SQL Server中多表连接时驱动顺序对性能的影响
本文出处:http://www.cnblogs.com/wy123/p/7106861.html
(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误进行修正或补充,无他)
最近在SQL Server中多次遇到开发人员提交过来的有性能问题的SQL,其表面的原因是表之间去的驱动顺序造成的性能问题,
具体表现在(已排除其他因素影响的情况下),存储过程偶发性的执行时间超出预期,甚至在调试的时候,直接在存储过程的SQL语句中植入某些具体的参数,在性能上仍达不到预期的响应时间。
此类问题在排除了服务器资源因素,索引,锁,parameter sniff等常见问题之后,确认识是表之间的驱动顺序造成的,因为在尝试sql语句的末尾加上option(force order)之后,性能迅速提升。
通常情况下,表之间连接的时候是采用“小表驱动大表”是一种相对比较高效的方式,也即在loop join的时候,先循环小表,通过循环驱动大表,然后产生查询结果集。
该性能表面上看,是表之间的驱动顺序顺序造成的,在强制一个驱动顺序之后,性能有非常明显的提升,
但是再进一步思考,为什么默认情况下,SQL Server没有选择一个合理的驱动顺序?
因此本文就简单阐述这两个问题:
1)为什么表之间的驱动顺序会影响性能?
2)为什么SQL Server在某些情况下没有选择出正确的驱动顺序?
为什么表之间的驱动顺序会影响性能?
首先演示一下表在连接的时候,驱动顺序对性能的影响,其中test_smalltable插入1W行数据,test_bigtable插入10W行测试数据,依次来代表小表与大表
create table test_smalltable
(
id int identity(1,1) primary key,
otherColumns char(500)
) create table test_bigtable
(
id int identity(1,1) primary key,
otherColumns char(500)
) declare @i int = 0
while @i<100000
begin
if @i<10000
begin
insert into test_smalltable values (NEWID())
end
insert into test_bigtable values (NEWID())
set @i = @i + 1
end
在测试表写入数据完成之后,使用一下两个SQL,通过强制使用loop join的驱动顺序的方式来观察其IO情况
