【sparkSQL】SparkSession的认识
https://www.cnblogs.com/zzhangyuhang/p/9039695.html
https://www.jianshu.com/p/dea6a78b9dff
在Spark1.6中我们使用的叫Hive on spark,主要是依赖hive生成spark程序,有两个核心组件SQLcontext和HiveContext。
这是Spark 1.x 版本的语法
|
1
2
3
4
5
|
//set up the spark configuration and create contexts val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local") // your handle to SparkContext to access other context like SQLContext val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value") val sqlContext = new org.apache.spark.sql.SQLContext(sc) |
而Spark2.0中我们使用的就是sparkSQL,是后继的全新产品,解除了对Hive的依赖。
从Spark2.0以上的版本开始,spark是使用全新的SparkSession接口代替Spark1.6中的SQLcontext和HiveContext
来实现对数据的加载、转换、处理等工作,并且实现了SQLcontext和HiveContext的所有功能。
我们在新版本中并不需要之前那么繁琐的创建很多对象,只需要创建一个SparkSession对象即可。
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并支持把DataFrame转换成SQLContext自身中的表。
然后使用SQL语句来操作数据,也提供了HiveQL以及其他依赖于Hive的功能支持。
创建SparkSession
SparkSession 是 Spark SQL 的入口。
使用 Dataset 或者 Datafram 编写 Spark SQL 应用的时候,第一个要创建的对象就是 SparkSession。
Builder 是 SparkSession 的构造器。 通过 Builder, 可以添加各种配置。
Builder 的方法如下:
| Method | Description |
|---|---|
| getOrCreate | 获取或者新建一个 sparkSession |
| enableHiveSupport | 增加支持 hive Support |
| appName | 设置 application 的名字 |
| config | 设置各种配置 |
你可以通过 SparkSession.builder 来创建一个 SparkSession 的实例,并通过 stop 函数来停止 SparkSession。
|
1
2
3
4
5
6
7
|
import org.apache.spark.sql.SparkSessionval spark: SparkSession = SparkSession.builder .appName("My Spark Application") // optional and will be autogenerated if not specified .master("local[*]") // avoid hardcoding the deployment environment .enableHiveSupport() // self-explanatory, isn't it? .config("spark.sql.warehouse.dir", "target/spark-warehouse") .getOrCreate |
这样我就就可以使用我们创建的SparkSession类型的spark对象了。
2.在SparkSession这个类中,有builder,通过builder去构建SparkSession实例,用法如下。
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("spark://hadoopmaste:
7077").appName("test").config("spark.xxxx.conf", "some-value")
.getOrCreate()
master用于指定spark集群地址
appName用于设置app的名称
config中以key,value的形式进行一些配置
config可以以链式编程的方式多次调用,每次调用可设置一组key,value配置。而且conf中还可以传入一个关键字参数conf,指定外部的SparkConf配置对象getOrCreate,若存在sparksession实例直接返回,否则实例化一个sparksession返回
设置参数
创建SparkSession之后可以通过 spark.conf.set 来设置运行参数
|
1
2
3
4
5
|
//set new runtime options spark.conf.set("spark.sql.shuffle.partitions", 6) spark.conf.set("spark.executor.memory", "2g") //get all settings val configMap:Map[String, String] = spark.conf.getAll()//可以使用Scala的迭代器来读取configMap中的数据。 |
读取元数据
如果需要读取元数据(catalog),可以通过SparkSession来获取。
|
1
2
3
|
//fetch metadata data from the catalog spark.catalog.listDatabases.show(false) spark.catalog.listTables.show(false) |
这里返回的都是Dataset,所以可以根据需要再使用Dataset API来读取。
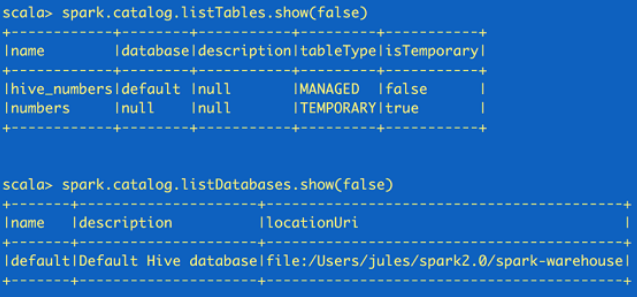
注意:catalog 和 schema 是两个不同的概念
Catalog是目录的意思,从数据库方向说,相当于就是所有数据库的集合;
Schema是模式的意思, 从数据库方向说, 类似Catelog下的某一个数据库;
创建Dataset和Dataframe
通过SparkSession来创建Dataset和Dataframe有多种方法。
最简单的就是通过range()方法来创建dataset,通过createDataFrame()来创建dataframe。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
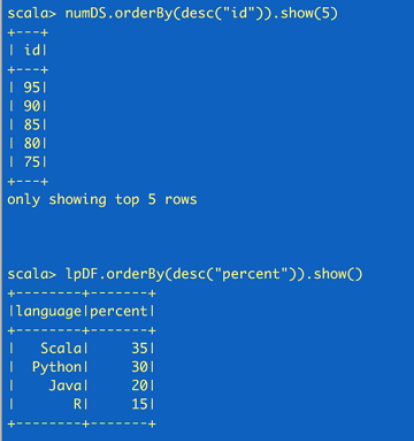
