CUDA加opencv复现导向滤波算法
CUDA是GPU通用计算的一种,其中现在大热的深度学习底层GPU计算差不多都选择的CUDA,在这我们先简单了解下其中的一些概念,为了好理解,我们先用DX11里的Compute shader来和CUDA比较下,这二者都可用于GPU通用计算。
先上一张微软MSDN上的图.
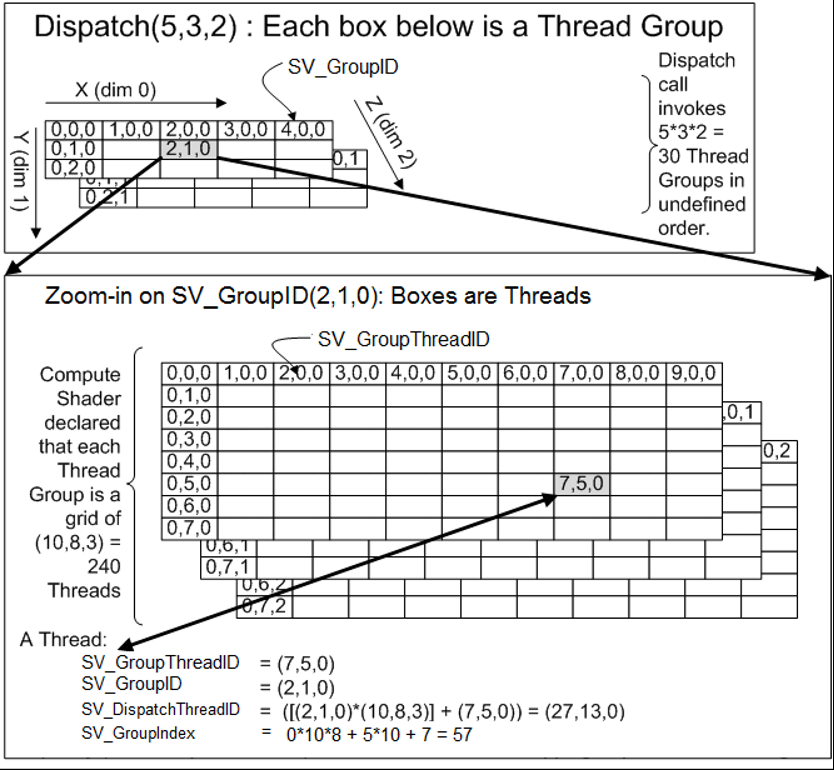
Compute shader:
线程块: Dispatch(x,y,z), 索引SV_GroupID
线程组: [numthreads(SIZE_X, SIZE_Y, 1)], 索引SV_GroupThreadID.
组内索引: CS以组为单位,shader共享在一个组内,groupshared / GroupMemoryBarrierWithGroupSync,其SV_GroupIndex为组内索引,组内共享块一般用此SV_GroupIndex做为索引,或是这个的倍数,SV_GroupIndex = SV_GroupThreadID.x + SV_GroupThreadID.y*SIZE_X(在这假定二维)
所有线程唯一索引:在整个空间的索引三维索引为SV_DispatchThreadID,SV_DispatchThreadID = SV_GroupThreadID+SV_GroupID*numthreads;
如果提供一个width,height的数据,有关系width=x*SIZE_X,height=y*SIZE_Y.(所以一般我们得到数据的长宽,然后设定线程组后,调度就直接求出来了,但是可能不是整除,所以可以把真实的传入进去).而SV_DispatchThreadID表示在整个width,height中的索引,一般来说,我们直接用SV_DispatchThreadID就够了,但是如果使用了groupshared/GroupMemoryBarrierWithGroupSync,就会用SV_GroupIndex来整个当个线程组计算。
同样的概念CUDA中:increment_kernel<<<gridDim, blockDim, 0, 0>>>
线程块: gridDim, 索引 blockIdx
线程组: blockDim 索引 threadIdx
组内索引:给组内共享块索引用.__shared__/__syncthreads,那针对的对象应该用groupIndex来当索引。
int groupIndex = threadIdx.x;(假定一维)
int groupIndex = threadIdx.x + threadIdx.y*blockDim.x;(假定二维)
所有线程唯一索引: 在线程组里的索引 threadIdx ,和dx cs不同,这里是三维的。
如上找到在整个width,height中的位置和上面的SV_DispatchThreadID一样。
const int idx = threadIdx.x + blockIdx.x * blockDim.x; const int idy = threadIdx.y + blockIdx.y * blockDim.y;
同理dx11里常用内存显存交换API如map/unmap对应cudaMemcpyAsync cudaMemcpyDeviceToHost/cudaMemcpyHostToDevice这些。
回到正题上,导向滤波算法 是何凯明提出的一种保边滤波算法,这种算法在这不细说,opencv已经自带这种算法,这篇文章只是针对这种算法实现一个cuda版本的,毕竟对于图像处理来说,很多点都是并行计算的,这个链接里有提到matlab的实现,我们看下多通道下的快速实现来看下效果。

效果非常牛,其中我把相应matlab实现贴出来,先简单理解下,其中matlab的这种写法很像一些深度学习库python接口里提供的数据操作类的用法,看起来还是很好理解的。
function q = fastguidedfilter_color(I, p, r, eps, s)
% GUIDEDFILTER_COLOR O() time implementation of guided filter using a color image as the guidance.
