【Robot Framework 项目实战 02】使用脚本生成统一格式的RF关键字
背景
在微服务化的调用环境下,测试数据及接口依赖的维护是一个问题,因为依赖的接口和数据可能不在同一个服务下,而这相关的多个服务往往是不同人员来测试的。
因此为了节省沟通成本,避免关键字的重复冗余。所以我们在RF框架推广之初就确定了接口关键字统一管理的基调,方便不同服务之间的调用。
脚本介绍
中间数据Excel
为了让关键字的格式统一,我们每一个业务线使用同一个关键字数据生成脚本,小伙伴们通过维护Excel来维护接口关键字。
被维护的Excel内容如下:
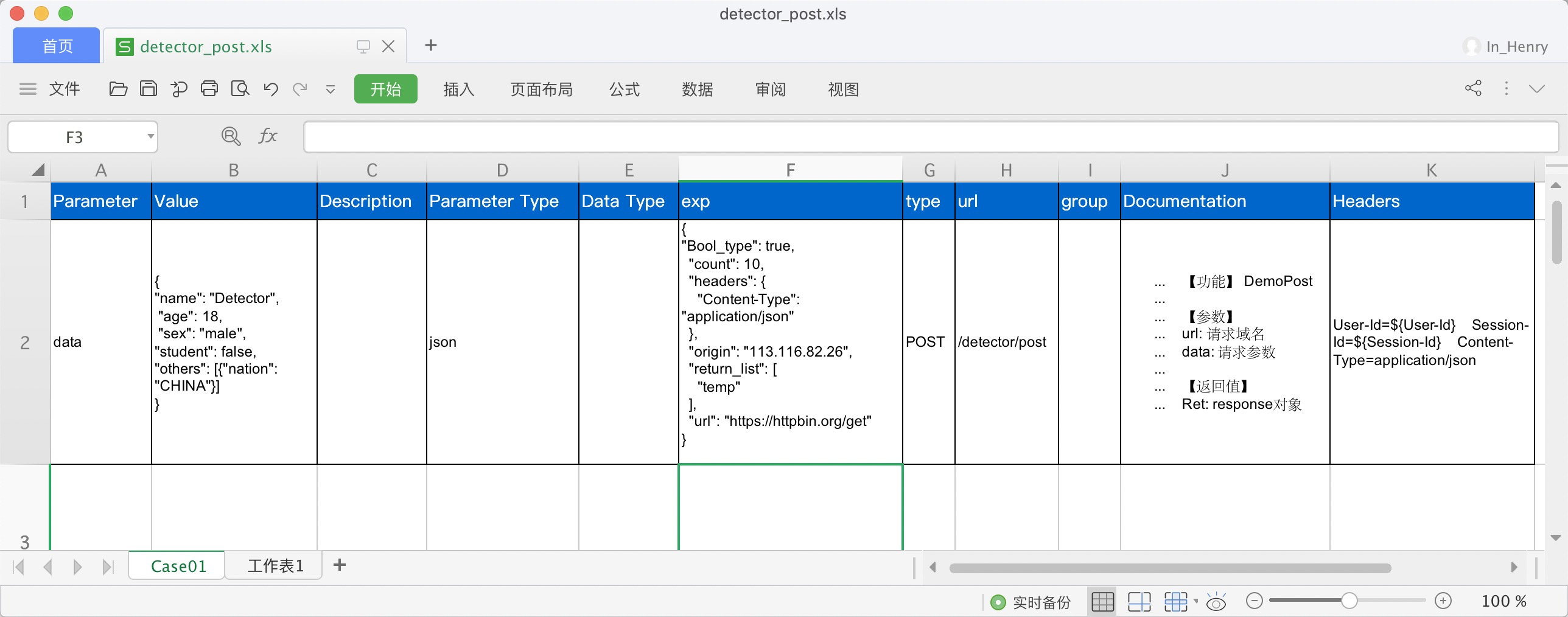
Excel文件名称规则: 为接口服务名称和path的组合,
Excel文件内容规则: 接口传递参数类型,请求参数,请求方式,path路径,预期返回,接口headers及接口描述等信息。
初期,关键字的生成由一人统一管理,发送数据及预期结果,主要用于检测数据
对应生成的关键字如下:
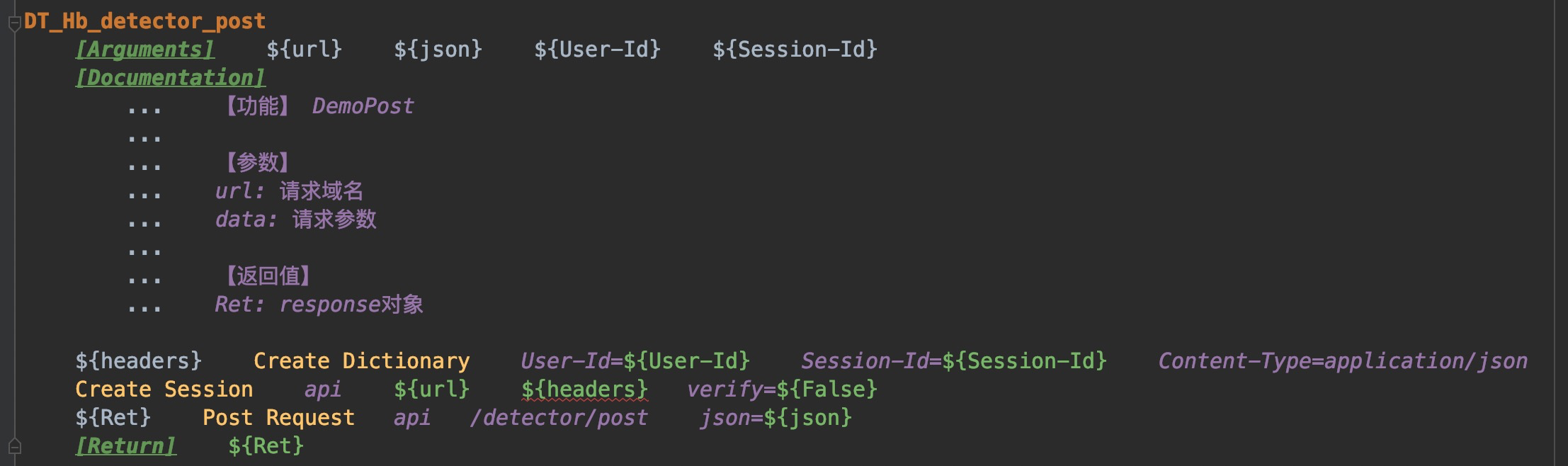
注:Excel中的Path及headers中存在${}时,关键字会将其作为传入参数
关键字命名规则: 公司代号_流水线(项目组)代号_服务名称_接口path(path相同时以请求方式区分)
完整脚本
具体的脚本较为简单: apitest/Common/Testscript/common/gen_rf_kw.py
#! /usr/bin/python
# coding:utf-8
"""
@author:Bingo.he
@file: gen_common_kw.py
@time: 2019/01/01
"""
import os
import re
from apitest.Common.Testscript.utils.logger import logger
from apitest.Common.Testscript.utils.operate_xls import OperateXls
class GenRFkw:
def __init__(self, xls_folder, demo_case_folder):
self.xls_folder = xls_folder
self.target_case_folder = demo_case_folder
@staticmethod
def kw_requests_init(target_robot_name):
with open(target_robot_name, 'a') as f:
f.write('*** Settings ***' + '\n')
f.write('Library TestLibrary' + '\n')
f.write('Library RequestsLibrary' + '\n')
f.write('\n')
f.write('*** Keywords ***' + '\n')
@staticmethod
def gen_kw(target_robot_name, param_type, req_method, url, document, headers, msg_type):
if param_type == "json" or param_type == "data":
# param_type = "data"
param_type = "json"
with open(target_robot_name, 'a', encoding="utf-8") as f:
f.write(' [Arguments] ${url}')
f.write(' ${' + param_type + '}')
# 允许url中传递可变参数
if "${" in url:
p = re.compile(r'{(.*?)}')
verify_urls = p.findall(url)
for verify_url in verify_urls:
f.write(" ${{{}}}".format(verify_url))
# 允许headers中传递可变参数
if "${" in headers:
sprint_str = headers
