Caffe学习笔记3
Caffe学习笔记3
本文为原创作品,未经本人同意,禁止转载,禁止用于商业用途!本人对博客使用拥有最终解释权
欢迎关注我的博客:http://blog.csdn.net/hit2015spring和http://www.cnblogs.com/xujianqing
http://caffe.berkeleyvision.org/gathered/examples/feature_extraction.html
这篇博客主要是用imagenet的一个网络模型来对自己的图片进行训练和测试
图片下载网址:http://download.csdn.net/detail/hit2015spring/9704947
参考文章:
http://caffe.berkeleyvision.org/gathered/examples/imagenet.html
1、准备数据,生成样本标签
在caffe/data 文件夹下新建文件夹myself

这篇文章主要是帮助你怎么准备你的数据集,怎么训练你自己的模型尺度,在这个笔记中主要是对自己网上下载的车,马,恐龙,花,进行训练和测试,训练2类各80张,测试各20张,放在/data/myself 目录下的train和val文件夹下,这些图片分类好了




这里面的图像的大小全部为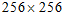 的,可以在终端用命令行,调整图像大小,训练和测试的图像均为
的,可以在终端用命令行,调整图像大小,训练和测试的图像均为
for name in data/myself/val/val_dinosar/*.JPEG; do
convert -resize 256x256\! $name $name
done

给这些图片制作索引标签,生成训练和测试的txt文件,用批量处理工具对这些图片进行处理:在data/myself/ 文件夹下面建立一个label.py的python脚本文件

在终端运行该脚本
python label.py
可以在data/myself/ 文件夹下生成两个txt文件,train.txt和val.txt



2、生成lmdb文件
在caffe/ 文件夹下新建myself文件夹,

从/home/xxx/caffe/examples/imagenet下复制create_imagenet.sh文件到caffe/myself
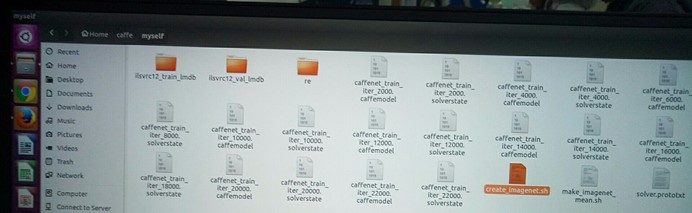

其中:
EXAMPLE =/home/wangshuo/caffe/myself
表示生成的LMDB文件存放的位置
DATA=/home/wangshuo/caffe/data/myself
表示数据标签存放的位置
TRAIN_DATA_ROOT=/home/wangshuo/caffe/data/myself/
VAL_DATA_ROOT=/home/wangshuo/caffe/data/myself/
表示训练和测试数据的位置,注意这里只填到myself这一级的目录。

EXAMPLE/ilsvrc12_val_lmdb
表示生成文件名为ilsvrc12_train_lmdb 和ilsvrc12_val_lmdb
在caffe根目录下运行create_imagenet.sh
./myself/create_imagenet.sh
在caffe/myself文件夹下生成lmdb文件

3、生成均值文件
从caffe/ examples/imagenet/ 拷贝make_imagenet_mean.sh文件到caffe/myself 文件夹下
修改该文件


EXAMPLE=/home/wangshuo/caffe/myself
##上面生成的lmdb文件目录
DATA=/home/wangshuo/caffe/data/myself
###生成文件所要存放的目录
TOOLS=/home/wangshuo/caffe/build/tools
在caffe根目录下运行该文件
./myself/make_imagenet_mean.sh
在caffe/data/myself 下生成imagenet_mean.binaryproto文件
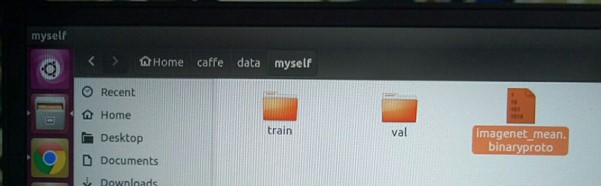
4、模型定义
复制models/bvlc_reference_caffenet/train_val.prototxt到caffe/myself文件夹,并修改路径
|
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto" source: "examples/imagenet/ilsvrc12_train_lmdb" mean_file: "data/ilsvrc12/imagenet_mean.binaryproto" source: "examples/imagenet/ilsvrc12_val_lmdb" |
|
mean_file: "data/myself/imagenet_mean.binaryproto" source: "myself/ilsvrc12_train_lmdb" mean_file: "data/myself/imagenet_mean.binaryproto" source: "myself/ilsvrc12_val_lmdb" |



这里还有一个bitch_size的参数,该参数如果过大,会提示GPU内存不够,在这里我设置为8
复制models/bvlc_reference_caffenet/solver.prototxt到caffe/myself
文件夹下,并修改文件路径
|
net: "myself/train_val.prototxt" ##模型所在目录 snapshot_prefix: "myself/caffenet_train"##生成的模型参数 |

test_iter: 1000 是指测试的批次,我们就 20 张照片,设置20就可以了。
test_interval: 1000 是指每 1000 次迭代测试一次,我们改成 500 次测试一次。
base_lr: 0.01 是基础学习率,因为数据量小, 0.01 就会下降太快了,因此改成 0.001
lr_policy: "step"学习率变化
gamma: 0.1 学习率变化的比率
stepsize: 100000 每 100000 次迭代减少学习率
display: 20 每 20 层显示一次
max_iter: 450000 最大迭代次数,
momentum: 0.9 学习的参数,不用变
weight_decay: 0.0005 学习的参数,不用变
snapshot: 10000 每迭代 10000 次显示状态,这里改为 2000 次
solver_mode: GPU 末尾加一行,代表用 GPU 进行
5、训练
在caffe根目录下运行
|
./build/tools/caffe time --model=myself/train_val.prototxt |