select * from test_smalltable a inner loop join test_bigtable b on a.id = b.id option(force order)
GO select * from test_bigtable a inner loop join test_smalltable b on a.id = b.id option(force order)
GO
如图,是两个SQL执行之后产生的IO信息,可以发现,因为两个表的驱动顺序不一致,导致的逻辑IO几乎差了一个数量级。
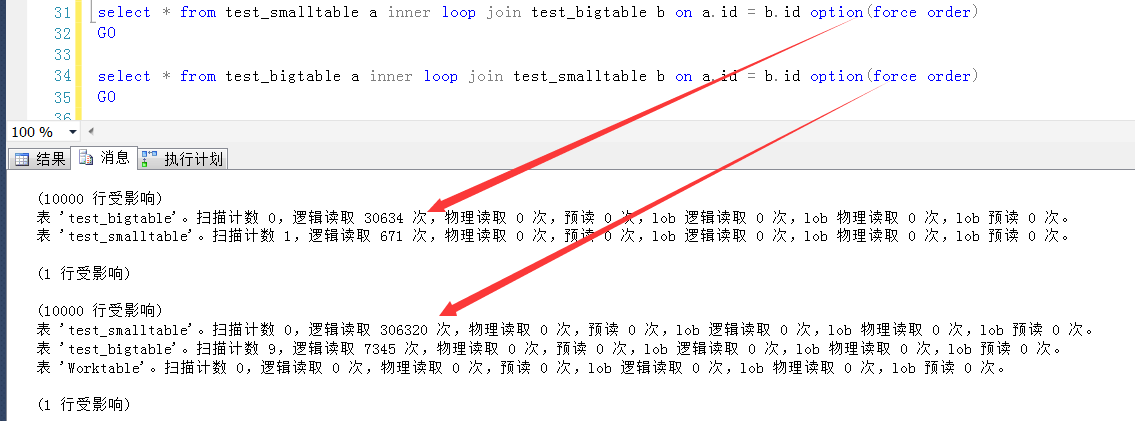
造成此问题的原因,可能有一些难以理解,双循环嵌套,谁在外谁在内还有差别,表面上看不都是一样的?其实不然。
loop join是采用的类似如下双循环嵌套的方式来执行的,直至外层的表循环结束,循环(查询)完成
foreache(outer_row in outer_table)
{
foreache(internal_row in internal_table)
{
if (outer_row.key = internal_row.key)
{
--输出结果
}
}
}
以上述测试为例,做一个粗略的对比统计
如果外层是小表(1W行),外层循环1W次,分别对内层的大表(10W行)查询,然后结束查询,相当于循环1W次,分别用Id查询内层表,
可以粗略地认为整体的代价是:1W+1W*10W = 11W,这里先忽略具体代价的单位
如果外层是大表(10W行),外层循环10W次,分别对内层的小表(1W行)查询,然后结束查询,相当于循环10W次,分别用Id查询内层表,
可以粗略地认为整体的代价是:10W+10W*1W = 20W,同理,这里也先忽略代价的单位
现在就很清楚了,前者(小表驱动大表)的代价是11W,后者(大表驱动小表)的代价是20W,因此,通常来说,小表驱动大表是一种相对较为高效的方式。
但是要注意这里的大表与小表,不仅仅是“表”级别的概念,因为实际中SQL并没有这么简单,还可以是根据筛选条件过滤之后的结果的概念,这也是引出第二个问题的关键点。
为什么SQL Server在某些情况下没有选择出正确的驱动顺序
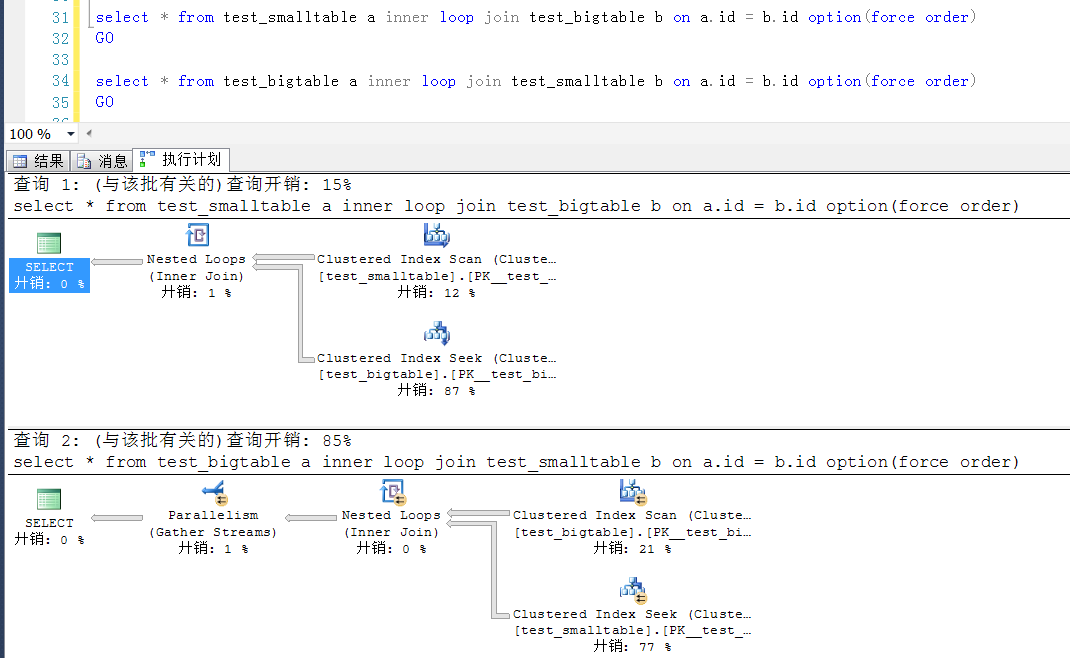
在上述的测试中,如果不加查询提示,执行计划的生成是跟表书写的顺序没有关系的,一下截图可以看到,书写顺序不一样,执行计划仍旧是一样的。
也就是说,在书写SQL语句的时候,大表在前或者在后,正常情况下是不影响执行计划的生成的。

那么为什么,一开始提到的问题,为什么SQL Server在某些情况下没有选择出正确的驱动顺序还会出现?
