kdd cup 2019
比赛简介:
任务1:推荐最佳交通方式
任务描述:给定用户的一些信息,预测用户使用何种最佳交通方式由O(起点)到D(终点)
数据描述:

profiles.csv:
属性pid:用户的ID;
属性p0~p65:用户的个人信息(如身高,年龄,职业等)

训练集(2018.10.1~2018.11.30两个月的数据):
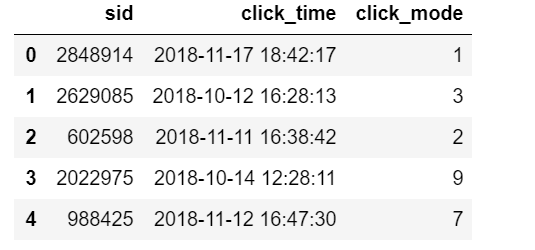
train_clicks.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性click_time: 用户点击某种方案的时间;
属性click_mode:用户选择了某种出行方式(****这是训练集的label标签****)
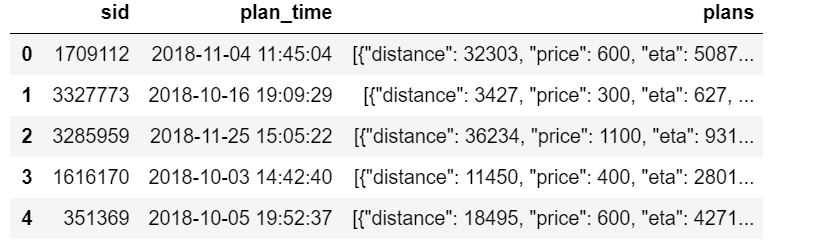
train_plans.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性plan_time:用户准备查询如何去目的点的时间;
属性plans:这个信息是基于百度地图推荐的方案(包括距离,需要的时间,价格,交通方式),注:交通方式可能是某些组合,如taxi-bus
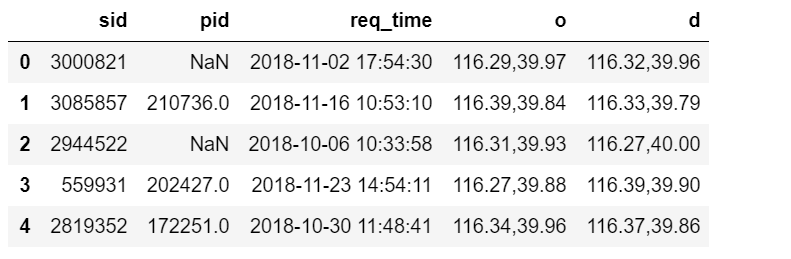
train_queries.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性pid:用户的ID;
属性req_time:和plan_time几乎一样,用户查询的时间(并不是完全一样的,有的有一些时间差,猜测可能是手机的网速等问题);
属性o:起点的经纬度;
属性d:终点的经纬度
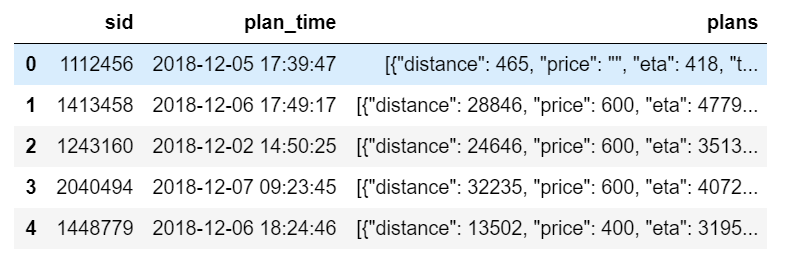
测试集(2018.12.1~2018.12.7七天的数据):
test_plans.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性plan_time:用户准备查询如何去目的点的时间;
属性plans:这个信息是基于百度地图推荐的方案(包括距离,需要的时间,价格,交通方式),注:交通方式可能是某些组合,如taxi-bus
test_queries.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性pid:用户的ID;
属性req_time:和plan_time几乎一样,用户查询的时间(并不是完全一样的,有的有一些时间差,猜测可能是手机的网速等问题);
属性o:起点的经纬度;
属性d:终点的经纬度
任务就是根据训练集的数据来训练模型,然后将测试集的特征放入模型,预测每个用户出行的交通选择方式(即训练集中的click_mode属性)
开源代码如下:
2.1 工具包导入
import numpy as np
import pandas as pd
import lightgbm as lgb
import os import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline import warnings
warnings.filterwarnings("ignore") from tqdm import tqdm
import json
from sklearn.metrics import f1_score
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from itertools import product
import ast
2.2 数据读取
path = 'E:/data/data_set_phase1/'
train_queries = pd.read_csv(path + 'train_queries.csv', parse_dates=['req_time'])
train_plans = pd.read_csv(path + 'train_plans.csv', parse_dates=['plan_time'])
train_clicks = pd.read_csv(path + 'train_clicks.csv')
profiles = pd.read_csv(path + 'profiles.csv')
test_queries = pd.read_csv(path + 'test_queries.csv', parse_dates=['req_time'])
test_plans = pd.read_csv(path + 'test_plans.csv', parse_dates=['plan_time'])
3 特征工程
此处我们对所有表格进行合并,这样方便提取表格之间的交互特征,注意因为初赛的数据相对较少,所以我们才合在一起,不然尽量不要做,这样会给机器的内存带来非常大的负担.
