Spark详解
原文连接 http://xiguada.org/spark/
Spark概述
当前,MapReduce编程模型已经成为主流的分布式编程模型,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。但是MapReduce也存在一些缺陷,如高延迟、不支持DAG模型、Map与Reduce的中间数据落地等。因此在近两年,社区出现了优化改进MapReduce的项目,如交互查询引擎Impala、支持DAG的TEZ、支持内存计算Spark等。Spark是UC Berkeley AMP lab开源的通用并行计算框架,以其先进的设计理念,已经成为社区的热门项目。Spark相对与MapReduce的优势有:低延迟、支持DAG和分布式内存计算。虽然Spark有许多优势,但是毕竟没有经过大规模生产的验证,所以暂未能代替MapReduce,庆幸的是,由于许多人意识到Spark的优势所在,社区Spark已成热门项目。本文对Spark的分析基于社区spark 1.0.2版本。
Spark生态圈介绍
Spark力图整合机器学习(MLib)、图算法(GraphX)、流式计算(Spark Streaming)和数据仓库(Spark SQL)等领域,通过计算引擎Spark,弹性分布式数据集(RDD),架构出一个新的大数据应用平台。
Spark生态圈以HDFS、S3、Techyon为底层存储引擎,以Yarn、Mesos和Standlone作为资源调度引擎;使用Spark,可以实现MapReduce应用;基于Spark,Spark SQL可以实现即席查询,Spark Streaming可以处理实时应用,MLib可以实现机器学习算法,GraphX可以实现图计算,SparkR可以实现复杂数学计算。

图1 Spark生态圈
Spark包与目录介绍
下载源码包:http://spark.apache.org/downloads.html
Spark 1.0.2源码包目录结构:
图2 spark代码目录结构
源代码下子目录很多,下表是几个关键目录的介绍。
|
子目录 |
功能 |
|
core |
Spark核心代码都在此目录下 |
|
sql |
Spark sql相关的代码 |
|
streaming |
Spark Streaming(实时计算)相关的代码 |
|
mlib |
MLib(机器学习)相关代码 |
|
graphx |
GraphX(图计算)相关代码 |
|
yarn |
支持Spark运行在Yarn上的模块 |
|
example |
各种spark作业的例子 |
非关键目录
|
子目录 |
功能 |
|
assembly |
组装spark项目的地方 |
|
bagel |
基于Spark的轻量Pregel实现,bagel将被GraphX代替 |
|
ec2 |
提交spark集群到Amazon EC2 |
|
external |
与一些外部系统的依赖 |
|
extra |
此目录包含了spark默认不构建的组件 |
|
repl |
Spark shell功能模块 |
|
tools |
工具包 |
Spark编译
Spark使用mvn编译,并为我们提交了构建项目的脚本:make-distribution.sh,推荐在Linux下编译,编译命令:./make-distribution.sh --hadoop 2.2.0 --with-yarn –tgz
编译成功后会工程目录下生成dist目录,即项目可执行包:
图3
如何运行Spark作业
