使用Python爬虫爬取网络美女图片
准备工作
安装python3.6
略
安装requests库(用于请求静态页面)
pip install requests -i https://mirrors.ustc.edu.cn/pypi/web/simple
安装lxml库(用于解析html文件)
pip install lxml -i https://mirrors.ustc.edu.cn/pypi/web/simple
安装与配置selenium(用于请求动态页面)
pip install selenium -i https://mirrors.ustc.edu.cn/pypi/web/simple
selenium 需要与浏览器配合使用,在以前的爬虫教程中,往往把 selenium 和 PhantomJS 配合使用,PhantomJS 是一款无界面的浏览器,能否执行js脚本,从而可以实现加载和渲染动态页面。但是由于最新版 selenium 已经不再支持 PhantomJS,所以必须使用其他浏览器代替,本教程使用的是Firefox浏览器,Firefox浏览器也支持无界面模式( headless模式 ),用于爬虫非常方便。另外Chrome也是支持的。详细的安装与配置教程请参考:
本教程要爬取的美女图片来自
页面分析
图集列表页面
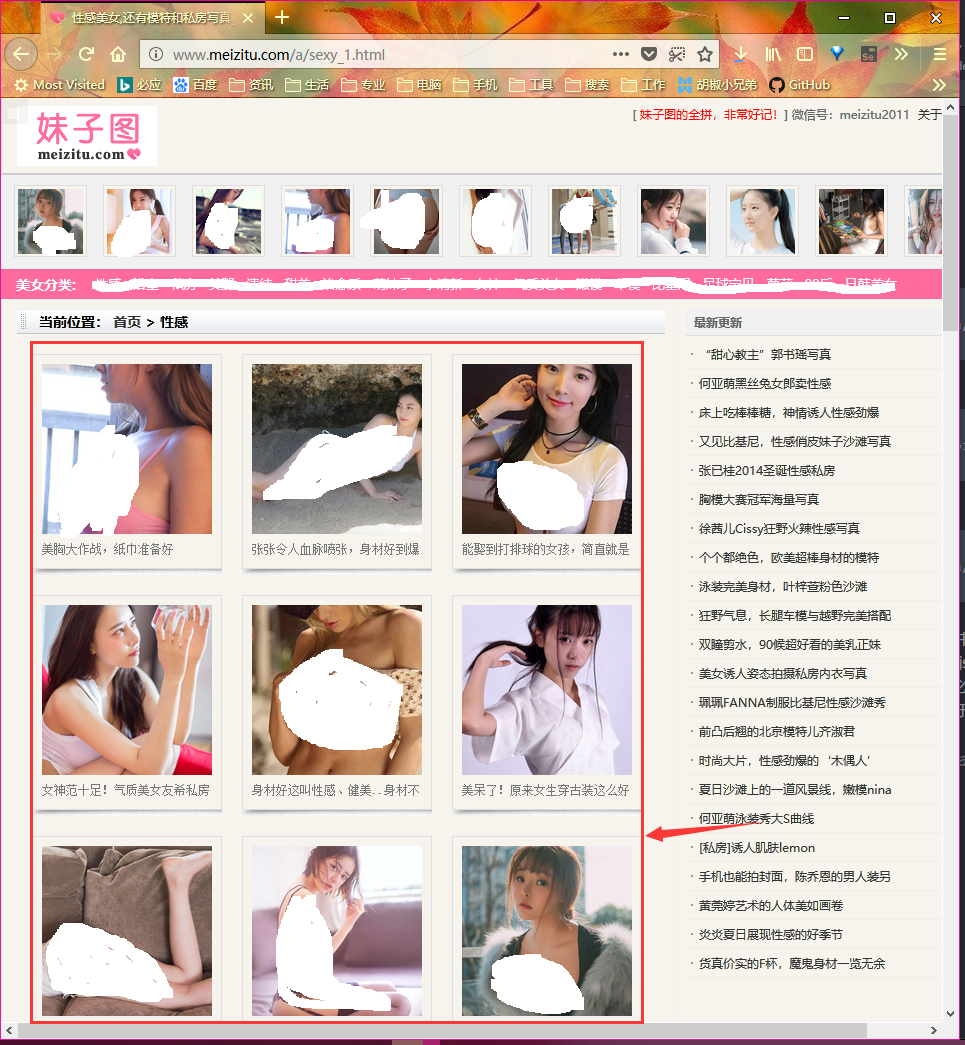
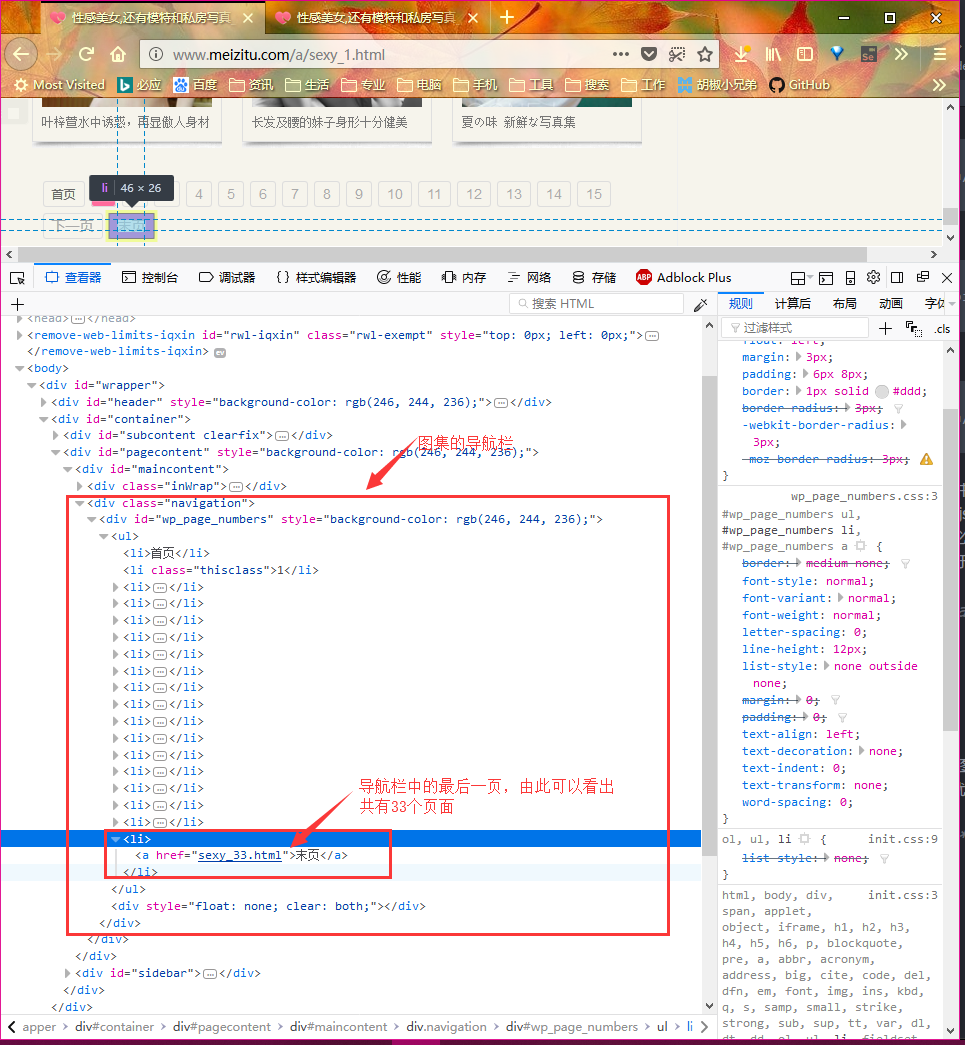
打开妹子图页面,如下图。页面的正文部分列出了33个美女图集。每个页面共有33个图集,总共有33个页面,所以总共有1089个图集。图片的链接就包含在每个图集中。
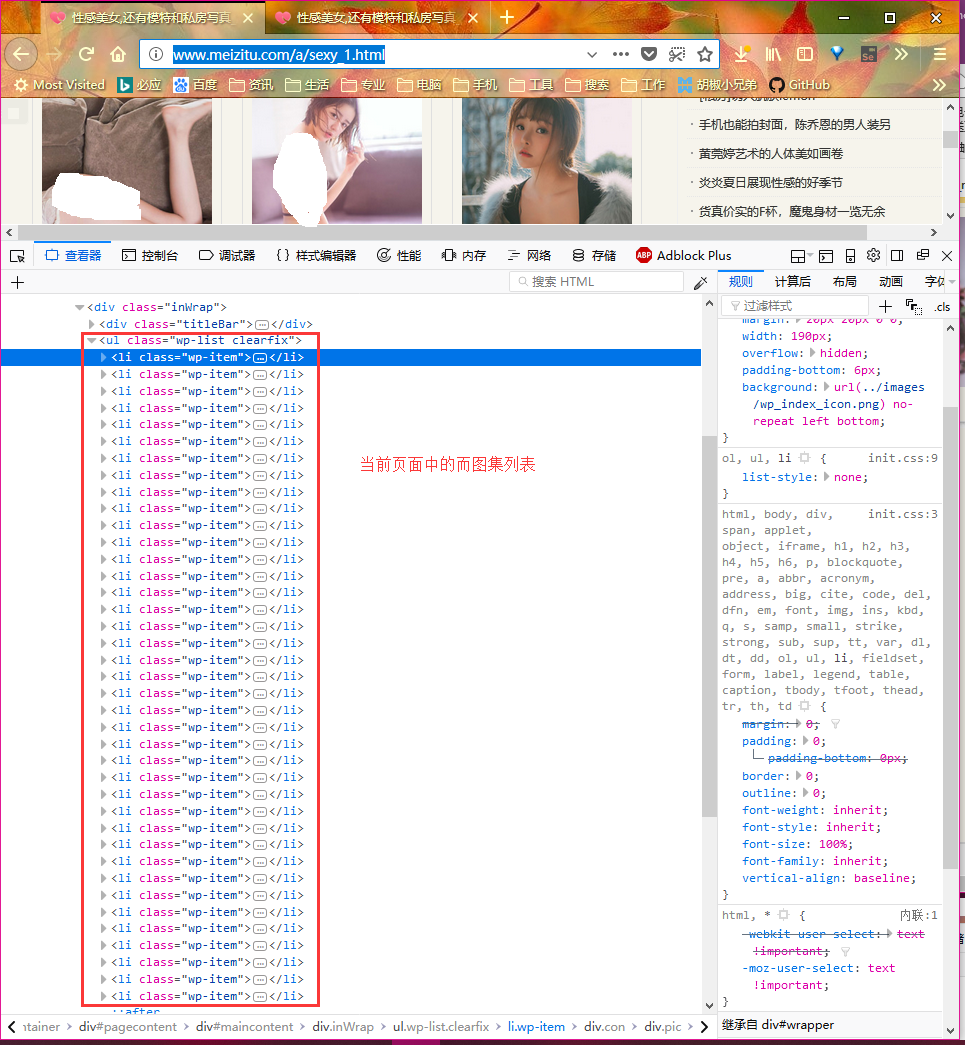
在页面上单击右键,选择 审查元素按键,或直接按 F12 进入调试模式。页面结构如下:
图集详情页面
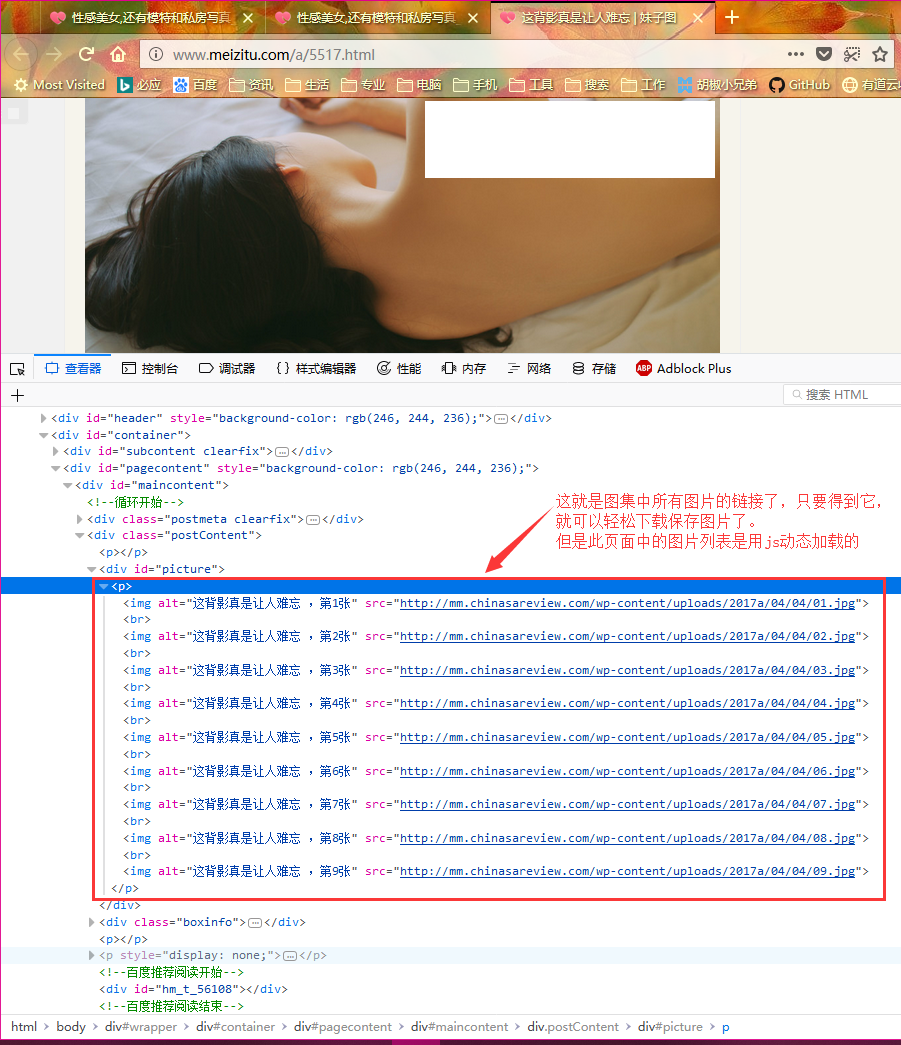
点进任意一个图集中,进入调试模式,可以看出页面结构如下:
源码详解