3.1 数据集合并
train = train_queries.merge(train_plans, 'left', ['sid'])
test = test_queries.merge(test_plans, 'left', ['sid'])
train = train.merge(train_clicks, 'left', ['sid'])
train['click_mode'] = train['click_mode'].fillna(0).astype(int)
data = pd.concat([train, test], ignore_index=True)
data = data.merge(profiles, 'left', ['pid'])
3.2 od(经纬度)特征
因为经纬度是组合字符串特征,此处我们对其进行还原,因为o,d本身是有相对大小关系的,我们不再对其进行编码。
data['o_lng'] = data['o'].apply(lambda x: float(x.split(',')[0]))
data['o_lat'] = data['o'].apply(lambda x: float(x.split(',')[1]))
data['d_lng'] = data['d'].apply(lambda x: float(x.split(',')[0]))
data['d_lat'] = data['d'].apply(lambda x: float(x.split(',')[1]))
3.3 plan_time & req_time特征
3.3.1 原始特征
时间信息会影响我们的决定,比如大晚上从A地到B地其实很多人是不会选择步行的,更多的会选择打车之类的,因为太黑了,怕迷路等;而如果是早高峰,而且离公司就几公里的情况, 那么一般就不会打车,因为特别会容易堵车,这个时候大家更喜欢骑自行车.
此处我们提取weekday来标志是周几; hour来标志是当日几点.
time_feature = []
for i in ['req_time']:
data[i + '_hour'] = data[i].dt.hour
data[i + '_weekday'] = data[i].dt.weekday
time_feature.append(i + '_hour')
time_feature.append(i + '_weekday')
3.3.2 plan_time & req_time差值特征
我们做EDA的时候发现plan_time和req_time并不是完全一样的,有的有一些时间差,我们猜测可能是手机的网速等问题,所以我们做差值来标志用户的手机信号等信息.
data['time_diff'] = data['plan_time'].astype(int) - data['req_time'].astype(int)
time_feature.append('time_diff')
3.4 plans特征
plans这个数据集包含的信息非常多,因为这个信息是基于百度地图推荐的。所以毫无疑问是本次比赛的关键之一,我们对其进行展开并提取相关的特征。
此处我发现kdd已经有大佬开源了plans的特征提取关键代码,我感觉很不错,此处我便直接引用,至于其他的特征欢迎去作者的Github下载.
此处关于plans的特征主要可以归纳为如下的特征:
百度地图推荐的距离的统计值(mean,min,max,std)
各种交通方式的价格的统计值(mean,min,max,std)
各种交通方式的时间的统计值(mean,min,max,std)
一些其他的特征,最大距离的交通方式,最高价格的交通方式,最短时间的交通方式等.
