【Redis】- 缓存击穿
什么是缓存击穿
在谈论缓存击穿之前,我们先来回忆下从缓存中加载数据的逻辑,如下图所示
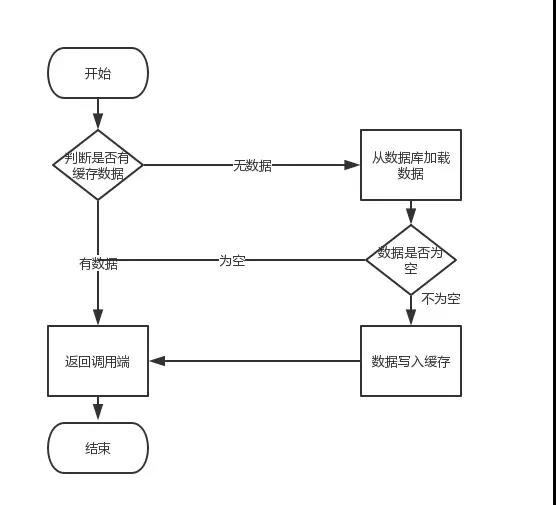
因此,如果黑客每次故意查询一个在缓存内必然不存在的数据,导致每次请求都要去存储层去查询,这样缓存就失去了意义。如果在大流量下数据库可能挂掉。这就是缓存击穿。
场景如下图所示:
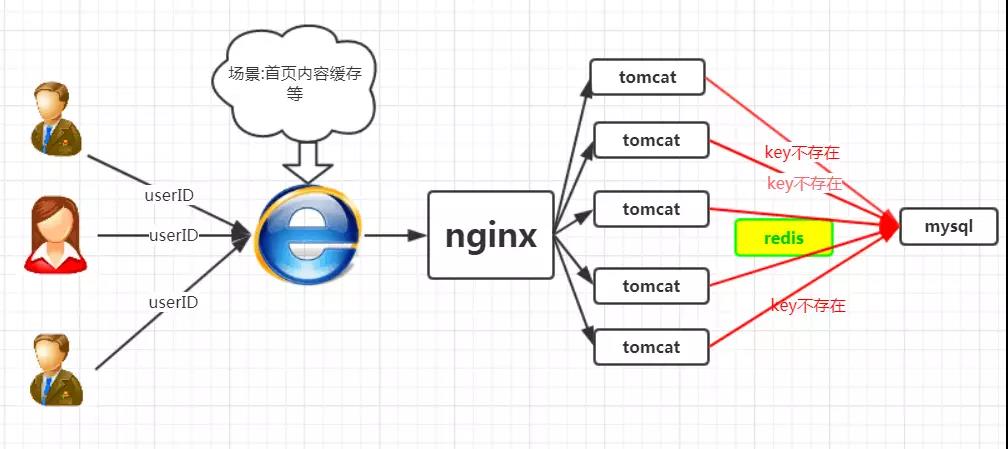
我们正常人在登录首页的时候,都是根据userID来命中数据,然而黑客的目的是破坏你的系统,黑客可以随机生成一堆userID,然后将这些请求怼到你的服务器上,这些请求在缓存中不存在,就会穿过缓存,直接怼到数据库上,从而造成数据库连接异常。
解决方案
在这里我们给出三套解决方案,大家根据项目中的实际情况,选择使用.
