lower_bound && upper_bound
用lower_bound进行二分查找
●在从小到大排好序的基本类型数组上进行二分查找。
这是二分查找的一种版本,试图在已排序的[first,last)中寻找元素value。如果[first,last)具有与value相等的元素(s),便返回一个迭代器,指向其中第一个元素。如果没有这样的元素存在,便返回“假设这样的元素存在是应该出现的位置”。也就是说,它会返回一个迭代器,指向第一个“不小于value的元素”。如果value大于[first,last)内的任何一个元素,则返回last。以稍许不同的观点来看lower_bound,其返回值是“在不破坏顺序状态的原则下,可插入value的第一个位置”。如下图
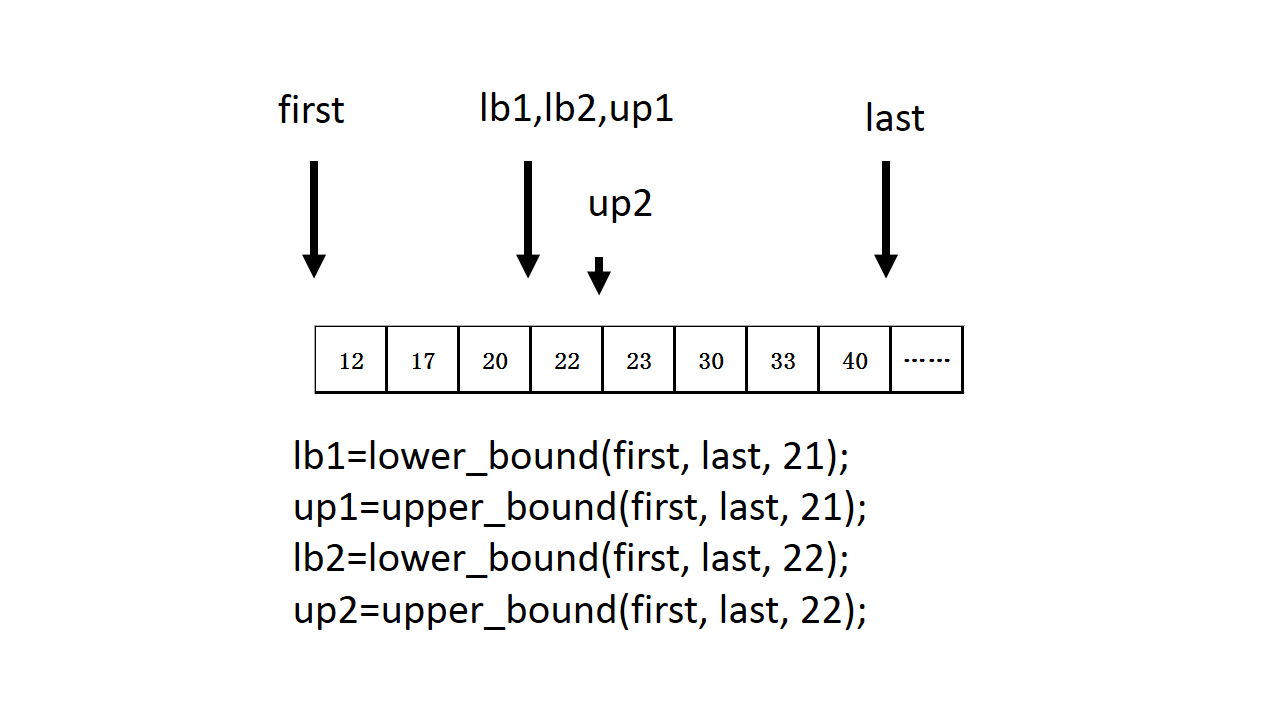
具体的用法是:
I
在对元素类型为T的从小到大排好序的基本类型的数组中进行查找。
T * lower_bound ( 数组名 + n1, 数组名 + n2 , 值 );
* p 是查找区间里下标最小的,大于等于“值”的元素。如果找不到,p指向下标为n2的元素。
II
在元素为任意的T类型、按照自定义排序规则排好序的数组中进行查找。
T * lower_bound ( 数组名 + n1, 数组名 + n2, 值 , 排序规则结构名());
返回一个指针 T * P;
* P是查找区间里下标最小的,按自定义排序规则,可以排在“值”后面的元素。如果找不到,p指向下标为n2的元素。
这个算法有两个版本,版本1采用operator<进行比较,版本2采用仿函数comp。更正式地说,版本1返回[first,last)中最远的迭代器i,使得[first,i)中的每个迭代器j都满足 *j < value。版本2返回[first,last)中最远的迭代器i,使[first,i)中的每个迭代器j都满足“comp(j *, value)为真”。
函数原型就不给了,讲一讲用法就行了。
用upper_bound进行二分查找
算法upper_bound是二分查找(binary_search)的另一个版本。它试图在已排序的[first,last)中寻找value。更明确地说,它会返回 “在不破坏顺序的情况下,可插入 value的最后一个合适的位置”。
由于STL规范“区间圈定”时的起头和结尾并不对称(是的,[first,last)包含first但不包含last),所以 upper_bound 与lower_bound 的返回值意义大有不同。如果你查找某值,而它的确出现在区间内,则 lower_bound 返回的是一个指向该元素的迭代器。然而upper_bound 不这么做。因为upper_bound所返回的是在不破坏排序状态的情况下,value 可被插入的“最后一个”合适的位置。如果value存在,那么它返回的迭代器将指向value的下一位置,而非指向value本身。
upper_bound有两个版本,版本一采用operator < 进行比较,版本二采用仿函数comp。更正式地说,版本一返回[first,last) 区间内最远的迭代器i,使[first,i)内的每一个迭代器j都满足 "value < *j"不为真。版本二返回[first,last)区间内最远的迭代器i,使[first,last)中的每个迭代器j都满足"comp( value , *j )不为真"。
下面是upper_bound的具体用法:
I
在元素类型为T的从小到大排好序的基本类型的数组中进行查找:
T * upper_bound ( 数组名 + n1, 数组名 + n2, 值);
返回一个指针 T * p;