data['plans_json'] = data['plans'].fillna('[]').apply(lambda x: json.loads(x))
def gen_plan_feas(data):
n = data.shape[0]
mode_list_feas = np.zeros((n, 12))
max_dist, min_dist, mean_dist, std_dist = np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)) max_price, min_price, mean_price, std_price = np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)) max_eta, min_eta, mean_eta, std_eta = np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)) min_dist_mode, max_dist_mode, min_price_mode, max_price_mode, min_eta_mode, max_eta_mode, first_mode = \
np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)) mode_texts = []
for i, plan in tqdm(enumerate(data['plans_json'].values)):
if len(plan) == 0:
cur_plan_list = []
else:
cur_plan_list = plan
if len(cur_plan_list) == 0:
mode_list_feas[i, 0] = 1
first_mode[i] = 0
max_dist[i] = -1
min_dist[i] = -1
mean_dist[i] = -1
std_dist[i] = -1
max_price[i] = -1
min_price[i] = -1
mean_price[i] = -1
std_price[i] = -1
max_eta[i] = -1
min_eta[i] = -1
mean_eta[i] = -1
std_eta[i] = -1
min_dist_mode[i] = -1
max_dist_mode[i] = -1
min_price_mode[i] = -1
max_price_mode[i] = -1
min_eta_mode[i] = -1
max_eta_mode[i] = -1
mode_texts.append('word_null')
else:
distance_list = []
price_list = []
eta_list = []
mode_list = []
for tmp_dit in cur_plan_list:
distance_list.append(int(tmp_dit['distance']))
if tmp_dit['price'] == '':
price_list.append(0)
else:
price_list.append(int(tmp_dit['price']))
eta_list.append(int(tmp_dit['eta']))
mode_list.append(int(tmp_dit['transport_mode']))
mode_texts.append(
' '.join(['word_{}'.format(mode) for mode in mode_list]))
distance_list = np.array(distance_list)
price_list = np.array(price_list)
eta_list = np.array(eta_list)
mode_list = np.array(mode_list, dtype='int')
mode_list_feas[i, mode_list] = 1
distance_sort_idx = np.argsort(distance_list)
price_sort_idx = np.argsort(price_list)
eta_sort_idx = np.argsort(eta_list)
max_dist[i] = distance_list[distance_sort_idx[-1]]
min_dist[i] = distance_list[distance_sort_idx[0]]
mean_dist[i] = np.mean(distance_list)
std_dist[i] = np.std(distance_list)
max_price[i] = price_list[price_sort_idx[-1]]
min_price[i] = price_list[price_sort_idx[0]]
mean_price[i] = np.mean(price_list)
std_price[i] = np.std(price_list)
max_eta[i] = eta_list[eta_sort_idx[-1]]
min_eta[i] = eta_list[eta_sort_idx[0]]
mean_eta[i] = np.mean(eta_list)
std_eta[i] = np.std(eta_list)
first_mode[i] = mode_list[0]
max_dist_mode[i] = mode_list[distance_sort_idx[-1]]
min_dist_mode[i] = mode_list[distance_sort_idx[0]]
max_price_mode[i] = mode_list[price_sort_idx[-1]]
min_price_mode[i] = mode_list[price_sort_idx[0]]
max_eta_mode[i] = mode_list[eta_sort_idx[-1]]
min_eta_mode[i] = mode_list[eta_sort_idx[0]]
feature_data = pd.DataFrame(mode_list_feas)
feature_data.columns = ['mode_feas_{}'.format(i) for i in range(12)]
feature_data['max_dist'] = max_dist
feature_data['min_dist'] = min_dist
feature_data['mean_dist'] = mean_dist
feature_data['std_dist'] = std_dist
feature_data['max_price'] = max_price
feature_data['min_price'] = min_price
feature_data['mean_price'] = mean_price
feature_data['std_price'] = std_price
feature_data['max_eta'] = max_eta
feature_data['min_eta'] = min_eta
feature_data['mean_eta'] = mean_eta
feature_data['std_eta'] = std_eta
feature_data['max_dist_mode'] = max_dist_mode
feature_data['min_dist_mode'] = min_dist_mode
feature_data['max_price_mode'] = max_price_mode
feature_data['min_price_mode'] = min_price_mode
feature_data['max_eta_mode'] = max_eta_mode
feature_data['min_eta_mode'] = min_eta_mode
feature_data['first_mode'] = first_mode
print('mode tfidf...')
tfidf_enc = TfidfVectorizer(ngram_range=(1, 2))
tfidf_vec = tfidf_enc.fit_transform(mode_texts)
svd_enc = TruncatedSVD(n_components=10, n_iter=20, random_state=2019)
mode_svd = svd_enc.fit_transform(tfidf_vec)
mode_svd = pd.DataFrame(mode_svd)
mode_svd.columns = ['svd_mode_{}'.format(i) for i in range(10)]
plan_fea = pd.concat([feature_data, mode_svd], axis=1)
plan_fea['sid'] = data['sid'].valreturn plan_fea
data_plans = gen_plan_feas(data)
plan_features = [col for col in data_plans.columns if col not in ['sid']]
data = data.merge(data_plans, on='sid', how='left')
4 模型训练&验证&提交
4.1 模型训练&验证
4.1.1 评估指标设计
为了对线上线下有一定的了解,我们尽可能设计和线上一样的评估,下面是lgb的评估函数
def f1_weighted(labels,preds):
preds = np.argmax(preds.reshape(12, -1), axis=0)
score = f1_score(y_true=labels, y_pred=preds, average='weighted')
return 'f1_weighted', score, True
4.1.2 模型验证
此处我们模拟线上,选用7天的时间作为验证集.
