爬虫(十):scrapy命令行详解
建爬虫项目
scrapy startproject 项目名
例子如下:
localhost:spider zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/spider/test1 You can start your first spider with:
cd test1
scrapy genspider example example.com
localhost:spider zhaofan$
这个时候爬虫的目录结构就已经创建完成了,目录结构如下:
|____scrapy.cfg
|____test1
| |______init__.py
| |____items.py
| |____middlewares.py
| |____pipelines.py
| |____settings.py
| |____spiders
| | |______init__.py
接着我们按照提示可以生成一个spider,这里以百度作为例子,生成spider的命令格式为;
scrapy genspider 爬虫名字 爬虫的网址
localhost:test1 zhaofan$ scrapy genspider baiduSpider baidu.com
Created spider 'baiduSpider' using template 'basic' in module:
test1.spiders.baiduSpider
localhost:test1 zhaofan$
关于命令详细使用
命令的使用范围
这里的命令分为全局的命令和项目的命令,全局的命令表示可以在任何地方使用,而项目的命令只能在项目目录下使用
全局的命令有:
startproject
genspider
settings
runspider
shell
fetch
view
version
项目命令有:
crawl
check
list
edit
parse
bench
startproject
这个命令没什么过多的用法,就是在创建爬虫项目的时候用
genspider
用于生成爬虫,这里scrapy提供给我们不同的几种模板生成spider,默认用的是basic,我们可以通过命令查看所有的模板
localhost:test1 zhaofan$ scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
localhost:test1 zhaofan$
当我们创建的时候可以指定模板,不指定默认用的basic,如果想要指定模板则通过
scrapy genspider -t 模板名字
localhost:test1 zhaofan$ scrapy genspider -t crawl zhihuspider zhihu.com
Created spider 'zhihuspider' using template 'crawl' in module:
test1.spiders.zhihuspider
localhost:test1 zhaofan$
crawl
这个是用去启动spider爬虫格式为:
scrapy crawl 爬虫名字
这里需要注意这里的爬虫名字和通过scrapy genspider 生成爬虫的名字是一致的
check
用于检查代码是否有错误,scrapy check
list
scrapy list列出所有可用的爬虫
fetch
scrapy fetch url地址
该命令会通过scrapy downloader 讲网页的源代码下载下来并显示出来
这里有一些参数:
--nolog 不打印日志
--headers 打印响应头信息
--no-redirect 不做跳转
view
scrapy view url地址
该命令会讲网页document内容下载下来,并且在浏览器显示出来因为现在很多网站的数据都是通过ajax请求来加载的,这个时候直接通过requests请求是无法获取我们想要的数据,所以这个view命令可以帮助我们很好的判断
shell
这是一个命令行交互模式
通过scrapy shell url地址进入交互模式
这里我么可以通过css选择器以及xpath选择器获取我们想要的内容(xpath以及css选择的用法会在下个文章中详细说明),例如我们通过scrapy shell http://www.baidu.com
