《利用python进行数据分析》读书笔记--第九章 数据聚合与分组运算(一)
http://www.cnblogs.com/batteryhp/p/5046450.html
对数据进行分组并对各组应用一个函数,是数据分析的重要环节。数据准备好之后,通常的任务就是计算分组统计或生成透视表。groupby函数能高效处理数据,对数据进行切片、切块、摘要等操作。可以看出这跟SQL关系密切,但是可用的函数有很多。在本章中,可以学到:
- 根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象
- 计算分组摘要统计,如计数、平均值、标准差、,或自定义函数
- 对DataFrame的列应用各种各样的函数
- 应用组内转换或其他运算,如规格化、线性回归、排名或选取子集等
- 计算透视表和交叉表
- 执行分位数分析以及其他分组分析
对时间数据的聚合也称重采样(resampling),在第十章介绍。
1、GroupBy技术
很多数据处理过程都经历“拆分-应用-合并”的过程。即根据一个或多个键进行分组、每一个应用函数、再进行合并。
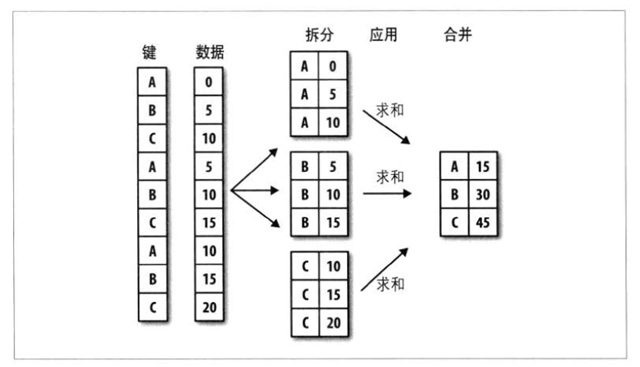
分组键有多种形式:
- 列表或数组,长度与待分组的轴一样
- 表示DataFrame某个列明的值
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系
- 函数,用于处理轴索引或索引中的各个标签
下面开始写例子。
- 简单实例

#-*- encoding: utf-8 –*-
#分组实例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
print df,'\n'
#根据key1进行分组,并计算data1的均值。
#注意下面的方式,取出来进行分组,而不是在DataFrame中分组,这种方式很灵活
#可以看到这是一个GroupBy对象,具备了应用函数的基础
#这个过程是将Seri进行聚合,产生了新的Series
grouped = df['data1'].groupby(df['key1'])
print grouped,'\n'
print grouped.mean(),'\n'
means = df['data1'].groupby([df['key1'],df['key2']]).mean()
print means,'\n' #得到一个层次化索引的DataFrame
print means.unstack(),'\n'
#上面的分组键均为Series,实际上,分组键可以是任何长度适当的数组,很灵活
states = np.array(['Ohio','California','California','Ohio','Ohio'])
years = np.array([2005,2005,2006,2005,2006])
print df['data1'].groupby([states,years]).mean(),'\n'
#还可以用列名(可以是字符串、数字或其他python对象)用作分组键
print df.groupby('key1').mean(),'\n' #这里将数值型的列都进行了mean,非数值型的忽略
print df.groupby(['key1','key2']).mean(),'\n'
#groupby以后可以应用一个很有用的size方法
print df.groupby(['key1','key2']).size(),'\n' #截止翻译版为止,分组键中的缺失值被排除在外
>>>
data1 data2 key1 key2
0 1.489789 -1.548474 a one
1 -1.000447 -0.187066 a two
2 0.254255 -0.960017 b one
3 1.279892 1.124993 b two
4 -0.366753 0.139047 a one
<pandas.core.groupby.SeriesGroupBy object at 0x03A895B0>
key1
a 0.040863
b 0.767073
key1 key2
a one 0.561518
two -1.000447
b one 0.254255
two 1.279892
key2 one two
key1
a 0.561518 -1.000447
b 0.254255 1.279892
California 2005 -1.000447
2006 0.254255
Ohio 2005 1.384841
2006 -0.366753
data1 data2
key1
a 0.040863 -0.532165
b 0.767073 0.082488
data1 data2
key1 key2
a one 0.561518 -0.704714
two -1.000447 -0.187066
b one 0.254255 -0.960017
two 1.279892 1.124993
key1 key2
a one 2
two 1
b one 1
two 1
[Finished in 0.7s]
- 对分组进行迭代
#-*- encoding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)}) #对分组进行迭代,groupby对象支持迭代
#下面是迭代?……不过就是将分组的结果分别赋值给两个量?不是这样的,下面的循环会打印两个one print df.groupby('key1')
for name,group in df.groupby('key1'):
print 'one'
print name
print group,'\n' #多重键的情况,元组的第一个元素将会是由键值组成的元组,下面会打印四个two
#也就是说,下面的三个print是一个组合,打印key值这一点挺好
for (k1,k2),group in df.groupby(['key1','key2']):
print 'two'
print k1,k2
print group,'\n'
#当然,可以对数据片段进行操作
#转换为字典,应该是比较有用的一个转换方式
