关于ava容器、队列,知识点总结
推荐《java 并发编程实战》这本书,中文的翻译有些差(哈哈,并发确实难,不好翻译),适合有并发经验的人来读。
这篇短文,整理了容器的知识点,对容器的使用场景,容器的原理等有个整体的认知!
1. 层次构造
看看下面的Collection层次构造图:
(这张图为突出某些重点,对层次上的东西进行了取舍,此外类继承的多个接口,也没有表示出来)
FIFO:first-in-first-out
bounded:有界队列
doubly-linked:双向链表
natural ordering:自然顺序
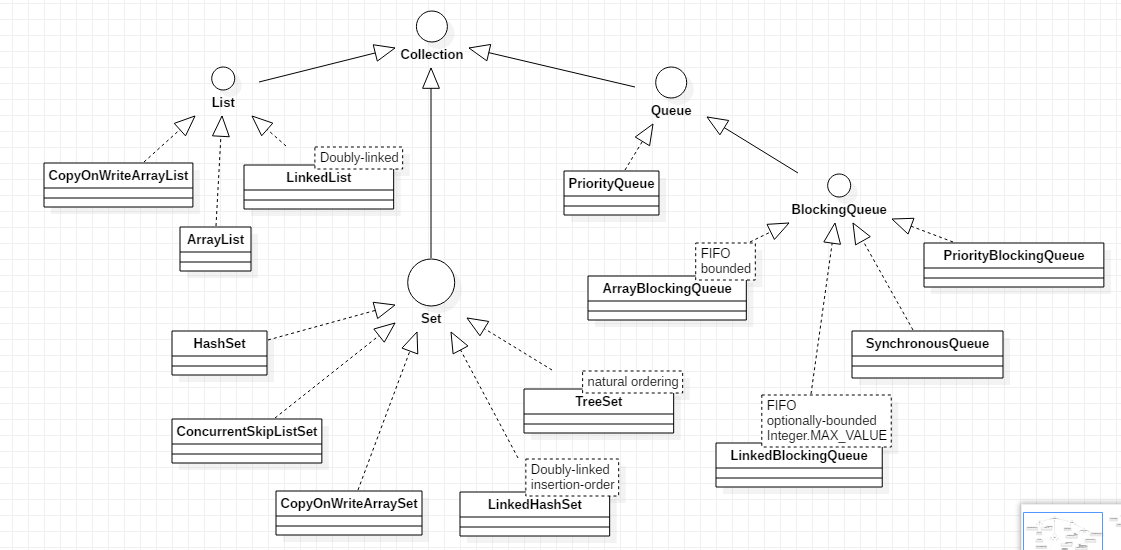
上图中,我们常用的集合基本都罗列了。一些需要注意到的东西也在上面列举了,希望大家好好看看。在类或接口的右上方,有些注释,标明了它的一次特点或是原理。
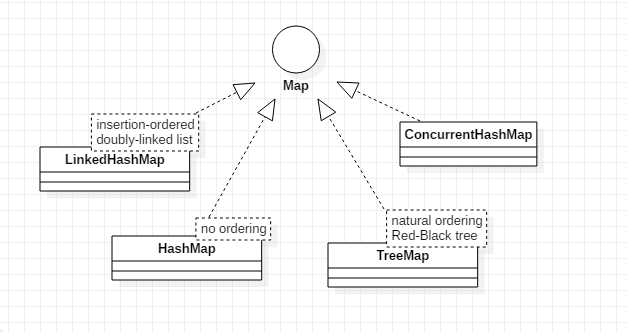
接下来看看Map的部分:
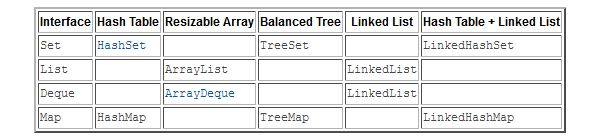
我们再看一下面这张图,阐述了容器实现的方式:
2. 迭代器
ArrayList、LinkedList等容器的实现都不是同步的。在多线程的情况下,必须进行额外的同步操作。一种方式就是,加上同步器,同步器的锁就是list。另外一种方式,在容器创建的时候,用Collections中的方法对容器进行包装,示例如下:
List list = Collections.synchronizedList(new ArrayList()); // 包装之后,就是线程安全的。
...
synchronized (list) { // 不加锁的话,迭代器会出现ConcurrentModificationException
// 这里呢,还有一种可替代方案:克隆容器,然后在副本上进行迭代
Iterator i = list.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}
Map m = Collections.synchronizedMap(new HashMap());
...
Set s = m.keySet(); // Needn't be in synchronized block
...
synchronized (m) { // Synchronizing on m, not s!