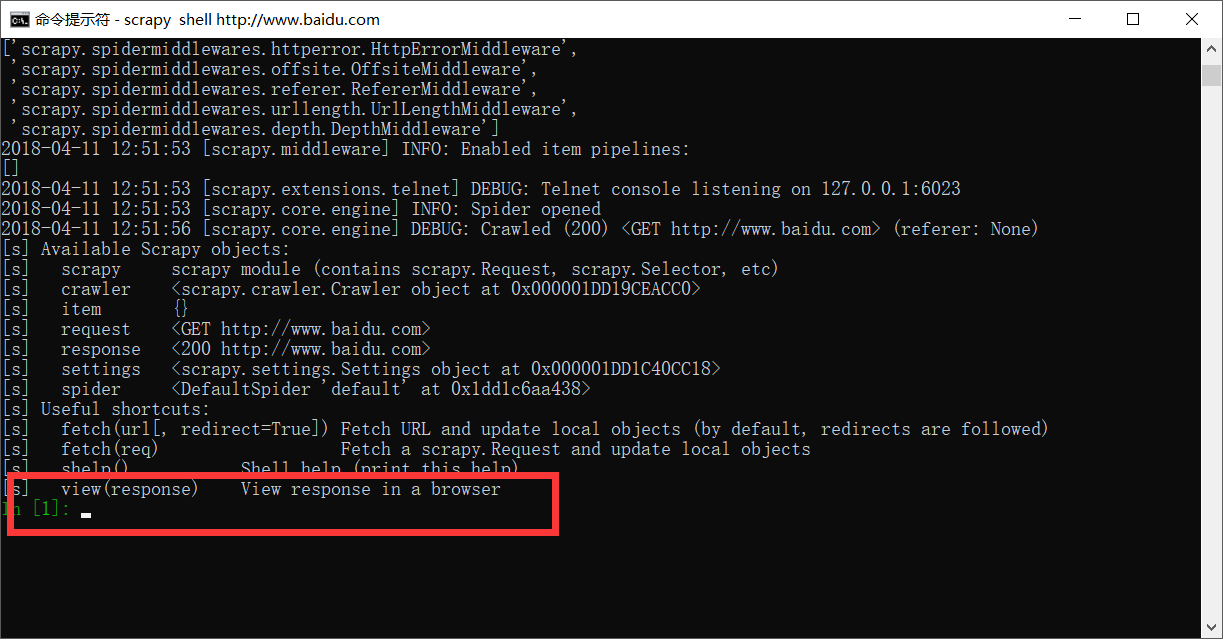
这里最后给我们返回一个response,这里的response就和我们通requests请求网页获取的数据是相同的。
view(response)会直接在浏览器显示结果
response.text 获取网页的文本
下图是css选择器的一个简单用法

settings
获取当前的配置信息
通过scrapy settings -h可以获取这个命令的所有帮助信息
C:\Users\felix>scrapy settings -h
Usage
=====
scrapy settings [options]
Get settings values
Options
=======
--help, -h show this help message and exit
--get=SETTING print raw setting value
--getbool=SETTING print setting value, interpreted as a boolean
--getint=SETTING print setting value, interpreted as an integer
--getfloat=SETTING print setting value, interpreted as a float
--getlist=SETTING print setting value, interpreted as a list
Global Options
--------------
--logfile=FILE log file. if omitted stderr will be used
--loglevel=LEVEL, -L LEVEL
log level (default: DEBUG)
--nolog disable logging completely
--profile=FILE write python cProfile stats to FILE
--pidfile=FILE write process ID to FILE
--set=NAME=VALUE, -s NAME=VALUE
set/override setting (may be repeated)
--pdb enable pdb on failure
拿一个例子进行简单的演示:(这里是我的这个项目的settings配置文件中配置了数据库的相关信息,可以通过这种方式获取,如果没有获取的则为None)
C:\Users\felix>scrapy settings --get=MYSQL_HOST
192.168.1.18
runspider
这个和通过crawl启动爬虫不同,这里是scrapy runspider 爬虫文件名称
所有的爬虫文件都是在项目目录下的spiders文件夹中
version
查看版本信息,并查看依赖库的信息
C:\Users\felix>scrapy version
Scrapy 1.5.0
C:\Users\felix>scrapy version -v
Scrapy : 1.5.0
lxml : 4.1.1.0
libxml2 : 2.9.5
cssselect : 1.0.3
parsel : 1.4.0
w3lib : 1.19.0
Twisted : 17.9.0
Python : 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:54:40) [MSC v.1900 64 bit (AMD64)]
pyOpenSSL : 17.5.0 (OpenSSL 1.1.0g 2 Nov 2017)
cryptography : 2.1.4
Platform : Windows-10-10.0.16299-SP0
爬虫(十):scrapy命令行详解的更多相关文章
- Scrapy命令行详解
官方文档:https://doc.scrapy.org/en/latest/ Global commands: startproject genspider settings runspider sh ...