%
% - guidance image: I (should be a color (RGB) image)
% - filtering input image: p (should be a gray-scale/single channel image)
% - local window radius: r
% - regularization parameter: eps
% - subsampling ratio: s (try s = r/ to s=r) I_sub = imresize(I, /s, 'nearest'); % NN is often enough
p_sub = imresize(p, /s, 'nearest');
r_sub = r / s; % make sure this is an integer [hei, wid] = size(p_sub);
N = boxfilter(ones(hei, wid), r_sub); % the size of each local patch; N=(2r+)^ except for boundary pixels. mean_I_r = boxfilter(I_sub(:, :, ), r_sub) ./ N;
mean_I_g = boxfilter(I_sub(:, :, ), r_sub) ./ N;
mean_I_b = boxfilter(I_sub(:, :, ), r_sub) ./ N; mean_p = boxfilter(p_sub, r_sub) ./ N; mean_Ip_r = boxfilter(I_sub(:, :, ).*p_sub, r_sub) ./ N;
mean_Ip_g = boxfilter(I_sub(:, :, ).*p_sub, r_sub) ./ N;
mean_Ip_b = boxfilter(I_sub(:, :, ).*p_sub, r_sub) ./ N; % covariance of (I, p) in each local patch.
cov_Ip_r = mean_Ip_r - mean_I_r .* mean_p;
cov_Ip_g = mean_Ip_g - mean_I_g .* mean_p;
cov_Ip_b = mean_Ip_b - mean_I_b .* mean_p; % variance of I in each local patch: the matrix Sigma in Eqn ().
% Note the variance in each local patch is a 3x3 symmetric matrix:
% rr, rg, rb
% Sigma = rg, gg, gb
% rb, gb, bb
var_I_rr = boxfilter(I_sub(:, :, ).*I_sub(:, :, ), r_sub) ./ N - mean_I_r .* mean_I_r;
var_I_rg = boxfilter(I_sub(:, :, ).*I_sub(:, :, ), r_sub) ./ N - mean_I_r .* mean_I_g;
var_I_rb = boxfilter(I_sub(:, :, ).*I_sub(:, :, ), r_sub) ./ N - mean_I_r .* mean_I_b;
var_I_gg = boxfilter(I_sub(:, :, ).*I_sub(:, :, ), r_sub) ./ N - mean_I_g .* mean_I_g;
var_I_gb = boxfilter(I_sub(:, :, ).*I_sub(:, :, ), r_sub) ./ N - mean_I_g .* mean_I_b;
var_I_bb = boxfilter(I_sub(:, :, ).*I_sub(:, :, ), r_sub) ./ N - mean_I_b .* mean_I_b; a = zeros(hei, wid, );
for y=:hei
for x=:wid
Sigma = [var_I_rr(y, x), var_I_rg(y, x), var_I_rb(y, x);
var_I_rg(y, x), var_I_gg(y, x), var_I_gb(y, x);
var_I_rb(y, x), var_I_gb(y, x), var_I_bb(y, x)]; cov_Ip = [cov_Ip_r(y, x), cov_Ip_g(y, x), cov_Ip_b(y, x)]; a(y, x, :) = cov_Ip * inv(Sigma + eps * eye()); % very inefficient. Replace this in your C++ code.
end
end b = mean_p - a(:, :, ) .* mean_I_r - a(:, :, ) .* mean_I_g - a(:, :, ) .* mean_I_b; % Eqn. () in the paper; mean_a(:, :, ) = boxfilter(a(:, :, ), r_sub)./N;
mean_a(:, :, ) = boxfilter(a(:, :, ), r_sub)./N;
mean_a(:, :, ) = boxfilter(a(:, :, ), r_sub)./N;
mean_b = boxfilter(b, r_sub)./N; mean_a = imresize(mean_a, [size(I, ), size(I, )], 'bilinear'); % bilinear is recommended
mean_b = imresize(mean_b, [size(I, ), size(I, )], 'bilinear');
q = mean_a(:, :, ) .* I(:, :, )...
+ mean_a(:, :, ) .* I(:, :, )...
+ mean_a(:, :, ) .* I(:, :, )...