Caffe学习笔记3的更多相关文章
- Caffe学习笔记2--Ubuntu 14.04 64bit 安装Caffe(GPU版本)
0.检查配置 1. VMWare上运行的Ubuntu,并不能支持真实的GPU(除了特定版本的VMWare和特定的GPU,要求条件严格,所以我在VMWare上搭建好了Caffe环境后,又重新在Windo ...
- Caffe学习笔记(三):Caffe数据是如何输入和输出的?
Caffe学习笔记(三):Caffe数据是如何输入和输出的? Caffe中的数据流以Blobs进行传输,在<Caffe学习笔记(一):Caffe架构及其模型解析>中已经对Blobs进行了简 ...
- Caffe学习笔记(二):Caffe前传与反传、损失函数、调优
Caffe学习笔记(二):Caffe前传与反传.损失函数.调优 在caffe框架中,前传/反传(forward and backward)是一个网络中最重要的计算过程:损失函数(loss)是学习的驱动 ...
- Caffe学习笔记(一):Caffe架构及其模型解析
Caffe学习笔记(一):Caffe架构及其模型解析 写在前面:关于caffe平台如何快速搭建以及如何在caffe上进行训练与预测,请参见前面的文章<caffe平台快速搭建:caffe+wind ...
- Caffe学习笔记4图像特征进行可视化
Caffe学习笔记4图像特征进行可视化 本文为原创作品,未经本人同意,禁止转载,禁止用于商业用途!本人对博客使用拥有最终解释权 欢迎关注我的博客:http://blog.csdn.net/hit201 ...
- Caffe 学习笔记1
Caffe 学习笔记1 本文为原创作品,未经本人同意,禁止转载,禁止用于商业用途!本人对博客使用拥有最终解释权 欢迎关注我的博客:http://blog.csdn.net/hit2015spring和 ...
- Caffe学习笔记2
Caffe学习笔记2-用一个预训练模型提取特征 本文为原创作品,未经本人同意,禁止转载,禁止用于商业用途!本人对博客使用拥有最终解释权 欢迎关注我的博客:http://blog.csdn.net/hi ...
- CAFFE学习笔记(五)用caffe跑自己的jpg数据
1 收集自己的数据 1-1 我的训练集与测试集的来源:表情包 由于网上一幅一幅图片下载非常麻烦,所以我干脆下载了两个eif表情包.同一个表情包里的图像都有很强的相似性,因此可以当成一类图像来使用.下载 ...
- CAFFE学习笔记(四)将自己的jpg数据转成lmdb格式
1 引言 1-1 以example_mnist为例,如何加载属于自己的测试集? 首先抛出一个问题:在example_mnist这个例子中,测试集是人家给好了的.那么如果我们想自己试着手写几个数字然后验 ...
随机推荐
- Windows 8.1 SecureBoot未正确配置的解决方法
使用联想Y510P,安装win8.1后破解 ,屏幕右下角老是显示 SecureBoot未正确配置的解决方法,以下是解决方案 步骤1:在机器重启至“Lenovo字样的屏幕”时,不停敲击“F2”键或“Fn ...
- EL中定义函数
1.在java类中要定义一个static函数 2配置:在WEB-INF/*.tld的配置文件 3在JSP页面上 4使用
- hadoop SequenceFile示例
1.写入,SequenceFile的key和value不一定是Writable,只要能被Serialization序列化和反序列化就可以. private static final String[] ...
- [SDOI2013]淘金 数位DP
做了好久.... 大致思路: 求出前k大的方格之和即为答案, 先考虑一维的情况,设f[i]为数位上各个数相乘为i的数的总数,也就是对于数i,有f[i]个数它们各个位相乘为i, 再拓展到二维,根据乘法原 ...
- BZOJ3670 & 洛谷2375 & UOJ5:[NOI2014]动物园——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=3670 https://www.luogu.org/problemnew/show/P2375#su ...
- [CodeVs1227]方格取数2(最大费用最大流)
网络流24题的坑还没填完,真的要TJ? 题目大意:一个n*n的矩阵,每格有点权,从(1,1)出发,可以往右或者往下走,最后到达(n,n),每达到一格,把该格子的数取出来,该格子的数就变成0,这样一共走 ...
- Ubuntu安装CUDA9.0 + cuDNN
本篇文章是基于安装CUDA 9.0的经验写,CUDA9.0目前支持Ubuntu16.04和Ubuntu17.04两个版本,如下图所示(最下面的安装方式我们选择第一个,即runfile方式): 下载链接 ...
- HDU 5640
King's Cake Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total ...
- centos中mysql的安装
一:前沿 过完年了,花了不少钱啊!本来还打算买电脑的了,结果这个事情还是的延期啊!苍天啊!刚刚也看了下,一台苹果也大概是1w左右!买吧!boy!别犹豫了吧!好吧现在来说说我自己的工作吧!现在过完年到公 ...
- js对数组的常用操作
在js中对数组的操作是经常遇到的,我呢在这就列一下经常用到的方法 删除数组中的元素: 1.delete方法:delete删除的只是数组元素的值,所占的空间是并没有删除的 代码: var arr=[12 ...