JVM常用指标查询
一.what‘s going on in Java Application
当系统卡顿,应用莫名被杀掉,我们应该怎么排查?在我已知的系统挂掉的情况,只经历过两种:1.内存申请不了(OOM);2.CPU占用过高
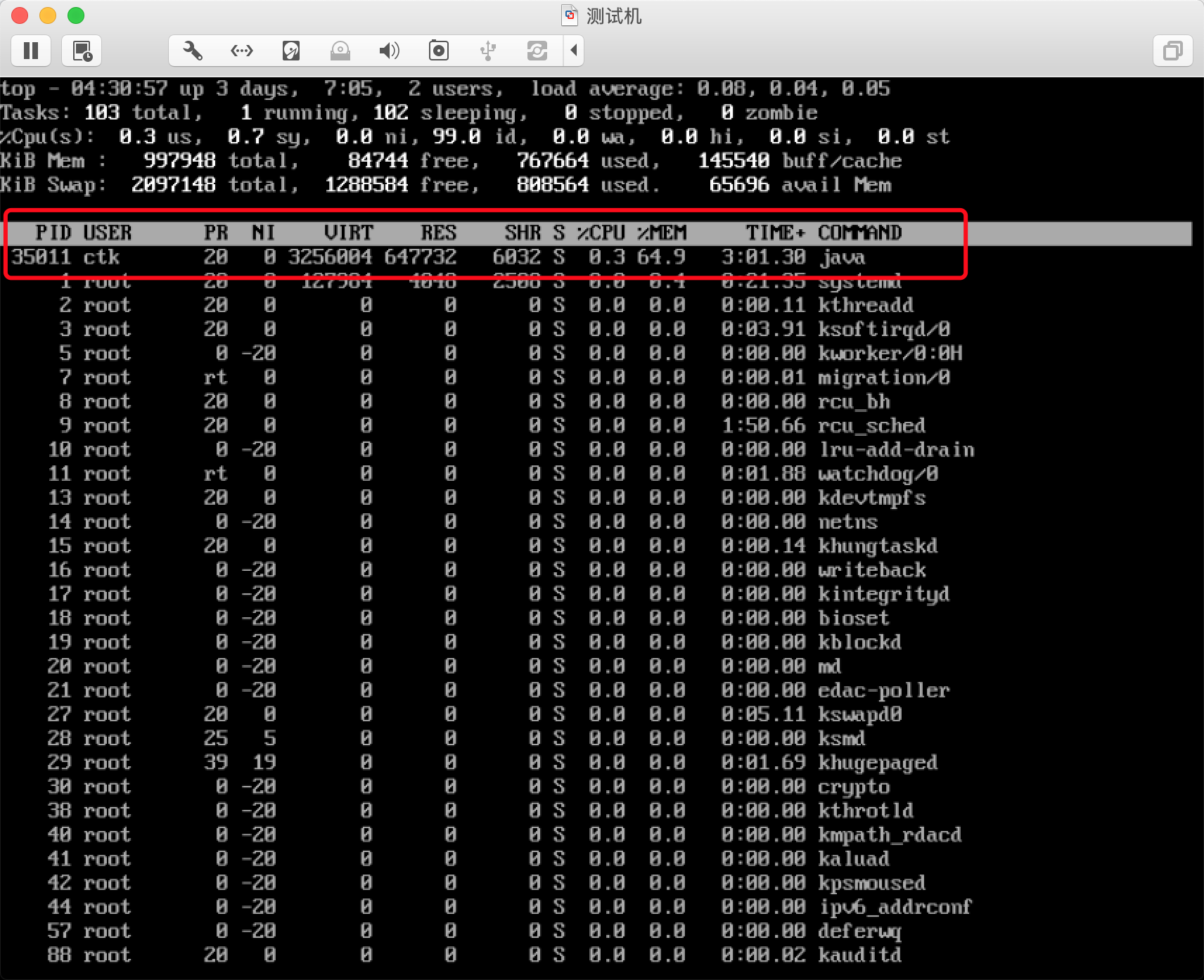
使用top命令即可以观察linux的进程信息,以及CPU占用信息,拿到了进程号就可以进一步了解进程信息。
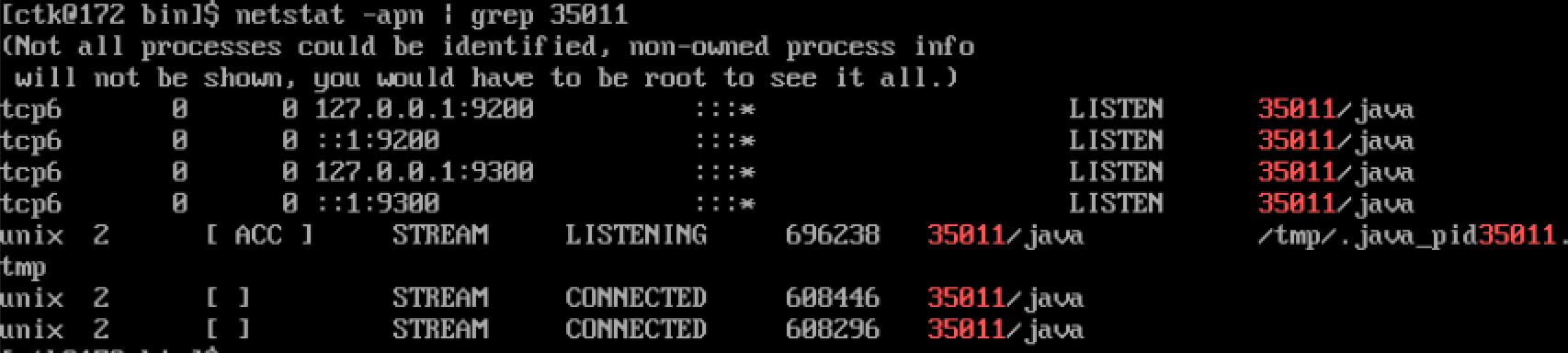
netstat -apn | grep
即可观察java应用所监听的端口。
如果机子上配置了Java环境,则使用jps命令即可看到Java进程号。
通常我最常用是
jps -ml
可显示给主函数传入的参数,并显示主类的完整包名。

可以查询启动Java进程时候jvm的参数,使用
jps -v
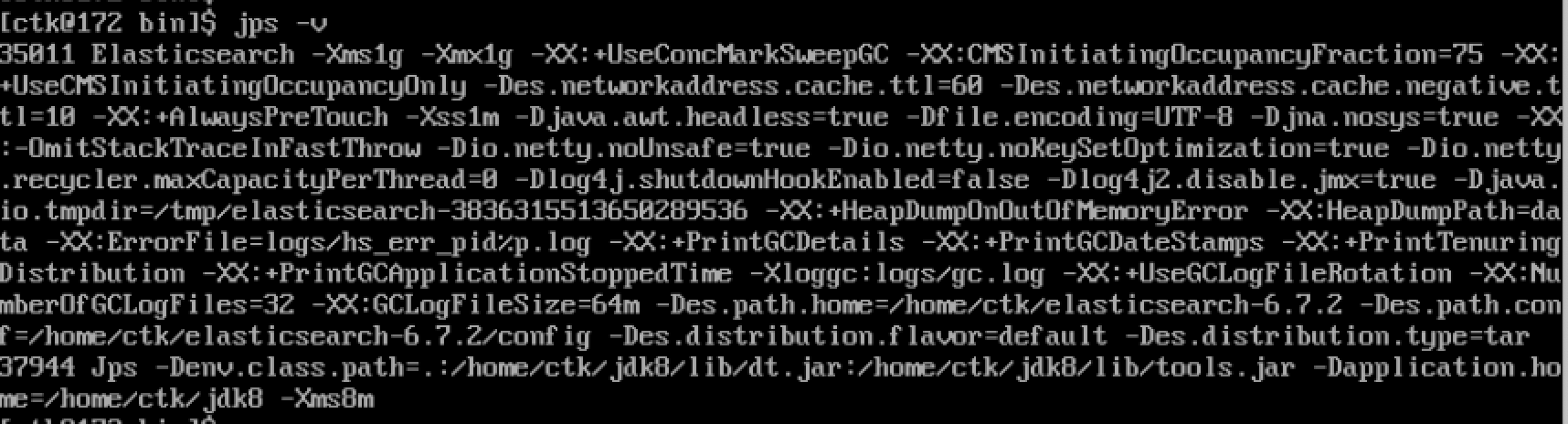
可以看到一些收集器的配置(以上是使用CMS),Java堆的内存配置,等等。注意里面有一个参数,HeapDumpOnOutofMemmoryError,这个参数说明JVM在检测到内存溢出的时候会输出一个内存快照,并输出到后面这个dumpPath中。
内存溢出有两种情况,一种是到达JVM设置的最大内存,而这个时候并没有到达Linux系统内存瓶颈,这个时候应该是不会把Java杀掉(猜测);另一种是造成了Linux系统内存申请问题,则Linux会杀掉这个异常进程(Linux Kernel OOM(Out of memory killer))。
如果想从linux层面查看进程,则进入文件夹;Linux的进程是以文件形式记录的,也就是fd的概念。
/proc/{pid}/status

linux日志文件说明 (抄过来的)
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
/var/log/secure 安全相关的日志信息
/var/log/maillog 邮件相关的日志信息
/var/log/cron 定时任务相关的日志信息
/var/log/spooler UUCP和news设备相关的日志信息
/var/log/boot.log 守护进程启动和停止相关的日志消息
