【转】float与double的范围和精度
原文:http://blog.csdn.net/wuna66320/article/details/1691734
1 范围
float和double的范围是由指数的位数来决定的。
float的指数位有8位,而double的指数位有11位,分布如下:
float:
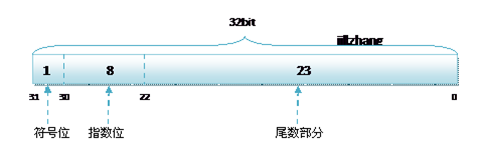
1bit(符号位)
8bits(指数位)
23bits(尾数位)
double:
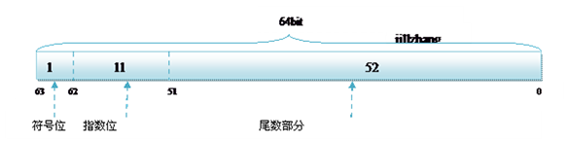
1bit(符号位)
11bits(指数位)
52bits(尾数位)
在数学中,特别是在计算机相关的数字(浮点数)问题的表述中,有一个基本表达法[1]:
value of floating-point = significand x base ^ exponent , with sign --- F.1
译为中文表达即为:
(浮点)数值 = 尾数 × 底数 ^ 指数,(附加正负号)---------------- F.2
于是,float的指数范围为-127~128,而double的指数范围为-1023~1024,并且指数位是按补码的形式来划分的。其中负指数决定了浮点数所能表达的绝对值最小的数;而正指数决定了浮点数所能表达的绝对值最大的数,也即决定了浮点数的取值范围。
float的范围为-2^128 ~ +2^128,也即-3.40E+38 ~ +3.40E+38;double的范围为-2^1024 ~ +2^1024,也即-1.79E+308 ~ +1.79E+308。
2 精度
float和double的精度是由尾数的位数来决定的。浮点数在内存中是按科学计数法来存储的,其整数部分始终是一个隐含着的“1”,由于它是不变的,故不能对精度造成影响。
float:2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字;
double:2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。
单精度类型(float)和双精度类型(double)存储
2009-11-24 13:57
C 语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范 的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
而双精度的存储方式为:
R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*100,而120.5可以表示为:1.205*102, 这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数 法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用 二进制的科学计数法表示1000.01可以表示为1.0001*23,1110110.1可以表示为1.1101101*26,任何一个数都的科学计数法表示都为1.xxx*2n, 尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了 24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点, 24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以 指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
首先看下8.25,用二进制的科学计数法表示为:1.0001*23
按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示:
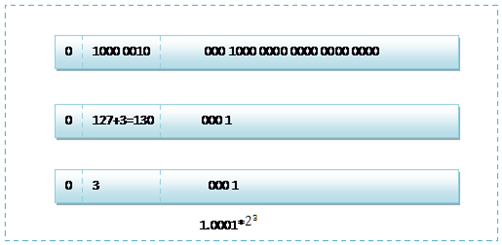
而单精度浮点数120.5的存储方式如下图所示:
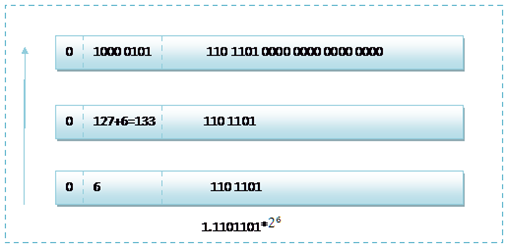
那 么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存 数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:

根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101*26=120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的

下面我就这个基础知识点来解决一个我们的一个疑惑,请看下面一段程序,注意观察输出结果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可 能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的 2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两 种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0 100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数 的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2= 1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列 00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:

但 是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数 据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如 2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
【转】float与double的范围和精度的更多相关文章
- java float与double的范围和精度
float与double的范围和精度 1. 范围 float和double的范围是由指数的位数来决定的. float的指数位有8位,而double的指数位有11位,分布如下: float: 1 ...
- float,double和decimal的精度问题
先标注一个音标,因为我老是读错:decimal ['desɪml] 精度对比: 类型 CTS 类型 描述 有效数字 范围 float System.Single 32-bit single-preci ...
- float与double的范围和精度(摘录)
什么是浮点数在计算机系统的发展过程中,曾经提出过多种方法表达实数.典型的比如相对于浮点数的定点数(Fixed Point Number).在这种表达方式中,小数点固定的位于实数所有数字中间的某个位置. ...
- float与double的范围和精度以及大小非零比较
1. 范围 float和double的范围是由指数的位数来决定的. float的指数位有8位,而double的指数位有11位,分布如下: float: 1bit(符号位) 8bits(指数位) ...
- float与double的范围和精度
1. 范围 float和double的范围是由指数的位数来决定的. float的指数位有8位,而double的指数位有11位,分布如下: float: 1bit(符号位) 8bits(指数位 ...
- 浮点型 float和double类型的内存结构和精度问题
首先引用一个例子在java中可能你会遇到这样的问题: 例:0.99999999f==1f //true 0.9999999f==1f //false 这是超出精度造成的,为了知道为什么会造成这样的问题 ...
- 关于float与double
//float与double的范围和精度 1. 范围 float和double的范围是由指数的位数来决定的. // float的指数位有8位,而double的指数位有11位,分布如下:// float ...
- Char、float、Double、BigDecimal
Char初识 char: char类型是一个单一的 16 位 Unicode 字符 char 在java中是2个字节("字节"是byte,"位"是bit ,1 ...
- float和double的精度
作者: jillzhang 联系方式:jillzhang@126.com 原网址:http://blog.csdn.net/wuna66320/article/details/1691734 1 范围 ...
随机推荐
- zabbix通过SDK和API获取阿里云RDS的监控数据
阿里云的RDS自带的监控系统获取数据不怎么直观,想要通过API获取数据通过zabbix显示,因为网上资料缺乏和其他一些原因,获取API签名很困难,但使用阿里云的SDK可以完美避开获取签名的步骤. 阿里 ...
- Mybatis高级结果映射
有时侯,我们用SQL取得的结果需要映射到类似Map<key, Bean>这样的数据结构中或是映射到多个实体类中时,我们就需要使用到resultMap.下面用3个例子说明Mybatis高级结 ...
- 二叉树实例学习(四)——获取节点的高度函数getHight()
树T中所有节点深度的最大值称为该树的高度(height),实际上每个节点与其所有子节点都可以看做一颗树,也就是说除了根结点,所有子结点都可以看做是一颗子树,因此每个结点都有树高.在本程序中约定,仅含单 ...
- Vuex模块:开启命名空间
模块开启命名空间后,享有独自的命名空间. { "模块1":{ state:{}, getters:{}, mutations:{}, actions:{} }, "模块2 ...
- 【VS开发】【计算机视觉】OpenCV读写xml文件《C++版本》
OpenCV FileStorage类读写XML/YML文件 在OpenCV程序中,需要保存中间结果的时候常常会使用.xml / .yml文件,opencv2.0之前都是使用C风格的代码,当时读写XM ...
- 【Matlab开发】MATLAB编译C/C++代码
在使用MATLAB编译C/C++代码时,C/C++代码中要使用一个mexFunction函数,那么这个函数是如何定义,在编译时又是如何实现的呢?下面我将使用实例进行说明. 如一个简单的函数: doub ...
- 随笔--第一次使用crontab linux选择编辑器问题
第一次使用crontab 时,会出现:no crontab for root - using an empty one “Select a editor ......”下面有几个选项,就是叫你选择编辑 ...
- SQL Server 下载与安装
1.首先去Microsoft官网下载对应的安装程序,下载地址:https://www.microsoft.com/zh-cn/sql-server/sql-server-downloads 2.运行安 ...
- 通过模板创建一个ABP项目
⒈下载 进入ABP模板页面,选择模板后下载 ⒉运行 1.初始化数据库 修改xxxx.Migrator.xxxx.Web.Host appsettings.json中的连接字符串 2.还原数据库 在Nu ...
- centerOS7安装lnmp环境
视频地址: https://www.bilibili.com/video/av55251610?p=65 安装nginx http://nginx.org 点击 download vim /etc/y ...