print list(df.groupby('key1')),'\n'
pieces = dict(list(df.groupby('key1')))
#注意下面的字典中的每个值仍然是一个“含有名称的DataFrame”,可能不严谨,但是就是这意思
print pieces['a'],'\n'
print type(pieces['a'])
print pieces['a'][['data1','data2']],'\n'
#groupby默认在axis = 0上进行分组,可以设置在任何轴上分组
#下面用dtype对列进行分组
print df.dtypes,'\n'
grouped = df.groupby(df.dtypes,axis = 1)
print grouped,'\n'
print dict(list(grouped)) #有点像把不同数值类型的列选出来
>>>
<pandas.core.groupby.DataFrameGroupBy object at 0x0333CEB0>
one
a
data1 data2 key1 key2
0 -0.984933 0.392220 a one
1 -2.104506 4.120798 a two
4 -0.267432 -1.825800 a one
one
b
data1 data2 key1 key2
2 0.476850 -1.738739 b one
3 -0.863738 -0.458431 b two
two
a one
data1 data2 key1 key2
0 -0.984933 0.39222 a one
4 -0.267432 -1.82580 a one
two
a two
data1 data2 key1 key2
1 -2.104506 4.120798 a two
two
b one
data1 data2 key1 key2
2 0.47685 -1.738739 b one
two
b two
data1 data2 key1 key2
3 -0.863738 -0.458431 b two
[('a', data1 data2 key1 key2
0 -0.984933 0.392220 a one
1 -2.104506 4.120798 a two
4 -0.267432 -1.825800 a one), ('b', data1 data2 key1 key2
2 0.476850 -1.738739 b one
3 -0.863738 -0.458431 b two)]
data1 data2 key1 key2
0 -0.984933 0.392220 a one
1 -2.104506 4.120798 a two
4 -0.267432 -1.825800 a one
<class 'pandas.core.frame.DataFrame'>
data1 data2
0 -0.984933 0.392220
1 -2.104506 4.120798
4 -0.267432 -1.825800
data1 float64
data2 float64
key1 object
key2 object
<pandas.core.groupby.DataFrameGroupBy object at 0x033F0190>
{dtype('object'): key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one, dtype('float64'): data1 data2
0 -0.984933 0.392220
1 -2.104506 4.120798
2 0.476850 -1.738739
3 -0.863738 -0.458431
4 -0.267432 -1.825800}
[Finished in 0.7s]
- 选取一个或一组列
#-*- encoding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
print df,'\n' #对于由DataFrame产生的GroupBy对象,如果用一个或一组列名进行索引,就能实现选取部分列进行聚合的目的,即
#下面语法效果相同
print df.groupby('key1')['data1'] #又一次选取方式的区分,这条语句返回Series,下一条返回DataFrame
print df.groupby('key1')[['data1']]
#下面的
print df['data1'].groupby(df['key1'])
print df[['data1']].groupby(df['key1']),'\n'
#尤其对于大数据集,可能只是对部分列进行聚合。比如,想计算data2的均值并返回DataFrame
print df.groupby(['key1','key2'])[['data2']].mean(),'\n'
>>>
data1 data2 key1 key2
0 -1.381889 0.919518 a one
1 -0.186802 1.265642 a two
2 -0.173303 0.866173 b one
3 0.015841 -0.601375 b two
4 -0.281338 -0.319804 a one
<pandas.core.groupby.SeriesGroupBy object at 0x039EB970>
<pandas.core.groupby.DataFrameGroupBy object at 0x039EB930>
<pandas.core.groupby.SeriesGroupBy object at 0x039EB930>
<pandas.core.groupby.DataFrameGroupBy object at 0x039EB950>
data2
key1 key2
a one 0.299857
two 1.265642
b one 0.866173
two -0.601375
[Finished in 0.7s]
- 通过字典或Series进行分组
