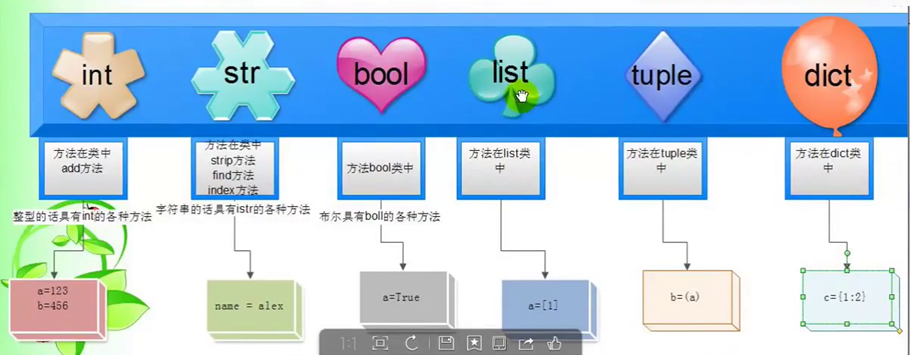
python基本数据类型剖析
一、 基本数据类型常用功能:
1. 整数 int
- #int内部优化
n1=123
n2=n1- n1= 123
n2= 123
========2份内存=========
if -5~257:
n1= 123
n2 =123
else:
n1= 123
n2= 123
======》对象的内存地址 = ID(对象或对象的变量名)
#Python 内容优化:在-5~257默认同一个地址码
#查看内存地址:ID(变量名)
#查看字符串、数组长度:len(字符串、数组)
- #长度限制
用int,超出了范围
32 -2**31~2**31-1
64 -2**63~2**63-1
long在Python没有长度限制- 获取可表示的二进制最短位数
n = 4
w = n.bit_length()
print(w)
- 2.字符串 str:字符串就是一个有字符组成的序列。
str
s1 ="dsa"
s2 =str("dsa")
# s1=str()#s1 =""
#无参数,创建空字符串
#一个参数,创建普通字符串
#两个参数,int(字节,编码)
#两端去除空格除去两侧(不包括内部)空格的字符串
- s1.strip()
#以.....开头
s1.startswith
#找子序列,返回子序列所在位置的最左端索引值
s1.find
#将字符串中的某个子序列替换成指定的值
s1.replace(“is”.“eez”)
# 变大写
s1.upper()
# 是。。。吗?
s1.isalpha()
#lower 把字符串变成小写字母
#jion 连接序列中的元素 与 split将字符串分割成序列- #公共功能
- 1.字符==》字节
utf-8编码==》一个汉字为3个字节
gbk编码 ==》一个汉字为2个字节
编码、for:把自己名字分别用二进制、八进制、十六进制写出来
name = "刘飞"
for i in name:
print(i)
bytes_list = bytes(i,encoding ="utf-8")
print(bytes_list)
print(bytes(i,encoding ="utf-8")
- for b in bytes_list:
字节默认16进制
print(b)
#3.5 for循环时候,循环的每一个元素是“字节“
#bytes_list = bytes("字符串” ,encoding ="utf-8")
print(bytes_list) #默认没一个字节都是16进制表示
# for b in bytes_list:
print(b) #默认每一个字节都是10进制表示
#10进制的数字 ==》 2进制
bin(10进制的数字)
len
id
#bytes可以将字符串转换字节
# py2.X for循环中遇到中文用字节循环即(2*3)
# py3.x for循环中遇到中文严格按照字符循环
- 3.布尔值 bool
4.列表 list
元素的集合
- name_list = ["123","abc","sdf"]
# print(name_list[0:2])
# print(name_list[2:len(name_list)])
#
a.# name_list.append("asc") #append在列表末尾追加新的对象,单个加入
# name_list.append("asc")- # print(name_list)
b.# print(name_list.count("asc")) #count统计某个元素在列表中出现的个数
# temp= [111,123,145,123,15]
c.# name_list.extend(temp) #extend在列表末尾批量的把一组列表加入到前者中- # print(name_list)
d.#print(name_list.index("sdf"))#index从列表中找出某个值第一个位置的索引值- e.# name_list.insert(1,"156") #insert将对象插入列表中