从前面的页面分析中可以看出,这个网站的页面结构其实很简单,我们只需要依次打开第1到第33个页面,得到每个页面的html源码,然后从html源码中提取出每个页面上包含的图集的链接列表(共33个),然后再依次打开第1到第33个图集详情页面,但是图集详情页面中的图片列表是用js动态加载的,我们需要使用selenium加载这个动态页面,等该页面加载完毕之后再得到该页面的html源码,然后从图集详情页面中提取出每张图片的链接,最后再依次下载每张图片保存即可。
整个流程其实并不复杂。
使用requests下载静态html页面
该函数用于下载图集列表页面,这个页面是静态的,可以直接通过 requests.get(url) 函数抓取。但是有一点需要注意,为了把我们的爬虫伪装成正常的浏览器请求,避免我们的爬虫被服务器禁止,我们需要给 requests 添加http请求头,其中包含伪造的 User-Agent 浏览器标识
def download_page_html(url):
phtml = None
try:
requests_header["User-Agent"] = random.choice(user_agent_list) # 选择一个随机的User-Agent
# print(requests_header)
page = requests.get(url=url, headers=requests_header) # 请求指定的页面
# print(page.encoding)
page.encoding = "gb2312" # 转换页面的编码为gb2312(避免中文乱码)
phtml = page.text # 提取请求结果中包含的html文本
# print("requests success")
page.close() # 关闭requests请求
except requests.exceptions.RequestException as e:
print("requests error:", e)
phtml = None
finally:
return phtml
下载指定链接的图片文件
该函数用于提取出图片链接之后下载图片,图片保存在以图集标题命名的文件夹中
def download_picture(url, dir):
try:
picdir = "{0}/{1}".format(PICTURE_PATH, dir) # 构造图片保存路径
# print(picdir)
if os.path.exists(picdir) != True:
os.makedirs(picdir) # 如果指定的文件夹不存在就递归创建
pic_name = url.split("/")[-1] # 用图片链接中最后一个/后面的部分作为保存的图片名
pic_full_name = "{0}/{1}".format(picdir, pic_name)
# print("save picture to :", pic_full_name)
requests_header["User-Agent"] = random.choice(user_agent_list) # 选择一个随机的User-Agent
response = requests.get(url, headers=requests_header) # 获取的文本实际上是图片的二进制文本
imgdata = response.content # 将他拷贝到本地文件 w 写 b 二进制 wb代表写入二进制文本
if len(imgdata) > (5*1024): # 只保存大于5k的图片
with open(pic_full_name, 'wb') as f:
f.write(imgdata) # 把图片数据写入文件。with语句会自动关闭f
print("save picture to :", pic_full_name)
else:
print("picture size too small")
response.close()
except:
print("download piccture {0} error".format(url))
获取所有需要爬取的页面数
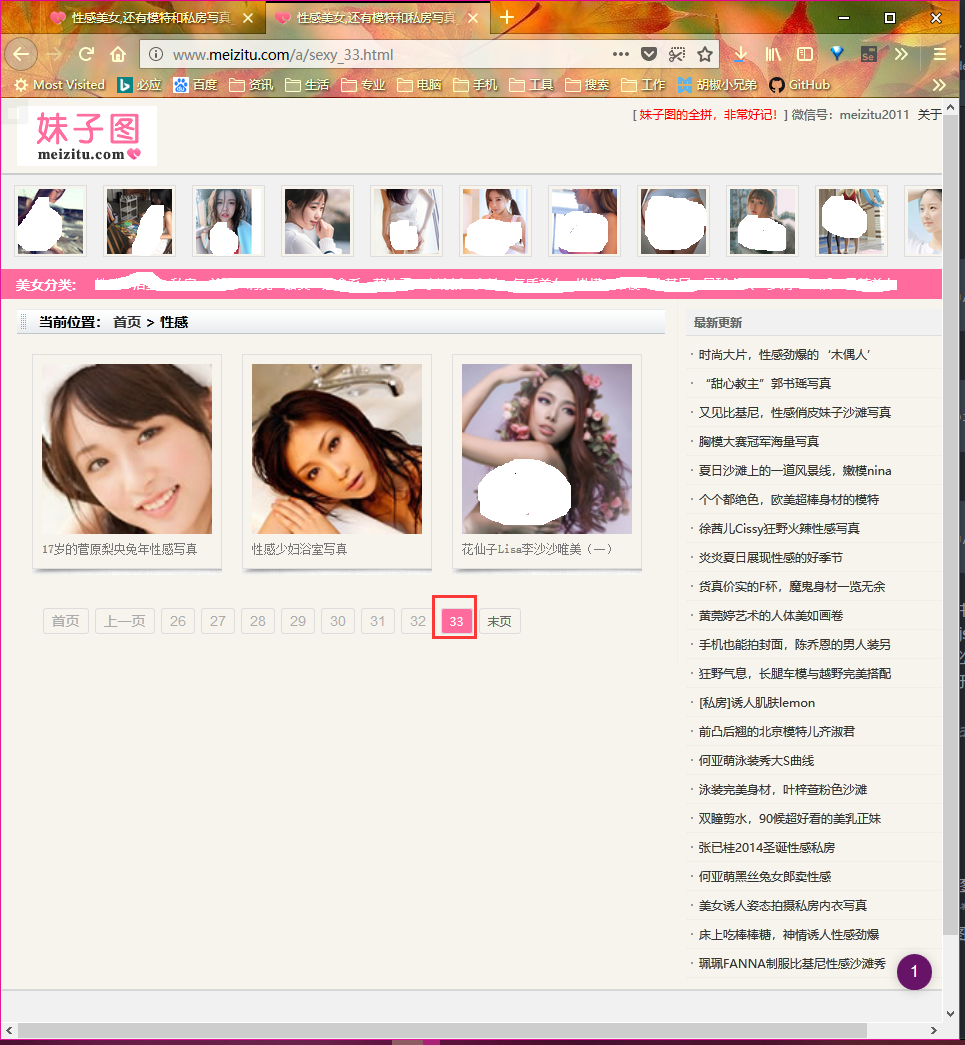
我们刚才已经分析过了,实际上只有33个需要处理的页面,但是以后网站肯定会更新,为了兼容性,我们并不准备写死,而是从html页面中提并分析出待处理的页面数。在选择页面底部的导航栏中有一个 末页 按钮,其href属性中包含了一个数字,这个数字就是页面的数目(也是页面的序号)。
def get_page_list_num(tree):
page_list_num = 0
try:
gotolast = tree.xpath("/html/body/div[1]/div[2]/div[2]/div[1]/div[2]/div/ul/li[18]/a/@href")[0] # sexy_33.html