+ mean_b;
end
fastguidedfilter_color
实现方式很简单,我们需要做的就是把这代码转换成CUDA代码,如果只是CUDA代码,相应显示图像效果不好搞,我们引入opencv,并使用其中提供的cv::cuda::GpuMat来简单封装,我们来看下如何实现CUDA本身库以及我们自己的核函数加opencv提供的CUDA函数一起来实现如下matlab的CUDA实现。
inline __host__ __device__ void inverseMat3x3(const float3& col0, const float3& col1, const float3& col2, float3& invCol0, float3& invCol1, float3& invCol2)
{
float det = col0.x*(col1.y*col2.z - col2.y*col1.z)
- col0.y*(col1.x*col2.z - col1.z*col2.x)
+ col0.z*(col1.x*col2.y - col1.y*col2.x);
if (det > 0.000000001f)
{
float invdet = 1.0f / det;
invCol0.x = (col1.y*col2.z - col2.y*col1.z)*invdet;
invCol0.y = (col0.z*col2.y - col0.y*col2.z)*invdet;
invCol0.z = (col0.y*col1.z - col0.z*col1.y)*invdet;
invCol1.x = (col1.z*col2.x - col1.x*col2.z)*invdet;
invCol1.y = (col0.x*col2.z - col0.z*col2.x)*invdet;
invCol1.z = (col1.x*col0.z - col0.x*col1.z)*invdet;
invCol2.x = (col1.x*col2.y - col2.x*col1.y)*invdet;
invCol2.y = (col2.x*col0.y - col0.x*col2.y)*invdet;
invCol2.z = (col0.x*col1.y - col1.x*col0.y)*invdet;
}
} inline __host__ __device__ float3 mulMat(const float3 data, const float3& col0, const float3& col1, const float3& col2)
{
float3 dest;
dest.x = dot(data, make_float3(col0.x, col1.x, col2.x));
dest.y = dot(data, make_float3(col0.y, col1.y, col2.y));
dest.z = dot(data, make_float3(col0.z, col1.z, col2.z));
return dest;
} inline __global__ void findMatrix(PtrStepSz<float4> source, PtrStepSz<float3> dest, PtrStepSz<float3> dest1, PtrStepSz<float3> dest2)
{
const int idx = blockDim.x * blockIdx.x + threadIdx.x;
const int idy = blockDim.y * blockIdx.y + threadIdx.y; if (idx < source.cols && idy < source.rows)
{
float4 scolor = source(idy, idx);// rgbauchar42float4(source(idy, idx));
float3 color = make_float3(scolor); dest(idy, idx) = color*scolor.w;
dest1(idy, idx) = color.x*color;
dest2(idy, idx) = make_float3(color.y*color.y, color.y*color.z, color.z*color.z);
}
} //导向滤波求值 Guided filter 论文地址http://kaiminghe.com/publications/pami12guidedfilter.pdf
inline __global__ void guidedFilter(PtrStepSz<float4> source, PtrStepSz<float3> col1, PtrStepSz<float3> col2, PtrStepSz<float3> col3, PtrStepSz<float4> dest, float eps)
{
const int idx = blockDim.x * blockIdx.x + threadIdx.x;