/var/log/wtmp 该日志文件永久记录每个用户登录、注销及系统的启动、停机的事件
有一次查询OOM挂掉的应用信息,在阿里云监控里内存下来的那个时间点,去查message,看到了Linux的OOM kill的日志。
二.Memmory or CPU
在市面上看到的Java应用,无论是处理什么业务的,最常见的就是对这两种资源的支配。计算密集型,考虑空间换时间;文档型、内存型的,考虑优化业务方法或者考虑多台机器。根据以上的方法,我们可以对Java进程的一些指标进行监控,而我们如果需要进一步知道卡顿的原因,则我们可以使用jdk自带的工具进行查询。
内存这个主题可以分为很多场景:堆内存不足(业务需求增长、代码中申请内存不合理导致频繁Full GC、一次申请内存超过JVM设置、内存溢出)、常量池内存不足、Linux内存不足、爆栈 等等。但是大多数情况下,我们都是可以预料到的(大多数都是代码的问题)。如果你有一个业务,会加载大量的文档,那你肯定一开始就知道需要准备可伸缩型架构了(只要加机器就能解决线上问题的架构,也就是便于横向扩展)。所以,在内存这个主题上,我们只需要关注一些不是立即发生、在系统运行中逐渐拖垮系统的问题排查,比如,内存溢出。
在Java中,内存溢出指的是使用过的并且未来不再使用的内存没有被GC正常回收的情况。举个例子,你在系统中使用了全局的Map记录一些业务以及数据对应的关系,而key值是业务产生时候的标志(每次业务都会不一样),value值是每次业务的对应数据;如果在业务完成之后没有remove,则在系统运行的过程中,这个Map是会不断增大的,最终这些无用的内存会导致OOM。(当然,一个正常的程序员是不会这么写的)
我们在内存溢出的时候可能做得更加隐秘,所以需要使用jdk的工具帮助我们发现这些问题。
jmap -histo {pid} | head
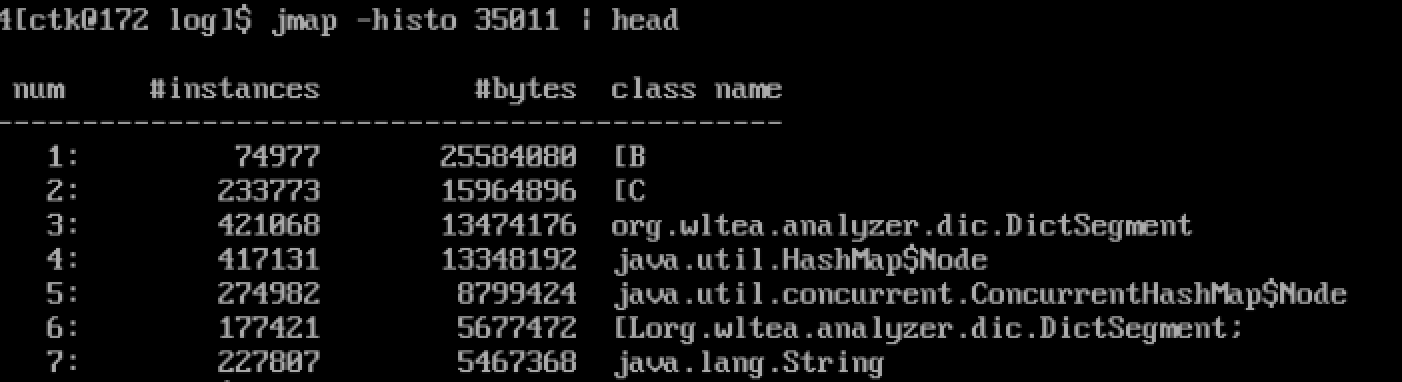
这个是正常的内存快照,如果是不正常的,则排在前几的有可能就是你写的那个数据结构。再通过一些手段定位出是代码中的哪行。这样我们排查内存溢出就会简单一些了。
[ctk@ ~]$ jmap -heap
Attaching to process ID , please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.181-b13 using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC Heap Configuration:
MinHeapFreeRatio =
MaxHeapFreeRatio =
MaxHeapSize = (.0MB)
NewSize = (.1875MB)
MaxNewSize = (.1875MB)
OldSize = (.8125MB)
NewRatio =
SurvivorRatio =
MetaspaceSize = (.796875MB)
CompressedClassSpaceSize = (.0MB)
MaxMetaspaceSize = MB
G1HeapRegionSize = (.0MB) Heap Usage:
New Generation (Eden + Survivor Space):
capacity = (.875MB)
used = (.74217224121094MB)
free = (.13282775878906MB)
50.40690783467237% used
Eden Space:
capacity = (.5625MB)
used = (.68754577636719MB)
free = (.874954223632812MB)
56.6197870818662% used
From Space:
capacity = (.3125MB)
used = (.05462646484375MB)
free = (.25787353515625MB)
0.6571604793233082% used
To Space:
capacity = (.3125MB)
used = (.0MB)
free = (.3125MB)
0.0% used
concurrent mark-sweep generation:
capacity = (.8125MB)
used = (.3957748413086MB)
free = (.4167251586914MB)
11.734088869068874% used interned Strings occupying bytes.