//create a Dataset using spark.range starting from 5 to 100, with increments of 5val numDS = spark.range(5, 100, 5)//创建dataset// reverse the order and display first 5 itemsnumDS.orderBy(desc("id")).show(5)//compute descriptive stats and display themnumDs.describe().show()// create a DataFrame using spark.createDataFrame from a List or Seqval langPercentDF = spark.createDataFrame(List(("Scala", 35), ("Python", 30), ("R", 15), ("Java", 20)))//创建dataframe//rename the columnsval lpDF = langPercentDF.withColumnRenamed("_1", "language").withColumnRenamed("_2", "percent")//order the DataFrame in descending order of percentagelpDF.orderBy(desc("percent")).show(false) |
读取数据
可以用SparkSession读取JSON、CSV、TXT和parquet表。
|
1
2
3
4
|
import spark.implicits //使RDD转化为DataFrame以及后续SQL操作//读取JSON文件,生成DataFrameval jsonFile = args(0)val zipsDF = spark.read.json(jsonFile) |
使用SparkSQL
借助SparkSession用户可以像SQLContext一样使用Spark SQL的全部功能。
|
1
2
3
4
|
zipsDF.createOrReplaceTempView("zips_table")//对上面的dataframe创建一个表zipsDF.cache()//缓存表val resultsDF = spark.sql("SELECT city, pop, state, zip FROM zips_table")//对表调用SQL语句resultsDF.show(10)//展示结果 |
存储/读取Hive表
下面的代码演示了通过SparkSession来创建Hive表并进行查询的方法。
|
1
2
3
4
5
6
7
|
//drop the table if exists to get around existing table error spark.sql("DROP TABLE IF EXISTS zips_hive_table") //save as a hive table spark.table("zips_table").write.saveAsTable("zips_hive_table") //make a similar query against the hive table val resultsHiveDF = spark.sql("SELECT city, pop, state, zip FROM zips_hive_table WHERE pop > 40000") resultsHiveDF.show(10) |
下图是 SparkSession 的类和方法, 这些方法包含了创建 DataSet, DataFrame, Streaming 等等。
| Method | Description |
|---|---|
| builder | "Opens" a builder to get or create a SparkSession instance |
| version | Returns the current version of Spark. |
| implicits | Use import spark.implicits._ to import the implicits conversions and create Datasets from (almost arbitrary) Scala objects. |
| emptyDataset[T] | Creates an empty Dataset[T]. |
| range | Creates a Dataset[Long]. |
| sql | Executes a SQL query (and returns a DataFrame). |
| udf | Access to user-defined functions (UDFs). |
| table | Creates a DataFrame from a table. |
| catalog | Access to the catalog of the entities of structured queries |
| read | Access to DataFrameReader to read a DataFrame from external files and storage systems. |
| conf | Access to the current runtime configuration. |
| readStream | Access to DataStreamReader to read streaming datasets. |
| streams | Access to StreamingQueryManager to manage structured streaming queries. |
| newSession | Creates a new SparkSession. |
| stop | Stops the SparkSession. |
当我们使用Spark-Shell的时候,Spark会自动帮助我们建立好了一个名字为spark的SparkSesson和一个名字为sc的SparkContext。
开发实践
1. 读取mysql表数据
import com.test.spark.db.ConnectionInfos;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.Arrays;
public class SparkSimple01 {
public static void main(String[] args) {
// 创建spark会话,实质上是SQLContext和HiveContext的组合
SparkSession sparkSession = SparkSession.builder().master("local[*]").appName("Java Spark SQL basic example").getOrCreate();
// 设置日志级别,默认会打印DAG,TASK执行日志,设置为WARN之后可以只关注应用相关日志
sparkSession.sparkContext().setLogLevel("WARN");
// 分区方式读取mysql表数据
Dataset<Row> predicateSet = sparkSession.read().jdbc(ConnectionInfos.TEST_MYSQL_CONNECTION_URL, "people",
(String[]) Arrays.asList(" name = 'tom'", " name = 'sam' ").toArray(), ConnectionInfos.getTestUserAndPasswordProperties());
predicateSet.show();
}
}
为了确认该查询对mysql发出的具体sql,我们先查看一下mysql执行sql日志,
#mysql 命令窗口执行以下命令打开日志记录
SHOW VARIABLES LIKE "general_log%";
SET GLOBAL general_log = 'ON';