p = re.compile(r'{(.*?)}')
sprint_num = p.findall(sprint_str)
for s in sprint_num:
f.write(" ${{{}}}".format(s))
f.write('\n')
f.write(' [Documentation] ' + document + '\n')
# 兼容form-data请求
if "multipart/form-data" == msg_type:
f.write(' ${boundary}= xl boundary parse ${data}' + '\n')
f.write(' ${headers} Create Dictionary ' + headers + '\n')
f.write(' Create Session api ${url} ${headers} verify=${False}' + '\n')
if '' != param_type.strip(): # 接口输入参数个数不为零
if req_method.upper() == 'GET' or req_method.upper() == 'DELETE':
f.write(' ${{Ret}} {} Request api '.format(req_method.capitalize()) + url)
f.write('${' + param_type + '}') # 发送GET请求,直接把EXCEL中读取出来的参数连接到URL后面
f.write('\n')
else:
f.write(' ${{Ret}} {} Request api '.format(req_method.capitalize()) + url)
f.write(' ' + param_type + '=${' + param_type + '}')
f.write('\n')
f.write(' [Return] ${Ret}' + '\n')
f.write('\n')
@staticmethod
def find_file_name(file_dir):
files = None
for root, dirs, files in os.walk(file_dir):
logger.info("当前目录路径" + root) # 当前目录路径
logger.info("当前路径下所有子目录" + str(dirs)) # 当前路径下所有子目录
logger.info("当前路径下所有非目录子文件" + str(files)) # 当前路径下所有非目录子文件
files = [file for file in files if ".xls" in file]
# 按照顺序排序
files.sort()
return files
@staticmethod
def interface_name(kw_excel):
return kw_excel.split(".")[0]
def run(self, **kwargs):
xls_files = self.find_file_name(self.xls_folder)
target_robot_name = os.path.join(self.target_case_folder, "DT_Hb_kwRequests.robot")
if os.path.exists(target_robot_name):
os.remove(target_robot_name)
self.kw_requests_init(target_robot_name)
for xls_file in xls_files:
interface_name = self.interface_name(xls_file)
with open(target_robot_name, 'a') as f:
f.write('DT_Hb_' + interface_name + '\n')
book = OperateXls(os.path.join(self.xls_folder, xls_file), index=0)
param_type = book.rf_xls_msg_type()
