scrapy-redis 实现分布式爬虫
分布式爬虫
一 介绍
原来scrapy的Scheduler维护的是本机的任务队列(存放Request对象及其回调函数等信息)+本机的去重队列(存放访问过的url地址)

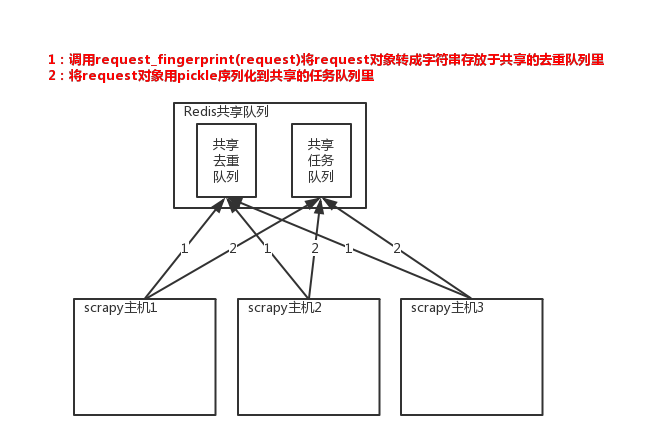
所以实现分布式爬取的关键就是,找一台专门的主机上运行一个共享的队列比如Redis,
然后重写Scrapy的Scheduler,让新的Scheduler到共享队列存取Request,并且去除重复的Request请求,所以总结下来,实现分布式的关键就是三点:
#1、共享队列
#2、重写Scheduler,让其无论是去重还是任务都去访问共享队列
#3、为Scheduler定制去重规则(利用redis的集合类型)
以上三点便是scrapy-redis组件的核心功能
#安装:
pip3 install scrapy-redis #源码:
D:\python3.6\Lib\site-packages\scrapy_redis
二、scrapy-redis组件
1、只使用scrapy-redis的去重功能


#一、源码:D:\python3.6\Lib\site-packages\scrapy_redis\dupefilter.py #二、配置scrapy使用redis提供的共享去重队列 #2.1 在settings.py中配置链接Redis
REDIS_HOST = 'localhost' # 主机名
REDIS_PORT = 6379 # 端口
REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)
REDIS_PARAMS = {} # Redis连接参数
REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块
REDIS_ENCODING = "utf-8" # redis编码类型
# 默认配置:D:\python3.6\Lib\site-packages\scrapy_redis\defaults.py #2.2 让scrapy使用共享的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#使用scrapy-redis提供的去重功能,查看源码会发现是基于Redis的集合实现的 #2.3、需要指定Redis中集合的key名,key=存放不重复Request字符串的集合
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
#源码:dupefilter.py内一行代码key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())} #2.4、去重规则源码分析dupefilter.py
def request_seen(self, request):
"""Returns True if request was already seen. ```
Parameters
----------
request : scrapy.http.Request Returns
-------
bool """
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
added = self.server.sadd(self.key, fp)
return added == 0
``` #2.5、将request请求转成一串字符后再存入集合 from scrapy.http import Request
from scrapy.utils.request import request_fingerprint req = Request(url='http://www.baidu.com')
result=request_fingerprint(req)
print(result) #75d6587d87b3f4f3aa574b33dbd69ceeb9eafe7b #2.6、注意:
- URL参数位置不同时,计算结果一致;
- 默认请求头不在计算范围,include_headers可以设置指定请求头
- 示范:
from scrapy.utils import request
from scrapy.http import Request ```
req = Request(url='http://www.baidu.com?name=8&id=1',callback=lambda x:print(x),cookies={'k1':'vvvvv'})
result1 = request.request_fingerprint(req,include_headers=['cookies',]) print(result) req = Request(url='http://www.baidu.com?id=1&name=8',callback=lambda x:print(x),cookies={'k1':666}) result2 = request.request_fingerprint(req,include_headers=['cookies',]) print(result1 == result2) #True
```
使用共享去重队列+源码分析
2、使用scrapy-redis的去重+调度实现分布式爬取
#1、源码:D:\python3.6\Lib\site-packages\scrapy_redis\scheduler.py #2、settings.py配置 # Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器将不重复的任务用pickle序列化后放入共享任务队列,默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 对保存到redis中的request对象进行序列化,默认使用pickle
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 调度器中请求任务序列化后存放在redis中的key
SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_PERSIST = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
SCHEDULER_FLUSH_ON_START = False # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。如果没有则立刻返回会造成空循环次数过多,cpu占用率飙升
SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去重规则,在redis中保存时对应的key
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则对应处理的类,将任务request_fingerprint(request)得到的字符串放入去重队列