*p 是查找区间里下标最小的、大于“值”的元素。如果找不到,p指向下标为n2的元素。
II
在元素为任意的T类型、按照自定义排序规则排好序的数组中进行查找
T * upper_bound( 数组名 + n1, 数组名 + n2 , 值 ,排序规则结构名());
返回一个指针 T * p;
* p是查找区间里下标最小的,按自定义排序规则,必须排在“值”后面的元素。如果找不到,p指向下标为n2的元素。
lower_bound&upper_bound用法实例
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
struct rule
{
bool operator() ( const int & a1, const int & a2)
{
return a1% < a2%;// 按照个位数由小到大排序
}
};
void print(int a[],int size)
{
for(int i = ;i < size;i ++)
cout << a[i] << ",";
cout << endl;
}
#define NUM 7
int main()
{
int a[NUM] = { ,,,,,,};
sort(a,a+NUM);
print(a,NUM);// =>3,5,5,7,12,21,98, int * p = lower_bound( a, a + NUM, );
cout << *p << "," << p-a << endl; //=>5,1 p = upper_bound ( a, a + NUM, );
cout << *p << endl;//=>7
cout << * upper_bound ( a, a+NUM, )<< endl;//=>21 sort( a, a + NUM, rule());
print( a, NUM);//=>21,12,3,5,5,7,98, cout << * lower_bound ( a, a + NUM , , rule()) << endl;//=>7 cout << lower_bound ( a, a + NUM , , rule()) - a <<endl;//=>3 cout << upper_bound ( a, a + NUM, , rule()) - a <<endl;//=>7 if ( upper_bound ( a , a + NUM , , rule()) == a + NUM)
cout << "NOT FOUND" << endl; //=>not found cout << * upper_bound ( a, a + NUM, , rule()) << endl;//=>7 cout << * upper_bound ( a, a + NUM, , rule()) << endl;//=>5
return ;
}
lower_bound && upper_bound的更多相关文章
- STL中的二分查找———lower_bound,upper_bound,binary_search
关于STL中的排序和检索,排序一般用sort函数即可,今天来整理一下检索中常用的函数——lower_bound , upper_bound 和 binary_search . STL中关于二分查找的函 ...
- lower_bound/upper_bound example
http://www.cplusplus.com/reference/algorithm/upper_bound/左闭右开 Return iterator to lower bound Returns ...