#-*- encoding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame people = DataFrame(np.random.randn(5,5),columns = ['a','b','c','d','e'],index = ['Joe','Steve','Wes','Jim','Travis'])
people.ix[2:3,['b','c']] = np.nan #加点NaN
print people,'\n'
#假设已经知道列的分组方式,现在需要利用这个信息进行分组统计:
mapping = {'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
#下面为groupby传入一个已知信息的字典
by_column = people.groupby(mapping,axis = 1)
print by_column.sum(),'\n' #注意得到的名字是 red 和 blue
#Series也有这样的功能,被看作一个固定大小的映射,可以用Series作为分组键,pandas会自动检查对齐
map_series = Series(mapping)
print map_series,'\n'
print people.groupby(map_series,axis = 1).count()
>>>
a b c d e
Joe -0.344808 0.716334 1.092892 0.824548 0.206477
Steve 0.457156 -0.207056 -0.447555 -0.378811 -0.581657
Wes -0.739237 NaN NaN -1.168591 0.876174
Jim 0.116797 -1.888764 2.072722 0.029644 0.919705
Travis -0.482019 1.479823 0.706617 0.697408 -0.914512
blue red
Joe 1.917440 0.578003
Steve -0.826367 -0.331557
Wes -1.168591 0.136937
Jim 2.102366 -0.852261
Travis 1.404025 0.083292
a red
b red
c blue
d blue
e red
f orange
blue red
Joe 2 3
Steve 2 3
Wes 1 2
Jim 2 3
Travis 2 3
[Finished in 0.6s]
- 利用函数进行分组
#-*- encoding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame #相较于字典或Series,python函数在定义分组映射关系时可以更有创意且更为抽象。
#函数会在各个索引值上调用一次,并根据结果进行分组。
people = DataFrame(np.random.randn(5,5),columns = ['a','b','c','d','e'],index = ['Joe','Steve','Wes','Jim','Travis'])
print people.groupby(len).sum() #名字长度相同的人进行加和
#将函数、数组、字典、Series混用也ok,因为最终都会转换为数组
key_list = ['one','one','one','two','two']
print people.groupby([len,key_list]).min()
>>>
a b c d e
3 0.528550 0.245731 1.187483 -1.086821 0.042086
5 -2.579143 0.152800 -0.911028 0.328152 0.627507
6 2.328199 -1.091351 -1.198069 0.571550 0.794774
a b c d e
3 one -0.444315 0.559996 -1.486260 0.090243 -1.131864
two -0.601314 -1.389457 1.616836 -1.366003 1.495320
5 one -2.579143 0.152800 -0.911028 0.328152 0.627507
6 two 2.328199 -1.091351 -1.198069 0.571550 0.794774
[Finished in 1.5s]
- 根据索引级别分组
#-*- encoding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame #层次化索引数据集最方便的地方就在于它能够根据索引级别进行聚合。要实现该目的,只要通过level关键字传入级别编号或名称即可
columns = pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],[1,3,5,1,3]],names = ['cty','tenor'])
hier_df = DataFrame(np.random.randn(4,5),columns = columns)
print hier_df,'\n'
print hier_df.groupby(level = 'cty',axis = 1).count(),'\n'
print hier_df.groupby(level = 'tenor',axis = 1).count(),'\n'
print hier_df.groupby(level = ['cty','tenor'],axis = 1).count()
>>>
cty US JP
tenor 1 3 5 1 3
0 0.211478 0.076928 -1.225755 0.080232 1.472201
1 0.159280 0.504315 0.741466 2.263926 0.771153
2 -0.759615 0.550016 -1.476229 1.838213 -0.509156
3 0.987656 0.238239 0.537588 -0.126640 0.252719
cty JP US
0 2 3