实际情况中,SQL的写法很少有这么简单的,更多的时候是在表连接之后,有各种各样的where条件。
上面说了,大表与小表的概念,不仅仅是“表”级别的概念,更多的是根据筛选条件过滤之后的结果(行数,或者大小)的概念,
比如,如下SQL,在where条件上可能加上各种筛选条件,比如可能是类似于type类型的,可能是时间范围的,还有可能两个表上都有某些筛选条件。
select * from test_smalltable a
inner join test_bigtable b on a.id = b.id
where a.otherColumns = '' and b.otherColumns = '' and other filter condition
那么此时,在面对复杂的查询的时候,SQL Server如何评估每个表经过各种条件筛选后的结果集的大小?
当然是依据where 后面的筛选条件(或者是on 后面的加的筛选条件),问题就来了,where 后面或者on后面的筛选条件,如何又依据什么来提供一个大概的筛选后的结果集?
没错,又是统计信息!
现在问题就清晰了起来,SQL Server依据统计信息,在经过各种(或许是比较复杂)的筛选条件过滤之后,得到一个“它自己认为的预估大小的结果集”,然后依据这个结果集来决定驱动顺序。
SQL Server在“它自己认为的预估大小的结果集”的基础上进行类似于“小表驱动大表”的方式进行运算(当然不仅仅是loop join,这里暂不说其他的join方式),
一旦这个预估的结果集的大小有较大的误差,即便是误差不大,但是足以改变真正的“小表驱动大表”的方式进行运算,第二个问题就出现了。
因此,总的来说,错误的驱动顺序,本质上在利用统计信息进行预估的时候,因为统计信息不足够准确或者预估算法自己的问题。
参考:http://www.cnblogs.com/wy123/tag/%E7%BB%9F%E8%AE%A1%E4%BF%A1%E6%81%AF%20Statistics/
导致SQL Server错误地用大表驱动的方式来执行运算,类似问题就出现了。