# print(name_list)- f.# name_list.pop() #pop移除列表中的一个元素,当括号没有数字时默认是最后一个
# print(name_list)- g.# name_list.remove("abc") # remove移除列表中某个值的第一个匹配项
# print(name_list)- h.# name_list.reverse() # reverse将列表中的元素反向存放
# print(name_list)- i.name_list.sort()
print(name_list) #sort用于原位置在列表中进行排序
- g.print(name_list)
del name_list[1]#del删除某个元素
print(name_list)
- k.name_tuple = ("ale","123")
#索引
print(name_tuple[0])
#len
print(name_tuple[len(name_tuple)-1])
#for
for i in name_tuple:
print(i)
- #count 计算元素出现的个数
print(name_tuple.count("ale"))
#index 获取指定元素的索引位置
print(name_tuple.index("ale"))
#不能删除
- 5.元组 tuple
元组跟列表一样也是一种序列,但是不能修改
t=(11,12,123)
t=(11,123,{"alee",{"as":"asd"}}
元组,儿子不能改变
元组,儿子不能变,但孙子能改变如上字典里面的
一般字符串,执行一个功能,生成一个新内容,但原来的内容不变
- list、tuple、dict,执行一个功能,生成一个新内容,原来的内容会改变
6.字典 dict
字典默认循环key的值 要循环整个需要dict.items()
键 :值对称为项,项之间用逗号隔开 有大括号括起来。- user_info={"name": "al", "age": 12, "gender": "m"}
- formkeys与单独写的同一个的字典区别
# s=dict.fromkeys({"k1","k2","k3"},[])
# print(s)
# s["k1"].append("x")#共用一块列表
# print(s)- s={"k1":[],"k2":[],"k3":[]}
s["k1"].append("x")#分别用了三块列表
print(s)
- a.len(d)返回d中的项(键-值对)的数量
b.d[k]返回关联到键k上的值
c.d[k]=v将值v关联到键k上
d.del d[k]删除键为k的项
e.k in d 检查d中是否有含有键为k的项
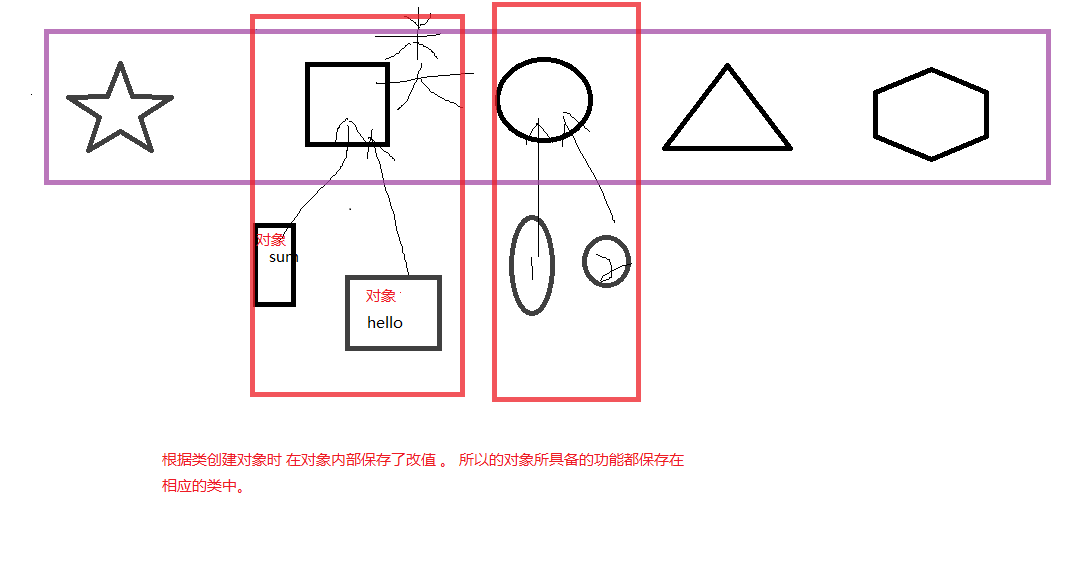
- #查看对象的类,或对象所具备的功能
1. # type
# temp = "ab"
# t = type(temp)
# print (t)
# str ,ctr+鼠标左,找到 str类,内部所有方法- 2. # temp = "ab"
# print (dir(temp))- 3. # temp = "ab"
# help(type(temp))- 4. temp ="ab "
temp.upper()
查找方法:鼠标放在upper()上 按住Ctrl +鼠标左键,会自动定位到 upper功能处
二、 索引:序列中的所有元素都是编号的---从0开始递增。这些元素可以通过编号分别访问。索引0指向第一个元素。 s1[0] 只能取一个元素
分片: 分片操作的实现需要提供两个索引作为边界,第一个索引的元素是包含在分片内的,而第二个则不包含在分片内(1=<元素<n) s1[0:1] 取多个元素
- enumerate
- #enumerate自动生成一列,默认从0自增一
#字符串=》数字 , int(字符串)
# li=["电脑","x鞋子","生活用品","硬盘"]
# for key ,item in enumerate(li,1):
# print(key,item)
# s=input("请输入商品:")
# # 字符串转换成int
# s_num = int(s)
# print(li[s_num-1])- # 索引
- # li=["电脑","x鞋子","生活用品","硬盘"]
# s= input("请输入内容:")
# b= li.index(s)
# print(b)- #range/xrange
#py2.7
#range:用获取指定方位内的数,range(0,10000000) 内存立刻执行