参考社区文档: https://spark.apache.org/docs/latest/quick-start.html
Spark运行模式介绍
Spark任务的运行模式有local、standalone、OnYarn等,各种运行模式的详细流程可以参考博客: http://www.cnblogs.com/shenh062326/p/3658543.html
Spark作业执行简要流程
无论运行在哪种模式下,Spark作业的执行流程都是相似的,主要有如下八步:
- 客户端提交作业
- Driver启动流程
- Driver申请资源并启动其余Executor(即Container)
- Executor启动流程
- 作业调度,生成stages与tasks。
- Task调度到Executor上,Executor启动线程执行Task逻辑
- Driver管理Task状态
- Task完成,Stage完成,作业完成
Spark原理详细介绍
DAGScheduler与TaskScheduler详解
DAGScheduler把一个spark作业转换成成stage的DAG(Directed Acyclic Graph有向无环图),根据RDD和stage之间的关系,找出开销最小的调度方法,然后把stage以TaskSet的形式提交给TaskScheduler。图3与图4展示了DAGScheduler与TaskScheduler的工作。
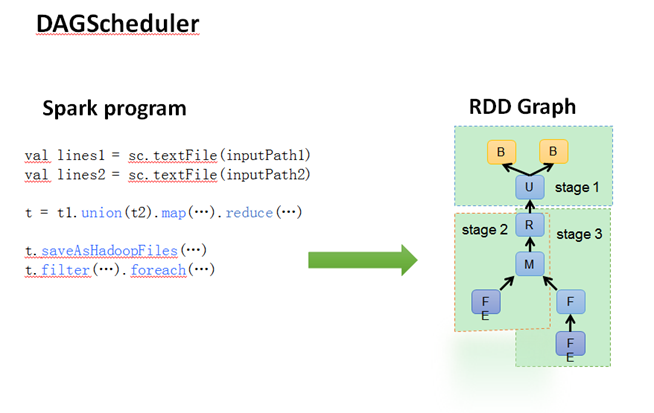
图4 DAGScheduler的作用
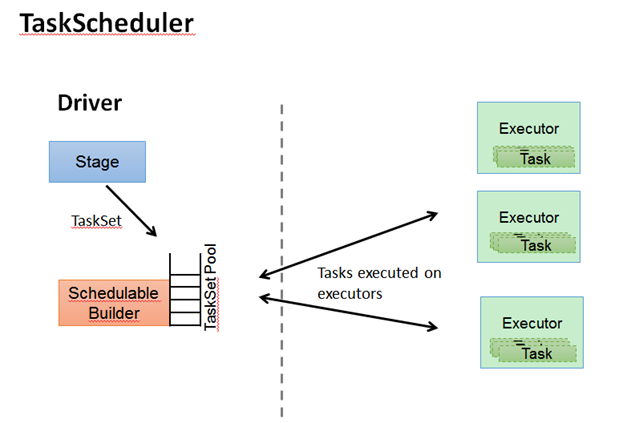
图5 TaskScheduler作用
DAGScheduler还决定了运行task的理想位置,并把这些信息传递给下层的TaskScheduler。此外,DAGScheduler还处理由于shuffle数据丢失导致的失败,这有可能需要重新提交运行之前的stage(非shuffle数据丢失导致的task失败由TaskScheduler处理)。
TaskScheduler维护所有TaskSet,当Executor向Driver发送心跳时,TaskScheduler会根据其资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行状态,重试失败的Task。
RDD详解
RDD(Resilient Distributed Datasets弹性分布式数据集),是spark中最重要的概念,用户可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中)。当然,RDD肯定不会这么简单,它的功能还包括容错、集合内的数据可以并行处理等。图5是RDD类的视图,图6简要展示了RDD的底层实现。更多RDD的操作描述和编程方法请参考社区文档:https://spark.apache.org/docs/latest/programming-guide.html。
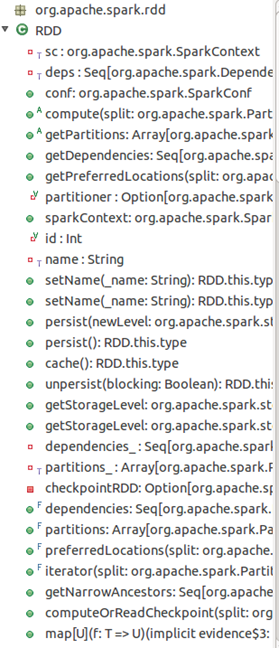
图6 RDD提供了许多操作
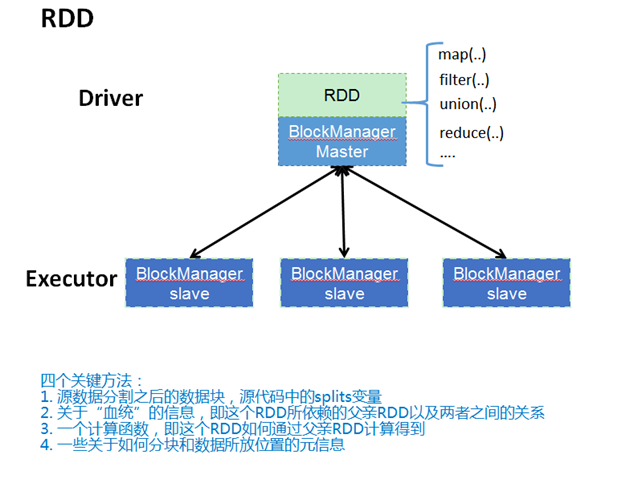
图7 RDD的实现
RDD cache的原理
RDD的转换过程中,并不是每个RDD都会存储,如果某个RDD会被重复使用,或者计算其代价很高,那么可以通过显示调用RDD提供的cache()方法,把该RDD存储下来。那RDD的cache是如何实现的呢?