鉴于该问题的特殊性,很难造case,就不造case演示了,截两个实际遇到的对比结果。实际情况中,驱动顺序对性能产生的影响,可能是从0.5秒到10秒的差别,也可能是1分钟到10分钟的差别
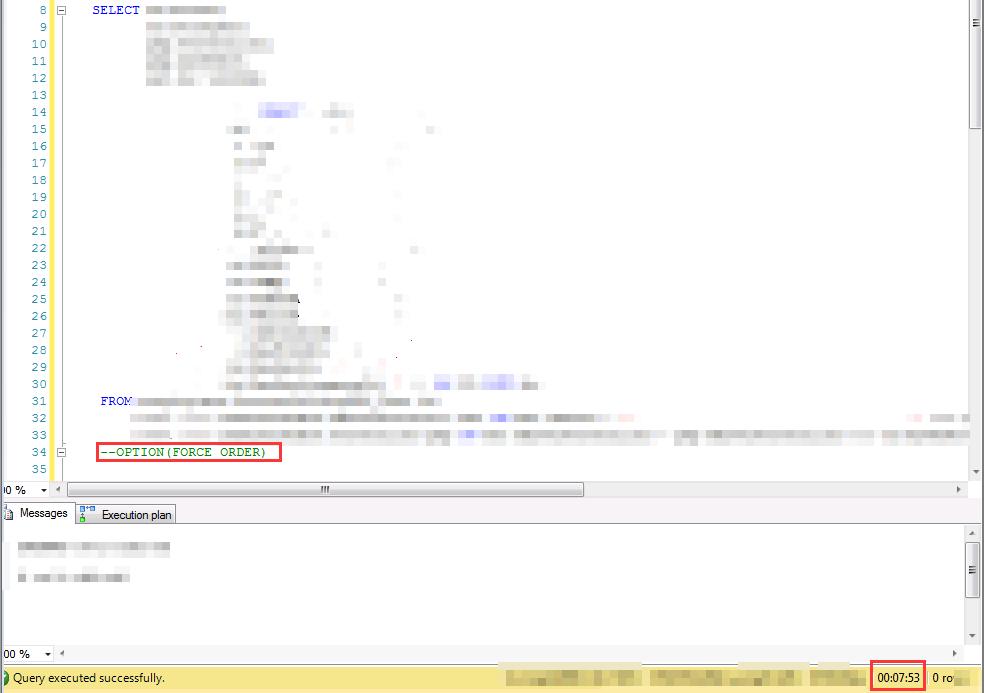
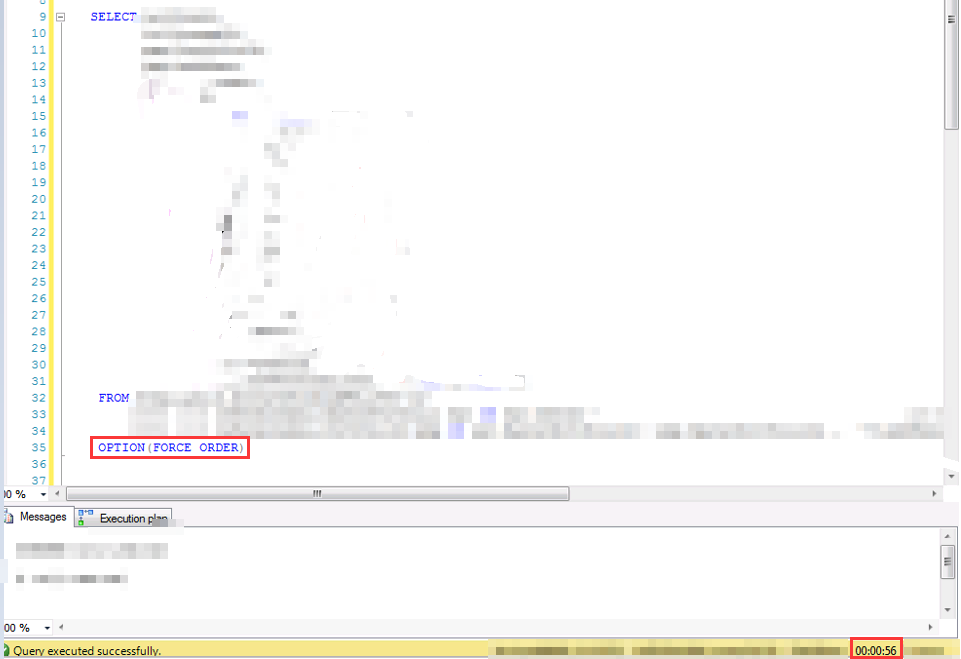
当然,加option(force order)的时候,要注意写法本身的是不是将小表放在了最前面,
在复杂的情况下,虽然是驱动顺序造成的问题,但是加option(force order)并不一定好使,因为多表连接的时候,按照书写的方式强制驱动,也不一定刚好就是一个合理的驱动顺序
甚至有更严重的问题出现,参考:http://www.cnblogs.com/wy123/p/6238844.html,因此不建议乱用option(force order)
总结:
面对较为复杂的查询和筛选条件的时候,尤其是在表中的数据较大的情况下,统计信息生成的预估,以及预估产生的表之间的驱动顺序,会对性能产生较大的影响。
面对类似问题,要确实直接原因是什么,根本原因是什么,如何快速确认问题,又要如何解决和避免,都是值得思考的,也是做性能优化的时候要考虑的问题之一。
SQL Server中多表连接时驱动顺序对性能的影响的更多相关文章
- 在SQL SERVER中获取表中的第二条数据
在SQL SERVER中获取表中的第二条数据, 思路:先根据时间逆排序取出前2条数据作为一个临时表,再按顺时排序在临时表中取出第一条数据 sql语句如下: select top 1 * from(se ...
- 显示 Sql Server 中所有表或表中行的信息
在MSSQL中显示某个数据库中所有表或视图的信息: (以下语句为获取所有表信息,将绿色字"U"替换为"V"则获取所有视图信息.) SELECT sysobjec ...
- 快速查看SQL Server 中各表的数据量以及占用空间大小
快速查看SQL Server 中各表的数据量以及占用空间大小. CREATE TABLE #T (NAME nvarchar(100),ROWS char(20),reserved varchar(1 ...