#xrange: 用获取指定方位内的数,range(0,10000000) 在内存不创建,只有在for循环中迭代时候创建,- # py3 ,range等同于py2.7中的xrange每循环一次就创建一次数值
- 作业:
一、s=[11,22,33,44,55,66,77,88,99,90]将所有大于66值保存在字典中的第一个key中,将小于66的值保存在第二个key的值中。
1.
s=[11,22,33,44,55,66,77,88,99,90]
- s1=[]
s2=[]
for i in s:
if i < 66:
s1.append(i)
else:
s2.append(i)
s3={"k1":s1,"k2":s2}
print(s3)
2.
- dict = {"k1":[],"k2":[]}
s=[11,22,33,44,55,66,77,88,99,90]
for i in s:
if i <= 66:
dict["k1"].append(i)
else:
dict["k2"].append(i)
print(dict)
- 二、查找列表中元素,移除空格,并查找以a或A开头并且以C结尾的所有元素
- s=["alex","aric","Alex","Tong"]
tu=("alex","arice","Alex","Tong")
- dict={"k1":"alex","k2":"arice","k3":"arice","k3":"Alex","k4":"Tong"}
- # s=["alex","aric","Alex","Tong"]
# for i in s:
# new_i=i.strip()
# if (new_i.startswith("a") or new_i.startswith("A"))and new_i.endswith("c"):
# print(new_i)- # tu=("alex", "aric", "Alex", "Tong")
# for i in tu :
# new_i =i.strip()
# # if (new_i.startswith("a") or new_i.startswith("A")) and new_i.endswith("c"):
# if new_i.endswith("c"):
# if new_i.startswith("a") :
# pass
# if new_i.startswith("A"):
# pass
# print(new_i)- dict={"k1":"alex","k2":"aric","k3":"arice","k3":"Alex","k4":"Tong"}
# for i in dict.values():
# new_i = i.strip()
# if (new_i.startswith("a") or new_i.startswith("A")) and new_i.startswith("c"):
# print(i)
# # if new_i.endswith("c"):
# # if new_i.startswith("a") :
# # pass
# # if new_i.startswith("A"):
# # pass
# # print(new_i)
- 三、
- b= ["手机","电脑","鼠标垫","游艇"],用户输入序号,显示用户选中的商品
- b= ["手机","电脑","鼠标垫","游艇"]
# s1=input("请输入商品:")
# a=s.index(s1)
# print(a)- for i,j in enumerate(b):
print(i+1,j)
num=input("num:")
num = int(num)
len_b=len(b)
if num >0 and num <= len_b:
print(b[num-1])
else:
print("商品不存在")
python基本数据类型剖析的更多相关文章
- python源码剖析学习记录-01
学习<Python源码剖析-深度探索动态语言核心技术>教程 Python总体架构,运行流程 File Group: 1.Core Modules 内部模块,例如:imp ...
- python 基本数据类型分析
在python中,一切都是对象!对象由类创建而来,对象所拥有的功能都来自于类.在本节中,我们了解一下python基本数据类型对象具有哪些功能,我们平常是怎么使用的. 对于python,一切事物都是对象 ...