const int idy = blockDim.y * blockIdx.y + threadIdx.y; if (idx < source.cols && idy < source.rows)
{
float4 color = source(idy, idx);// rgbauchar42float4(source(idy, idx));
float3 mean_I = make_float3(color);
float mean_p = color.w;
float3 mean_Ip = col1(idy, idx);// rgbauchar32float3(col1(idy, idx));
float3 var_I_r = col2(idy, idx) - mean_I.x*mean_I;// rgbauchar32float3(col2(idy, idx)) - mean_I.x*mean_I;//col0
float3 var_I_gbxfv = col3(idy, idx);// rgbauchar32float3(col3(idy, idx));
float gg = var_I_gbxfv.x - mean_I.y*mean_I.y;
float gb = var_I_gbxfv.y - mean_I.y*mean_I.z;
float bb = var_I_gbxfv.z - mean_I.z*mean_I.z; float3 cov_Ip = mean_Ip - mean_I*mean_p;
float3 col0 = var_I_r + make_float3(eps, .f, .f);
float3 col1 = make_float3(var_I_r.y, gg + eps, gb);
float3 col2 = make_float3(var_I_r.z, gb, bb + eps); float3 invCol0 = make_float3(.f, .f, .f);
float3 invCol1 = make_float3(.f, .f, .f);
float3 invCol2 = make_float3(.f, .f, .f);
inverseMat3x3(col0, col1, col2, invCol0, invCol1, invCol2);
float3 a = mulMat(cov_Ip, invCol0, invCol1, invCol2);
float b = mean_p - dot(a, mean_I); dest(idy, idx) = make_float4(a, b);
}
} inline __global__ void guidedFilterResult(PtrStepSz<float4> source, PtrStepSz<float4> guid, PtrStepSz<uchar4> dest, PtrStepSz<uchar> destp)
{
const int idx = blockDim.x * blockIdx.x + threadIdx.x;
const int idy = blockDim.y * blockIdx.y + threadIdx.y; if (idx < source.cols && idy < source.rows)
{
float4 color = source(idy, idx);// rgbauchar42float4(source(idy, idx));//I
float4 mean = guid(idy, idx);
float q = clamp(color.x*mean.x + color.y*mean.y + color.z*mean.z + mean.w, .f, .f);
float3 rgb = make_float3(color*q);
dest(idy, idx) = rgbafloat42uchar4(make_float4(rgb, q));
destp(idy, idx) = (uchar)(__saturatef(q)*255.0f);
}
}
矩阵计算
这种主要是matlab实现里,CUDA库和opencv本身没有提供的,我们自己需要实现的一部分,主要是导向滤波里多通道计算的一部分,如下我们给出opencv里的完整实现。
#include <cuda.h>
#include <cuda_runtime.h> #include <opencv2/core.hpp>
#include <opencv2/core/cuda.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/core/cuda_stream_accessor.hpp>
#include <opencv2/cudaimgproc.hpp>
#include <opencv2/cudawarping.hpp>
#include <opencv2/cudafilters.hpp> #include "cuda_help.h"
#include "fastguidedfilter.h" extern "C" void test11()
{