- Sql Server中判断表、列不存在则创建的方法[转]
一.Sql Server中如何判断表中某列是否存在 首先跟大家分享Sql Server中判断表中某列是否存在的两个方法,方法示例如下: 比如说要判断表A中的字段C是否存在两个方法: 第一种方法 ? ...
- SQL Server三种表连接原理
在SQL Server数据库中,查询优化器在处理表连接时,通常会使用一下三种连接方式: 嵌套循环连接(Nested Loop Join) 合并连接 (Merge Join) Hash连接 (Hash ...
- Sql Server中的表访问方式Table Scan, Index Scan, Index Seek
1.oracle中的表访问方式 在oracle中有表访问方式的说法,访问表中的数据主要通过三种方式进行访问: 全表扫描(full table scan),直接访问数据页,查找满足条件的数据 通过row ...
- 转:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek
0.参考文献 Table Scan, Index Scan, Index Seek SQL SERVER – Index Seek vs. Index Scan – Diffefence and Us ...
- 多个程序对sql server中的表进行查询和插入操作导致死锁
最近在做一个项目,是要用多个程序对sql server中的相同的数据库进行操作(查询和插入),所以在开始的时候常会出现死锁问题,后来在网上进行了咨询,发现了一些解决方法,留作大家参考: 并发去操纵一张 ...
- MS SQL Server中数据表、视图、函数/方法、存储过程是否存在判断及创建
前言 在操作数据库的时候经常会用到判断数据表.视图.函数/方法.存储过程是否存在,若存在,则需要删除后再重新创建.以下是MS SQL Server中的示例代码. 数据表(Table) 创建数据表的时候 ...
随机推荐
- Tex_Err:缺失wlscirep.cls
使用期刊模板编译时,需要'.cls'一类格式文件支持.从Overleaf上直接Copy代码到本地,发现自己的tex运行时会报错: ! LaTeX Error: File `wlscirep.cls' ...
- SQL注入之Sqli-labs系列第三十关(基于WAF防护的双引号报错注入)和三十一关
开始挑战第三十关和三十一关(Protection with WAF) 0x1 前言 这关其实和29关是同样的,login.php页面存在防护,只要检测到存在问题就跳转到hacked.php页面,不同的 ...
- HBase和Phoneix使用示例
HBase操作 基本操作 创建表 Examples: hbase> create 't1', {NAME => 'f1', VERSIONS => 5} hbase> crea ...
- Python全栈之路----函数进阶----生成器
生成器特点: 不能立即产生,取一次创建一次 只能往前走 等到走到最后,就会报错 >>> a = [i for i in range(1000)] >>> a [0, ...
- python学习之路03
一.常量和变量 1.python中的数据类型 分类: Number:数字型[整型,浮点型,复数] String:字符串型 Boolean:布尔型[True,False] None:空值 ...
- 关于C++指针
C++继承于C,对C的语法做了一些扩展.C语言中的指针占一个机器长度(32位处理器上一个指针占32位,64位处理器上安装64位操作系统一个指针占64位),指针的作用就是使用这块内存(4字节或者8字节) ...
- eclipse中mybatis自动生成插件使用
对于使用Mybatis的开发者来说, 使用mybatis generator来生成mapper 以及配置文件, 可以大大简化工作, mybatis generator有多种工作方式, eclipse插 ...
- Flutter 知识点
Flutter:一个移动应用开发框架,它使用 Dart.C++.Skia 开发,对外提供了完全不依赖系统平台的 Widget 的能力,只通过自绘图形的方式工作,具有极其优秀的跨平台性.目前已经支持了 ...
- [JAVA]对象的别名问题
对于JAVA的基本数据类型,a=b就是把b的内容复制给a.若接着又修改了a,对b是没有影响的. 但是在为对象“赋值”的时候,情况发生了变化.对一个对象进行操作时,我们真正操作的是对象的引用. 下面对两 ...
- 函数和对象 及 prototype和__proto__
对象有 __proto__ 函数有 prototype 对象的__proto__指向构造自己的函数的prototype 但有一例外 var Obj = {v:99}var pObj = Object ...