ELK分布式日志收集搭建和使用
大型系统分布式日志采集系统ELK
全框架 SpringBootSecurity
1、传统系统日志收集的问题
2、Logstash操作工作原理
3、分布式日志收集ELK原理
4、Elasticsearch+Logstash+Kiabana整合
5、Logstash将数据推送到ES
6、Kibana图形界面展示ES日志信息
搭建环境虚拟机要求:2G以上内存
1.传统问题:
传统系统日志收集的问题
在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下。
通常,日志被分散在储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
命令方式:
tail -n 300 myes.log | grep 'node-1' ##搜索某个日志在哪里
tail -100f myes.log
传统:
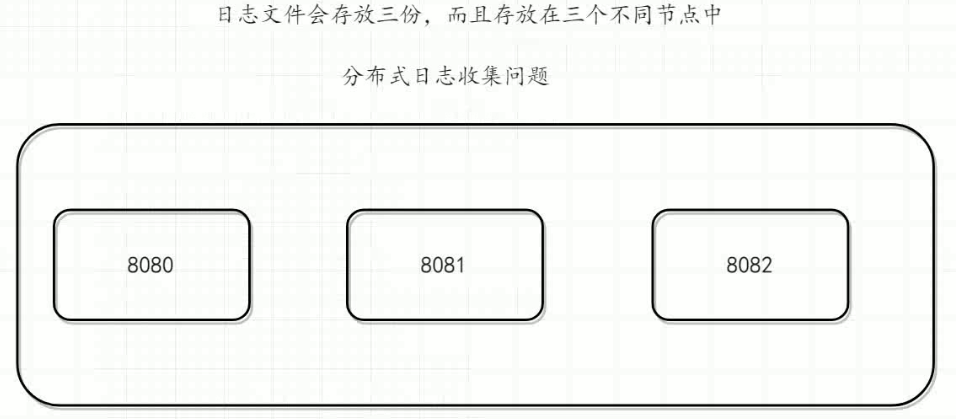
分布式日志收集问题 解决传统 日志分布在每台节点的问题 分散的。在搜索日志时候非常繁琐 (可以存放在redis哦,可以定时,但是不要存放在数据库中,不需要持久啊)
ELK分布式日志收集系统介绍
ElasticSearch是一个基于Lucene的开源分布式搜索服务器。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
ELK分布式日志收集系统原理:
在每个服务器节点安装Logstash插件,把节点的本底文件日志读取到Logstash中去,以每天的方式创建索引。然后再把本底的日志文件进行格式化转成json格式,写入到ES服务器集群中去。