RDD中提供的cache()方法只是简单的把该RDD放到cache列表中。当RDD的iterator被调用时,通过CacheManager把RDD计算出来,并存储到BlockManager中,下次获取便可直接通过CacheManager从BlockManager取出。
Shuffle原理简介
在Spark编程时,不仅仅只有reduce才会产生shuffle过程,RDD提供的groupByKey,countApproxDistinctByKey等操作都会生成shuffle。Spark中shuffle的实现与MapReduce的shuffle有比较大的差别,首先是map阶段,map的输出不再需要排序,直接写到文件中,一个map会把属于不同reduce的数据分别输出到不同的文体中,而reduce则通过aggregator处理所有shuffle fetch获取的partition。
从流程上看,MapTask结束后,Driver的MapOutPutTracker会注册MapOutPuts,ReduceTask启动后向Driver获取MapOutPutStatuses,然后fetch相应的MapOutPuts。
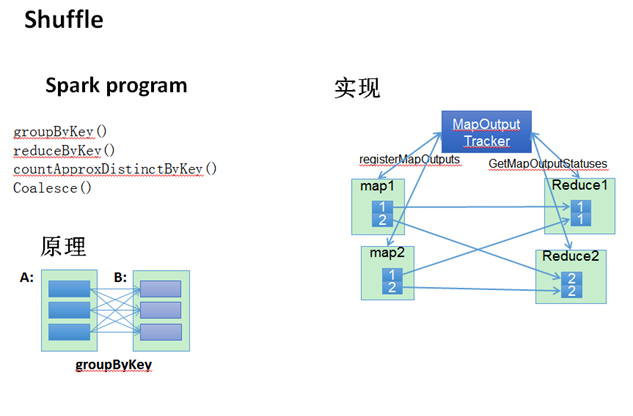
图8 Shuffle简介
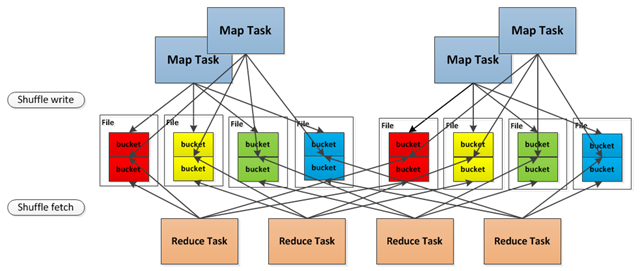
图9 Shuffle的原理(摘自网络)
Spark Streaming详解
Spark Streaming是建立在Spark上的实时计算框架,通过它提供丰富的API、基于内存的高速执行引擎,用户可以结合流式、批处理和交互试查询应用。
Spark Streaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据,其基本原理如下图所示。
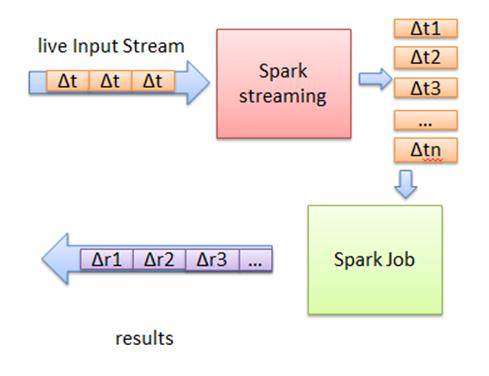
图10 Spark Streaming基本原理图
首先,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,最终结果也返回多块。