- Scrapy框架的命令行详解【转】
Scrapy框架的命令行详解 请给作者点赞 --> 原文链接 这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: loca ...
- [转载]OpenSSL中文手册之命令行详解(未完待续)
声明:OpenSSL之命令行详解是根据卢队长发布在https://blog.csdn.net/as3luyuan123/article/details/16105475的系列文章整理修改而成,我自己 ...
- 7Z命令行详解
7z.exe在CMD窗口的使用说明如下: 7-Zip (A) 4.57 Copyright (c) 1999-2007 Igor Pavlov 2007-12-06 Usage: 7za <co ...
- 7-zip命令行详解
一.简介 7z,全称7-Zip, 是一款开源软件.是目前公认的压缩比例最大的压缩解压软件. 主要特征: # 全新的LZMA算法加大了7z格式的压缩比 # 支持格式: * 压缩 / 解压缩:7z, XZ ...
- Python之爬虫(十五) Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- Python爬虫从入门到放弃(十三)之 Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- gcc命令行详解
介绍] ----------------------------------------- 常见用法: GCC 选项 GCC 有超过100个的编译选项可用. 这些选项中的许多你可能永远都不会用到, 但 ...
- 【转】winrar命令行详解
从命令行也可以运行 WinRAR 命令,常规的命令行语法描述如下: WinRAR <命令> -<开关1> -<开关N> <压缩文件> <文件.. ...
随机推荐
- Hibernate常用api以及增删改查
一 .API的定义 所谓的API全称就是(Application Programming Interface,应用程序编程接口).就是类库对外提供的接口.类.枚举.注解等元素. 如:JDK API ...
- Thread interrupted() 线程的中断
问题: 1.线程的中断方式. 2.为什么中断阻塞中的线程,会抛出异常. 代码示例: package com.hdwl.netty; public class ThreadInterrupted { p ...
- 记录MindSphere On Cloud Foundry的一次尝试过程
试验背景: 开始时间:2019年12月11日 结束时间:2019年12月13日 自己编写一个后台程序,尝试推送到Cloud Foundry上,并开放从MindSphere以外访问的权限. 程序实现以下 ...
- git版本控制系统重新认识
git 版本控制系统 目标:完全搞懂git分布式版本控制系统 搭建git版本控制系统 cvs集中化版本控制系统--集中式管理的服务器 git分布式版本控制系统--会将原始代码仓库镜像下来 新项目使用g ...
- Powershell学习笔记:(二)、基础知识
从Window7以后,WIndows系统都自带了Windows PowerShell. 自带版本如下 WIndow7 2.0 WIndow8 3.0 Window8.1 4.0 Win ...
- iOS - 总结适配IOS10需要注意的问题
1.自动管理证书 首先要说的就是Xcode8.打开Xcode8最明显的就是Targets-->General下的自动管理证书模块.以前对于新手来说无论是开发还是打包都必须要被苹果的开发签名系统虐 ...
- Linux(一):Linux基础
1. Linux入门 1.1. Linux概述 Linux是一套免费使用和自由传播的类Unix操作系统.Unix操作系统是上世纪70年代在贝尔实验室诞生的一个强大的多用户.多任务操作系统. Linux ...
- Vue框架之基础知识
在没有学习基础知识之前,我们需要下载vue的js文件,在使用vue语法之前引包 <script src='./vue.js'></script> 一.模板语法 模板语法是一种可 ...
- Yum三方仓库——RPMForge
参考:How to Enable RPMForge Repository in RHEL/CentOS 7.x/6.x/5.x RPMForge / RepoForge这两个项目已经死亡,不应该使用 ...
- linux网络编程之socket编程(十五)
今天继续学习socket编程,这次主要是学习UNIX域协议相关的知识,下面开始: [有个大概的认识,它是来干嘛的] ①.UNIX域套接字与TCP套接字相比较,在同一台主机的传输速度前者是后者的两倍. ...