Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找
Python爬虫教程-33-scrapy shell 的使用
- scrapy shell 的使用
- 条件:我们需要先在环境中,安装 scrapy 包,如果还没有安装,请参照:Python爬虫教程-30-Scrapy 爬虫框架介绍
- 为什么要使用 scrapy shell?
- 当我们需要爬取智联招聘,某一个岗位的信息的时候,如果我们当然不能简单的把整个页面的 HTML 都作为返回的结果吧,这时候我们需要提取数据,我们可以使用正则,但是呢使用正则由很容易出问题,也就需要我们不断地去调试,如果说对于一个较大的 Scrapy 项目去测试正则的结果是否正确,就过于麻烦了,这时候,我们要使用 scrapy shell 去调试,测试成功后,在拷贝到我们的项目中就可以了
- 怎么打开 scrapy shell?
- 1.打开【cmd】
- 2.进入需要的 Anaconda 环境
- 例如:
我的环境名为:learn
activate learn
- 3.使用命令进入 scrapy shell "需要访问的地址"
例如:
scrapy shell "http://baidu.com"
- 4.操作截图:
这里会出现一大堆,不用管,最后会有一个代码输入的地方:
这里就是我们写代码的地方
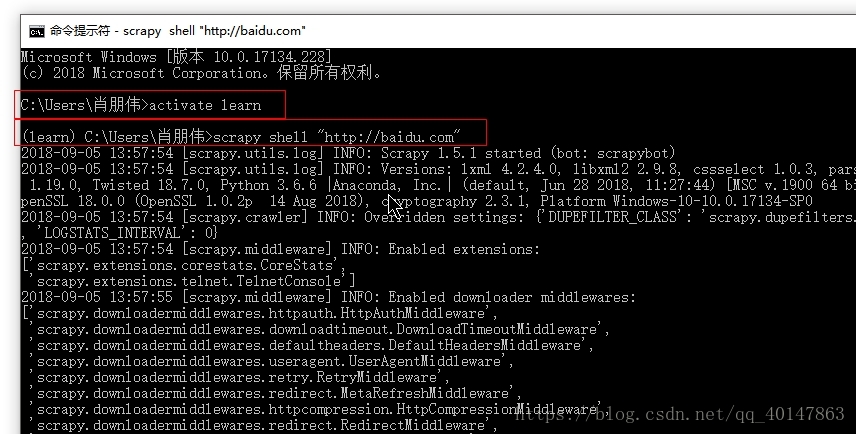
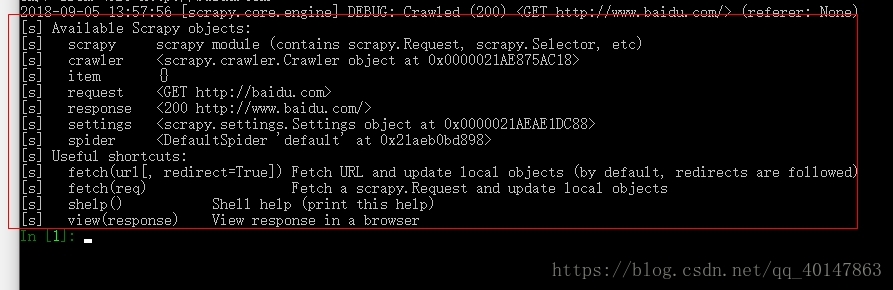
scrapy shell 的简单使用
- 1. response
- 执行命令之后,可以看到有很多 [s] 开头的东西,就是我们可以在下面代码输入框中使用的变量**
- 执行后,会自动将指定 url 的网页
- 下载完后,url 的内容保存在 response 的变量中
- response.body
- response.headers
- response.headers['Server']
- response.xpath() 使用 xpath
- response.css() 使用 css 语法选取内容
- 2.例如:我们使用:view(response):
- 截图:
- 结果就是调用浏览器,查看视图
- 截图:
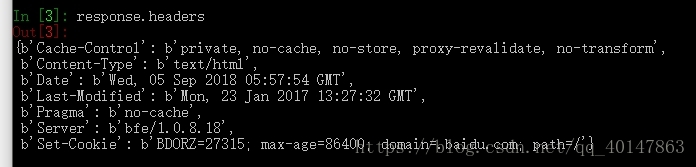
- 3.例如:我们想查看 headers 的内容:
- 使用:response.headers
- 截图:
- 4.一回车就执行了,怎样多行输入呢?