Iterator i = s.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}
(Collections中还有其他实用的方法,请查看java api)
3. 并发容器
ConcurrentHashMap:
使用分段锁的机制,允许任意数量的读取线程并发访问Map,并且一定数量的写入线程可以并发地修改Map。它带来的结果是,在并发访问环境下将实现更好的吞吐量,而在单线程环境中只损失非常小的性能。ConcurrentHashMap和其他并发容器不会抛出ConcurrentModificationException,因此不需要再迭代过程中对容器加锁。ConcurrentHashMap返回的迭代器具有弱一致性,而并非“及时失败”。弱一致性的迭代器可以容忍并发的修改。
(弱一致性该如何理解呢?数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。举例说明,可能你期望往ConcurrentHashMap中加入一个元素后,立马能对get可见,但ConcurrentHashMap并不能如你所愿。换句话说,put操作将一个元素加入后,get可能在某段时间内还看不到这个元素)
对于一些需要在整个Map上进行计算的方法,如size和isEmpty,这些方法的语义被略微减弱了以反映容器的并发特性。
额外的原子Map操作:
一些常见的复合操作,例如“若没有则添加”、“若相等则移除”、“若相等则替换”等,这些操作都是原子操作,不需要加锁。
computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)
computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
putIfAbsent(K key, V value)
remove(Object key, Object value)
replace(K key, V value)
CopyOnWriteArrayList:
用于替代同步List,在某些情况下提供了更好的并发性能,并且在迭代期间不需要对容器进行加锁或是复制。Copy-On-Write的安全性在于每次修改时,都会创建并重新发布一个新的容器的副本,从而实现可变性。但是这需要一定的开销,特别是当容器的规模较大时。仅当迭代操作远多于修改操作时,才应该使用“写入时复制”容器。
4. 链表
分为单向链表(singly-linked list)和双向链表(doubly-linked list)。
首先说一下链表(linked list)和数组(Array)的区别:
①Array是静态分配内存,不能动态扩展。在插入和删除方面,开销很大,但随机访问性强,查找速度快;linked list是动态分配内存,nodes数量可以按需求增加或减少,因此,处理未知数量的对象时,应该使用linked list。虽然,它插入删除速度快,但不能随机查找。
②链表结构区别
singly-linked list:

doubly-linked list:
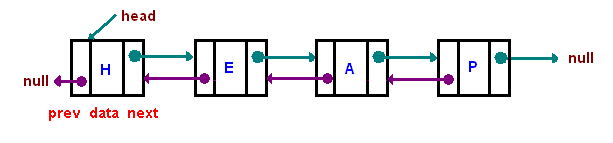
链表跟内存相比会占用更多内存,我们需花费额外的4bytes(32bitCPU中)内存来存储每个reference。
③doubly-linked list在查找和删除时利用了二分法的思想去实现,效率大大提高,但singly-linked list的应用更广泛。原因在于存储效率方面。
每个doubly-linked list的node结构比singly-linked list的多了一个指针,占用更多空间,这时设计者会以时间来换取空间,达到工程总体的平衡。
参考资料:https://www.cs.cmu.edu/~adamchik/15-121/lectures/Linked%20Lists/linked%20lists.html
5. SynchronousQueue
它有两个操作,put()和take(),这两个操作都是阻塞的。比如:当我们执行put()和,会一直阻塞到其他线程执行take()为止。队列的内部没有任何的存储容量(一个都没有),所以它不能插入数据,也不能移除数据,还不能进行迭代。newCachedThreadPool的实现,队列的部分就是使用了SysnchronousQueue。(newCachedThreadPool的特点,接收到一个新的任务就直接开启一个新的线程来执行)
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, // 0代表corePoolSize Integer.MAX_VALUE代表maximumPoolSize
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
我们先一个用公共变量来处理传递:
public class Demo002 {
public static void main(String args[]) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(2);
AtomicInteger sharedState = new AtomicInteger();
CountDownLatch countDownLatch = new CountDownLatch(1);
Runnable producer = () -> {
Integer producedElement = ThreadLocalRandom
.current()
.nextInt();
sharedState.set(producedElement);
countDownLatch.countDown();
};
Runnable consumer = () -> {
try {
countDownLatch.await();
Integer consumedElement = sharedState.get();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
};
executor.execute(producer);
executor.execute(consumer);
executor.awaitTermination(500, TimeUnit.MILLISECONDS);
executor.shutdown();
System.out.println(countDownLatch.getCount());
}
}
再用SysnchronousQueue处理传递:
public class Demo003 {
public static void main(String args[]) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(2);
SynchronousQueue<Integer> queue = new SynchronousQueue<>();
Runnable producer = () -> {
Integer producedElement = ThreadLocalRandom
.current()
.nextInt();
try {
queue.put(producedElement);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
};
Runnable consumer = () -> {
try {
Integer consumedElement = queue.take();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
};
executor.execute(producer);
executor.execute(consumer);
executor.awaitTermination(500, TimeUnit.MILLISECONDS);
executor.shutdown();
System.out.println(queue.size());
}
}
至此,我们看到了它的构造,用例子阐述了它的使用方法,SynchronousQueue服务于一个交换点,这个交换点用于生产者和消费者的协作。
关于ava容器、队列,知识点总结的更多相关文章
- Java容器相关知识点整理
结合一些文章阅读源码后整理的Java容器常见知识点.对于一些代码细节,本文不展开来讲,有兴趣可以自行阅读参考文献. 1. 思维导图 各个容器的知识点比较分散,没有在思维导图上体现,因此看上去右半部分很 ...