# print(gotolast)
gotolast = str(gotolast)
# print(gotolast)
gotolast = re.sub(r"\D", "", gotolast) # 把非数字字符串替换为空
page_list_num = int(gotolast) # 转化为整数
print("max_page_number:", page_list_num)
except:
print("get page number error")
page_list_num = 0
finally:
return page_list_num
xpath选择器
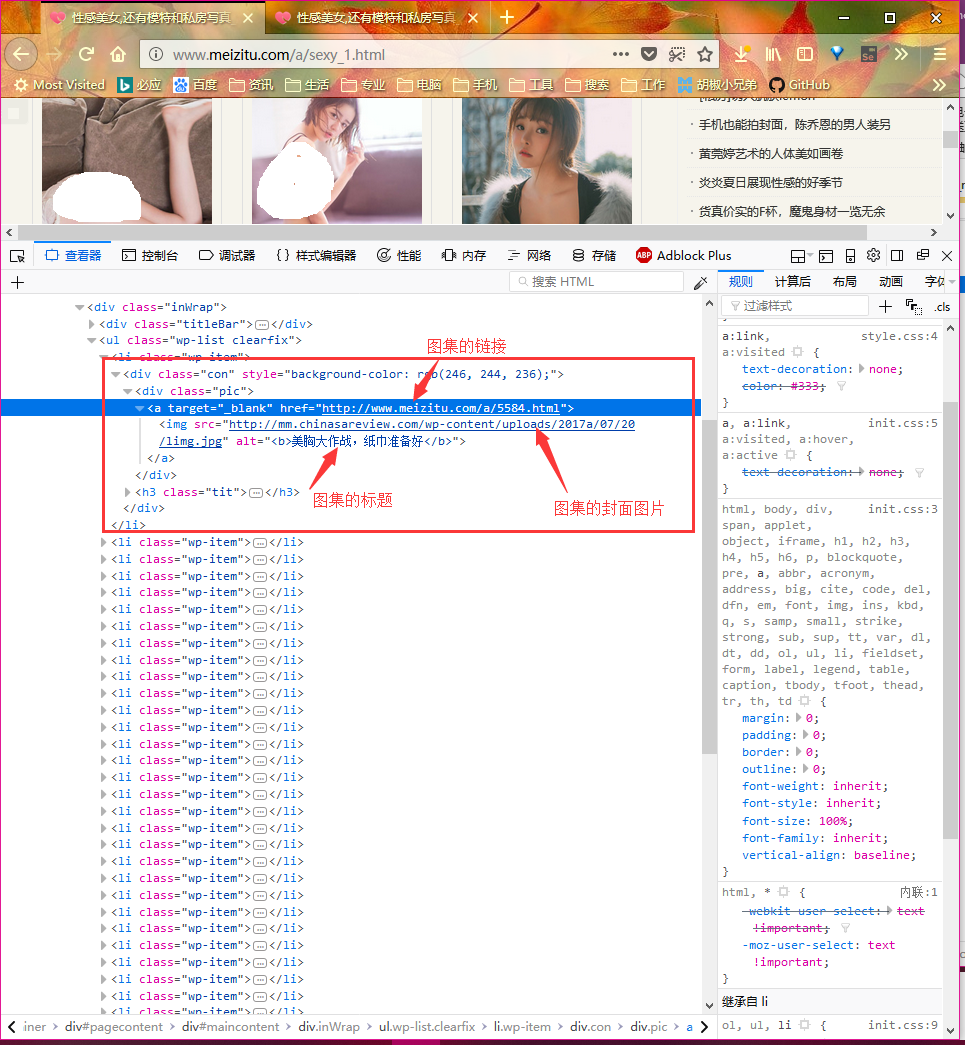
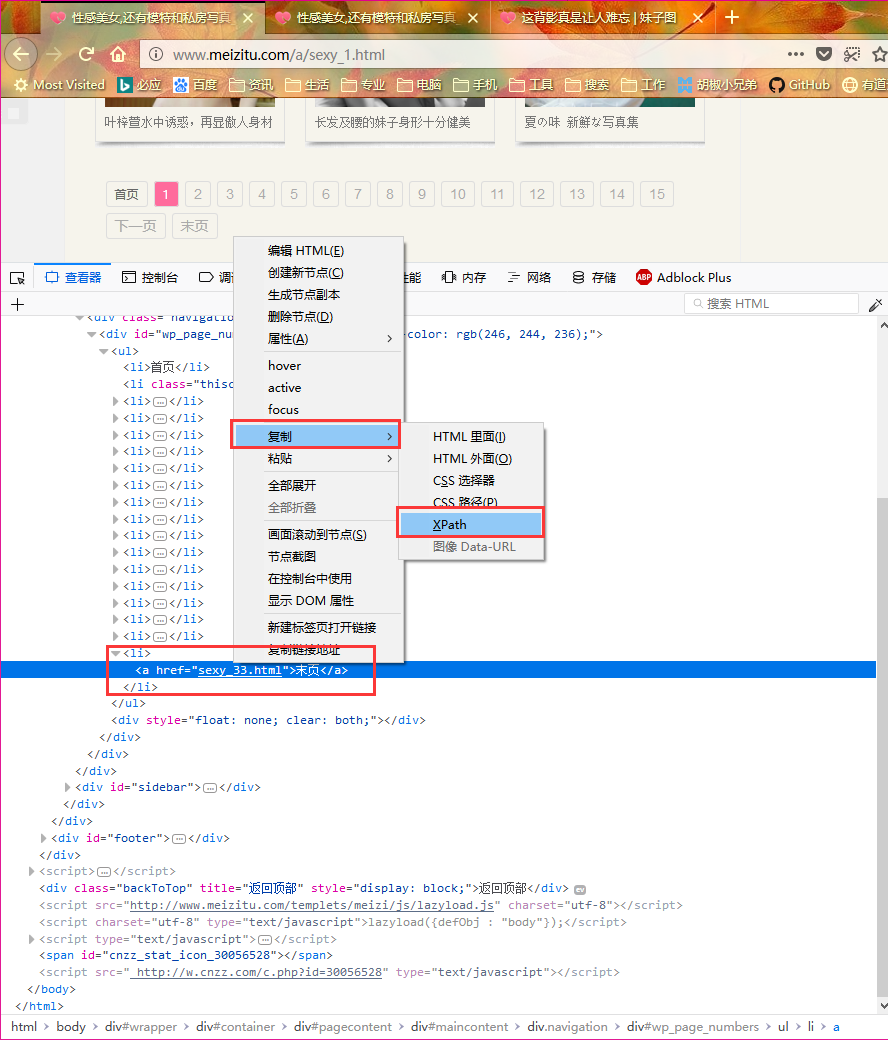
其实要在复杂的html文件中定位出我们需要的元素并不容易,但是一般浏览器都为我们提供了这一功能,比如我所使用的firefox浏览器就自带了这一功能,选中所需要的元素,然后在右键复制菜单中可以看到 复制Xpath的选项,使用它可以帮助我们快速定位我们需要的元素。下文所有的xpath都是使用这种方式得到的。如下图:
获取页面中的图片集列表
def get_pagealbum_list(tree): # 获取页面中的图片集列表
pagealbum_list = []
pagealbum_list = tree.xpath(
"/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/ul/li/div/div/a/@href")
return pagealbum_list
获取图集的标题和图集中的图片链接
这里同样使用的firefox的xpath工具定位到我们需要的元素的,然后通过lxml库的xpath方法从html页面中提取出我们想要的内容
def get_albumphoto_list(tree): # 获取图集中的图片列表
albumphoto_list = []
albumphoto_list = tree.xpath(