使用Spark Streaming编写的程序与编写Spark程序非常相似,在Spark程序中,主要通过操作RDD(Resilient Distributed Datasets弹性分布式数据集)提供的接口,如map、reduce、filter等,实现数据的批处理。而在Spark Streaming中,则通过操作DStream(表示数据流的RDD序列)提供的接口,这些接口和RDD提供的接口类似。
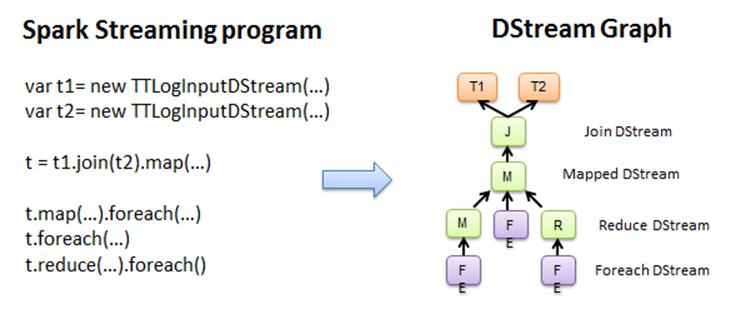
图11 Spark Streaming程序转换为DStream Graph
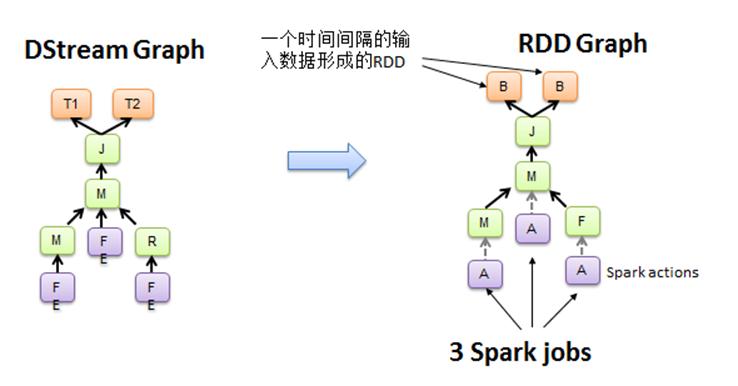
图12 DStream Graph转换为Spark jobs
在图12中,Spark Streaming把程序中对DStream的操作转换为DStream Graph,图4中,对于每个时间片,DStream Graph都会产生一个RDD Graph;针对每个输出操作(如print、foreach等),Spark Streaming都会创建一个Spark action;对于每个Spark action,Spark Streaming都会产生一个相应的Spark job,并交给JobManager。JobManager中维护着一个Jobs队列, Spark job存储在这个队列中,JobManager把Spark job提交给Spark Scheduler,Spark Scheduler负责调度Task到相应的Spark Executor上执行。
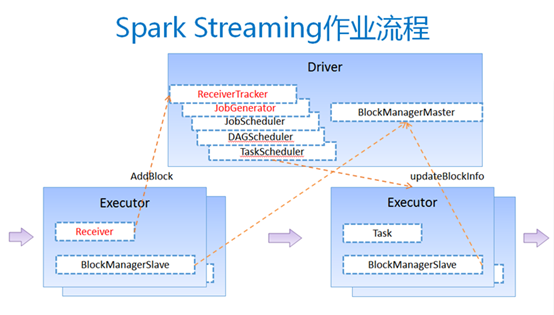
图13
Spark Streaming的另一大优势在于其容错性,RDD会记住创建自己的操作,每一批输入数据都会在内存中备份,如果由于某个结点故障导致该结点上的数据丢失,这时可以通过备份的数据在其它结点上重算得到最终的结果。
Spark详解的更多相关文章
- spark——详解rdd常用的转化和行动操作
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark第三篇文章,我们继续来看RDD的一些操作. 我们前文说道在spark当中RDD的操作可以分为两种,一种是转化操作(trans ...