- 在 scrapy shell 中,我们只进行简单的多行输入,比如函数,for循环,更多的多个函数,特别多行的话,我们何尝不使用 Pycharm 呢,我们使用 scrapy shell 的目的就是简单执行,快速
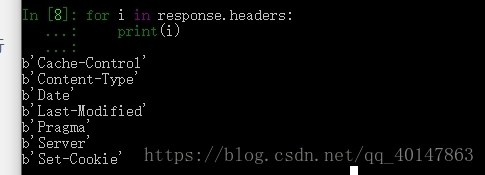
- 例如:for 循环打印 response.headers
- 截图:
- 这时候又有新的问题了,for 循环,可以多行了,但回车没法执行了
- 这时候使用的是:Ctrl + Enter 键执行
- 5.怎样输出属性的值呢?
- 例如:我们打印 response.headers 中的一个 Set-Cookie 项对于的值
- 截图:
- 6.selector
- 选择器,允许用户使用选择器来选择自己想要的内容
- response.selector.xpath:response.xpath 是 response.selector.xpath 的快捷方式
- response.selector.css:response.css 是 response.selector.css 的快捷方式
- selector.extract:把节点内容用 unicode 形式返回
- selector.re:允许用户通过正则选择内容


response.xpath 使用案例
- 1.使用 scrapy shell "http://baidu.com" 访问百度,得到response
- 2.目标:我们是想要找到这个页面的所有 div 头,并赋值给 divs
- 3.使用 len(divs) 查看共有多少个 div
- 4.我们输出下标为 0 的 div 头信息
- 操作截图:
- 5.这里只是头信息,想要获取 div 的内容代码
- 使用 divs[1].extract()
- 截图:


- 6.使用 xpath 精确查找
1.我们想找表格中的一个 a 标签
response.xpath( "//table/tr/td/a" )
- 2.//table 表示不管 table 在哪个标签的下面,找到所有的 table 标签
- 3.这里 / 只是表示在哪个标签里,是谁的子标签,不一定是儿子标签,也包括孙子标签
- 4.如果需要查找的页面有很多很多 a 标签,那么这样找,范围还是太宽了
5.按标签属性查找:
res_href = response.xpath( "//table/tr/td/a/@href" )
- 这时候,我就可以找到所有 a 标签的链接,我们可以打印一下链接
for i in res_href :
print( i.extract() )- 6.按标签属性的值查找:
- 例如:我们想要查找表格中一个 id = teacher 的一个列
res_href = response.xpath( "//table/tr/td[@id='teacher']" )
以上是使用 xpath 精确查找,当然也可以使用 re 正则 去查找,本篇就介绍到这里了,拜拜
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-33-scrapy shell 的使用的更多相关文章
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
随机推荐
- P1001 A+B Problem (树链剖分)
这题考验我们构造模型的能力. 考虑构造一棵树,树上有3个节点,节点1和节点2连一条权值为a的边,节点1和节点3连一条权值为b的边,显然答案就是节点2到节点3的最短路径. 但这样还不够.考虑加法的性质, ...
- UVALive - 6436、HYSBZ - 2435 (dfs)
这两道题都是用简单dfs解的,主要是熟悉回溯过程就能做,据说用bfs也能做 道路修建(HYSBZ - 2435) 在 W 星球上有n 个国家.为了各自国家的经济发展,他们决定在各个国家 之间建设双向道 ...
- 2019.4.3 HTML&CSS 理论部分
HTML 块标签 1.独占一行,不和其他标签待在一行; 2.能设置宽高 常见的块标签:h1-h6,p,div,table,hr,br,ul,ol, 行标签 1.可以和其他行标签待在一行 2.不能设置宽 ...
- linux忘记root密码怎么办
如何找回root密码,如果我们不小心,忘记root密码,怎么找回? 思路:进入到单用户模式,然后修改root密码.因为进入单用户模式,root不需要密码就可以登录. 详细过程: 1.打开虚拟机 2.开 ...
- C#串口通讯中常用的16进制的字节转换
1.对于通讯协议的十六进制数值进行简单转换 //二进制转十进制Console.WriteLine("二进制 111101 的十进制表示: "+Convert.ToInt32(&qu ...
- axios简单介绍
axios的配置,get,post,axiso的同步问题解决 一.缘由 vue-resoure不更新维护,vue团队建议使用axios. 二.axios安装 1.利用npm安装npm install ...
- oracle 处理锁表sql
declare --类型定义 cursor c_cur is --查询锁表进程 SELECT object_name, machine, s.sid, s.serial# FROM gv$locked ...
- 构建私有Docker Registry
1.设置insecure-registry: 可能会出现无法push镜像到私有仓库的问题. 这是因为我们启动的registry服务不是安全可信赖的. 1) sudo vim /etc/default/ ...
- datatable 转字符串
--select stuff ((SELECT ','+bu from DT_SalesBooking group by bu for xml path('')),1,1,'')--select st ...
- 1.http请求编程-->基础原理
一.技术分析 打开网页,不管我们请求的是静态资源还是动态资源,IIS都会根据ISAPI(微软和Process软件公司联合提出的Web服务器上的API标准)这一标准,将请求的文件根据文件后缀名的不同,转 ...