profile_feature = ['p' + str(i) for i in range(66)]
origin_num_feature = ['o_lng', 'o_lat', 'd_lng', 'd_lat'] + profile_feature
cate_feature = ['pid']
feature = origin_num_feature + cate_feature + plan_features + time_feature
train_index = (data.req_time < '2018-11-23')
train_x = data[train_index][feature].reset_index(drop=True)
train_y = data[train_index].click_mode.reset_index(drop=True) valid_index = (data.req_time > '2018-11-23') & (data.req_time < '2018-12-01')
valid_x = data[valid_index][feature].reset_index(drop=True)
valid_y = data[valid_index].click_mode.reset_index(drop=True) test_index = (data.req_time > '2018-12-01')
test_x = data[test_index][feature].reset_index(drop=True) print(len(feature), feature)
lgb_model = lgb.LGBMClassifier(boosting_type="gbdt", num_leaves=61, reg_alpha=0, reg_lambda=0.01,
max_depth=-1, n_estimators=2000, objective='multiclass',
subsample=0.8, colsample_bytree=0.8, subsample_freq=1,min_child_samples = 50, learning_rate=0.05, random_state=2019, metric="None",n_jobs=-1)
eval_set = [(valid_x, valid_y)]
model.fit(train_x, train_y, eval_set=eval_set, eval_metric=f1_weighted,categorical_feature=cate_feature, verbose=10, early_stopping_rounds=10
4.2 特征重要性分析
4.2.1 特征重要性分析
通过模型跑出来的结果,我们发现:
pid特征是最重要的,这并不奇怪,因为pid在本次比赛中是一种聚类特征,表示某一类人,比如有一类pid表示有钱人,那么这些人基本都是有房有车的,所以出行也都是驾车出行,那么他们基本都是选择自驾的;
另外我们发现时间的方差和距离的方差也是极其重要的特征,这也很好解释,因为std可以认为是一种分布的表示特征,如果std大标明不同的出行方式的差别极大,比如从A到B,步行需要2h,而做地铁只需要10min,那么毫无疑问,90%的人会考虑步行.
req_time_hour也是非常重要的特征,不同时段人们选择的交通方式是不一样的,所以也是可以理解的.
imp = pd.DataFrame()
imp['fea'] = feature
imp['imp'] = lgb_model.feature_importances_
imp = imp.sort_values('imp',ascending = False)
imp
plt.figure(figsize=[20,10])
sns.barplot(x = 'fea', y ='imp',data = imp)
4.2.2 预测结果分析
除了对特征进行分析,我们再来分析每个类的预测结果,
我们发现0,4,6,8的recall很差,也就是说很多都没预测出来,可能需要通过很多其他的手段对其进行处理.
至于为什么预测不好,是不是特征没提好,还是参数不行,还是其他原因,希望大家自行探索.
pred = lgb_model.predict(valid_x)
df_analysis = pd.DataFrame()
df_analysis['sid'] = data[valid_index]['sid']
df_analysis['label'] = valid_y.values
df_analysis['pred'] = pred
df_analysis['label'] = df_analysis['label'].astype(int)
from sklearn.metrics import accuracy_score
from sklearn.metrics import accuracy_score,recall_score,precision_score
dic_ = df_analysis['label'].value_counts(normalize = True)
def get_weighted_fscore(y_pred, y_true):
f_score = 0
for i in range(12):
yt = y_true == i
yp = y_pred == i
f_score += dic_[i] * f1_score(y_true=yt, y_pred= yp)
print(i,dic_[i],f1_score(y_true=yt, y_pred= yp), precision_score(y_true=yt, y_pred= yp),recall_score(y_true=yt, y_pred= yp))
print(f_score)
get_weighted_fscore(y_true =df_analysis['label'] , y_pred = df_analysis['pred'])
4.3 模型训练&提交
all_train_x = data[data.req_time < '2018-12-01'][feature].reset_index(drop=True)
all_train_y = data[data.req_time < '2018-12-01'].click_mode.reset_index(drop=True)
print(lgb_model.best_iteration_)
lgb_model.n_estimators = lgb_model.best_iteration_
lgb_model.fit(all_train_x, all_train_y,categorical_feature=cate_feature)
print('fit over')
result = pd.DataFrame()
result['sid'] = data[test_index]['sid']
result['recommend_mode'] = lgb_model.predict(test_x)
result['recommend_mode'] = result['recommend_mode'].astype(int)
print(len(result))
print(result['recommend_mode'].value_counts())
result[['sid', 'recommend_mode']].to_csv(path + '/sub/baseline.csv', index=False)
kdd cup 2019的更多相关文章
- 美团:WSDM Cup 2019自然语言推理任务获奖解题思路
WSDM(Web Search and Data Mining,读音为Wisdom)是业界公认的高质量学术会议,注重前沿技术在工业界的落地应用,与SIGIR一起被称为信息检索领域的Top2. 刚刚在墨 ...