# param = book.rf_xls_param_value()
decode_type = book.rf_xls_msg_type()
url = book.rf_xls_url()
document = book.rf_xls_document()
headers = book.rf_xls_headers()
method = book.rf_xls_method()
self.gen_kw(target_robot_name, param_type, method, url, document, headers, decode_type)
依赖脚本: apitest/Common/Testscript/utils/operate_xls.py
#! /usr/bin/python
# coding:utf-8
"""
@author:Bingo.he
@file: operate_xls.py
@time: 2019/01/01
"""
import xlrd
from apitest.Common.Testscript.utils.logger import logger
class OperateXls:
def __init__(self, xls_ile, index):
self.book = xlrd.open_workbook(xls_ile, encoding_override='utf-8')
self.sheet = self.book.sheet_by_index(index) # 通过sheet索引获得sheet对象
def switch_sheet_index(self, count):
"""
通过index切换sheet对象
:param count:
:return:
"""
self.sheet = self.book.sheet_by_index(count)
def switch_sheet_by_name(self, sheet_name):
"""
通过sheet name 切换 sheet对象
:param sheet_name:
:return:
"""
self.sheet = self.book.sheet_by_name(sheet_name)
def sheet_name_by_index(self, count):
return self.book.sheet_names()[count] # 获得指定索引的sheet表名字
def get_value(self, rowx, colx):
return self.sheet.cell_value(rowx, colx)
def sheet_params_by_name(self, sheet_name):
"""
返回sheet页所有数据
:param sheet_name:
:return: sheet data format: {row_num:[data of column1,data of column2....]}
"""
all_data = {}
row_data = []
sheet = self.book.sheet_by_name(sheet_name) # 通过sheet名字来获取
row_num = sheet.nrows # 获取行总数
cols_num = sheet.ncols # 获取行总数
logger.info("有效数据行数: " + str(row_num))
logger.info("有效数据列数: :" + str(cols_num))
for i in range(0, row_num):
for c in range(cols_num):
row_data.append(sheet.cell_value(i, c)) # 获取指定EXCEL文件中,第一个SHEET中的接口字段名
all_data[i] = row_data
row_data = []
# logger.info(str(json.dumps(all_data, indent=4)))
logger.info(str(all_data))
return all_data
def sheet_params_by_index(self, index):
"""
返回sheet页所有数据
