分别用Eclipse和IDEA搭建Scala+Spark开发环境
开发机器上安装jdk1.7.0_60和scala2.10.4,配置好相关环境变量。网上资料很多,安装过程忽略。此外,Eclipse使用Luna4.4.1,IDEA使用14.0.2版本。
1. Eclipse开发环境搭建
1.1. 安装scala插件
安装eclipse-scala-plugin插件,下载地址http://scala-ide.org/download/prev-stable.html

解压缩以后把plugins和features复制到eclipse目录,重启eclipse以后即可。
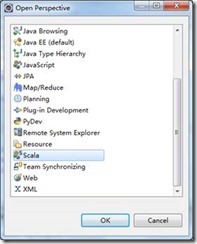
Window -> Open Perspective -> Other…,打开Scala,说明安装成功。
1.2. 创建maven工程
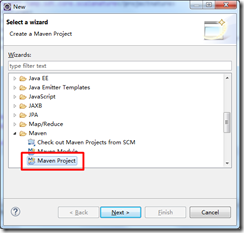
打开File -> New -> Other…,选择Maven Project:
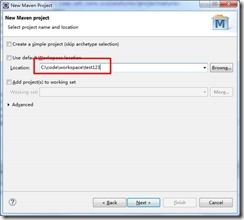
点击Next,输入项目存放路径:
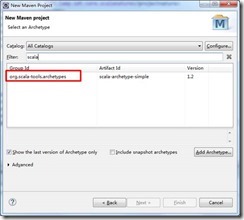
点击Next,选择org.scala-tools.archetypes:
点击Next,输入artifact相关信息:

点击Finish即可。默认创建好的工程目录结构如下:
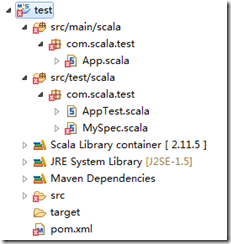
修改pom.xml文件:
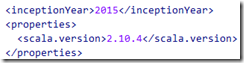
至此,一个默认的scala工程新建完成。
2. Spark开发环境搭建
2.1. 安装scala插件
开发机器使用的IDEA版本为IntelliJ IEDA 14.0.2。为了使IDEA支持scala开发,需要安装scala插件,如图:
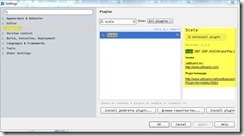
插件安装完成后,IntelliJ IDEA会要求重启。
2.2. 创建maven工程
点击Create New Project,在Project SDK选择jdk安装目录(建议开发环境中的jdk版本与Spark集群上的jdk版本保持一致)。点击左侧的Maven,勾选Create from archetype,选择org.scala-tools.archetypes:scala-archetype-simple:
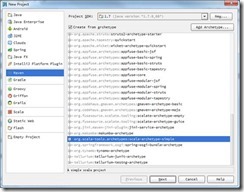
点击Next后,可根据需求自行填写GroupId,ArtifactId和Version(请保证之前已经安装maven)。点击Finish后,maven会自动生成pom.xml和下载依赖包。同1.2章节中eclipse下创建maven工程一样,需要修改pom.xml中scala版本。
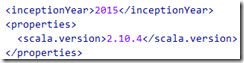
至此,IDEA下的一个默认scala工程创建完毕。
3. WordCount示例程序
3.1. 修改pom文件
在pom文件中添加spark和hadoop相关依赖包:
<!-- Spark --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.1.0</version> </dependency> <!-- Spark Steaming--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.1.0</version> </dependency> <!-- HDFS --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency>
在<build></build>中使用maven-assembly-plugin插件,目的是package时把依赖jar也打包。
<plugin> <artifactId>maven-assembly-plugin</artifactId> <version>2.5.5</version> <configuration> <appendAssemblyId>false</appendAssemblyId> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>com.ccb.WordCount</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>assembly</goal> </goals> </execution> </executions> </plugin>
3.2. WordCount示例
WordCount用来统计输入文件中所有单词出现的次数,代码参考:
package com.ccb
import org.apache.spark.{ SparkConf, SparkContext }
import org.apache.spark.SparkContext._
/**
* 统计输入目录中所有单词出现的总次数
*/
object WordCount {
def main(args: Array[String]) {
val dirIn = "hdfs://192.168.62.129:9000/user/vm/count_in"
val dirOut = "hdfs://192.168.62.129:9000/user/vm/count_out"
val conf = new SparkConf()
val sc = new SparkContext(conf)
val line = sc.textFile(dirIn)
val cnt = line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) // 文件按空格拆分,统计单词次数
val sortedCnt = cnt.map(x => (x._2, x._1)).sortByKey(ascending = false).map(x => (x._2, x._1)) // 按出现次数由高到低排序
sortedCnt.collect().foreach(println) // 控制台输出
sortedCnt.saveAsTextFile(dirOut) // 写入文本文件
sc.stop()
}
}
3.3. 提交spark执行
使用maven pacakge打包得到sparktest-1.0-SNAPSHOT.jar,并提交到spark集群运行。
执行命令参考:
|
./spark-submit --name WordCountDemo --class com.ccb.WordCount sparktest-1.0-SNAPSHOT.jar |
即可得到统计结果。
分别用Eclipse和IDEA搭建Scala+Spark开发环境的更多相关文章
- 【转】Eclipse和PyDev搭建完美Python开发环境(Ubuntu篇)
原文网址:http://www.cnblogs.com/Realh/archive/2010/10/10/1847251.html 前两天在Windows下成功地搭好了一个Python开发环境,这次转 ...
