深入理解hadoop之机架感知
深入理解hadoop之机架感知
机架感知
hadoop的replication为3,机架感知的策略为:
第一个block副本放在和client所在的datanode里(如果client不在集群范围内,则这第一个node是随机选取的)。第二个副本放置在与第一个节点不同的机架中的datanode中(随机选择)。第三个副本放置在与第二个副本所在节点同一机架的另一个节点上。如果还有更多的副本就随机放在集群的datanode里,这样如果第一个block副本的数据损坏,节点可以从同一机架内的相邻节点拿到数据,速度肯定比从跨机架节点上拿数据要快;同时,如果整个机架的网络出现异常,也能保证在其它机架的节点上找到数据。为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。那么Hadoop是如何确定任意两个节点是位于同一机架,还是跨机架的呢?答案就是机架感知。
默认情况下,hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务 。但是,hadoop对机架的感知并非是真正智能感知的,而是需要人为的告知hadoop哪台机器属于哪个rack,这样在hadoop的namenode启动初始化时,会将这些机器与rack的对应信息保存在内存中,作为写块操作时分配datanode列表时选择datanode的依据。
要将hadoop机架感知的功能启用,配置非常简单,在namenode所在机器的hadoop-site.xml配置文件中配置一个选项:
<property>
<name>topology.script.file.name</name>
<value>/path/to/RackAware.py</value>
</property>
这个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架,保存到内存的一个map中。
网络拓扑
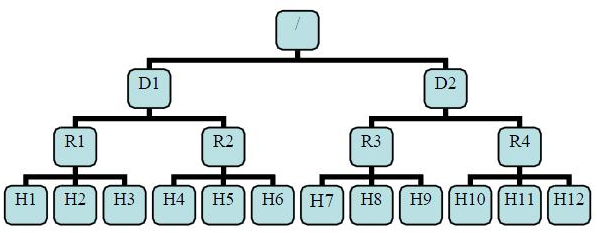
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
深入理解hadoop之机架感知的更多相关文章
- hadoop配置机架感知
接着上一篇来说.上篇说了hadoop网络拓扑的构成及其相应的网络位置转换方式,本篇主要讲通过两种方式来配置机架感知.一种是通过配置一个脚本来进行映射:另一种是通过实现DNSToSwitchMappin ...
- 【原创】Hadoop机架感知对性能调优的理解
Hadoop作为大数据处理的典型平台,在海量数据处理过程中,其主要限制因素是节点之间的数据传输速率.因为集群的带宽有限,而有限的带宽资源却承担着大量的刚性带宽需求,例如Shuffle阶段的数据传输不可 ...
- 【转载】Hadoop机架感知
转载自http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html 背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机 ...
- hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- hadoop之 hadoop 机架感知
1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份.这样如果本地数据损坏,节点可以从同一机 ...
- 第十三章 hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- 【Hadoop】Hadoop 机架感知配置、原理
Hadoop机架感知 1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份, 同机架内其它某一节点上一份,不同机架的某一节点上一份. 这样如果本地 ...
- Hadoop--Hadoop的机架感知
Hadoop的机架感知 Hadoop有一个“机架感知”特性.管理员可以手工定义每个slave数据节点的机架号.为什么要做这么麻烦的事情?有两个原因:防止数据丢失和提高网络性能. 为了防止数据丢 ...
- hdfs 机架感知
一.背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高 ...
随机推荐
- 2.HDFS和HA
1.HDFS简介 DataNode NameNode SecondaryNameNode HDFS文件权限 2.HDFS小结 3.HDFS交互操作 4.HDFS编程访问接口
- 【导航】JennyHui 老白兔记录贴
英语控 TED X - > 笔记 程序媛 2019-08-24 Java学习路径规划 思考记录 2018-08-24 常见的工作思考方式 浪费时间 百家讲坛 开卷八分钟
- 最详细React Native环境配置及项目初始化(2018-10-14)
注意配环境一定要全程使用稳定VPN工具,否则会浪费大量时间!!!相信我 一.截止到项目初始化之前也就是执行这条命令之前都按官网的方法就可以 https://reactnative.cn/docs/ge ...
- 编写 Model 层的代码
创建 App 这里把所有 Model 划分为三类:blog 相关.配置相关和评论相关.这么分的好处是便于独立维护各个模块,也便于在开发时分配任务. blog App 创建一个名为 blog 的 app ...
- Ironic 裸金属管理服务的底层技术支撑
目录 文章目录 目录 底层技术支撑 DHCP NBP TFTP IPMI PXE & iPXE Cloud Init Linux 操作系统启动引导过程 底层技术支撑 PXE:预启动执行环境,支 ...
- Python标准组件ConfigParser配置文件解析器,保存配置时支持大写字母的方法
虽然自己已经改用xml作为配置文件首选格式了,但是有时候还是需要解析ini.cfg文件(为了兼容早期版本或者其他作者的软件). 基本上Python自带的ConfigParser足够应对了,但是美中不足 ...
- DVD Cloner 2019MAC如何使用?
DVD Cloner 2019 for mac是一款应用在Mac上的DVD刻录软件,它可以将DVD克隆到任何空白光盘,包括具有多种复制模式的DVD + R / RW,DVD-R / RW,DVD + ...
- Python爬虫学习==>第十一章:分析Ajax请求-抓取今日头条信息
学习目的: 解决AJAX请求的爬虫,网页解析库的学习,MongoDB的简单应用 正式步骤 Step1:流程分析 抓取单页内容:利用requests请求目标站点,得到单个页面的html代码,返回结果: ...
- linux centos 安装输入法
终端输入命令: yum install ibus-libpinyin.x86_64
- 切换windows系统输入法的中英文,可以忽视是哪种打字法
调用windows的API //用户获取当前输入法句柄 [DllImport("imm32.dll")] public static extern IntPtr ImmGetCon ...