使用-heap查看堆信息,这样就能整体看看内存的情况。
另一种情况,是收集器选型不合理导致的gc卡顿,这样需要去观察gc的状态,用到了jdk的另一种工具:jstat
[ctk@ ~]$ jstat -gc
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
8512.0 8512.0 55.9 0.0 68160.0 32072.9 963392.0 113045.3 79036.0 72618.0 12220.0 10128.0 2.041 0.129 2.170
带c的意思是capacity(容量)的意思,带u的是used(已使用)的意思。s0,s1这些都是书上的概念,年轻代,老年代等等。M是method,方法区的意思。一般看的是YGC,YGCT,就是young gc次数,young gc time;FGC,FGCT,full gc次数,full gc time等参数。如果full gc的时间过长,young gc次数过于频繁,则考虑去优化代码。
[ctk@ ~]$ jstat -gcutil
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.66 0.00 62.44 11.73 91.88 82.88 2.041 0.129 2.170
0.66 0.00 62.44 11.73 91.88 82.88 2.041 0.129 2.170
0.66 0.00 62.44 11.73 91.88 82.88 2.041 0.129 2.170
0.66 0.00 62.44 11.73 91.88 82.88 2.041 0.129 2.170
后边带个100指100ms输出一次。
至今还没碰到gc来不及而内存爆炸的情况,如果出现大体都是代码写得不好。
另一个topic,就是CPU占用过高的问题。CPU占用过高的情况很容易联想就是死循环,线程一直Runnable而且不退出。很多情况下都是BUG,没有什么业务会让Java进程使用那么高的占用率。我遇到过三次,情况都不一样,都归于BUG。
第一个,是在一个2c的系统里面,使用了全局jdk1.7的Map,并且是HashMap。在resize和put的过程中,链表成了环,所以在系统开的Thread中,卡在ContainsKey这个方法中,导致CPU占用过高挂掉,这个问题很隐蔽,并且是几率型发生的(谁也不能保证成环,也不能保证你计算到那个环上)。我们最初是使用top命令观察一段时间,发现CPU莫名的高,但是内存占用却不高,而且不是业务旺季。这个时候要采用jdk提供的另一种工具:jstack
[ctk@ ~]$ jstack | grep RUNNABLE -A