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
3、持久化
#从目标站点获取并解析出数据后保存成item对象,会由引擎交给pipeline进行持久化/保存到数据库,scrapy-redis提供了一个pipeline组件,可以帮我们把item存到redis中 #1、将item持久化到redis时,指定key和序列化函数
REDIS_ITEMS_KEY = '%(spider)s:items'
REDIS_ITEMS_SERIALIZER = 'json.dumps' #2、使用列表保存item数据
4、从Redis中获取起始URL
scrapy程序爬取目标站点,一旦爬取完毕后就结束了,如果目标站点更新内容了,我们想重新爬取,那么只能再重新启动scrapy,非常麻烦
scrapy-redis提供了一种供,让scrapy从redis中获取起始url,如果没有scrapy则过一段时间再来取而不会关闭
这样我们就只需要写一个简单的脚本程序,定期往redis队列里放入一个起始url。 #具体配置如下 #1、编写爬虫时,起始URL从redis的Key中获取
REDIS_START_URLS_KEY = '%(name)s:start_urls' #2、获取起始URL时,去集合中获取还是去列表中获取?True,集合;False,列表
REDIS_START_URLS_AS_SET = False # 获取起始URL时,如果为True,则使用self.server.spop;如果为False,则使用self.server.lpop
# lpush cnblogs:start_urls https://www.cnblogs.com 》》》 我们启动的是redis 中的url
scrapy-redis 实现分布式爬虫的更多相关文章
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- scrapy如何实现分布式爬虫
使用scrapy爬虫的时候,记录一下如何分布式爬虫问题: 关键在于多台主机协作的关键:共享爬虫队列 主机:维护爬取队列从机:负责数据抓取,数据处理,数据存储 队列如何维护:Redis队列Redis 非 ...
- scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置
scrapy——7 什么是scrapy-redis 怎么安装scrapy-redis scrapy-redis常用配置文件 scrapy-redis键名介绍 实战-利用scrapy-redis分布式爬 ...
- 阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请 ...
- 基于scrapy框架的分布式爬虫
分布式 概念:可以使用多台电脑组件一个分布式机群,让其执行同一组程序,对同一组网络资源进行联合爬取. 原生的scrapy是无法实现分布式 调度器无法被共享 管道无法被共享 基于 scrapy+redi ...
- 在阿里云Centos7.6上面部署基于Redis的分布式爬虫Scrapy-Redis
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_83 Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的 ...
- Python36 使用Redis 构建分布式爬虫(未完)
很长时间未更新了,人懒了. 最近有不少的东西,慢慢写吧,最近尝试了一下python 使用Redis 来构建分布式爬虫: 单体爬虫有很多缺点,但是在学习过程中能够学习爬虫的基本理念与运行模式,在后期构建 ...
- Scrapy 教程(八)-分布式爬虫
scrapy 本身并不是一个分布式框架,而 Scrapy-redis 库使得分布式成为可能: Scrapy-redis 并没有重构框架,而是基于redis数据库重写了框架的某些组件. 分布式框架要解决 ...
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码 scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开 ...
随机推荐
- LC 499. The Maze III 【lock,hard】
There is a ball in a maze with empty spaces and walls. The ball can go through empty spaces by rolli ...
- php文件上传系统
一般10M以下的文件上传通过设置Web.Config,再用VS自带的FileUpload控件就可以了,但是如果要上传100M甚至1G的文件就不能这样上传了.我这里分享一下我自己开发的一套大文件上传控件 ...
- Eclipse MAT和jvisualvm分析内存溢出
---------------------------------------------mac os版------------------------------------------------ ...
- springboot后端实现条件查询,要配合使用mybatis
package cn.com.dyg.work.sqlgen; import cn.com.dyg.work.common.exception.DefException; import cn.com. ...
- pytorch中的激励函数(详细版)
初学神经网络和pytorch,这里参考大佬资料来总结一下有哪些激活函数和损失函数(pytorch表示) 首先pytorch初始化: import torch import t ...
- 【AMAD】django-extensions -- Django框架的自定义命令扩展集合
动机 简介 个人评分 动机 使用Django进行开发的时候,会不会感觉开发工具少了一些.比如每次进入python shell调试的时候要重新import每个model. 简介 django-exten ...
- Linux C/C++基础——二级指针做形参
1.二级指针做形参 #include<stdio.h> #include<stdlib.h> void fun(int **temp) { *temp=(int*)malloc ...
- 华为HCNA乱学Round 7:VLAN间路由
- pypy3.6的下载地址和安装第三方依赖
1.不同版本的下载链接 建议使用此链接:https://bitbucket.org/pypy/pypy/downloads/ 官网的:http://doc.pypy.org/en/latest/rel ...
- 【C/C++】什么是线程安全
<strong>线程安全</strong>就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用.不 ...