"/html/body/div[2]/div[2]/div[2]/div[1]/div[2]/div[1]/p/img/@src")
return albumphoto_list
def get_albumphoto_title(tree): # 获取图集中的标题
albumphoto_title = None
albumphoto_title = tree.xpath(
"/html/body/div[2]/div[2]/div[2]/div[1]/div[1]/div[1]/h2/a/text()")[0]
# print(albumphoto_title)
return albumphoto_title
加载和渲染动态网页
由于图集详情页中的图片列表是通过js代码动态渲染得到的,所以如果直接通过requests请求这个页面会得到一个只包含js代码的html,里面并没有我们需要的图片链接,因为requests请求不能执行js代码,所以没法加载出图片。我们这里需要使用selenium配合firefox浏览器来加载和渲染这个动态页面,等待渲染完成后再获取html源码,这时html中包含了图片链接
def web_driver_init():
global web_driver
if web_driver == None:
options = Options()
options.add_argument('-headless') # 无头参数
# 配了环境变量第一个参数就可以省了,不然传绝对路径
web_driver = Firefox(firefox_options=options)
web_driver.implicitly_wait(20)
def web_driver_page(url):
htmlpage = None
try:
web_driver.get(url)
htmlpage = web_driver.page_source
except:
print("get webpage {0} error".format(url))
finally:
return htmlpage
def web_driver_exit():
if web_driver != None:
web_driver.close()
爬虫处理逻辑meizitu_webspider
def meizitu_webspider():