1 2 3
2 2 3
3 2 3
tenor 1 3 5
0 2 2 1
1 2 2 1
2 2 2 1
3 2 2 1
cty JP US
tenor 1 3 1 3 5
0 1 1 1 1 1
1 1 1 1 1 1
2 1 1 1 1 1
3 1 1 1 1 1
[Finished in 1.2s]
2、数据聚合
这里的数据聚合是说任何能够从数组产生标量值的过程。之前的例子已经用到了一些,比如mean()、count()、min()、max()等。常见的聚合运算都有就地计算数据集统计信息的优化实现。当然并不止这些,可以用自己定义的运算,还可以调用分组对象上已经定义好的任何方法。例如,quantile可以计算Series或DataFrame列的样本分位数。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
#print df
grouped = df.groupby('key1')
#注意下面的quantile并没有直接实现于GroupBy,它是一个Series方法,故而能用,
#就是说,此过程实际上是groupby对df进行高效切片,然后对每个切片应用quantile
print grouped['data1'].quantile(0.9),'\n'
#对于自己定义的聚合函数,只需将其传入aggregate或agg即可
#注意下面是对每列都应用
def peak_to_peak(arr):
return arr.max() - arr.min()
print grouped.agg(peak_to_peak),'\n'
#有些方法(describe)也是可以应用的。
print grouped.describe()
#自定义函数比经过优化的函数要慢得多,这是因为在构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)
#下面说明更高级的聚合功能,用的是R语言reshape2包中的数据集tips,这数据是从R中自己导出来的
tips = pd.read_csv('E:\\tips.csv')
#增加小费占比一列
tips['tip_pct'] = tips['tip'] / tips['total_bill']
print tips.head()
>>>
key1
a 0.970028
b 0.642314
data1 data2
key1
a 1.502016 1.583056
b 0.495911 0.384405
data1 data2
key1
a count 3.000000 3.000000
mean 0.304136 0.822614
std 0.802148 0.792578
min -0.284158 0.007541
25% -0.152726 0.438623
50% -0.021293 0.869705
75% 0.598283 1.230151
max 1.217858 1.590597
b count 2.000000 2.000000
mean 0.443950 0.425535
std 0.350662 0.271816
min 0.195994 0.233332
25% 0.319972 0.329433
50% 0.443950 0.425535
75% 0.567927 0.521636
max 0.691905 0.617737
total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female False Sun Dinner 2 0.059447
1 10.34 1.66 Male False Sun Dinner 3 0.160542
2 21.01 3.50 Male False Sun Dinner 3 0.166587
3 23.68 3.31 Male False Sun Dinner 2 0.139780
4 24.59 3.61 Female False Sun Dinner 4 0.146808
[Finished in 0.7s]
经过优化的GroupBy的方法,按作者的意思,这些函数是快的。

- 面向列的多函数应用
有时候需要对不同的列应用不同的函数,或者对一列应用不同的函数。下面是例子。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt #下面说明更高级的聚合功能,用的是R语言reshape2包中的数据集tips,这数据是从R中自己导出来的
tips = pd.read_csv('E:\\tips.csv')
#增加小费占比一列
tips['tip_pct'] = tips['tip'] / tips['total_bill']
print tips.head(),'\n'
grouped = tips.groupby(['sex','smoker'])
grouped_pct = grouped['tip_pct']
print grouped_pct.agg('mean'),'\n'
#若传入一组函数或函数名,得到的DataFrame的列就会以相应的函数命名
def peak_to_peak(arr):
return arr.max() - arr.min()
#对比例这一列应用三个函数
print grouped_pct.agg(['mean','std',peak_to_peak]),'\n'
#上面有个问题就是列名是自动给出的,以函数名为列名,若传入元组
#(name,function)组成的列表,就会自动将第一个元素作为列名
print grouped_pct.agg([('foo','mean'),('bar',np.std)]),'\n' #注意np.std不能加引号
#还可以对多列应用同一函数
functions = ['count','mean','max']
result = grouped['tip_pct','total_bill'].agg(functions) #对两列都应用functions
print result,'\n' #得到的结果的列名是层次化索引,可以直接用外层索引选取数据
print result['tip_pct'],'\n'