- Spark框架详解
一.引言 作者:Albert陈凯链接:https://www.jianshu.com/p/f3181afec605來源:简书 Introduction 本文主要讨论 Apache Spark 的设计与 ...
- (七)Transformation和action详解-Java&Python版Spark
Transformation和action详解 视频教程: 1.优酷 2.YouTube 什么是算子 算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作. 算子分类: 具体: 1.Value ...
- Scala 深入浅出实战经典 第61讲:Scala中隐式参数与隐式转换的联合使用实战详解及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载: 百度云盘:http://pan.baidu.com/s/1c0noOt ...
- Scala 深入浅出实战经典 第60讲:Scala中隐式参数实战详解以及在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Spark小课堂Week6 启动日志详解
Spark小课堂Week6 启动日志详解 作为分布式系统,Spark程序是非常难以使用传统方法来进行调试的,所以我们主要的武器是日志,今天会对启动日志进行一下详解. 日志详解 今天主要遍历下Strea ...
- Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕
Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕 今天会逐行解析一下SparkStreaming运行的日志,运行的是WordCountO ...
- Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解
Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解 今天主要理一下StreamingContext的启动过程,其中最为重要的就是Jo ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- react生命周期函数使用箭头函数,导致mobx-react问题
最近新人加入了项目,遇到了一个很奇怪的问题.mobx observable 属性,onChange的时候就是页面不会刷新. 试来试去,就是不知道什么原因,后来其他同事查到是因为componentWil ...
- Sql Server中常用函数replicate
SQL常用函数之三 REPLICATE () 按指定次数重复字符表达式. 语法 REPLICATE ( character_expression, integer_expression) 参数 cha ...
- CentOS7.5更改grub2菜单背景&开机动态画面
Grub2菜单背景 红帽企业版 Linux 7 的引导装载程序是“GRUB 2”.您可以更改“GRUB 2”外观的几个部分.以下几小节将向您展示如何改变 Linux 发行版名称.菜单颜色,和背景图片. ...
- sql几种删除语句的联系与区别
DELETE.TRUNCATE.DROP三种删除语句联系与区别 相同点: 1.truncate和不带where子句的delete.以及drop都会删除表内的数据. 2.drop.truncate都是D ...
- Java实现蛇形矩阵
public class Solution { //下x++ 左y-- 上x-- 右y++ public void prints(int n) { int[][] mp = new int[n][n] ...
- SOAP消息的结构
概述 介绍SOAP报文的结构,以及获取的方式. 正文 1.其实发送的是SOAP消息 在前面讲述过使用Eclipse的工具Web Services Explorer发送请求.在Actions中填写请求参 ...
- UFO长啥样?--Python数据分析来告诉你
前言 真心讲,长这么大,还没有见过UFO长啥样,偶然看到美国UFO报告中心有关于UFO时间记录的详细信息,突然想分析下这些记录里都包含了那些有趣的信息,于是有了这次的分析过程. 当然,原始数据包含的记 ...
- Flask实战第60天:帖子分页技术实现
编辑manage.py,添加测试帖子 @manager.command def create_test_post(): for x in range(1, 100): title = '标题{}'.f ...
- 【数据结构】 最小生成树(三)——prim算法
上一期介绍到了kruskal算法,这个算法诞生于1956年,重难点就是如何判断是否形成回路,此处要用到并查集,不会用当然会觉得难,今天介绍的prim算法在kruskal算法之后一年(即1957年)诞生 ...
- 解决Xamarin Android SDK Manager闪退问题
解决Xamarin Android SDK Manager闪退问题 SDK Manager闪退是因为它找不到java.exe导致的.SDK Manager默认是通过读取注册表中JDK安装信息来java ...