:param index:
:return: sheet data format: {row_num:[data of column1,data of column2....]}
"""
all_data = {}
row_data = []
sheet = self.book.sheet_by_index(index) # 通过sheet名字来获取
row_num = sheet.nrows # 获取行总数
cols_num = sheet.ncols # 获取行总数
logger.info("有效数据行数: " + str(row_num))
logger.info("有效数据列数: :" + str(cols_num))
for i in range(0, row_num):
for c in range(cols_num):
row_data.append(sheet.cell_value(i, c)) # 获取指定EXCEL文件中,第一个SHEET中的接口字段名
all_data[i] = row_data
row_data = []
# logger.info(str(json.dumps(all_data, indent=4)))
logger.info(str(all_data))
return all_data
class ReadRFExcel(OperateXls):
def rf_xls_param_type(self):
return self.get_value(1, 0) # 获取'B2'字段内容
def rf_xls_param_value(self):
return self.get_value(1, 1) # 获取'B2'字段内容
def rf_xls_msg_type(self):
return self.get_value(1, 3) # 获取'D2'字段内容
def rf_xls_method(self):
return self.get_value(1, 6) # 获取'G2'字段内容
def rf_xls_url(self):
return self.get_value(1, 7) # 获取'H2'字段内容
def rf_xls_group(self):
return self.get_value(1, 8) # 获取'I2'字段内容
def rf_xls_document(self):
return self.get_value(1, 9) # 获取'J2'字段内容
def rf_xls_headers(self):
return self.get_value(1, 10) # 获取'K2'字段内容
if __name__ == '__main__':
op = ReadRFExcel("test.xls", 0)
print(op.rf_xls_headers())
op.switch_sheet_index(1)
op.rf_xls_headers()
op.sheet_params_by_index(1)
op.sheet_name_by_index(1)
【Robot Framework 项目实战 02】使用脚本生成统一格式的RF关键字的更多相关文章
- 【Robot Framework 项目实战 02】SeleniumLibrary Web UI 自动化
前言 SeleniumLibrary 是针对 Robot Framework 开发的 Selenium 库.它也 Robot Framework 下面最流程的库之一.主要用于编写 Web UI 自动化 ...
- 【Robot Framework 项目实战 03】使用脚本自动生成统一格式的RF自动化用例
背景 虽然大家都已经使用了统一的关键字,但是在检查了一些测试用例之后,还是发现因为大家对RF的熟悉程度不一导致的测试用例颗粒度差异很大的情况:而且在手动方式转化测试用例过程中,有不少工作是完全重复的且 ...
- 【Robot Framework 项目实战 00】环境搭建
前言 我们公司在推广RF这个框架做后端接口测试,力求让同事们能更快的完成服务端需求的自动化,作为主导者之一,决定分享一些经验,方便后来者. 我会从安装部署.Request.selenium.自定义框架 ...