ftuples = [('DDD','mean'),('AAA',np.var)]
print grouped['tip_pct','total_bill'].agg(ftuples),'\n'
#如果想对不同的列应用不同的函数,具体的办法是向agg传入一个从列映射到函数的字典
print grouped.agg({'tip':np.max,'size':sum}),'\n' #sum这样的函数可以加引号或者不加
print grouped.agg({'tip':['min','max','mean','std'],'size':sum})
>>>
total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female False Sun Dinner 2 0.059447
1 10.34 1.66 Male False Sun Dinner 3 0.160542
2 21.01 3.50 Male False Sun Dinner 3 0.166587
3 23.68 3.31 Male False Sun Dinner 2 0.139780
4 24.59 3.61 Female False Sun Dinner 4 0.146808
sex smoker
Female False 0.156921
True 0.182150
Male False 0.160669
True 0.152771
Name: tip_pct
mean std peak_to_peak
sex smoker
Female False 0.156921 0.036421 0.195876
True 0.182150 0.071595 0.360233
Male False 0.160669 0.041849 0.220186
True 0.152771 0.090588 0.674707
foo bar
sex smoker
Female False 0.156921 0.036421
True 0.182150 0.071595
Male False 0.160669 0.041849
True 0.152771 0.090588
tip_pct total_bill
count mean max count mean max
sex smoker
Female False 54 0.156921 0.252672 54 18.105185 35.83
True 33 0.182150 0.416667 33 17.977879 44.30
Male False 97 0.160669 0.291990 97 19.791237 48.33
True 60 0.152771 0.710345 60 22.284500 50.81
count mean max
sex smoker
Female False 54 0.156921 0.252672
True 33 0.182150 0.416667
Male False 97 0.160669 0.291990
True 60 0.152771 0.710345
tip_pct total_bill
DDD AAA DDD AAA
sex smoker
Female False 0.156921 0.001327 18.105185 53.092422
True 0.182150 0.005126 17.977879 84.451517
Male False 0.160669 0.001751 19.791237 76.152961
True 0.152771 0.008206 22.284500 98.244673
size tip
sex smoker
Female False 140 5.2
True 74 6.5
Male False 263 9.0
True 150 10.0
tip size
min max mean std sum
sex smoker
Female False 1.00 5.2 2.773519 1.128425 140
True 1.00 6.5 2.931515 1.219916 74
Male False 1.25 9.0 3.113402 1.489559 263
True 1.00 10.0 3.051167 1.500120 150
[Finished in 0.7s]
- 以‘无索引’的方式返回聚合数据
到目前为止,示例中的聚合数据都是由唯一的分组键组成的索引(可能还是层次化的)。由于并不是总需要如此,可以向groupby传入as_index = False禁用该功能。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt tips = pd.read_csv('E:\\tips.csv')
#增加小费占比一列
tips['tip_pct'] = tips['tip'] / tips['total_bill']
print tips.head(),'\n'
print tips.groupby(['sex','smoker'],as_index = False).mean() #这里的形式可能有时候更好用
>>>
total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female False Sun Dinner 2 0.059447
1 10.34 1.66 Male False Sun Dinner 3 0.160542
2 21.01 3.50 Male False Sun Dinner 3 0.166587
3 23.68 3.31 Male False Sun Dinner 2 0.139780
4 24.59 3.61 Female False Sun Dinner 4 0.146808
sex smoker total_bill tip size tip_pct
0 Female False 18.105185 2.773519 2.592593 0.156921
1 Female True 17.977879 2.931515 2.242424 0.182150