讲下述三种方案前,我们先回忆下redis的setnx方法
SETNX key value
将 key 的值设为 value ,当且仅当 key 不存在。
若给定的 key 已经存在,则 SETNX 不做任何动作。
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
可用版本:>= 1.0.0
时间复杂度: O(1)
返回值: 设置成功,返回 1。设置失败,返回 0 。
效果如下
redis> EXISTS job # job 不存在
(integer) 0
redis> SETNX job "programmer" # job 设置成功
(integer) 1
redis> SETNX job "code-farmer" # 尝试覆盖 job ,失败
(integer) 0
redis> GET job # 没有被覆盖
"programmer"
1、使用互斥锁
该方法是比较普遍的做法,即,在根据key获得的value值为空时,先锁上,再从数据库加载,加载完毕,释放锁。若其他线程发现获取锁失败,则睡眠50ms后重试。
至于锁的类型,单机环境用并发包的Lock类型就行,集群环境则使用分布式锁( redis的setnx)
集群环境的redis的代码如下所示:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//其他线程休息50毫秒后重试
Thread.sleep(50);
get(key);
}
}
}
优点
思路简单
保证一致性
缺点
代码复杂度增大
存在死锁的风险
2、异步构建缓存
在这种方案下,构建缓存采取异步策略,会从线程池中取线程来异步构建缓存,从而不会让所有的请求直接怼到数据库上。该方案redis自己维护一个timeout,当timeout小于System.currentTimeMillis()时,则进行缓存更新,否则直接返回value值。
集群环境的redis代码如下所示:
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 异步更新后台异常执行
threadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
}
优点
性价最佳,用户无需等待
缺点
无法保证缓存一致性
3、布隆过滤器
1、原理
布隆过滤器的巨大用处就是,能够迅速判断一个元素是否在一个集合中。因此他有如下三个使用场景:
网页爬虫对URL的去重,避免爬取相同的URL地址
反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)
缓存击穿,将已存在的缓存放到布隆过滤器中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
OK,接下来我们来谈谈布隆过滤器的原理
其内部维护一个全为0的bit数组,需要说明的是,布隆过滤器有一个误判率的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。
假设,根据误判率,我们生成一个10位的bit数组,以及2个hash函数((f_1,f_2)),如下图所示(生成的数组的位数和hash函数的数量,我们不用去关心是如何生成的,有数学论文进行过专业的证明)。

假设输入集合为((N_1,N_2)),经过计算(f_1(N_1))得到的数值得为2,(f_2(N_1))得到的数值为5,则将数组下标为2和下表为5的位置置为1,如下图所示
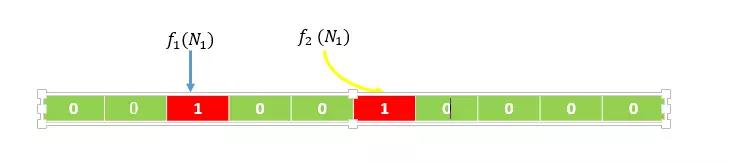
同理,经过计算(f_1(N_2))得到的数值得为3,(f_2(N_2))得到的数值为6,则将数组下标为3和下表为6的位置置为1,如下图所示

这个时候,我们有第三个数(N_3),我们判断(N_3)在不在集合((N_1,N_2))中,就进行(f_1(N_3),f_2(N_3))的计算
若值恰巧都位于上图的红色位置中,我们则认为,(N_3)在集合((N_1,N_2))中
若值有一个不位于上图的红色位置中,我们则认为,(N_3)不在集合((N_1,N_2))中
以上就是布隆过滤器的计算原理,下面我们进行性能测试,
2、性能测试
代码如下:
(1)新建一个maven工程,引入guava包