- [STL]lower_bound&upper_bound
源码 lower_bound template <class ForwardIterator, class T> ForwardIterator lower_bound (ForwardI ...
- STL中的unique()和lower_bound ,upper_bound
unique(): 作用:unique()的作用是去掉容器中相邻元素的重复元素(数组可以是无序的,比如数组可以不是按从小到大或者从大到小的排列方式) 使用方法:unique(初始地址,末地址): 这里 ...
- vector 牛逼 +lower_bound+ upper_bound
vector 超级 日白 解决的问题空间问题,可以自由伸缩. 一下用法: 向量大小: vec.size(); 向量判空: vec.empty(); 末尾添加元素: vec.push_back(); / ...
- C++ lower_bound/upper_bound用法解析
1. 作用 lower_bound和upper_bound都是C++的STL库中的函数,作用差不多,lower_bound所返回的是第一个大于或等于目标元素的元素地址,而upper ...
- LeetCode:Search Insert Position,Search for a Range (二分查找,lower_bound,upper_bound)
Search Insert Position Given a sorted array and a target value, return the index if the target is fo ...
- STL lower_bound upper_bound binary-search
STL中的二分查找——lower_bound .upper_bound .binary_search 二分查找很简单,原理就不说了.STL中关于二分查找的函数有三个lower_bound .upper ...
- C++标准库之 Lower_Bound, upper_Bound
关于二分查找,这绝对是最简单却又最难的实现了,其各种版本号能够參见http://blog.csdn.net/xuqingict/article/details/17335833 在C++的标准库中,便 ...
随机推荐
- SSE图像算法优化系列二十二:优化龚元浩博士的曲率滤波算法,达到约1000 MPixels/Sec的单次迭代速度
2015年龚博士的曲率滤波算法刚出来的时候,在图像处理界也曾引起不小的轰动,特别是其所说的算法的简洁性,以及算法的效果.执行效率等方面较其他算法均有一定的优势,我在该算法刚出来时也曾经有关注,不过 ...
- CentOS7通过rsync+crontab实现两台服务器文件同步
centos7系统中已经默认安装rsync 1:主服务器配置 (1)修改rsyncd.conf 配置文件 [root@localhost app]# vi /etc/rsyncd.conf motd ...
- C# 对轻量级(IoC Container)依赖注入Unity的使用
概述 Unity是一个轻量级的可扩展的依赖注入容器,支持构造函数,属性和方法调用注入.Unity可以处理那些从事基于组件的软件工程的开发人员所面对的问题.构建一个成功应用程序的关键是实现非常松散的耦合 ...
- SQL Server 性能优化实战系列(二)
SQL Server datetime数据类型设计.优化误区 一.场景 在SQL Server 2005中,有一个表TestDatetime,其中Dates这个字段的数据类型是datetime,如果你 ...
- mysql分区方案的研究
笔者觉得,分库分表确实好的.但是,动不动搞分库分表,太麻烦了.分库分表虽然是提高数据库性能的常规办法,但是太麻烦了.所以,尝试研究mysql的分区到底如何. 之前写过一篇文章,http://www.c ...
- halcon开发必读
关于HALCON的新手入门问题简答(1) 无论读入什么图像,读入图像显示效果明显和原始图像不一致,哪怕是从相机读入的图像,也是明显颜色差异.什么原因引起? 答:初步诊断是,显示的时候调用的颜色查找表存 ...
- Oracle中查看所有表和字段
获取表字段: select * from user_tab_columns where Table_Name='用户表' order by column_name 获取表注释: select * fr ...
- Kubernetes集群部署之四Master节点部署
Kubernetes Master节点部署三个服务:kube-apiserver.kube-controller-manager.kube-scheduler和一个命令工具kubectl. Maste ...
- Iterator和ListIterator
Iterator和ListIterator主要区别有: 一.ListIterator有add()方法,可以向List中添加对象,而Iterator不能. 二.ListIterator和Iterator ...
- Dubbo 分布式 日志 追踪
使用dubbo分布式框架进行微服务的开发,一个大系统往往会被拆分成很多不同的子系统,并且子系统还会部署多台机器,当其中一个系统出问题了,查看日志十分麻烦. 所以需要一个固定的流程ID和机器ip地址等来 ...