如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7
思路:
1、先选取你要爬取的电影
2、用vip解析工具解析,获取地址
3、写好脚本,下载片断
4、将片断利用电脑合成
需要的python模块:
##第一个模块不要安装,第二个模块需要安装
1、from multiprocessing import Pool
2、import requests
##模块安装方法
用windows命令行终端
pip install requests
一、先选取你要爬的电影,本例随便找了个VIP电影,复制地址
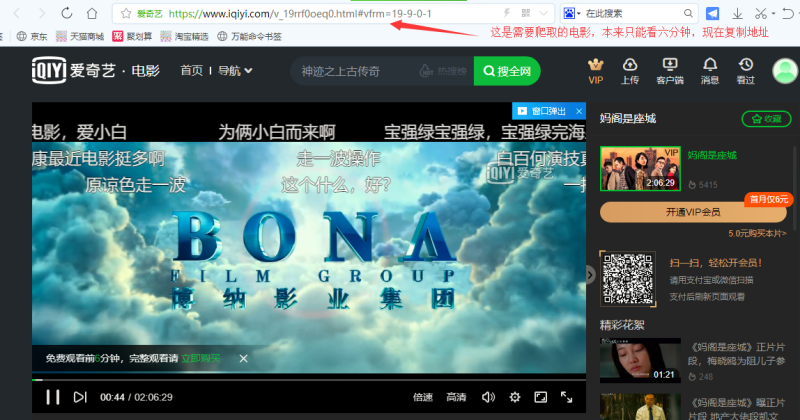
二、用vip解析工具解析,获取地址
(一)进行上网搜索,点击VIP解析
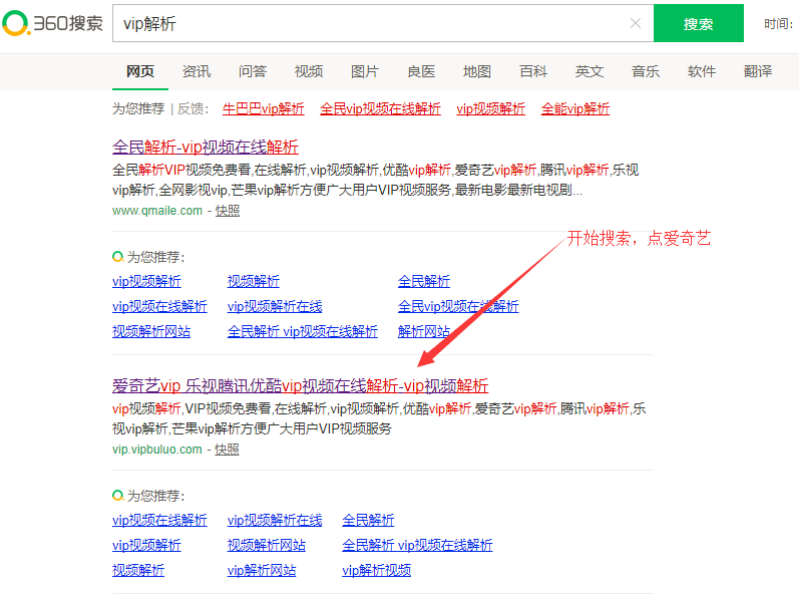
(二)、粘贴电影地址,点击播放

(三)、按下F12或者右击点检查,进入开发者工具界面,点击网络,复制地址
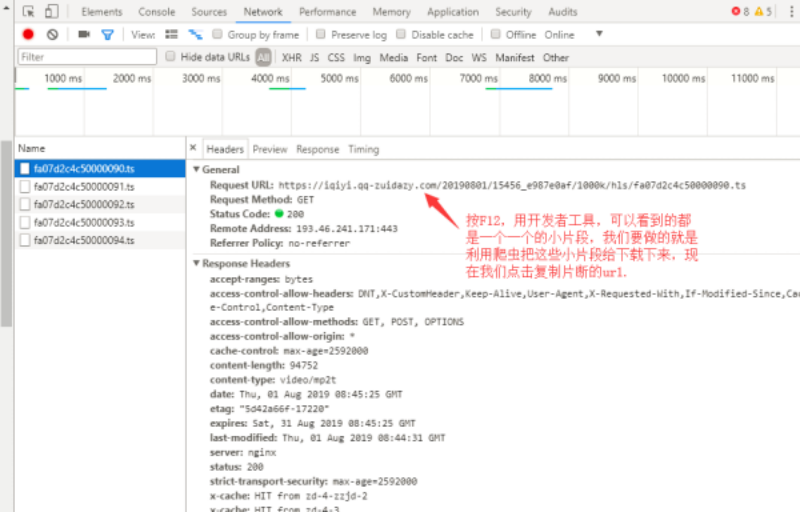
三、写好脚本,利用爬虫下载片断
##描述:该脚本目前适合下载爱奇艺,腾迅视频VIP视频
##作者:小刘
##电话:有事请写评论
##注意:只适全python爬虫的学习者,不适合专门去看电影的爱好者
##导入的两个模块,其中requests模块需要自行下载
from multiprocessing import Pool
import requests
##定义一个涵数
def demo(i):
##定义了一个url,后面%3d就是截取后面三位给他加0,以防止i的参数是1的时候参数对不上号,所以是1的时候就变成了001
url="https://vip.okokbo.com/20180114/ArVcZXQd/1000kb/hls/phJ51837151%03d.ts"%i
##定义了请求头信息