- 【转】关于KDD Cup '99 数据集的警告,希望从事相关工作的伙伴注意
Features From: Terry Brugger Date: 15 Sep 2007 Subject: KDD Cup '99 dataset (Network Intrusion) cons ...
- KDD Cup 99网络入侵检测数据的分析
看论文 该数据集是从一个模拟的美国空军局域网上采集来的 9 个星期的网络连接数据, 分成具有标识的训练数据和未加标识的测试数据.测试数据和训练数据有着不同的概率分布, 测试数据包含了一些未出现在训练数 ...
- Kdd Cup 2013 总结2
- 史无前例的KDD 2014大会记
2014大会记" title="史无前例的KDD 2014大会记"> 作者:蒋朦 微软亚洲研究院实习生 创造多项纪录的KDD 2014 ACM SIGKDD 国际会 ...
- 利用KD树进行异常检测
软件安全课程的一次实验,整理之后发出来共享. 什么是KD树 要说KD树,我们得先说一下什么是KNN算法. KNN是k-NearestNeighbor的简称,原理很简单:当你有一堆已经标注好的数据时,你 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- KDD-CUP Proposal
From 鞠源 已有 1303 次阅读 2012-11-25 21:09 |系统分类:科研笔记|关键词:会议 领域 justify 知识 KDDCUP - Competition is a stron ...
- Datasets for Data Mining and Data Science
https://github.com/mattbane/RecommenderSystem http://grouplens.org/datasets/movielens/ KDDCUP-2012官网 ...
随机推荐
- goroutine 修改全局变量无效问题
原文:https://studygolang.com/topics/7050 go修改全局变量的问题 测试 goroutine 修改全局变量,有x y 两个全局函数,分别在两个 goroutine f ...
- JavaScript002,验证输入
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- [Visual Studio] 自定义项目模板(.vsix扩展)
VS自定义项目模板:[2]创建VSIX项目模板扩展 听语音 | 浏览:1237 | 更新:2015-01-02 09:21 | 标签:软件开发 1 2 3 4 5 6 7 分步阅读 一键约师傅 百度师 ...
- [译] 尤雨溪:Vue 3.0 计划
[译] 尤雨溪:Vue 3.0 计划 原文:Plans for the Next Iteration of Vue.js作者:Evan You 发表时间:Sep 30, 2018译者:西楼听雨 发表时 ...
- C# DocumentCompleted事件多次条用解决方案
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e) { ...
- hash 跟B+tree的区别
1.hash只支持in跟=,不支持范围查询,时间复杂度:O(1) 2.B+tree支持范围查询,时间复杂度:O(log n) 3. B+tree 的优点:1.磁盘读取代价更低 ...
- python--openCV--鼠标事件
import cv2 import numpy as np cv2.namedWindow("new") def drawxxx(event,x,y,flags,param): # ...
- rxjs入门指南
使用场景 在复杂的,频繁的异步请求场景,使用rxjs. 在依赖的多个异步数据,决定渲染的情景,使用rxjs. 总之:在前台频繁的.大量的.和后台数据交互的复杂项目里面,使用rxjs(web端,iOS, ...
- Integer int auto-boxing auto-unboxing ==
Auto-boxing 自动装箱 Auto-unboxing 自动拆箱 == 相等 1.new出来的对象,除非遇到了拆箱的情况,肯定不相等. 因为new对象之前需要在JVM堆中提供空间,所以new出来 ...
- 6502 assemble 条件判断
LDA #$ CMP #$ BNE notequal STA $ notequal: BRK