java.lang.Thread.State: RUNNABLE "elasticsearch[BeEZ6i3][trigger_engine_scheduler][T#1]" # daemon prio= os_prio= tid=0x00007faaf869f000 nid=0x88f9 waiting on condition [0x00007faaba846000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000c881d468> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
--
java.lang.Thread.State: RUNNABLE "elasticsearch[keepAlive/6.7.2]" # prio= os_prio= tid=0x00007faaf9fa8000 nid=0x88f8 waiting on condition [0x00007faabad47000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000c571a008> (a java.util.concurrent.CountDownLatch$Sync)
--
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:)
- locked <0x00000000c9ce5940> (a sun.nio.ch.Util$)
--
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:)
- locked <0x00000000c9ce5d90> (a sun.nio.ch.Util$)
--
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:)
- locked <0x00000000c9c57a08> (a sun.nio.ch.Util$)
--
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:)
- locked <0x00000000c9c58398> (a sun.nio.ch.Util$)
--
java.lang.Thread.State: RUNNABLE
at java.io.FileInputStream.readBytes(Native Method)
at java.io.FileInputStream.read(FileInputStream.java:)
at org.elasticsearch.xpack.ml.process.logging.CppLogMessageHandler.tailStream(CppLogMessageHandler.java:)
at org.elasticsearch.xpack.ml.process.NativeController.lambda$tailLogsInThread$(NativeController.java:)
at org.elasticsearch.xpack.ml.process.NativeController$$Lambda$/.run(Unknown Source)