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36"}
##构建自定义请求对象
req=requests.get(url,headers=headers)
##将文件保存在当前目录的mp4文件中,名字以url后十位数起名
with open('./mp4/ {}'.format(url[-10:]), 'wb') as f:
f.write(req.content) ##程序代码的入口
if __name__=='__main__':
##定义一个进程池,可以同时执行二十个任务,不然一个一个下载太慢
pool = Pool(20)
##执行任务的代码
for i in range(100):
pool.apply_async(demo, (i,)) pool.close()
pool.join()
四、将片断利用电脑合成
(一)、复制电影存放的路径

(二)、用进入windows命令行模式,粘贴地址
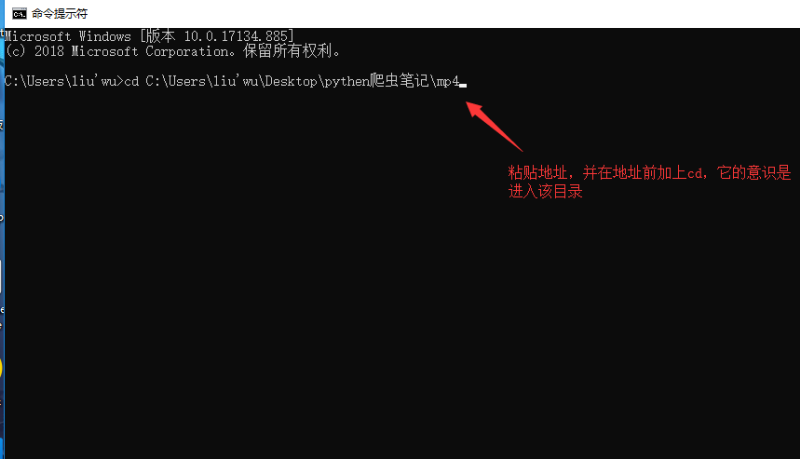
(三)、复制该目录下所有以*.ts结尾的文件,复制成一个文件

(四)、进行合并
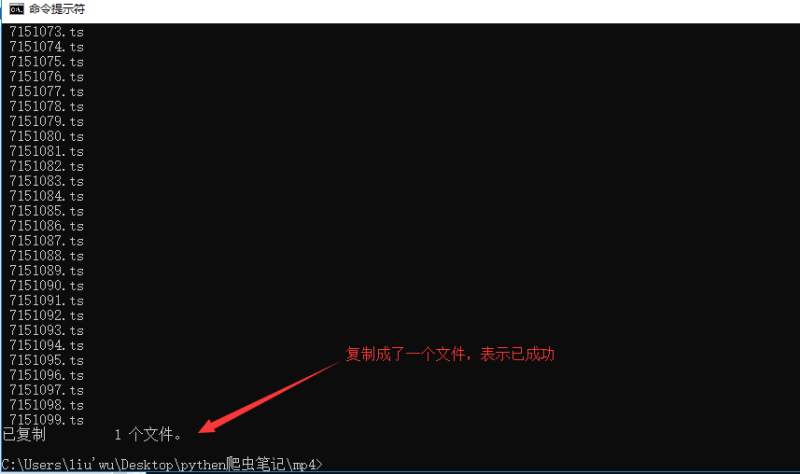
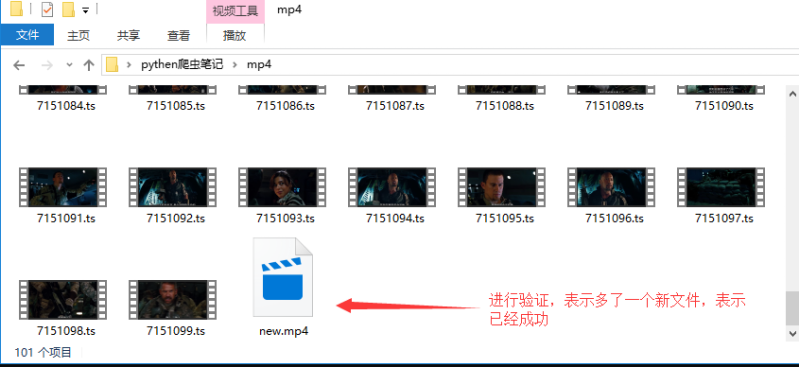
(五)、进行验证
(
五、有疑问请留言
如何利用python爬虫爬取爱奇艺VIP电影?的更多相关文章
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- 使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息 转载请注明出处. 爬取目标:每个电影的评分.名称.时长.主演.和类型 爬取思路: 源文件:(有注释) from selenium import webd ...