- Python开发【第二章】:Python深浅拷贝剖析
Python深浅拷贝剖析 Python中,对象的赋值,拷贝(深/浅拷贝)之间是有差异的,如果使用的时候不注意,就可能产生意外的结果. 下面本文就通过简单的例子介绍一下这些概念之间的差别. 一.对象赋值 ...
- python常用数据类型内置方法介绍
熟练掌握python常用数据类型内置方法是每个初学者必须具备的内功. 下面介绍了python常用的集中数据类型及其方法,点开源代码,其中对主要方法都进行了中文注释. 一.整型 a = 100 a.xx ...
- 闲聊之Python的数据类型 - 零基础入门学习Python005
闲聊之Python的数据类型 让编程改变世界 Change the world by program Python的数据类型 闲聊之Python的数据类型所谓闲聊,goosip,就是屁大点事可以咱聊上 ...
- python自学笔记(二)python基本数据类型之字符串处理
一.数据类型的组成分3部分:身份.类型.值 身份:id方法来看它的唯一标识符,内存地址靠这个查看 类型:type方法查看 值:数据项 二.常用基本数据类型 int 整型 boolean 布尔型 str ...
- Python入门-数据类型
一.变量 1)变量定义 name = 100(name是变量名 = 号是赋值号100是变量的值) 2)变量赋值 直接赋值 a=1 链式赋值 a=b=c=1 序列解包赋值 a,b,c = 1,2,3 ...
- Python基础:八、python基本数据类型
一.什么是数据类型? 我们人类可以很容易的分清数字与字符的区别,但是计算机并不能,计算机虽然很强大,但从某种角度上来看又很傻,除非你明确告诉它,"1"是数字,"壹&quo ...
- python之数据类型详解
python之数据类型详解 二.列表list (可以存储多个值)(列表内数字不需要加引号) sort s1=[','!'] # s1.sort() # print(s1) -->['!', ' ...
随机推荐
- js文字跑马灯
实现文字跑马灯效果,主要控制scrollLeft. 效果图如下 代码如下 <html> <head> <script type="text/javascript ...
- Jmeter4.0---- 修改jmeter源代码(18)
1.说明 jmeter本身功能很强大,但是在使用的时候我们会发现有些想法jmeter无法帮我们实现,这个时候就需要我们细节去修改一下它的源代码,来满足我们的需求. * 仅供参考 2.步骤 第一步: j ...
- Eclipse中项目本身没有问题,可是工程名却有红色小叉叉解决办法
右击项目“Properties”,在弹出的“Properties”的左侧边框,单击“Project Facets”,打开“Project Facets”页面, 在页面中“Java”下拉选项中,选择与自 ...
- 轮播图--使用原生js的轮播图
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- requests模块高级操作之proxies
一.代理proxy 概念:代理服务器 作用:请求和响应的转发 免费代理 www.goubanjia.com 快代理 西祠代理 代理精灵(付费) 匿名度: 透明:对方服务器知道你使用代理也知道你真实ip ...
- flutter问题集锦
现在的多平台开发很多啦,目前主流的救赎react native 和weex了,其他的旧的就不说了,新出来的gomobile目前基本无人使用,底层的很多原生对接还没有完善,flutter发布了第一版正式 ...
- 12-factor应用和微服务架构应用的区别
SAP云平台的帮助文档很多时候将12-factor应用和微服务架构的应用相提并论. 然而从Allan Beck和John Mcteague的Cloud成熟度模型概念里,12-factor应用从成熟度上 ...
- 17.SpringMVC核心技术-拦截器
SpringMVC 中的 Interceptor 拦截器是非常重要和相当有用的,它的主要作用是拦截指定 的用户请求, 并进行相应的预处理与后处理.其拦截的时间点在“处理器映射器根据用户提 交的请求映射 ...
- django中app_name以及namespace理解
在写django的时候,html中反向解析经常会用到app_name 但有时候又是namespace,具体的区别如下: 大部分情况 这两者有其一就可以了. 并且两者(可以简化理解)无区别 只要一种情况 ...
- 【JAVA各版本特性】JAVA 1.0 - JAVA 12
make JDK Version 1.01996-01-23 Oak(橡树) 初代版本,伟大的一个里程碑,但是是纯解释运行,使用外挂JIT,性能比较差,运行速度慢. JDK Version 1.119 ...