--
java.lang.Thread.State: RUNNABLE
at java.lang.UNIXProcess.waitForProcessExit(Native Method)
at java.lang.UNIXProcess.lambda$initStreams$(UNIXProcess.java:)
at java.lang.UNIXProcess$$Lambda$/.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
--
java.lang.Thread.State: RUNNABLE "C1 CompilerThread1" # daemon prio= os_prio= tid=0x00007faaf80fa000 nid=0x88ce waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE "C2 CompilerThread0" # daemon prio= os_prio= tid=0x00007faaf80f8000 nid=0x88cd waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE "Signal Dispatcher" # daemon prio= os_prio= tid=0x00007faaf80f5800 nid=0x88cc runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE "Surrogate Locker Thread (Concurrent GC)" # daemon prio= os_prio= tid=0x00007faaf80f4800 nid=0x88cb waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE "Finalizer" # daemon prio= os_prio= tid=0x00007faaf80c1800 nid=0x88ca in Object.wait() [0x00007faad3ffe000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000000c5888f08> (a java.lang.ref.ReferenceQueue$Lock)
我们先是定位RUNNABLE的线程,发现有好几个线程都是卡在containsKey这个方法。这个方法就是去hash一个key,并遍历链表看看这个key是否存在。这里有一个循环,如果循环不结束,则线程是一直RUNNABLE的,而且即使客户端DISCONNECT,也不能保证这个Thread停止。我们是web服务,断开连接,但是后台线程依然是没有结束。
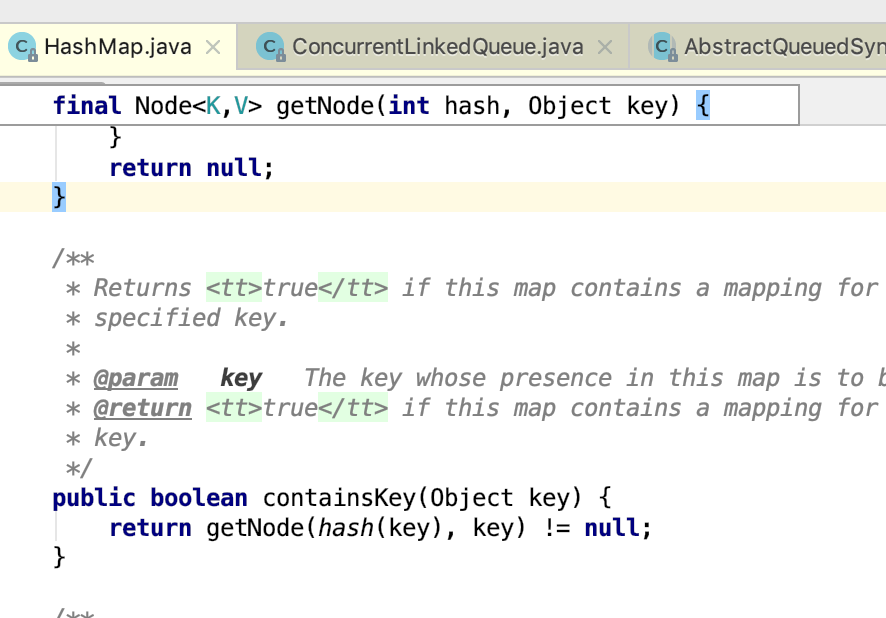