- 【Robot Framework 项目实战 01】使用 RequestsLibrary 进行接口测试
写在前面 本文我们一起来学习如何使用Robot Framework 的RequestsLibrary库,涉及POST.GET接口测试,RF用例分层封装设计等内容. 接口 接口测试是我们最常见的测试类型 ...
- 【Robot Framework 项目实战 04】基于录制,生成RF关键字及 自动化用例
背景 因为服务的迁移,Jira版本的更新,很多接口文档的维护变少,导致想要编写部分服务的自动化测试变得尤为麻烦,很多服务,尤其是客户端接口需要通过抓包的方式查询参数来编写自动化用例,但是过程中手工重复 ...
- SDKStyle的Framework项目使用旧版项目文件生成的Nuget包遇到的问题
随笔-2021-11-10 SDKStyle的Framework项目使用旧版项目文件生成的Nuget包遇到的问题 简介 C#从NetCore之后使用了新版的项目文件,SDK-Style项目,新版本的项 ...
- 【SSH项目实战三】脚本密钥的批量分发与执行
[SSH项目实战]脚本密钥的批量分发与执行 标签(空格分隔): Linux服务搭建-陈思齐 ---本教学笔记是本人学习和工作生涯中的摘记整理而成,此为初稿(尚有诸多不完善之处),为原创作品,允许转载, ...
- Robot Framework测试框架用例脚本设计方法
Robot Framework介绍 Robot Framework是一个通用的关键字驱动自动化测试框架.测试用例以HTML,纯文本或TSV(制表符分隔的一系列值)文件存储.通过测试库中实现的关键字驱动 ...
- Robot Framework 项目搭建
首先新建一个项目“RobotDemo".项目Type一般选择“Directory”形式. 项目第一层可以放3种文件:Test Suite.Directory 和 Resource File. ...
随机推荐
- 初学java1 数据类型
java数据类型 分为8种 整型 byte 8位 short 16位 int 32位 long 64位 字符型 char 必需为单引号'' 且只能有一个字符 浮点型 float double 布尔类型 ...
- Linux 命令实战
命令登录 ssh UserName@RemoteIP ssh seemmo@192.168.0.1 统计文件.目录的数量 统计当前目录下文件数量:ls -l | grep "^- ...
- mac安装composer
推荐阅读:https://www.jianshu.com/p/edde14a67b1a 自己实际操作: 下载 composer https://getcomposer.org/download/ 下载 ...
- springboot mvc自动配置(二)注册DispatcherServlet到ServletContext
所有文章 https://www.cnblogs.com/lay2017/p/11775787.html 正文 上一篇文章中,我们看到了DispatcherServlet和DispatcherServ ...
- zlog日志函数库
在C的世界里面没有特别好的日志函数库(就像JAVA里面的的log4j,或者C++的log4cxx).C程序员都喜欢用自己的轮子.printf就是个挺好的轮子,但没办法通过配置改变日志的格式或者输出文件 ...
- Vue粒子特效(vue-particles插件)
` npm install vue-particles --save-dev ` ` import VueParticles from 'vue-particles' Vue.use(VueParti ...
- tornado基本使用一
一.tornado web程序编写思路 . 创建web应用实例对象,第一个初始化参数为路由映射列表 . 定义实现路由映射列表中的handler类 . 创建服务器实例, 绑定服务器端口 . 启动当前线程 ...
- Mongodb 的ORM框架 Morphia 注解 之 @Reference
public class BlogEntry { private String title; private Date publishDate; private String body; privat ...
- linux 欢迎界面
开博第一篇文章,简单地写一篇linux欢迎界面吧 可以通过修改/etc/motd 或/etc/issue两个文件实现修改登录显示 区别:/etc/motd:( 登录成功才会显示 ) /etc/issu ...
- 机器学习(十)—聚类算法(KNN、Kmeans、密度聚类、层次聚类)
聚类算法 任务:将数据集中的样本划分成若干个通常不相交的子集,对特征空间的一种划分. 性能度量:类内相似度高,类间相似度低.两大类:1.有参考标签,外部指标:2.无参照,内部指标. 距离计算:非负性, ...