2 Male False 19.791237 3.113402 2.711340 0.160669
3 Male True 22.284500 3.051167 2.500000 0.152771
[Finished in 0.6s]
3、分组级运算和转换
聚合只是分组运算中的一种,它是数据转换的一个特例。也就是说,它只是接受能够将一维数组简化为标量值的函数。本节将介绍transform和apply方法,能够执行更多其他的分组运算。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt #下面为DataFrame添加一个用于存放各索引分组平均值的列。一个办法是先聚合在合并:
df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
#print df,'\n'
k1_means = df.groupby('key1').mean().add_prefix('mean_')
print k1_means,'\n'
#下面用左边的key1作为连接键,right_index是将右边的行索引作为连接键
print pd.merge(df,k1_means,left_on = 'key1',right_index = True)
#上面的方法虽然也行,但是不灵活。可以看作利用mean函数对数据的两列进行转换。 people = DataFrame(np.random.randn(5,5),columns = ['a','b','c','d','e'],index = ['Joe','Steve','Wes','Jim','Travis'])
print people,'\n'
key = ['one','two','one','two','one']
print people.groupby(key).mean(),'\n'
#看下面神奇的事情
print people.groupby(key).transform(np.mean),'\n'
#不难看出,transform会将一个函数应用到各个分组并将结果放置到适当的位置,
#如果各分组产生的是一个标量值,则改值就会被广播出去
#下面的例子很说明问题,很灵活
def demean(arr):
return arr - arr.mean()
demeaned = people.groupby(key).transform(demean)
print demeaned,'\n'
#下面检查一下demeaned各组均值是否为0
print demeaned.groupby(key).mean()
>>>
mean_data1 mean_data2
key1
a -0.729610 -0.141770
b -0.174505 0.484952 data1 data2 key1 key2 mean_data1 mean_data2
0 -2.082417 0.752055 a one -0.729610 -0.141770
1 -0.563339 -0.915167 a two -0.729610 -0.141770
4 0.456927 -0.262198 a one -0.729610 -0.141770
2 -0.173514 1.695344 b one -0.174505 0.484952
3 -0.175496 -0.725440 b two -0.174505 0.484952
a b c d e
Joe -1.109408 -0.379178 -0.666847 2.003109 -1.331988
Steve 0.316630 -1.801337 -0.479510 0.305003 1.641795
Wes 0.338475 -0.613742 -0.623375 -0.423722 -0.529741
Jim 0.206591 -0.876095 0.297528 -0.177179 0.208701
Travis -1.307377 0.144524 0.236289 0.382082 0.497277 a b c d e
one -0.69277 -0.282799 -0.351311 0.653823 -0.454817
two 0.26161 -1.338716 -0.090991 0.063912 0.925248 a b c d e
Joe -0.69277 -0.282799 -0.351311 0.653823 -0.454817
Steve 0.26161 -1.338716 -0.090991 0.063912 0.925248
Wes -0.69277 -0.282799 -0.351311 0.653823 -0.454817
Jim 0.26161 -1.338716 -0.090991 0.063912 0.925248
Travis -0.69277 -0.282799 -0.351311 0.653823 -0.454817 a b c d e
Joe -0.416638 -0.096379 -0.315536 1.349286 -0.877171
Steve 0.055020 -0.462621 -0.388519 0.241091 0.716547
Wes 1.031245 -0.330943 -0.272064 -1.077544 -0.074924
Jim -0.055020 0.462621 0.388519 -0.241091 -0.716547
Travis -0.614607 0.427322 0.587599 -0.271741 0.952094 a b c d e
one 0 -1.850372e-17 -3.700743e-17 1.850372e-17 0
two 0 -5.551115e-17 0.000000e+00 0.000000e+00 0
[Finished in 0.7s]
- apply:一般性的“拆分-应用-合并”
本节就是说apply函数很重要,是最一般化的GroupBy方法。跟aggregate一样,transform也是一个有着严格条件的特殊函数:传入的函数只能产生两种结果,要么是可以广播的标量,要么是产生一个相同大小的结果数组。apply函数将对象拆分为多个片段,对各个片段调用传入的函数,并尝试将各片段合到一起。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt tips = pd.read_csv('E:\\tips.csv')