#pragma region xxxx
cv::cuda::setDevice(); std::string windowNameIP = "vvvvvIP";
namedWindow(windowNameIP);
std::string windowNameP = "vvvvvP";
namedWindow(windowNameP); Stream curentStream = {};
cudaStream_t cudaStream = StreamAccessor::getStream(curentStream); int scale = ;
int width = ;
int height = ;
int scaleWidth = width / scale;
int scaleHeight = height / scale; Mat frame(height, width, CV_8UC3);
Mat resultFrame;// (height, width, CV_8UC3);
Mat cpuIP;// (scaleHeight, scaleWidth, CV_8UC4);
Mat cpuP; Mat I(height, width, CV_8UC3);
Mat P(height, width, CV_8UC3);
cv::cuda::GpuMat gpuI;
cv::cuda::GpuMat gpuP; cv::cuda::GpuMat gpuKeying(height, width, CV_32FC4);
cv::cuda::GpuMat gpuCvting;
//I_sub+p_sub
cv::cuda::GpuMat gpuResize(scaleHeight, scaleWidth, CV_32FC4);//I_sub+p_sub
cv::cuda::GpuMat mean_I(scaleHeight, scaleWidth, CV_32FC4); //box I_sub+p_sub mean_Irgb+mean_p cv::cuda::GpuMat mean_Ipv(scaleHeight, scaleWidth, CV_32FC3);
cv::cuda::GpuMat var_I_rxv(scaleHeight, scaleWidth, CV_32FC3);
cv::cuda::GpuMat var_I_gbxfv(scaleHeight, scaleWidth, CV_32FC3); cv::cuda::GpuMat mean_Ip(scaleHeight, scaleWidth, CV_32FC3);
cv::cuda::GpuMat var_I_rx(scaleHeight, scaleWidth, CV_32FC3);
cv::cuda::GpuMat var_I_gbxf(scaleHeight, scaleWidth, CV_32FC3); cv::cuda::GpuMat meanv(scaleHeight, scaleWidth, CV_32FC4);
cv::cuda::GpuMat means(scaleHeight, scaleWidth, CV_32FC4);
cv::cuda::GpuMat mean(scaleHeight, scaleWidth, CV_32FC4);
cv::cuda::GpuMat resultIP(height, width, CV_8UC4);
cv::cuda::GpuMat resultP(height, width, CV_8UC1); const char imgPathI[] = "D:\\下载\\fast-guided-filter-code-v1\\img_feathering\\toy.bmp";
const char imgPathP[] = "D:\\下载\\fast-guided-filter-code-v1\\img_feathering\\toy-mask.bmp";
I = cv::imread(imgPathI, IMREAD_COLOR);
P = cv::imread(imgPathP, IMREAD_GRAYSCALE);
#pragma endregion #pragma region paramet
dim3 block(, );
dim3 grid(divUp(width, block.x), divUp(height, block.y));
dim3 grid2(divUp(scaleWidth, block.x), divUp(scaleHeight, block.y)); //创建blue
auto filter = cv::cuda::createBoxFilter(CV_8UC4, CV_8UC4, Size(, ));//包装的NPP里的nppiFilterBox_8u_C4R
int softness = ;
float eps = 0.000001f;
NppiSize oSizeROI; //NPPI blue
oSizeROI.width = scaleWidth;
oSizeROI.height = scaleHeight;