打开Lenovo.log得到以上代码在mysql上的执行情况:

通过分区查询获取表数据的方式有以下几个优点:
- 利用表索引查询提高查询效率
- 自定义sql条件使分区数据更加均匀,方便后面的并行计算
- 分区并发读取可以通过控制并发控制对mysql的查询压力
- 可以读取大数据量的mysql表
spark jdbc 读取msyql表还有直接读取(无法读取大数据量表),指定字段分区读取(分区不够均匀)等方式,通过项目实践总结,以上的分区读取方式是我们目前认为对mysql最友好的方式。
分库分表的系统也可以利用这种方式读取各个表在内存中union所有spark view得到一张统一的内存表,在业务操作中将分库分表透明化。如果线上数据表数据量较大的时候,在union之前就需要将spark view通过指定字段的方式查询,避免on line ddl 在做变更时union表报错,因为可能存在部分表已经添加新字段,部分表还未加上新字段,而union要求所有表的表结构一致,导致报错。
2. Dataset 分区数据查看
我们都知道 Dataset 的分区是否均匀,对于结果集的并行处理效果有很重要的作用,spark Java版暂时无法查看partition分区中的数据分布,这里用java调用scala 版api方式查看,线上不推荐使用,因为这里的分区查看使用foreachPartition,多了一次action操作,并且打印出全部数据。
import org.apache.spark.sql.{Dataset, Row}
/**
* Created by lesly.lai on 2017/12/25.
*/
class SparkRddTaskInfo {
def getTask(dataSet: Dataset[Row]) {
val size = dataSet.rdd.partitions.length
println(s"==> partition size: $size " )
import scala.collection.Iterator
val showElements = (it: Iterator[Row]) => {
val ns = it.toSeq
import org.apache.spark.TaskContext
val pid = TaskContext.get.partitionId
println(s"[partition: $pid][size: ${ns.size}] ${ns.mkString(" ")}")
}
dataSet.foreachPartition(showElements)
}
}
还是用上面读取mysql数据的例子来演示调用,将predicateSet作为参数传入
new SparkRddTaskInfo().getTask(predicateSet);
控制台打印结果

通过分区数据,我们可以看到之前的predicate 方式得到的分区数就是predicate size 大小,并且按照我们想要的数据分区方式分布数据,这对于业务数据的批处理,executor的local cache,spark job执行参数调优都很有帮助,例如调整spark.executor.cores,spark.executor.memory,GC方式等等。
这里涉及java和Scala容器转换的问题,Scala和Java容器库有很多相似点,例如,他们都包含迭代器、可迭代结构、集合、 映射和序列。但是他们有一个重要的区别。Scala的容器库特别强调不可变性,因此提供了大量的新方法将一个容器变换成一个新的容器。
在Scala内部,这些转换是通过一系列“包装”对象完成的,这些对象会将相应的方法调用转发至底层的容器对象。所以容器不会在Java和Scala之间拷贝来拷贝去。一个值得注意的特性是,如果你将一个Java容器转换成其对应的Scala容器,然后再将其转换回同样的Java容器,最终得到的是一个和一开始完全相同的容器对象(这里的相同意味着这两个对象实际上是指向同一片内存区域的引用,容器转换过程中没有任何的拷贝发生)。
3. sql 自定义函数
自定义函数,可以简单方便的实现业务逻辑。
import com.tes.spark.db.ConnectionInfos;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
public class SparkSimple02 {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local[*]").appName("Java Spark SQL basic example").getOrCreate();
sparkSession.sparkContext().setLogLevel("WARN");
Dataset<Row> originSet = sparkSession.read().jdbc(ConnectionInfos.TEST_MYSQL_CONNECTION_URL, "people", ConnectionInfos.getTestUserAndPasswordProperties());
originSet.cache().createOrReplaceTempView("people");
// action操作 打印原始结果集
originSet.show();
// 注册自定义函数
sparkSession.sqlContext().udf().register("genderUdf", gender -> {
if("M".equals(gender)){
return "男";
}else if("F".equals(gender)){
return "女";
}
return "未知";
}, DataTypes.StringType);
// 查询结果
Dataset<Row> peopleDs = sparkSession.sql("select job_number,name,age, genderUdf(gender) gender, dept_id, salary, create_time from people ");
// action操作 打印函数处理后结果集
peopleDs.show();
}
}
执行结果:

在sql中用使用java代码实现逻辑操作,这为sql的处理逻辑能力提升了好几个层次,将函数抽取成接口实现类可以方便的管理和维护这类自定义函数类。此外,spark也支持自定义内聚函数,窗口函数等等方式,相比传统开发实现的功能方式,使用spark sql开发效率可以明显提高。
4. mysql 查询连接复用
最近线上任务遇到一个获取mysql connection blocked的问题,从spark ui的executor thread dump 可以看到blocked的栈信息,如图:

查看代码发现DBConnectionManager 调用了 spark driver注册mysql driver 使用同步方式的代码

看到这里我们很容易觉得是注册driver 导致的blocked,其实再仔细看回报错栈信息,我们会发现,这里的getConnection是在dataset 的foreachpartition 中调用,并且是在每次db 操作时获取一次getConnection 操作,这意味着在该分区下有多次重复的在同步方法中注册driver获取连接的操作,看到这里线程blocked的原因就很明显了,这里我们的解决方式是:
a. 在同个partition中的connection 复用进行db操作
b. 为了避免partition数据分布不均导致连接active时间过长,加上定时释放连接再从连接池重新获取连接操作
通过以上的连接处理,解决了blocked问题,tps也达到了4w左右。
5. executor 并发控制
我们都知道,利用spark 集群分区并行能力,可以很容易实现较高的并发处理能力,如果是并发的批处理,那并行处理的能力可以更好,但是,mysql 在面对这么高的并发的时候,是有点吃不消的,因此我们需要适当降低spark 应用的并发和上下游系统和平相处。控制spark job并发可以通过很多参数配置组合、集群资源、yarn队列限制等方式实现,经过实践,我们选择以下参数实现:
#需要关闭动态内存分配,其他配置才生效
spark.dynamicAllocation.enabled = false
spark.executor.instances = 2
spark.executor.cores = 2

这里发现除了设置executor配置之外,还需要关闭spark的动态executor分配机制,spark 的ExecutorAllocationManager 是 一个根据工作负载动态分配和删除 executors 的管家, ExecutorAllocationManager 维持一个动态调整的目标executors数目, 并且定期同步到资源管理者,也就是 yarn ,启动的时候根据配置设置一个目标executors数目, spark 运行过程中会根据等待(pending)和正在运行(running)的tasks数目动态调整目标executors数目,因此需要关闭动态配置资源才能达到控制并发的效果。
除了executor是动态分配之外,Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,我们先看看worker中的内存规划是怎样的:

worker 可以根据实例配置,内存配置,cores配置动态生成executor数量,每一个executor为一个jvm进程,因此executor 的内存管理是建立在jvm的内存管理之上的。从本文第一张spark on yarn图片可以看到,yarn模式的 executor 是在yarn container 中运行,因此container的内存分配大小同样可以控制executor的数量。
RDD 的每个 Partition 经过处理后唯一对应一个 Block(BlockId 的格式为 rdd_RDD-ID_PARTITION-ID ),从上图可以看出,开发过程中常用的分区(partition)数据是以block的方式存储在堆内的storage内存区域的,还有为了减少网络io而做的broadcast数据也存储在storage区域;堆内的另一个区域内存则主要用于缓存rdd shuffle产生的中间数据;此外,worker 中的多个executor还共享同一个节点上的堆外内存,这部分内存主要存储经序列化后的二进制数据,使用的是系统的内存,可以减少不必要的开销以及频繁的GC扫描和回收。
为了更好的理解executor的内存分配,我们再来看一下executor各个内存块的参数设置:


了解spark 内存管理的机制后,就可以根据mysql的处理能力来设置executor的并发处理能力,让我们的spark 应用处理能力收放自如。调整executor数量还有另外一个好处,就是集群资源规划,目前我们的集群队列是yarn fair 模式,