然后回忆起并发编程那本书里提到的,并发下诡异的HashMap,遂猜测成环。因为使用的是static HashMap,所以建议修改为ConcurrentHashMap,观察一段时间之后,问题修复。
第二个是在进行阿里云vpc服务迁移的时候,发布生产的时候,莫名其妙服务不打错误日志,而应用起不来,屡试不爽。并且在启动的很久之后,报了Socket TimeOut之类的错误。然后启动的时候使用jstack查状态,发现主线程main卡在数据库连接上,一直是RUNNABLE的情况,最终在启动很久之后报出TIMEOUT之类的错误。(没有现场日志了)所以推测是服务器与数据库的链接配置(安全组,权限,用户)是否正常,最终是安全组的配置问题。
第三个问题非常诡异,消息中心采用ActiveMQ,业务方使用ActiveMQ Client进行使用。而消息中心闪断之后,理应触发重连机制,但是在抛出一个异常JMS 什么Support Exception之后,CPU变得异常的高。而在抛出这个异常的时候,抛出了一个NoClassDef异常,这个异常大概率是jar冲突。这个问题没有详细排查,猜测是ActiveMQ在处理这个异常的时候,如果找不到有可能仍然不断发起重连,一直新建重连线程导致的。由于是老系统,所以没有详细查了,根本原因还是依赖太过混乱。
dump内存。
jmap -dump:format=b,file=dump.hprof {pid}
使用MAT进行内存分析。
新鲜案例,幽灵一般的内存泄露。由于内存中的ArrayList占据老年代大量内存,触发的fullgc不能把它gc掉导致频繁的fullgc,进而CPU 100%,接口变慢。

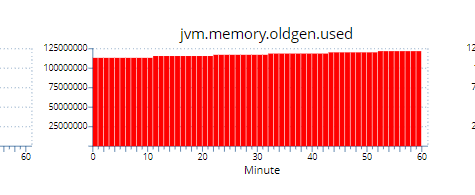
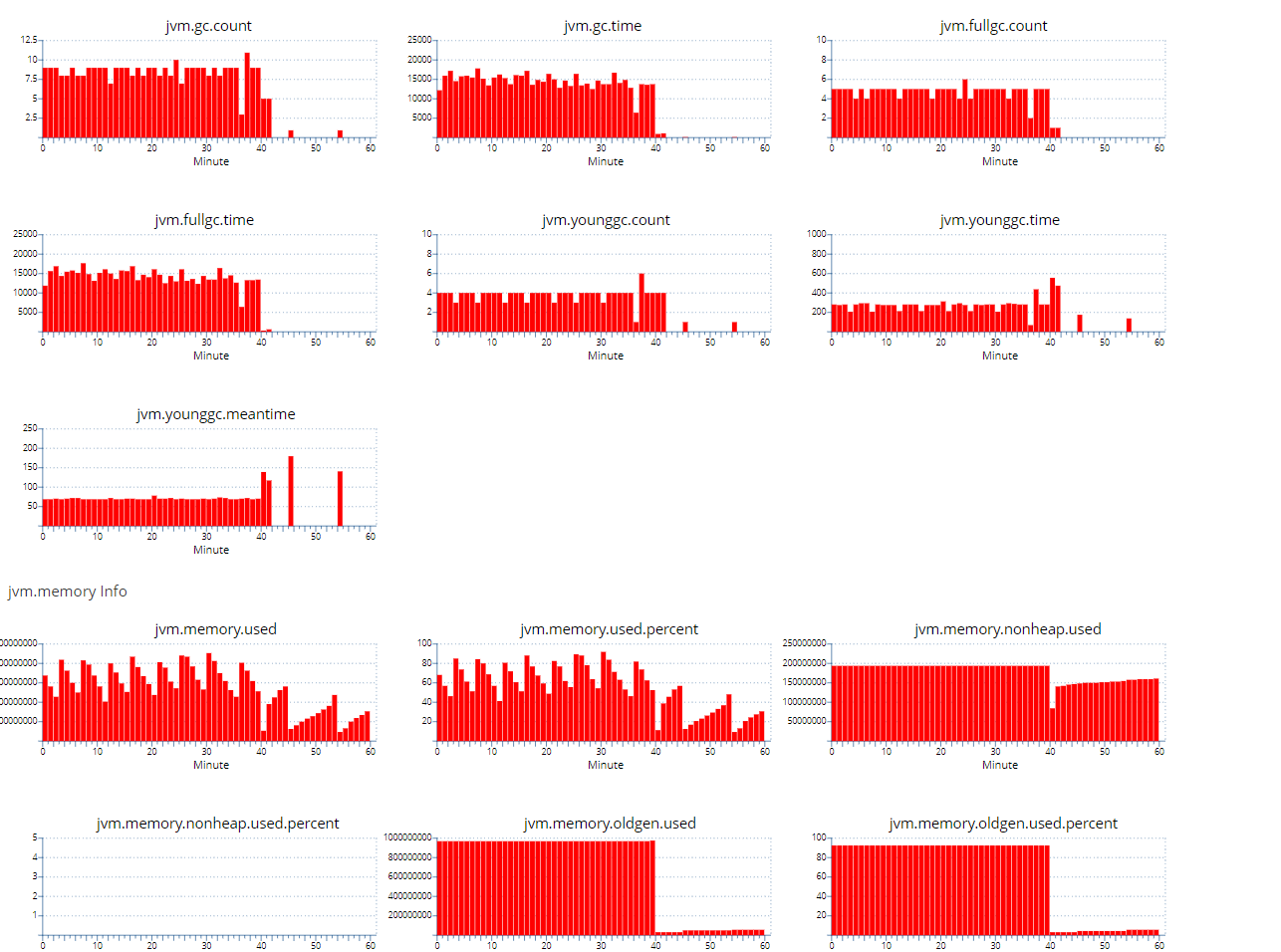
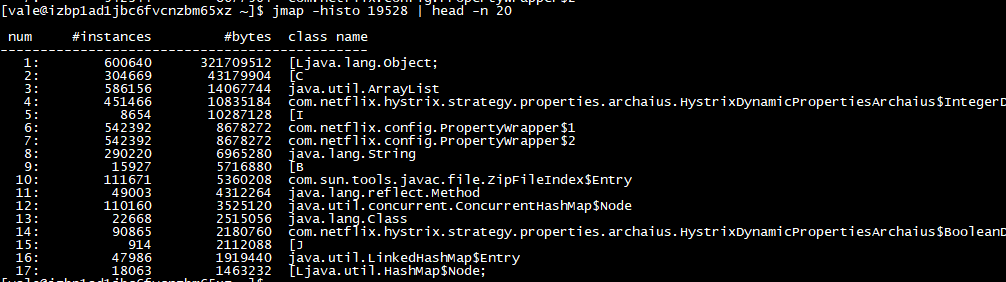
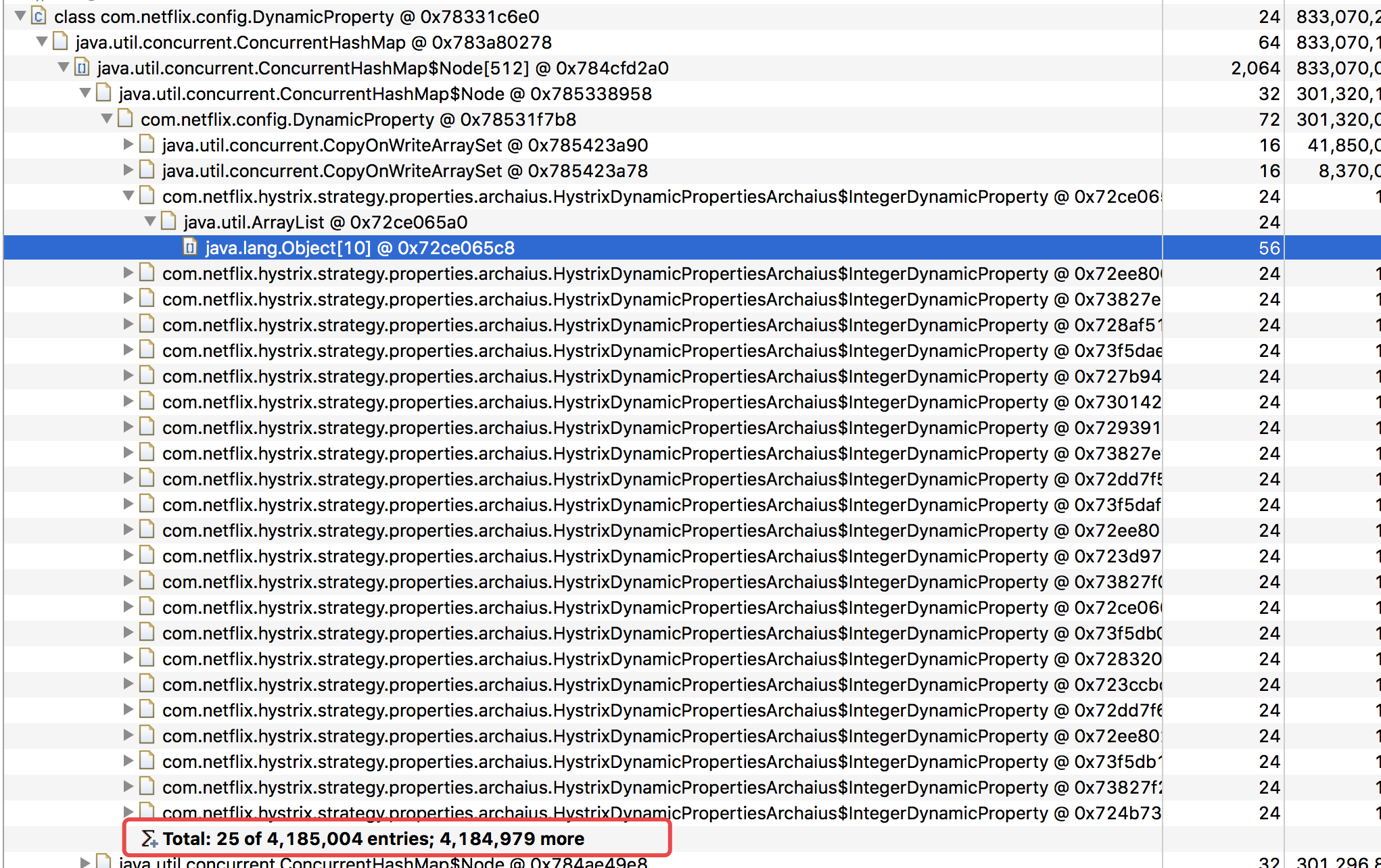
还没找到原因。
MemoryAnalyzer.exe-vmargs -Xmx4g
打开MAT时候指定最大内存。
三.In Conclusion
如果除去以上两种,系统响应慢还有一个,就是Linux IO问题。这个不常遇到,但是一个中间件的熟人在做RocketMQ搭建的时候,我体验到了这种差别。(首先IO同步异步会有TPS的差别,cache和零拷贝又有区别)我并不精通,所以不再总结。
日常的业务系统,如果不是业务正常引起的,最主要排查的是内存溢出以及不正常的Runnable引起的CPU过高。搞定这两个,就可以了。
JVM常用指标查询的更多相关文章
- JVM调优系列:(五)JVM常用调试参数和工具
转自:http://blog.csdn.net/opensure/article/details/46715769 JVM常用调试参数: –verbose:gc在虚拟机发生内存回收时在输出设备显示信息 ...