NppiSize oMaskSize;
oMaskSize.height = softness;
oMaskSize.width = softness;
NppiPoint oAnchor;
oAnchor.x = oMaskSize.width / ;
oAnchor.y = oMaskSize.height / ;
NppiPoint oSrcOffset = { , }; setNppStream(cudaStream);
#pragma endregion while (int key = cv::waitKey())
{
gpuI.upload(I);
gpuP.upload(P);
//把颜色通道与导向通道合并,他们很多计算是同样的,合成四通道的加速并容易对齐32/64/128这些值
combin << <grid, block, , cudaStream >> > (gpuI, gpuP, gpuKeying);
//导向滤波这算法的优势,与图像大小可以做到无关,在这我们使用缩小8倍后的大小
cv::cuda::resize(gpuKeying, gpuResize, cv::Size(scaleWidth, scaleHeight), , , cv::INTER_NEAREST, curentStream);
//计算矩阵 rr, rg, rb/rg, gg, gb/rb, gb, bb
findMatrix << <grid2, block, , cudaStream >> > (gpuResize, mean_Ipv, var_I_rxv, var_I_gbxfv);
//模糊缩小后的原始值
nppiFilterBoxBorder_32f_C4R((Npp32f*)gpuResize.ptr<float4>(), gpuResize.step, oSizeROI, oSrcOffset, (Npp32f*)mean_I.ptr<float4>(), mean_I.step, oSizeROI, oMaskSize, oAnchor, NPP_BORDER_REPLICATE);
//模糊矩阵
nppiFilterBoxBorder_32f_C3R((Npp32f*)mean_Ipv.ptr<float3>(), mean_Ipv.step, oSizeROI, oSrcOffset, (Npp32f*)mean_Ip.ptr<float3>(), mean_Ip.step, oSizeROI, oMaskSize, oAnchor, NPP_BORDER_REPLICATE);
nppiFilterBoxBorder_32f_C3R((Npp32f*)var_I_rxv.ptr<float3>(), var_I_rxv.step, oSizeROI, oSrcOffset, (Npp32f*)var_I_rx.ptr<float3>(), var_I_rx.step, oSizeROI, oMaskSize, oAnchor, NPP_BORDER_REPLICATE);
nppiFilterBoxBorder_32f_C3R((Npp32f*)var_I_gbxfv.ptr<float3>(), var_I_gbxfv.step, oSizeROI, oSrcOffset, (Npp32f*)var_I_gbxf.ptr<float3>(), var_I_gbxf.step, oSizeROI, oMaskSize, oAnchor, NPP_BORDER_REPLICATE);
//求导
guidedFilter << <grid2, block, , cudaStream >> > (mean_I, mean_Ip, var_I_rx, var_I_gbxf, meanv, eps);
//模糊求导的结果
nppiFilterBoxBorder_32f_C4R((Npp32f*)meanv.ptr<float4>(), meanv.step, oSizeROI, oSrcOffset, (Npp32f*)means.ptr<float4>(), means.step, oSizeROI, oMaskSize, oAnchor, NPP_BORDER_REPLICATE);
//返回到原图像大小
cv::cuda::resize(means, mean, cv::Size(width, height), , , cv::INTER_LINEAR, curentStream);
//求结果
guidedFilterResult << <grid, block, , cudaStream >> > (gpuKeying, mean, resultIP, resultP);
//显示结果
resultIP.download(cpuIP);
resultP.download(cpuP);
cv::imshow(windowNameIP, cpuIP);
cv::imshow(windowNameP, cpuP);
}
}
opencv cuda fastguided
同样,给出实现效果。