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
</dependencies>
(2)测试一个元素是否属于一个百万元素集合所需耗时
package bloomfilter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class Test {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter =BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 获取开始时间
//判断这一百万个数中是否包含29999这个数
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 获取结束时间
System.out.println("程序运行时间: " + (endTime - startTime) + "纳秒");
}
}
输出如下所示
命中了
程序运行时间: 219386纳秒
也就是说,判断一个数是否属于一个百万级别的集合,只要0.219ms就可以完成,性能极佳。
(3)误判率的一些概念
首先,我们先不对误判率做显示的设置,进行一个测试,代码如下所示
package bloomfilter;
import java.util.ArrayList;
import java.util.List;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class Test {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter =BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
//故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
输出结果如下
误判对数量:330
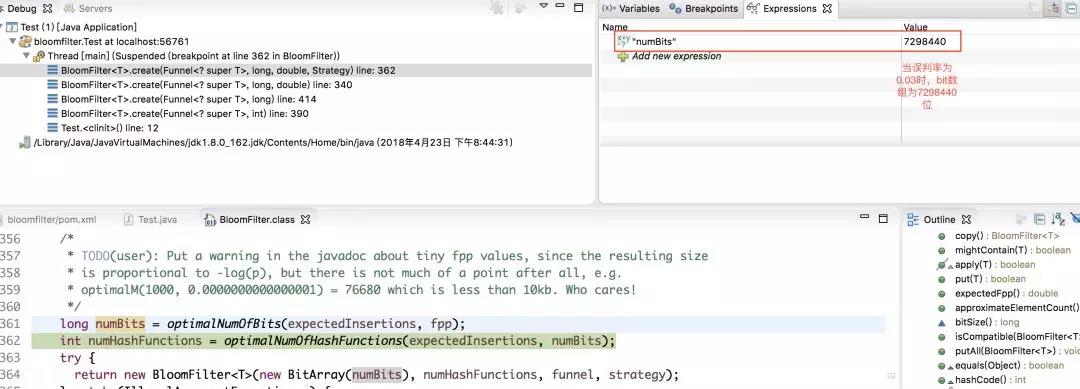
如果上述代码所示,我们故意取10000个不在过滤器里的值,却还有330个被认为在过滤器里,这说明了误判率为0.03.即,在不做任何设置的情况下,默认的误判率为0.03。
下面上源码来证明:
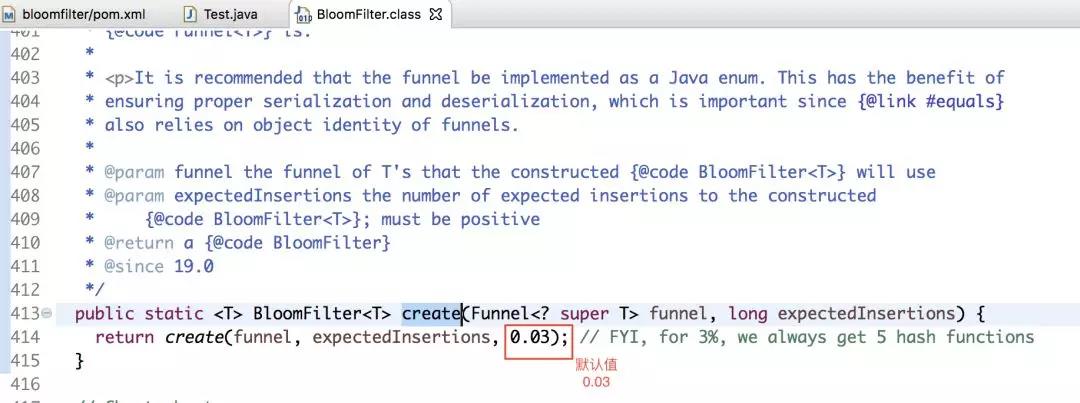
接下来我们来看一下,误判率为0.03时,底层维护的bit数组的长度如下图所示
将bloomfilter的构造方法改为
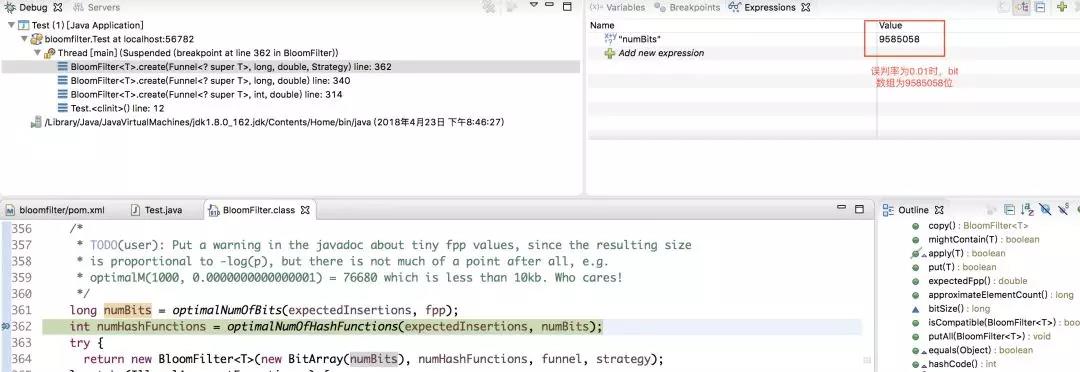
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,0.01);
即,此时误判率为0.01。在这种情况下,底层维护的bit数组的长度如下图所示
由此可见,误判率越低,则底层维护的数组越长,占用空间越大。因此,误判率实际取值,根据服务器所能够承受的负载来决定,不是拍脑袋瞎想的。
3、实际使用
redis伪代码如下所示
String get(String key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){
return null;
}else{
value = db.get(key);
redis.set(key, value);
}
}
return value;
}
优点
思路简单
保证一致性
性能强
缺点
代码复杂度增大
需要另外维护一个集合来存放缓存的Key
布隆过滤器不支持删值操作
转自:https://blog.csdn.net/hjm4702192/article/details/80518952
【Redis】- 缓存击穿的更多相关文章
- redis 缓存击穿 看一篇成高手系列3
什么是缓存击穿 在谈论缓存击穿之前,我们先来回忆下从缓存中加载数据的逻辑,如下图所示 因此,如果黑客每次故意查询一个在缓存内必然不存在的数据,导致每次请求都要去存储层去查询,这样缓存就失去了意义.如果 ...
- redis缓存击穿和缓存雪崩
工作中经常会用到redis来做缓存,以防止后台db挂掉.但是db数据一般都在10T以上,不可能把mysql中的数据全部放入redis中,所以一般是将一些热key放入redis中. 缓存击穿 一个请求先 ...