global page_list_num
global page_list_idx
global requests_url
global webspider_sleep
print("requests_url :", requests_url)
page_html_list = download_page_html(requests_url) # 下载当前页面
if(page_html_list != None):
# print(page_html_list)
tree = lxml.html.fromstring(page_html_list)
if page_list_num == 0: # 计算当前共有多少个页面需要处理
page_list_num = get_page_list_num(tree)
pagealbum_list = get_pagealbum_list(tree) # 获取当前页面中图集列表
# print(pagealbum_list)
for lst in pagealbum_list: # 以此遍历当前页面中的每个图集
print("album_list:", lst)
# 图集使用的js异步加载图片,所以这里要用selenium加载动态页面
albumphoto_page = web_driver_page(lst)
# print(albumphoto_page)
if albumphoto_page != None:
tree0 = lxml.html.fromstring(albumphoto_page)
albumphoto_title = get_albumphoto_title(tree0) # 获取图集标题
print("Title:", albumphoto_title)
albumphoto_list = get_albumphoto_list(tree0) # 获取图集中的图片列表
for plst in albumphoto_list:
print("imgsrc:", plst)
download_picture(plst, albumphoto_title) # 下载图片
webspider_sleep = random.randint(1, 5) # 延时一个随机值,避免被服务器反爬
