.工资Double,哈哈.今天我们来看一个比較重要的Feature--使用Web API运行FetchXML查询! 对的,各位.你们 ...
- solr facet查询及solrj 读取facet数据(相当有用)
原文出自:http://www.coin163.com/java/docs/201310/d_3010029802.html 一. Facet 简介 Facet 是 solr 的高级搜索功能之一 ...
- lucene搜索之facet查询原理和facet查询实例——TODO
转自:http://www.lai18.com/content/7084969.html Facet说明 我们在浏览网站的时候,经常会遇到按某一类条件查询的情况,这种情况尤以电商网站最多,以天猫商城为 ...
- solr facet查询及solrj 读取facet数据[转]
solr facet查询及solrj 读取facet数据 | 所属分类:solr facet solrj 一. Facet 简介 Facet 是 solr 的高级搜索功能之一 , 可以给用户提供更 ...
- 调用API接口,查询手机号码归属地(3)
从mysql数据库获取电话号码,查询归属地并插入到数据库 #!/usr/bin/python # -*- coding: utf-8 -*- import json, urllib, sys, pym ...
- 调用API接口,查询手机号码归属地(2)
使用pymysql pip install pymysql 创建mysql测试表 CREATE TABLE `userinfo` ( `id` int(20) NOT NULL AUTO_INCREM ...
- 调用API接口,查询手机号码归属地(1)
使用https://www.juhe.cn/提供的接口,查询归属地 在官网注册key即可使用. 代码如下 #!/usr/bin/python # -*- coding: utf-8 -*- impor ...
随机推荐
- .39-浅析webpack源码之parser.parse
因为换了个工作,所以博客停了一段时间. 这是上个月留下来的坑,webpack的源码已经不太想看了,又臭又长,恶心的要死,想去看node的源码……总之先补完这个 上一节完成了babel-loader对J ...
- Docker配置阿里云加速地址
首先需要注册一个阿里云账号,只要注册账号就可以,不用充钱购买任何阿里云服务! 打开阿里云网站https://cr.console.aliyun.com,登陆自己的阿里云账号. 然后只需要在服务器配置d ...
- Extjs 项目中常用的小技巧,也许你用得着(5)--设置 Ext.data.Store 传参的请求方式
1.extjs 给怎么给panel设背景色 设置bodyStyle:'background:#ffc;padding:10px;', var resultsPanel = Ext.create('Ex ...
- LoRa术语
ADR Adaptive Data Rate 自适应数据率 AES Advanced Encryption Standard 高级加密标准 AFA ...
- C# 往线程里传参数的方法总结
Thread (ParameterizedThreadStart) 初始化 Thread 类的新实例,指定允许对象在线程启动时传递给线程的委托. Thread (ThreadStart) 初始化 ...
- Navicat相关应用及注意事项
一.MySQL数据类型 1.数值型 SMALLINT: 2个字节 INT: 4个字节 // age int(10) INTEGER:INT的同义词 BIGINT : 8个字节 FLOAT : ...
- js点击获取标签元素
14.数组去重 方法一:利用冒泡 function elementName(evt){ evt = evt|| window.event; // IE: window.event // IE用src ...
- js之展开收缩菜单,用到window.onload ,onclick,
目标效果:点击标签1,如果列表标签的style的display是block,改成none,否则改成block,来达到展开收缩菜单效果 一.准备阶段 html文件 <!DOCTYPE html&g ...
- grafana-simple-json-datasource 用于连接各种grafana不支持的数据源
https://grafana.com/plugins/grafana-simple-json-datasource 1.安装方法很简单,下载后解压放到plugins目录就好. 我的是解决版的graf ...
- 火狐hr标签的兼容性问题
想在盒子里加一条白色横线 加了以下代码 页面效果如下<hr style="width:80%;height:1px;border:none;border-top:1px solid # ...