#增加小费占比一列
tips['tip_pct'] = tips['tip'] / tips['total_bill']
#print tips.head(),'\n'
#下面找出指定列的最大的几个值,然后将所在行选出来
def top(df,n = 5,column = 'tip_pct'):
return df.sort_index(by = column)[-n:]
print top(tips,n = 6),'\n'
#如果对smoker分组并用该函数调用apply
print tips.groupby('smoker').apply(top),'\n'
#上面实际上是在各个片段上调用了top,然后用pd.concat进行了连接,并以分组名称进行了标记,于是就形成了层次化索引
#当然可以向top函数传入参数
print tips.groupby(['smoker','day']).apply(top,n = 1,column = 'total_bill')
#需要说明的是:apply很强大,需要发挥想象力,它只需返回一个pandas对象或者标量值即可
#之前曾经这么做过:
result = tips.groupby('smoker')['tip_pct'].describe()
print result,'\n'
print result.unstack('smoker'),'\n'
#下面的方式,效果一样
f = lambda x : x.describe()
print tips.groupby('smoker')['tip_pct'].apply(f),'\n'
#对所有列都行
print tips.groupby('smoker').apply(f),'\n'
#看的出,上面自动生成了层次化索引,可以将分组键去掉
print tips.groupby('smoker',group_keys = False).apply(top),'\n'
#下面看得出,重新设置索引会去掉原来所有索引,并重置索引
print tips.groupby('smoker').apply(top).reset_index(drop = True),'\n'
#下面看的出来,as_index在这里并不管用
print tips.groupby('smoker',as_index = False).apply(top),'\n'
#下面看的出来,as_index在这里并不管用
print tips.groupby(['sex','smoker'],as_index = False).apply(top),'\n'
- 分位数和桶分析
第七章中的cut和qcut函数可以对数据进行拆分,现在将其与groupby集合起来会轻松实现对数据集的桶(bucket)(嗯,注意名字)或分位数(quantile)分析了。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt frame = DataFrame({'data1':np.random.randn(1000),'data2':np.random.randn(1000)})
print frame.head(),'\n'
factor = pd.cut(frame.data1,4)
print factor[:10],'\n'
#cut返回的对象可直接用于groupby(很合理)
def get_stats(group):
return {'min':group.min(),'max':group.max(),'count':group.count(),'mean':group.mean()}
grouped = frame.data2.groupby(factor)
print grouped.apply(get_stats),'\n'
print grouped.apply(get_stats).unstack(),'\n'
#上面的桶是区间大小相等的桶,要想得到数据量相等的桶,用qcut即可。
grouping = pd.qcut(frame.data1,10)
#print grouping
#labels = False 标明只返回各个值所在的分组编号,而不是所在的各个分组,感觉这样更好
grouping = pd.qcut(frame.data1,10,labels = False)
#print grouping,'\n'
grouped = frame.data2.groupby(grouping)
print grouped.apply(get_stats).unstack()
《利用python进行数据分析》读书笔记--第九章 数据聚合与分组运算(一)的更多相关文章
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
- Python 数据分析—第九章 数据聚合与分组运算
打算从后往前来做笔记 第九章 数据聚合与分组运算 分组 #生成数据,五行四列 df = pd.DataFrame({'key1':['a','a','b','b','a'], 'key2':['one ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- 【python】《利用python进行数据分析》笔记
[第三章]ipython C-a 到行首 C-e 到行尾 %timeit 测量语句时间,%time是一次,%timeit是多次. %pdb是自动调试的开关. %debug中,可以用b 12在第12行设 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据聚合和分组运算(1)-GroupBy Mechanics
前言 Python的pandas包提供的数据聚合与分组运算功能很强大,也很灵活.<Python for Data Analysis>这本书第9章详细的介绍了这方面的用法,但是有些细节不常用 ...