print("waiting {0} seconds".format(webspider_sleep))
time.sleep(webspider_sleep)
if page_list_idx < page_list_num: # 递归处理下一个页面
page_list_idx = page_list_idx + 1
requests_url = REQUEST_URL1.format(page_list_idx)
meizitu_webspider()
else:
return 0
运行爬虫
if __name__ == "__main__":
web_driver_init() # 初始化selenium
meizitu_webspider()
web_driver_exit() # 退出selenium
程序运行截图
项目文件截图
使用Python爬虫爬取网络美女图片
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
使用Python爬虫爬取网络美女图片的更多相关文章
- python爬虫——爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需 ...
- Python爬虫 爬取Web页面图片
从网页页面上批量下载jpg格式图片,并按照数字递增命名保存到指定的文件夹 Web地址:http://news.weather.com.cn/2017/12/2812347.shtml 打开网页,点击F ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
随机推荐
- Codeforces 555 C. Case of Chocolate
\(>Codeforces \space 555 C. Case of Chocolate<\) 题目大意 : 有一块 \(n \times n\) 的倒三角的巧克力,有一个人要吃 \(q ...
- 全网第二好懂的FFT(快速傅里叶变换)
声明:本FFT是针对OI的.专业人员请出门左拐. Ⅰ前言 很久以前,我打算学习FFT. 然而,算法导论讲的很详细,却看不懂.网上博客更别说了,什么频率之类的都来了.我暗自下了决心:写一篇人看得懂的FF ...