小结:
ELK分布式日志收集原理
1、每台服务器集群节点安装Logstash日志收集系统插件
2、每台服务器节点将日志输入到Logstash中
3、Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearch中
4、浏览器使用安装Kibana查询日志信息
关于Logstash介绍
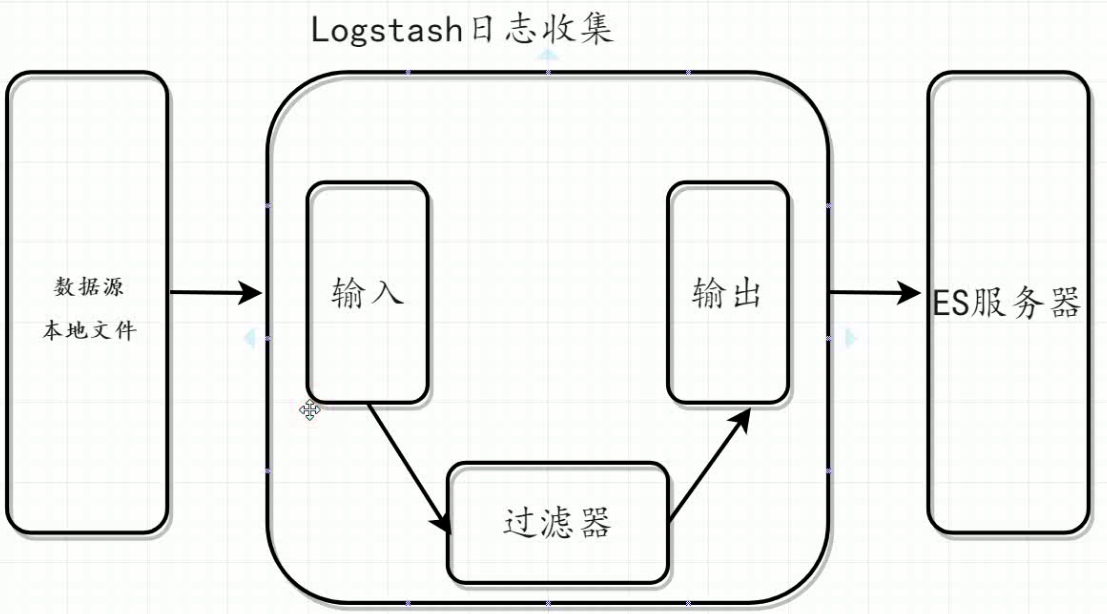
Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
核心流程:Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
Logstash环境安装
1、上传logstash安装包(资料)
2、解压tar –zxvf logstash-6.4.3.tar.gz
3、在config目录下放入mayikt01.conf 读入并且读出日志信息
ELK搭建:
1、安装ElasticSearch
2、安装Logstash
3、 安装Kibana
(1,3:https://www.cnblogs.com/toov5/p/10295790.html)
实际项目中 ELK+Kafka
上传安装包解压,本文使用的日志文件是 es自己产生的日志文件:
/home/elasticsearch/elasticsearch-6.4.3/logs 下面的日志
查询日志的Linux指令: tail -n 300 myes.log | grep 'node-1' ## 查询关键字‘node-1’的内容 前300行