- Qt5_容器_知识点记录
1.删除: 1.1.erase 1.2.remove / removeAt 2. 3. 4. 5.
- C++ 顺序容器基础知识总结
0.前言 本文简单地总结了STL的顺序容器的知识点.文中并不涉及具体的实现技巧,对于细节的东西也没有提及.一来不同的标准库有着不同的实现,二来关于具体实现<STL源码剖析>已经展示得全面细 ...
- 线程高级应用-心得7-java5线程并发库中阻塞队列Condition的应用及案例分析
1.阻塞队列知识点 阻塞队列重要的有以下几个方法,具体用法可以参考帮助文档:区别说的很清楚,第一个种方法不阻塞直接抛异常:第二种方法是boolean型的,阻塞返回flase:第三种方法直接阻塞. 2. ...
- 并发编程 - 进程 - 1.队列的使用/2.生产者消费者模型/3.JoinableQueue
1.队列的使用: 队列引用的前提: 多个进程对同一块共享数据的修改:要从硬盘读文件,慢,还要考虑上锁: 所以就出现了 队列 和 管道 都在内存中(快): 队列 = 管道 + 上锁 用队列的目的: 进程 ...
- STL 容器(vector 和 list )
1.这个容器的知识点比较杂 迭代器的理解: 1.erase()函数的返回值,它的迭代器在循环遍历中的奇特之处: #define _CRT_SECURE_NO_WARNINGS #include < ...
- Spring IOC 一——容器装配Bean的简单使用
下文:SpringIOC 二-- 容器 和 Bean的深入理解 写在前面 这篇文章去年写的,缘起于去年某段时间被领导临时"抓壮丁"般的叫过去做java开发,然后在网上找了一个 Sp ...
- Python进阶----进程之间通信(互斥锁,队列(参数:timeout和block),), ***生产消费者模型
Python进阶----进程之间通信(互斥锁,队列(参数:timeout和block),), ***生产消费者模型 一丶互斥锁 含义: 每个对象都对应于一个可称为" 互斥锁&qu ...
- 掌握SpringBoot-2.3的容器探针:实战篇
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:原创文章分类汇总,及配套源码,涉及Java.Docker.K8S.DevOPS等 经过多篇知识 ...
随机推荐
- Spring NoSuchBeanDefinitionException六大原因总结
1. Overview In this article, we are discussing the Springorg.springframework.beans.factory.NoSuchBea ...
- Nginx 配置负载均衡
nginx负载均衡配置,主要是proxy_pass,upstream的使用. 注意问题,多台机器间session的共享问题. 不用session,用户cookie.或者用redis替代session. ...
- git在本地回退
参考https://www.cnblogs.com/qufanblog/p/7606105.html 已经用 git commit 提交了代码. 可以使用 git reset --hard HEAD ...
- 覃超:Facebook的项目开发流程和工程师的绩效管理机制
覃超:Facebook的项目开发流程和工程师的绩效管理机制 http://mp.weixin.qq.com/s?__biz=MjM5MDE0Mjc4MA==&mid=2650992350&am ...
- 第一次作业——WorkCount
项目地址:https://gitee.com/yangfj/wordcount_project 1.软件需求分析: 撰写PSP表格: PSP2.1 PSP阶段 预估耗时 (分钟) 实际耗时 (分钟) ...
- 1018. Binary Prefix Divisible By 5可被 5 整除的二进制前缀
网址:https://leetcode.com/problems/binary-prefix-divisible-by-5/ 一次for循环遍历数组,在上次计算的基础上得到本次的结果! class S ...
- bsxfun.h multiple threads backup
https://code.google.com/p/deep-learning-faces/source/browse/trunk/cuda_ut/include/bsxfun.h?r=7&s ...
- Linux c读取系统内存使用信息
系统的内存使用信息能够在虚拟文件系统/proc/meminfo中找到,如图 所以只要打开/proc/meminfo文件,然后从中读取信息就好了 #include <stdio.h>#inc ...
- django+celery +rabbitmq
celery是一个python的分布式任务队列框架,支持 分布的 机器/进程/线程的任务调度.采用典型的生产者-消费者模型 包含三部分:1. 队列 broker :可使用redis ,rabbitmq ...
- scrapy的Middleware
对于下载中间件 settings里的数字大小: process_request的顺序 数字越小,越先调用 process_response 的顺序, 数字越大,越先调用 返回值: process_re ...