- Gym - 101620I Intrinsic Interval
题面在这里! 首先一个非常重要的性质是,两个好的区间的交依然是好的区间. 有了这个性质,我们只要找到包含某个区间的右端点最小的好区间,然后就是这个区间的答案拉. 至于找右端点最小的好区间就是一个扫描线 ...
- 【枚举】【尺取法】hdu6103 Kirinriki
两个等长字符串A,B的距离被定义为 给你一个字符串,问你对于所有长度相等的不相交子串对,其距离不超过m的前提下,最长的长度是多少. 枚举对称轴,两侧先贪心地扩展到最长,超过m之后,再缩短靠近对称轴的端 ...
- SOCKET类型定义及应用
读代码时看到此处,摘记下来. 流套接字(SOCK_STREAM):流套接字用于提供面向连接.可靠的数据传输服务.该服务将保证数据能够实现无差错.无重复发送,并按顺序接收.流套接字之所以能够实现可靠的数 ...
- cocos2d-x解析xml时的Bug
cocos2d-x中使用tinyxml解析xml配置.如下: tinyxml2::XMLDocument doc; if (tinyxml2::XML_SUCCESS != doc.LoadFile( ...
- MYSQL复习笔记11-排序分组
Date: 20140223Auth: Jin 一.排序 order by作用:对查询结果进行排序1.基本语法SELECT column_name(s) FROM table_name ORDER B ...
- FFT算法的完整DSP实现
傅里叶变换或者FFT的理论参考: [1] http://www.dspguide.com/ch12/2.htm The Scientist and Engineer's Guide to Digita ...
- 定时任务框架-quartz
依赖 <!-- 定时任务jar --> <dependency> <groupId>org.quartz-scheduler</groupId> < ...
- REDIS数据备份集群部署和双集群同步工具redis-migrate-tool
REDIS 版本 < 4.0 笔者用的是 v=3.0.7 REDIS集群创建镜像:registry.cn-shenzhen.aliyuncs.com/cp_m/redis-trib:0.1.3 ...