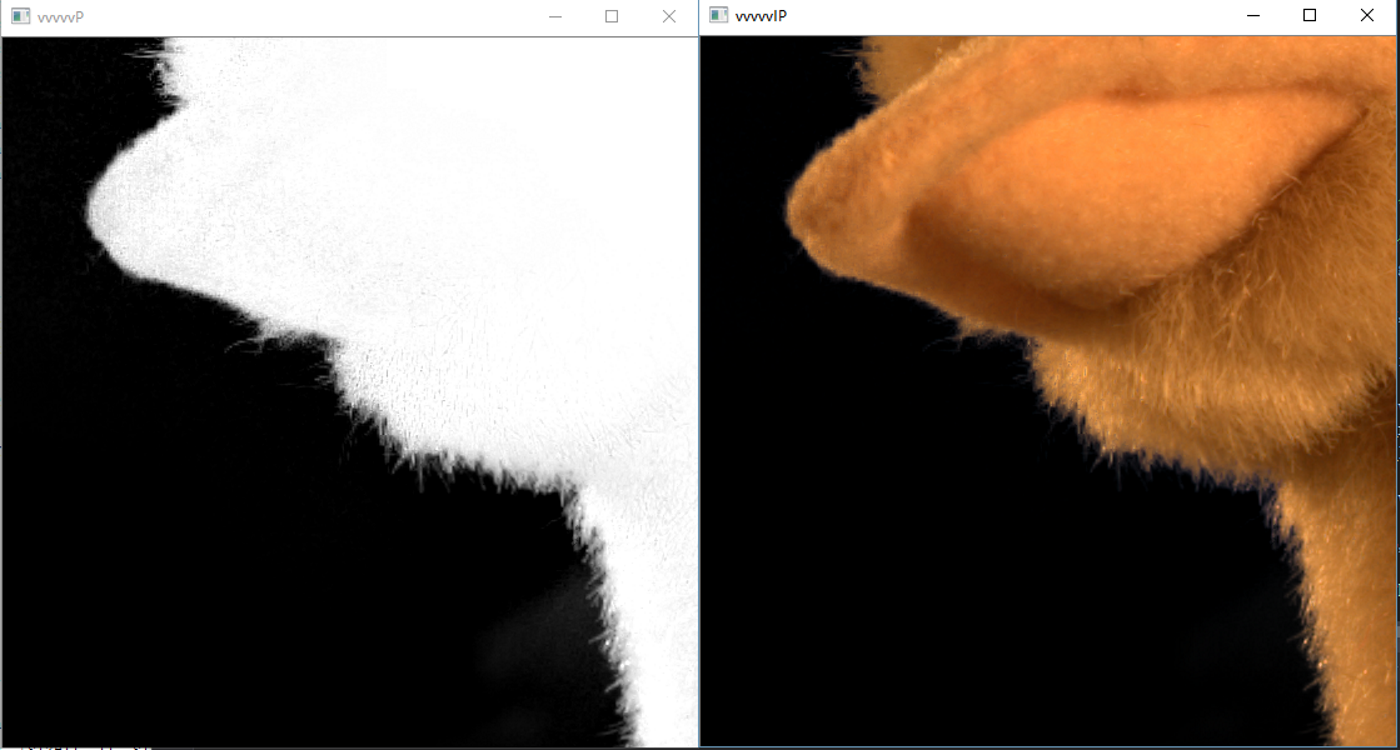
和matlab的效果,哈哈,反正我肉眼没看到区别。
说下这个实现过程的一些想法和弯路,其中matlab主要不一样的地方是,他把颜色图与导向图分开处理的,但是这二者大部分处理是一样的,为了加速计算,在cuda里,我首先把导向图与颜色图合并然后一起做计算,别的处理都是差不多的。最开始其中的boxfilter方法准备用opncv提供的,但是发现他封装的CUDA实现并不完善,一些如float3的模糊并没有封装,所以就用原生的CUDA库里的实现,其中做了次测试,刚开始为了更好的性能,其中开始合并的图,中间的矩阵全用的是char来表示的float,毕竟刚开始以为缩小图像影响很大,而模糊的核大一般设大点(根据算法原理,核越大,突出边缘拿到的越大), 而核大了,又用的float,box模糊很容易塞满局部共享存储器,这玩意满了优化的速度就没了,然后发现结果完全不对,周边全是半透的模糊值,然后把中间的矩阵全改成float计算,改后发现效果好多了,但是边缘部分有些燥点,嗯,把合并的图改成float值类型后,结果和matlab以肉眼来看是一样了。还好,发现其中的缩小的倍率不影响结果,直接把原图缩小二倍和八倍效果一样,缩小八倍后,1070以10%左右占用在不到一毫秒下完成算法,虽然是因为图像比较小的原因,但是这个确实牛叉。
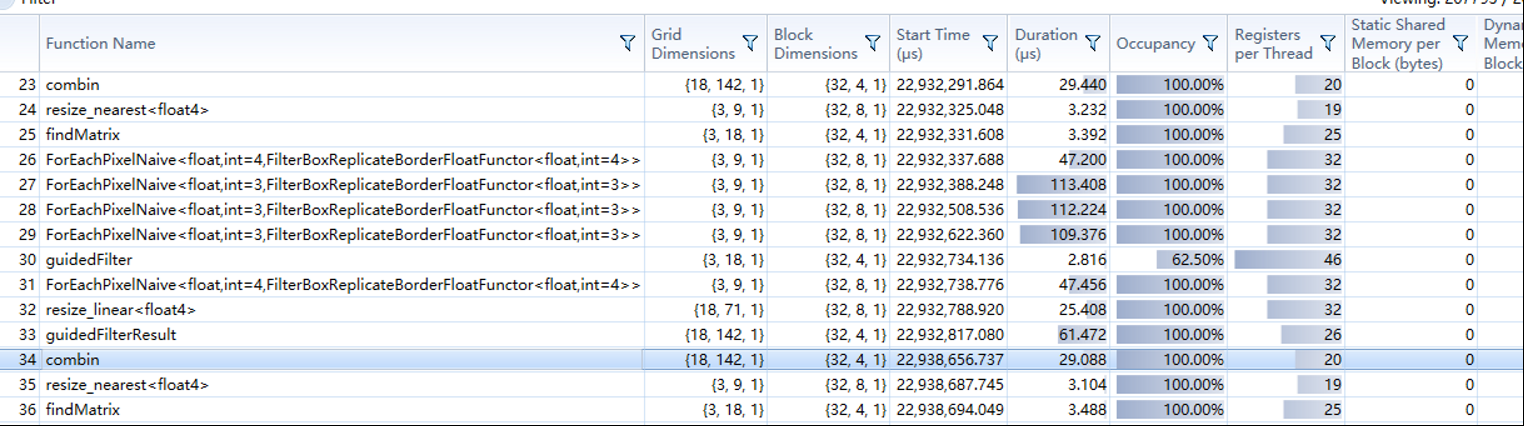
在1070下,可以看到,不到一毫秒的处理,但是需要注意的,其中显存与内存的交互占了差不多一毫秒,而这是小分辨率的,而在1080P下,处理过程还在一毫秒左右,而显存与内存的上传下载差不多五毫秒了,所以考虑GPU通用计算一定要注意这种交互时间,所以最后的结果如果是给引擎渲染的就很不错,只需要从内存到显存这一步,或是显存大了,全显存交互就更快了。
在opencv下用CUDA还是很方便的,一是提供的GpuMat太方便了,帮我们保存了长宽,pitch,毕竟针对图像处理,每个核函数差不多都要这三个参数,有了GpuMat,感觉写的时候都爽了些,二是提供图像一些基本处理,读显示处理这些都能实现,大大提高效率。
最后说下,我们知道GPU有多个流处理器,所以很善长一个并行计算,所以一些我们在CPU下的方法拿到GPU下,很多就不一样,我们来简单分析下opencv下的cuda模块中的算法,帮助我们理解GPU编程模式与优化。
如下是常见的聚合算法处理,如一个列表里的最大值,最小值,列表的和等等。

这个算法在CPU下,我们常见就是一个for,找到最大值,在GPU中,分成多组,然后折半计算,而到32时,我们看到没有用__syncthreads来同步块了,主要是因为CUDA中,最小的执行单元是线程束,线程束是一起执行的,而一个线程束是32个线程组,故上在一个线程束里,因为是一起执行,相当于天然的__syncthreads。
如下是一段简单的代码,拿出来主要是因为opencv/CUDA底层会用这段,拿到数据,根据你的grid/block确定总大小N,然后只需要循环总长/N,不过一般来说,图像处理,我们会根据长宽自动分配对应的grid/block,所以我们的不需要外面这层循环。
还有用局部共享存储器的优化,毕竟局部共享存储器比全局存储器访问要快,比如模糊,每个块要取周块一些点运行,导致访问全局存储器过多,在这就可以先根据模糊的设置每块读取相应数据到局部共享存储器,然后做计算时从局部共享存储器取值,有兴趣的可以参看opencv_cudafilter里的如linearRowFilter的实现。
其中需要注意的一些事项,GpuMat创建显存单元用的是cudaMallocPitch而 cuda 中这样分配的二维数组内存保证了数组每一行首元素的地址值都按照 256 或 512 的倍数对齐,提高访问效率,但使得每行末尾元素与下一行首元素地址可能不连贯,使用指针寻址时要注意考虑尾部。比如960*540 CV_8UC4的step就不是960*4=3840,而是4096。1920*1080 cv_8uc3 的是6144,1920*1080 cv_8uc4 的是7680,与1920*4相等,我们在内存要拿到连续值就需要用cudaHostAlloc,然后用cudaMemcpy2DToArray复制过来。而出现an illegal memory access was encountered这个错误一般来说,肯定是你核函数里访问超出你对应数据的索引,一般来说,是对应id计算失误或是分配grid/block考虑不对。
CUDA有个非常好用的调试器Nsight,如上an illegal memory access was encountered就容易很清楚知道那个块索引出了问题,对应数据是否是正常的,以及相应的代码,调试数据和VS自身的差不多,非常方便,熟悉这工具,事半功倍。
CUDA加opencv复现导向滤波算法的更多相关文章
- 目标跟踪之粒子滤波---Opencv实现粒子滤波算法
目标跟踪学习笔记_2(particle filter初探1) 目标跟踪学习笔记_3(particle filter初探2) 前面2篇博客已经提到当粒子数增加时会内存报错,后面又仔细查了下程序,是代码方 ...