- Python之数据聚合与分组运算
Python之数据聚合与分组运算 1. 关系型数据库方便对数据进行连接.过滤.转换和聚合. 2. Hadley Wickham创建了用于表示分组运算术语"split-apply-combin ...
- 《利用Python 进行数据分析》 - 笔记(4)----json
解决方案: 读写文本格式的数据: pandas 提供了一些用于将表格型数据读取为DataFrame对象的函数 pandas 中的解析函数 函数的选项可以划分为以下几个大类 索引:将一个或多个列当做返回 ...
- 利用python进行数据分析之数据聚合和分组运算
对数据集进行分组并对各分组应用函数是数据分析中的重要环节. group by技术 pandas对象中的数据会根据你所提供的一个或多个键被拆分为多组,拆分操作是在对象的特定轴上执行的,然后将一个函数应用 ...
随机推荐
- Linux-002-执行命令时,提示: -bash: {命令}: command not found
首先,此文不适应未安装的命令. 起因: 进行系统环境变量配置时,路径分割符配置错误,错将":"配置为";". 现象: 任意用户执行命令时,提示:command ...
- 发布Live Writer代码着色插件CNBlogs.CodeHighlighter
在解决了使用Windows Live Writer发博所遇到的"建分类.加标签.写摘要"与"设置EntryName"的四个问题之后,我们趁热打铁,解决了第五个问 ...
- RSA加密
1.RSA的公钥和私钥到底哪个才是用来加密和哪个用来解密? 答:公钥加密私钥可解,私钥加密公钥可解. 2.RSA非对称加密特点? 答:算法强度复杂.加密解密速度比对称加密解密的速度慢.一个公钥,对外开 ...
- Spring MVC配置
web配置 <?xml version="1.0" encoding="UTF-8"?><web-app xmlns:xsi="ht ...
- SpringMVC操作指南-登录功能与请求过滤
[1] Source http://code.taobao.org/p/LearningJavaEE/src/LearningSpringMVC005%20-%20Login%20and%20Filt ...
- C语言数据类型取值范围
一.获取数据类型在系统中的位数 在不同的系统中,数据类型的字节数(bytes)不同,位数(bits)也有所不同,那么对应的取值范围也就有了很大的不同,那我们怎么知道你当前的系统中C语言的某个数据类型的 ...
- aix磁盘分区挂载问题
aix在进行磁盘分区挂载时,可能会报错
- 使用Vue构建中(大)型应用
init 首先要起一个项目,推荐用vue-cli安装 $ npm install -g vue-cli $ vue init webpack demo $ cd demo $ npm install ...
- Android--自定义加载框
1,在网上看了下好看的加载框,看了一下,挺好看的,再看了下源码,就是纯paint画出来的,再加上属性动画就搞定了 再来看一下我们的源码 LvGhost.java package com.qianmo. ...
- unresolved inclusion in the java header in JNI
eclipse的ndk开发环境建差不多后打开jni的samples里的hello-jni项目.添加native和运行都没有问题,但是打开hello-jni.c看到一片红: 光这一个文件牵涉的问题有下面 ...