先看看yarn fair模式,举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,当A的job执行完释放资源后,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。
在这种情况下,即使有多个队列执行任务,fair模式容易在资源空闲时占用其他队列资源,一旦占用时间过长,就会导致其他任务都卡住,这也是我们遇到的实际问题。如果我们在一开始能评估任务所用的资源,就可以在yarn队列的基础上指定应用的资源,例如executor的内存,cpu,实例个数,并行task数量等等参数来管理集群资源,这有点类似于yarn Capacity Scheduler 队列模式,但又比它有优势,因为spark 应用可以通过spark context的配置来动态的设置,不用在配置yarn 队列后重启集群,稍微灵活了一点。
除了以上提到的几点总结,我们还遇到很多其他的疑问和实践,例如,什么时候出现shuffle;如何比较好避开或者利用shuffle;Dataset 的cache操作会不会有性能问题,如何从spark ui中分析定位问题;spark 任务异常处理等等,暂时到这里,待续...
【sparkSQL】SparkSession的认识的更多相关文章
- java使用spark/spark-sql处理schema数据(spark1.6)
1.spark是什么? Spark是基于内存计算的大数据并行计算框架. 1.1 Spark基于内存计算 相比于MapReduce基于IO计算,提高了在大数据环境下数据处理的实时性. 1.2 高容错性和 ...
- [Spark SQL] SparkSession、DataFrame 和 DataSet 练习
本課主題 DataSet 实战 DataSet 实战 SparkSession 是 SparkSQL 的入口,然后可以基于 sparkSession 来获取或者是读取源数据来生存 DataFrameR ...
- sparksql工程小记
最近做一个oracle项目迁移工作,跟着spark架构师学着做,进行一些方法的总结. 1.首先,创建SparkSession对象(老版本为sparkContext) val session = Spa ...
- SparkSQL——用之惜之
SparkSql作为Spark的结构化数据处理模块,提供了非常强大的API,让分析人员用一次,就会为之倾倒,为之着迷,为之至死不渝.在内部,SparkSQL使用额外结构信息来执行额外的优化.在外部,可 ...
- SparkSQL
Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用. Hive SQL是转换成 ...
- java使用spark/spark-sql处理schema数据
1.spark是什么? Spark是基于内存计算的大数据并行计算框架. 1.1 Spark基于内存计算 相比于MapReduce基于IO计算,提高了在大数据环境下数据处理的实时性. 1.2 高容错性和 ...
- sparkSQL将谓词推入kudu引擎
kudu之所以执行非常快速,可以用来替代HDFS和Hbase等,一个主要原因是,我们可以将普通SQL中的谓词推入kudu引擎,这样kudu查询数据会变的非常快: 将谓词评估推入Kudu引擎可以提高性能 ...
- 使用sparkSQL的insert操作Kudu
可以选择使用Spark SQL直接使用INSERT语句写入Kudu表:与'append'类似,INSERT语句实际上将默认使用UPSERT语义处理: import org.apache.kudu.sp ...
- 【Spark深入学习 -16】官网学习SparkSQL
----本节内容-------1.概览 1.1 Spark SQL 1.2 DatSets和DataFrame2.动手干活 2.1 契入点:SparkSess ...
随机推荐
- 小程序html转wxml,微信小程序用wxParse解析html
1.首先下载 wxParse脚本,到https://github.com/icindy/wxParse下载,将wxParse文件夹放置到小程序根目录,即跟pages同级目录 2.在样式页面 wxss ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- JMeter中的正则表达式的匹配
==
- ARIMA模型总结
时间序列建模基本步骤 获取被观测系统时间序列数据: 对数据绘图,观测是否为平稳时间序列:对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列: 经过第二步处理,已经得到平稳时间序列.要对平稳时间序 ...
- 微信OpenID获取
用户要求在微信端登录一次后,以后不需要再登录. 我的系统是单独的一个网站. 使用MVC的记住密码功能, 如果用户重启,就还是要输入密码,所以需要有一个唯一不变的用来标示用户的ID. OpenID就 ...
- css td hover 选择器无效
最近在写一个日历控件,控件中使用了table 来显示日期.在css 文件中利用 td:hover 设置td 背景色时 一直没起作用.上百度google 了一下,网上大部分人遇到的都是在td:hover ...
- python 构造一个可以返回多个值的函数
为了能返回多个值,函数直接return 一个元组就行了 看上去返回了多个值,实际上是先创建了一个元组然后返回的.这个语法看上去比较奇怪,实际上我们使用的是逗号来生成一个元组,而不是用括号 >&g ...
- vue项目初始化时npm run dev报错webpack-dev-server解决方法
vue项目初始化时npm run dev报错webpack-dev-server解决方法 原因:这是新版webpack存在的BUG,卸载现有的新版本webpack,装老版本就好webpack-dev- ...
- MySQL数据的导出和导入
MySQL环境变量设置,将%MySQL_HOME%下的MySQL Server 5.1/bin放到Path下. MySQL的mysqldump工具,基本用法是: shell> mysqldu ...
- Porsche Piwis Tester II V12.100 Version Released
Piwis Tester II v12.100 Version released today! In this new version we can find the latest type Pors ...