- Vulkan移植GpuImage(二)Harris角点检测与导向滤波
Harris角点检测 UI还是用的上次扣像的,只有前后置可以用,别的没有效果,只看实现就好. 相应源码 在实现之前,我先重新整理编译glsl的生成工具,如Harris角点检测中间计算过程需要针对rgb ...
- OpenCV导向滤波(引导滤波)实现(Guided Filter)代码,以及使用颜色先验算法去雾
论文下载地址:http://research.microsoft.com/en-us/um/people/jiansun/papers/GuidedFilter_ECCV10.pdf 本文主要介绍导向 ...
- OPENCV基本滤波算法
图像滤波的主要目的是为了在保留图像细节的情况下尽量的对图像的噪声进行消除,从而是后来的图像处理变得更加的方便. 图像的滤波效果要满足两个条件:1.不能损坏图像的轮廓和边缘这些重要的特征信息.2.图像的 ...
- SSE图像算法优化系列三:超高速导向滤波实现过程纪要(欢迎挑战)
自从何凯明提出导向滤波后,因为其算法的简单性和有效性,该算法得到了广泛的应用,以至于新版的matlab都将其作为标准自带的函数之一了,利用他可以解决的所有的保边滤波器的能解决的问题,比如细节增强.HD ...
- SSE图像算法优化系列二十二:优化龚元浩博士的曲率滤波算法,达到约1000 MPixels/Sec的单次迭代速度
2015年龚博士的曲率滤波算法刚出来的时候,在图像处理界也曾引起不小的轰动,特别是其所说的算法的简洁性,以及算法的效果.执行效率等方面较其他算法均有一定的优势,我在该算法刚出来时也曾经有关注,不过 ...
- 基于Vivado HLS在zedboard中的Sobel滤波算法实现
基于Vivado HLS在zedboard中的Sobel滤波算法实现 平台:zedboard + Webcam 工具:g++4.6 + VIVADO HLS + XILINX EDK + ...
- 【OpenCV新手教程之十五】水漫金山:OpenCV漫水填充算法(Floodfill)
本系列文章由@浅墨_毛星云 出品,转载请注明出处. 文章链接: http://blog.csdn.net/poem_qianmo/article/details/28261997 作者:毛星云( ...
- opencv基于PCA降维算法的人脸识别
opencv基于PCA降维算法的人脸识别(att_faces) 一.数据提取与处理 # 导入所需模块 import matplotlib.pyplot as plt import numpy as n ...
随机推荐
- Scrapy基础(一) ------学习Scrapy之前所要了解的
技术选型: Scrapy vs requsts+beautifulsoup 1,reqests,beautifulsoup都是库,Scrapy是框架 2,Scrapy中可以加入reques ...
- MySQL环境变量的配置
找到mysql安装的bin目录下复制此路径: 我的电脑右击属性====>>高级系统设置==>>环境变量 找到path 单击编辑将路径粘贴到变量值的最前面,在bin后面加上英文的 ...
- 浅析webpack使用方法
webpack是一个网页模块打包工具,可以将所有代码.图片.样式打包在一起,除此之外还有许多实用的功能.最近看了一个慕课学习了一下webpack的使用,在这里做一下总结. 本文不会涉及太多深入的知识, ...
- c++检查内存泄漏
使用_CrtDumpMemoryLeaks()函数检查内存泄漏 #include <cstdio> #include <cstdlib> #include <crtdbg ...
- 【Newtonsoft.Json】自己实现JsonConverter ,精简返回的数据结果
Newtonsoft.Json的Json数据转换很好用,也提供了很多直接使用的类型
- 编程菜鸟的日记-初学尝试编程-C++ Primer Plus 第4章编程练习4
#include <iostream>#include <string>using namespace std;int main(){ string fname; string ...
- 前端可视化数据--echarts
很幸运能够给大家分享我对echarts的见解,在一些大型互联网公司面试时都会问到会使用echarts么? 今天在做项目时有这个需求,有幸学习echarts. 二.echarts.js的优势与不足 优 ...
- c# 后台绑定treeview 单个tab
<wijmo:C1TreeView ID="C1TreeView1" runat="server" ShowCheckBoxes="true&q ...
- JS_高程5.引用类型(1)Object类型
引用类型 在ECMASCript中,引用类型是一种数据结构,将数据和功能组织在一起,引用类型有时候也被称为对象定义,因为它们描述的是一类对象所具有的属性和方法.(注意:尽管ECMAScript从技术上 ...
- EBS WEBADI 下载模板提示 Visual Basic 运行时错误 '91' 对象变量或With块变量未设置
按以下的方法设置一遍EXCEL,并设置浏览器的安全属性.