- Python 爬虫实例(5)—— 爬取爱奇艺视频电视剧的链接(2017-06-30 10:37)
1. 我们找到 爱奇艺电视剧的链接地址 http://list.iqiyi.com/www/2/-------------11-1-1-iqiyi--.html 我们点击翻页发现爱奇艺的链接是这样的 ...
- Python爬取爱奇艺资源
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素“ ...
- Python爬虫爬取BT之家找电影资源
一.写在前面 最近看新闻说圣城家园(SCG)倒了,之前BT天堂倒了,暴风影音也不行了,可以说看个电影越来越费力,国内大厂如企鹅和爱奇艺最近也出现一些幺蛾子,虽然目前版权意识虽然越来越强,但是很多资源在 ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- 利用Python爬虫爬取指定天猫店铺全店商品信息
本编博客是关于爬取天猫店铺中指定店铺的所有商品基础信息的爬虫,爬虫运行只需要输入相应店铺的域名名称即可,信息将以csv表格的形式保存,可以单店爬取也可以增加一个循环进行同时爬取. 源码展示 首先还是完 ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 爬取爱奇艺电视剧url
----因为需要顺序,所有就用串行了---- import requests from requests.exceptions import RequestException import re im ...
随机推荐
- 在ABP core中使用RabbitMq
距上一篇博客的更新一集很久了,主要是最近做的事情比较杂,中间也有一个难点,就是在ABP中加入APP扫码登录,本来想些的,但是觉得这个写出来会不会让我们的系统被破解-_-||,所以想了想,就没有写. 这 ...
- LG2467 地精部落
题意 给出\(n\),求有几个\(W\)形的\(n\)的全排列(震荡) 思路 可以变求出第二个数比第一个数大的,再翻倍就好 设\(f[i][j]\)表示\(i\)个数中\(j\)个数不符合序列 转移时 ...
- tensorflow训练中出现nan
问题暂记: 之后看 https://blog.csdn.net/qq_23142123/article/details/80526931 https://www.zhihu.com/question/ ...
- 微信小程序wxss样式详解
一.wxml 界面结构wxmL比较容易理解,主要是由八大类基础组件构成: 一.视图容器(View Container): 二.基础内容(Basic Content) 组件名 说明 组件名 说明 vie ...
- DataFactory连接MySQL数据库
1.下载驱动 https://dev.mysql.com/downloads/connector/odbc/ 需要使用oracle登录账号密码后才能下载 下载完成后进行安装,一路下一步即可 2.连接m ...
- TP5连接数据库和phpstrom连接数据库(宝塔面板数据库连接)
1.编译器:phpstrom 框架:TP5 服务器面板:宝塔面板 2.我遇到的核心问题:数据库.用户名.密码均正确但是无法连接, 使用宝塔面板的都知道phpmyadmin的端口号是888,注意注意这个 ...
- RabbitMQ 使用参考
http://www.zouyesheng.com/rabbitmq.html 安装 基本概念 基本形式 持久化 调度策略 5.1. fanout 5.2. direct 5.3. topic 5.4 ...
- 自定义zabbix脚本--网卡平均流量
自定义zabbix脚本--网卡平均流量1. 在客户端修改配置文件 /etc/zabbix/zabbix_agentd.conf需要改动两个地方:(1) UnsafeUserParameters=1(2 ...
- centos虚拟机存储扩容
在vSphere Web Client上面创建的虚拟机,用了一段时间后存储无法满足需求,需要将原来的存储300G扩容到500G 点此编辑即可修改磁盘2的储存大小,但是修改此配置后,虚拟机centos是 ...
- JSX AS DSL? 写个 Mock API 服务器看看
这几天打算写一个简单的 API Mock 服务器,老生常谈哈?其实我是想讲 JSX, Mock 服务器只是一个幌子. 我在寻找一种更简洁.方便.同时又可以灵活扩展的.和别人不太一样的方式,来定义各种 ...