- Eclipse和PyDev搭建完美Python开发环境(Windows篇)(转)
摘要:本文讲解了用Eclipse和PyDev搭建Python的开发环境. 十一长假在家闲着没事儿,准备花点时间学习一下Python. 今儿花了一个下午搭建Python的开发环境,不禁感叹————开 ...
- 【Spark笔记】Windows10 本地搭建单机版Spark开发环境
0x00 环境及软件 1.系统环境 OS:Windows10_x64 专业版 2.所需软件或工具 JDK1.8.0_131 spark-2.3.0-bin-hadoop2.7.tgz hadoop-2 ...
- 搭建eclipse+maven+scala-ide的scala web开发环境
http://www.tuicool.com/articles/NBzAzy 江湖传闻,scala开发的最佳利器乃 JetBrains 的神作 IntelliJ IDEA ,外加构建工具sbt 是也. ...
- Windows下Eclipse+Scala+Spark开发环境搭建
1.安装JDK及配置java环境变量 本文使用版本为jdk1.7.0_79,过程略 2.安装scala 本文使用版本为2.11.8,过程略 3.安装spark 本文使用版本为spark-2.0.1-b ...
- Eclipse和PyDev搭建完美Python开发环境(Windows篇)
目录安装Pythonpython for eclipse插件安装配置PyDev插件测试 安装Python从网站上下载最新的版本,从http://python.org/download/下载.安装过程与 ...
- Eclipse和PyDev搭建完美Python开发环境 Windows篇
1,安装Python Python是一个跨平台语言,Python从3.0的版本的语法很多不兼容2版本,官网找到最新的版本并下载:http://www.python.org, 因为之前的一个项目是2版本 ...
- eclipse+cygwin+cdt搭建c/c++开发环境
Cygwin 是一个用于 Windows 的类 UNIX shell 环境. 它由两个组件组成:一个 UNIX API 库,它模拟 UNIX 操作系统提供的许多特性:以及 Bash shell 的改写 ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
随机推荐
- apply()方法和call()方法
obj.func.call(obj1) //是将obj1看做obj,调用func方法,将第一个参数看做函数调用的对象,可以看做,将obj的方法给obj1使用 ECMAScript规范给所有 ...
- SSIS 使用OLEDB/ADO NET Source 数据流source控件 连接Oracle失败
在做数据提取的时候发现一个非常奇怪的问题. Oracle客户端是安装正确并且Toad可以正常运行的,但是在新建OLEDB/ADO NET Source 数据流source控件连接Oracle的时候一直 ...
- [转载]hive中order by,sort by, distribute by, cluster by作用以及用法
1. order by Hive中的order by跟传统的sql语言中的order by作用是一样的,会对查询的结果做一次全局排序,所以说,只有hive的sql中制定了order by所有的 ...
- 【转】R树空间索引
R树在数据库等领域做出的功绩是非常显著的.它很好的解决了在高维空间搜索等问题.举个R树在现实领域中能够解决的例子吧:查找20英里以内所有的餐厅.如果没有R树你会怎么解决?一般情况下我们会把餐厅的坐标( ...
- 【创客+】偷心锁屏创始人Jerry创业心得分享
偷心锁屏创始人Jerry创业心得分享 作者:Jerry权泉,偷心锁屏创始人 我创业的起因非常偶然.08年在东京早稻田大学读博士期间,每周六都去社区活动中心跟日本人志愿者日语对话练习日语.有一次练习结束 ...
- 自学git心得-1
Github作为目前世界上最先进的分布式版本控制系统,是软工工作者管理工程代码的不二选择,笔者也是因时所需,自学了基本的git操作,在此回顾一下也作为分享. 推荐学习资源:https://www.li ...
- [PE格式分析] 3.IMAGE_NT_HEADER
源代码如下: typedef struct _IMAGE_NT_HEADERS { +00h DWORD Signature; // 固定为 0x00004550 根据小端存储为:"PE.. ...
- 深入理解mysql的底层实现
MySQL 的常用引擎 1. InnoDB InnoDB 的存储文件有两个,后缀名分别是 .frm 和 .idb,其中 .frm 是表的定义文件,而 idb 是数据文件. InnoDB 中存在表锁和行 ...
- mobile webiste 中的css的font-size em及line-height等换算
在mobile web设计 中,我们常常需要使用em这个字体大小的单位.em到底是多少呢? em到底应该设置为多少个em呢?通常换算成方法是1em=target fontsize we want/fo ...
- SQL Server ->> FIRST_VALUE和LAST_VALUE函数
两个都是SQL SERVER 2012引入的函数.用于返回在以分组和排序后取得最后一行的某个字段的值.很简单两个函数.ORDER BY字句是必须的,PARITION BY则是可选. 似乎没什么好说的. ...