- Redis缓存击穿
缓存击穿 缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞. 比如在做 ...
- Redis缓存击穿、缓存穿透、缓存雪崩
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 上篇文章谈到了Redis分布式锁,实际上就是为了解释为什么做缓存采用Redis而不使用map/guava.缓存 ...
- 谈谈redis缓存击穿透和缓存击穿的区别,雪崩效应
面试经历 在很长的一段时间里,我以为缓存击穿和缓存穿透是一个东西,直到最近去腾讯面试,面试官问我缓存击穿和穿透的区别:我回答它俩是一样的,面试官马上抬起头用他那细长的单眼皮眼睛瞪着我说:"你 ...
- Redis 缓存击穿(失效)、缓存穿透、缓存雪崩怎么解决?
原始数据存储在 DB 中(如 MySQL.Hbase 等),但 DB 的读写性能低.延迟高. 比如 MySQL 在 4 核 8G 上的 TPS = 5000,QPS = 10000 左右,读写平均耗时 ...
- redis缓存击穿问题一种思路分享
思路每一个key都有一个附属key1,附属key1可以是key加特定前缀组成,key对应value为真正的缓存数据,附属key1对应的value不重要,可以是随便一个值,附属key1的作用主要是维护缓 ...
- redis缓存穿透,缓存击穿,缓存雪崩
概念解释 redis 缓存穿透 key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源.比如用一个不存在的用户id获取用户信息,不论缓存还是数据库 ...
- Redis缓存雪崩、缓存穿透、热点Key解决方案和分析
缓存穿透 缓存系统,按照KEY去查询VALUE,当KEY对应的VALUE一定不存在的时候并对KEY并发请求量很大的时候,就会对后端造成很大的压力. (查询一个必然不存在的数据.比如文章表,查询一个不存 ...
- redis缓存介绍以及常见问题浅析
# 没缓存的日子: 对于web来说,是用户量和访问量支持项目技术的更迭和前进.随着服务用户提升.可能会出现一下的一些状况: 页面并发量和访问量并不多,mysql足以支撑自己逻辑业务的发展.那么其实可以 ...
随机推荐
- consonant_摩擦音
consonant_摩擦音_[t∫].[dʒ].[tr].[dr].[ts].[dz] 破擦音:即有爆破音又有摩擦音. [t∫]:噘嘴,舌尖抵住上牙龈,舌头下切,用一瞬间的气流发出声音,不震动. ch ...
- python 基础练习题, 陆续添加中
判定用户输入数字是否为闰年 闰年的定义:能够被4整除的年份 #input是自定义输入内容的函数 year = input("请输入年份数字:") #xxx.isdigit方法是检测 ...
- U盘kali系统安装
正言: 起初先百度了一下U盘安装Kali的资料,有很多版本和方法,当然还是以百度经验为例开始操作https://jingyan.baidu.com/article/cdddd41ca1027e53 ...
- 插入排序,C语言实现
插入排序是稳定排序,时间复杂度最低为O(n),最高为O(n^2),平均为O(n^2). 插入排序是将数组分为两部分,一部分已经排好序,另一部分未排好序,每次从未排好序的部分取第一个元素插入到已经排好序 ...
- Java设计模式(6)——创建型模式之原型模式(Prototype)
一.概述 概念 // 引用自<Java与模式> UML图 第二种:登记式 二.实践 先导知识 对象的拷贝: 直接赋值:此时只是相当于a1,a2指向同一个对象,无论哪一个操作的都是同一个对象 ...
- 20145202马超《java》【课堂实验】P98测试
当时在加水印所以没来得及提交,然而我回宿舍第一时间就提交了,希望老师额能够看到
- C#实现窗口最小化到系统托盘
先添加notifyicon控件notifyIcon1 using System; using System.Collections.Generic; using System.ComponentMod ...
- spring源码-Aware-3.4
一.Aware接口,这个也是spring的拓展之一,为啥要单独拿出来讲呢,因为他相比于BeanFactoryPostProcessor,BeanPostProcessor的实用性更加高,并且在具体的业 ...
- 100万套PPT模板,包含全宇宙所有主题类型PPT,绕宇宙100圈,持续更新
100万套PPT模板,包含全宇宙所有主题类型PPT(全部免费,都是精品,没有一张垃圾不好看的PPT,任何一张PPT拿来套入自己的信息就可以立马使用),绕宇宙100圈,任意一个模板在某文库上都价不菲.强 ...
- lesson 23 one man's meat is another man's poison
lesson 23 one man's meat is another man's poison delicacy n. 美味:佳肴: delicious adj. 美味的:可口的 关于虚拟语气: I ...