- 深入理解JVM虚拟机10:JVM常用参数以及调优实践
转自http://www.rowkey.me/blog/2016/11/02/java-profile/?hmsr=toutiao.io&utm_medium=toutiao.io&u ...
- Prometheus监控node-exporter常用指标含义
一.说明 最近使用Prometheus新搭建监控系统时候发现内存采集时centos6和centos7下内存监控指标采集计算公式不相同,最后采用统一计算方法并整理计算公式如下: 1 100-(node_ ...
- MySQL常用的查询命令
MySQL常用的查询命令 author: headsen chen 2017-10-19 10:15:25 个人原创.转载请注明作者,出处,否则依法追究法律责任 1,查询现在的时间:mysql& ...
- mysql常用快速查询修改操作
mysql常用快速查询修改操作 一.查找并修改非innodb引擎为innodb引擎 # 通用操作 mysql> select concat('alter table ',table_schema ...
- neo4j 常用命令查询,以及更新 节点 的 label 名 和 property 名
常用命令查询 https://neo4j.com/docs/cypher-refcard/current/ 更新节点的 labels 有时候 发现节点的 label 名字起错了怎么修改呢?!一个节点是 ...
- JVM常用启动参数+常用内存调试工具
一.JVM常用启动参数 -Xms:设置堆的最小值. -Xmx:设置堆的最大值. -Xmn:设置新生代的大小. -Xss:设置每个线程的栈大小. -XX:NewSize:设置新生代的初始值. -XX:M ...
- HTML常用标签查询
JAVA开发避免不了要接触前端,所以我不得不从0开始学习前端内容!下面分享我自己总结的HTML常用标签查询代码:将下面代码复制粘贴到文本文档,然后另存为html格式;通过file:///文档保存路径的 ...
- 评价PE基金绩效的常用指标
作为信息系统,辅助管理层决策是重要的功能之一.前文介绍了PE基金管理系统的建设,对PE业务的运转有了一些了解,但没有介绍如何评价PE基金的绩效,而这是管理层作出重大决策的主要依据之一.PE基金本质也是 ...
随机推荐
- 提升键盘可访问性和AT可访问性
概述 很多地方比如官网中需要提升 html 的可访问性,我参考 element-ui,总结了一套提升可访问性的方案,记录下来,供以后开发时参考,相信对其他人也有用. 可访问性 可访问性基本上分为 2 ...
- 阶段3 3.SpringMVC·_07.SSM整合案例_08.ssm整合之Spring整合MyBatis框架
service能供成功的调用到service对象就算是整合成功 如果能把生成的代理对象也存大IOC的容器中.那么ServiceImpl就可以拿到这个对象 做一个注入,然后就可以调用代理对象的查询数据库 ...
- jdk 1.8中的list排序
首先看看collections实现 public static <T> void sort(List<T> list, Comparator<? super T> ...
- Client Dimensions , offsetHeight , scrollTop 属性详解
http://stackoverflow.com/questions/22675126/what-is-offsetheight-clientheight-scrollheight http://ww ...
- 第一个python-ui界面
首先是安装eric6简直是个灾难,先是找不到汉化版的eric6,好不容易找到了,一打开eric6的窗体就说designer.exe不存在,确实在PyQt5里没有,明明在PyQt5-tools里面有,最 ...
- .net代码混淆 .NET Reactor 研究 脚本一键混淆一键发布
.net代码混淆 .NET Reactor 研究 为什么要混淆? .net比较适合快速开发桌面型应用,但缺点是发布出来的文件是可以反编译的,有时候为了客户的安全,我们的代码或者我们的逻辑不想让别人知道 ...
- 【Linux开发】linux设备驱动归纳总结(三):6.poll和sellct
linux设备驱动归纳总结(三):6.poll和sellct xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx ...
- MSF魔鬼训练营-3.3.2 口令猜测与嗅探
密码暴力破解以SSH为例,其他协议方法类似 SSH msf > use auxiliary/scanner/ssh/ssh_login msf auxiliary(ssh_login) ...
- 【转贴】GS464/GS464E
GS464/GS464E GS464为四发射64位结构,采用动态流水线.其1.0版本(简称GS464)为9级流水线结构,在龙芯3A.3B.2H中使用.其2.0版本(简称GS464E)为12级动态流水线 ...
- plpython 中文分词Windows 版
windows 下安装版本匹配python-3.4.3.amd64.msipostgresql-10.1-2-windows-x64.exe create language plpython3u;se ...