实时搜索:tail -100f myes.log

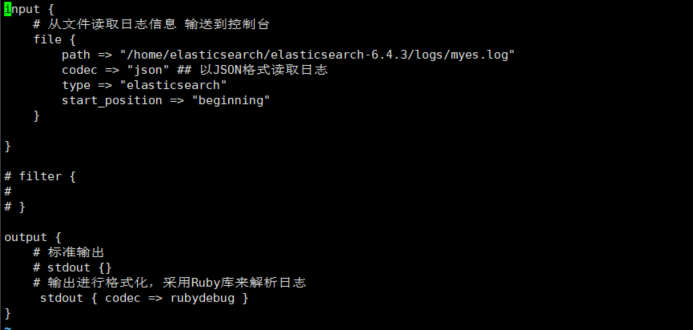
在:/home/elasticsearch/logstash-6.4.3/config 目录下创建Logstash的配置文件:
内容如下:
input {
# 从文件读取日志信息 输送到控制台 path要对应读取的目录
file {
path => "/home/elasticsearch/elasticsearch-6.4.3/logs/myes.log"
codec => "json" ## 以JSON格式读取日志
type => "elasticsearch"
start_position => "beginning"
} } # filter {
#
# } output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
}
如图: (当然可以配置多个 输入 多个输出)
保存
切换到bin目录下启动(指定启动文件): ./logstash -f ../config/toov501.conf
启动相当慢 小伙伴们要耐心等待哦
当前配置的形式是打印到窗口的方式: 启动后打印的日志非常漂亮~ JSON格式
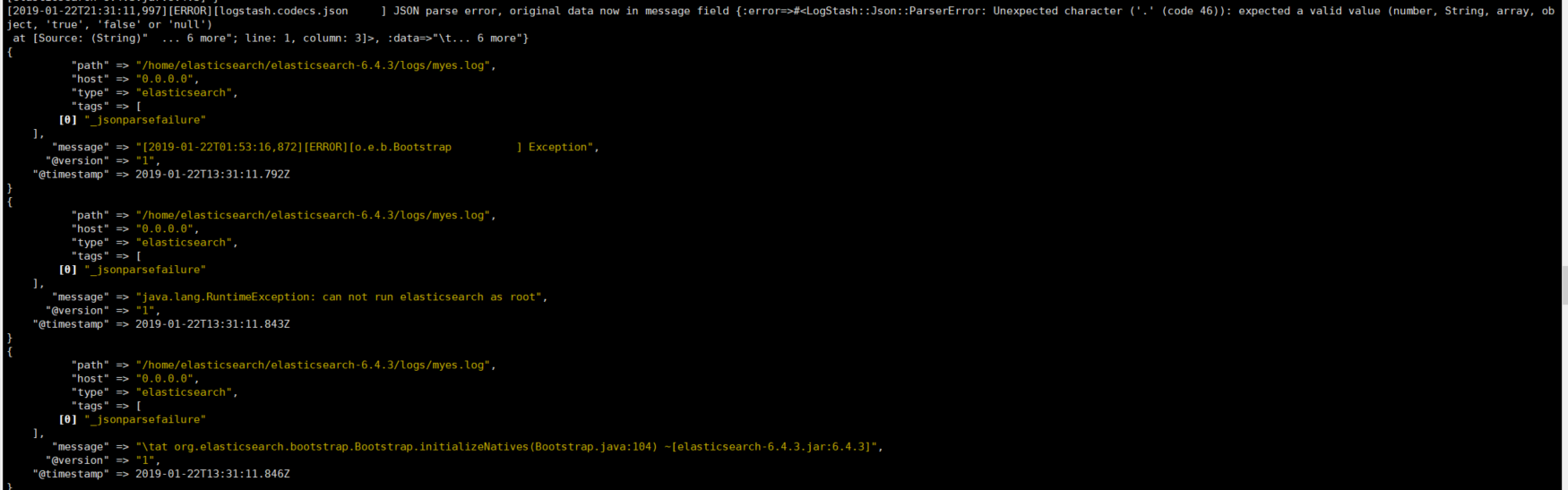
配置下日志的输出到ES中:
修改下 outoput 就OK了
output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.91.7:9200"]
index => "es-%{+YYYY.MM.dd}"
}
}
idex:索引! 根据每一天创建索引!!!! 默认doc!
注意如果你启动不成功,报错:
No sincedb_path set, generating one based on the "path" setting {:sincedb_pa
解决方案:
https://stackoverflow.com/questions/32001752/logstash-fails-to-read-file-no-sincedb-path-set-generating-one-based-on-the-fi
Maybe you can do as follows:
change your input config like this:
input {
file {
path =>[ "/usr/share/logstash-1.5.3/test.txt"]
start_position => beginning
sincedb_path => "/opt/logstash/sincedb-access"
}
}
then touch a file for sincedb_path:
touch /opt/logstash/sincedb-access
chown logstash:logstash /opt/logstash/sincedb-access
the most important thing is:
ln -s /lib/x86_64-linux-gnu/libcrypt.so.1 /usr/lib/x86_64-linux-gnu/libcrypt.so
You may lost libcrypt.so file.
我们使用 kibana查询
http://192.168.91.7:5601/app/kibana#/dev_tools/console?_g=()
GET /es-2019.01.22

查看:

可以进行各种查询:

ES查询效率快 倒排索引!
可以用图形化界面,大家可以自己玩玩

ELK分布式日志收集搭建和使用的更多相关文章
- 传统ELK分布式日志收集的缺点?
传统ELK图示: 单纯使用ElK实现分布式日志收集缺点? 1.logstash太多了,扩展不好. 如上图这种形式就是一个 tomcat 对应一个 logstash,新增一个节点就得同样的拥有 logs ...
- SpringBoot+kafka+ELK分布式日志收集
一.背景 随着业务复杂度的提升以及微服务的兴起,传统单一项目会被按照业务规则进行垂直拆分,另外为了防止单点故障我们也会将重要的服务模块进行集群部署,通过负载均衡进行服务的调用.那么随着节点的增多,各个 ...
- .NetCore快速搭建ELK分布式日志中心
懒人必备:.NetCore快速搭建ELK分布式日志中心 该篇内容由个人博客点击跳转同步更新!转载请注明出处! 前言 ELK是什么 它是一个分布式日志解决方案,是Logstash.Elastaics ...
- .NetCore 分布式日志收集Exceptionless 在Windows下本地安装部署及应用实例
自己安装时候遇到很多问题,接下来把这些问题写出来希望对大家有所帮助 搭建环境: 1.下载安装 java 8 SDK (不要安装最新的10.0) 并配置好环境变量(环境变量的配置就不做介绍了) 2.下载 ...
- 分布式日志收集收集系统:Flume(转)
Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力.Fl ...
- 分布式日志收集框架Flume
分布式日志收集框架Flume 1.业务现状分析 WebServer/ApplicationServer分散在各个机器上 想在大数据平台Hadoop进行统计分析 日志如何收集到Hadoop平台上 解决方 ...
- 分布式日志收集之Logstash 笔记(一)
(一)logstash是什么? logstash是一种分布式日志收集框架,开发语言是JRuby,当然是为了与Java平台对接,不过与Ruby语法兼容良好,非常简洁强大,经常与ElasticSearch ...
- StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程)
@ 目录 StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程) 一.下载ELK的安装包上传并解压 1.Elasticsearch下载 2.Logstash下载 3.Kibana ...
- 分布式日志收集系统Apache Flume的设计详细介绍
问题导读: 1.Flume传输的数据的基本单位是是什么? 2.Event是什么,流向是怎么样的? 3.Source:完成对日志数据的收集,分成什么打入Channel中? 4.Channel的作用是什么 ...
随机推荐
- iOS从当前隐藏导航界面push到下一个显示导航界面出现闪一下的问题
本文转载至 http://blog.csdn.net/woaifen3344/article/details/41284319 navios 如果有朋友遇到从当前隐藏导航界面push到下一个显示导航界 ...
- 61、常规控件(4)TabLayout-便捷实现标签
<android.support.design.widget.TabLayout android:id="@+id/tabs" android:layout_width=&q ...
- 5秒后跳转到另一个页面的js代码
今天看视频学习时学习了一种新技术,即平时我们在一个页面点击“提交”或“确认”会自动跳转到一个页面. 在网上搜了一下,关于这个技术处理有多种方法,我只记下我在视频里学到的三种: 1.用一个respons ...
- group_concat 多对多关联, 统计分组数据, 结果拼接到一个字段
统计用户所有的角色, 结果: 1 张三 普通用户,管理员,XXX 2 李四 普通用户, XXX select ur.user_id,u.login_name,GROUP_CONCAT ...
- 转义字符的理解(JAVA、字符串和正则表达式)
一.原理总结: 要理解转义,首先要从正则表达式说起. 在正则表达式中:*和\是特殊字符:为了匹配这两个字符本身,正则表达式中需要写为\*和\\ 在Java中,只能用字符串表示正则表达式,所以需要把\* ...
- 【IDEA】启动项目报错:3 字节的 UTF-8 序列的字节 3 无效
一.报错和原因: 项目起服务出错.具体报错就不贴了,报错主要是"3 字节的 UTF-8 序列的字节 3 无效". 分析:主要就是项目编码问题,IDEA中估计就是配置不对,没必要纠结 ...
- datagridview数据导出到excel
/// <summary> /// 导出Excel /// </summary> /// <param name="mydgv">控件 Data ...
- <2014 08 28> 大学学习小结
大一:哲学.物理(科普).瞎玩 大二:机械.力学.继续哲学 大三:电子电路.计算机.编程 大四:毕业项目(机器人等) 研一:物理.数学(常熟) 研二:AGV.TUM实习 研三:写论文.实习程序员.申请 ...
- 转!!mysql 查询条件不区分大小写问题
做用户登录模块时,输入用户名(大/小写)和密码 ,mysql都能查出来.-- mysql查询不区分大小写. 转自 http://blog.csdn.net/qishuo_java/article/de ...
- 转!!SpringMVC与Struts2区别与比较总结
1.Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上Spr ...