RocketMQ源码详解 | Broker篇 · 其三:CommitLog、索引、消费队列
概述
上一章中,已经介绍了 Broker 的文件系统的各个层次与部分细节,本章将继续了解在逻辑存储层的三个文件 CommitLog、IndexFile、ConsumerQueue 的一些细节。文章最后,还会对比下 RocketMQ 和 Kafka 的持久化结构与设计的合理性。
CommitLog
现在,先从 CommitLog 的几个指针开始复习
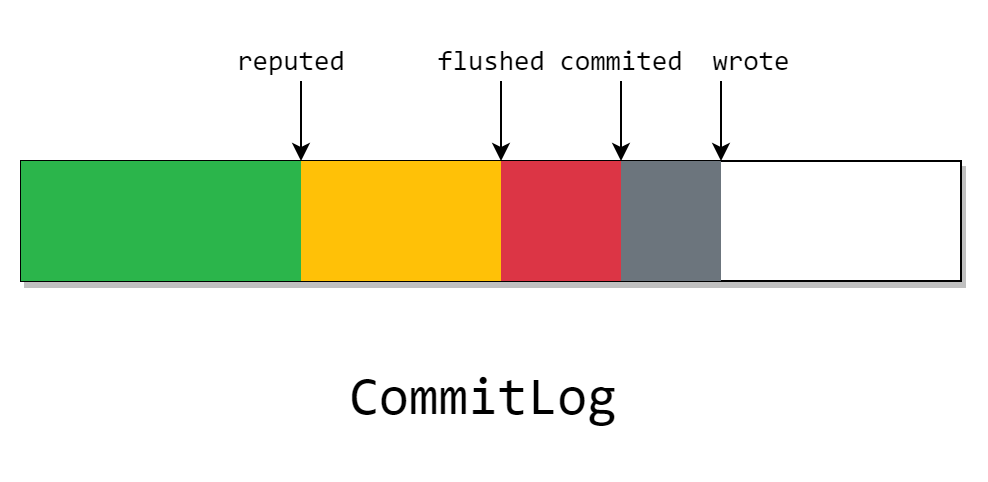
在上一章 《RocketMQ源码详解 | Broker篇 · 其二:文件系统》 中,我们已经了解了 CommitLog 的缓存和刷盘的策略,现在来简单梳理一下。
上文介绍道, CommitLog 在开启 transientStorePool 时,会有一块 writeBuffer,这块 ByteBuffer 是分配的一块堆外内存,也就是图上的灰色部分。我们在上图中看见的 wrote 指针,指向了当前已写入 writeBuffer 但是没有 commit 的位置。
这块灰色部分只存在 Java 进程中,也就是说程序崩了则会丢失。且如果关闭 transientStorePool 选择,该指针将不会存在。
然后当我们定期将 writeBuffer 刷入 FileChannel 后,就变成了图中的红色块。其中的 commited 指针代表在这之前的消息都刷入了 page cache。
这部分的消息由于存放在 page cache 中,且 page cache 是操作系统内核中的一块内存,所以程序崩了不会丢失,但在宕机后依旧会丢失。
不过 CommitLog 会根据具体的刷盘策略来异步或同步的进行刷盘,也就是说,在 flushed 指针之前的数据,已经完全的磁盘里了。
且这块数据除非介质被破坏,否则一般不会丢失。
而在等待所有的 CommitLogDispatcher 处理完成后,reputed 指针就会前进。而这个 dispatch 做的事,就是我们之前在消息提交时没有发现的两件事:构建 IndexFile 和 ConsumerQueue。
需要注意的是,图中虽然画为 reputed 指针在 flushed 指针后面。但实际上 reputed 指针最快可以和 wrote 指针同步,
CommitLogDispatcher 实现类有:
CommitLogDispatcherBuildConsumeQueueCommitLogDispatcherBuildIndexCommitLogDispatcherCalcBitMap
这些类会在后文进行介绍
由上章我们知道,CommitLog 的文件结构如下:
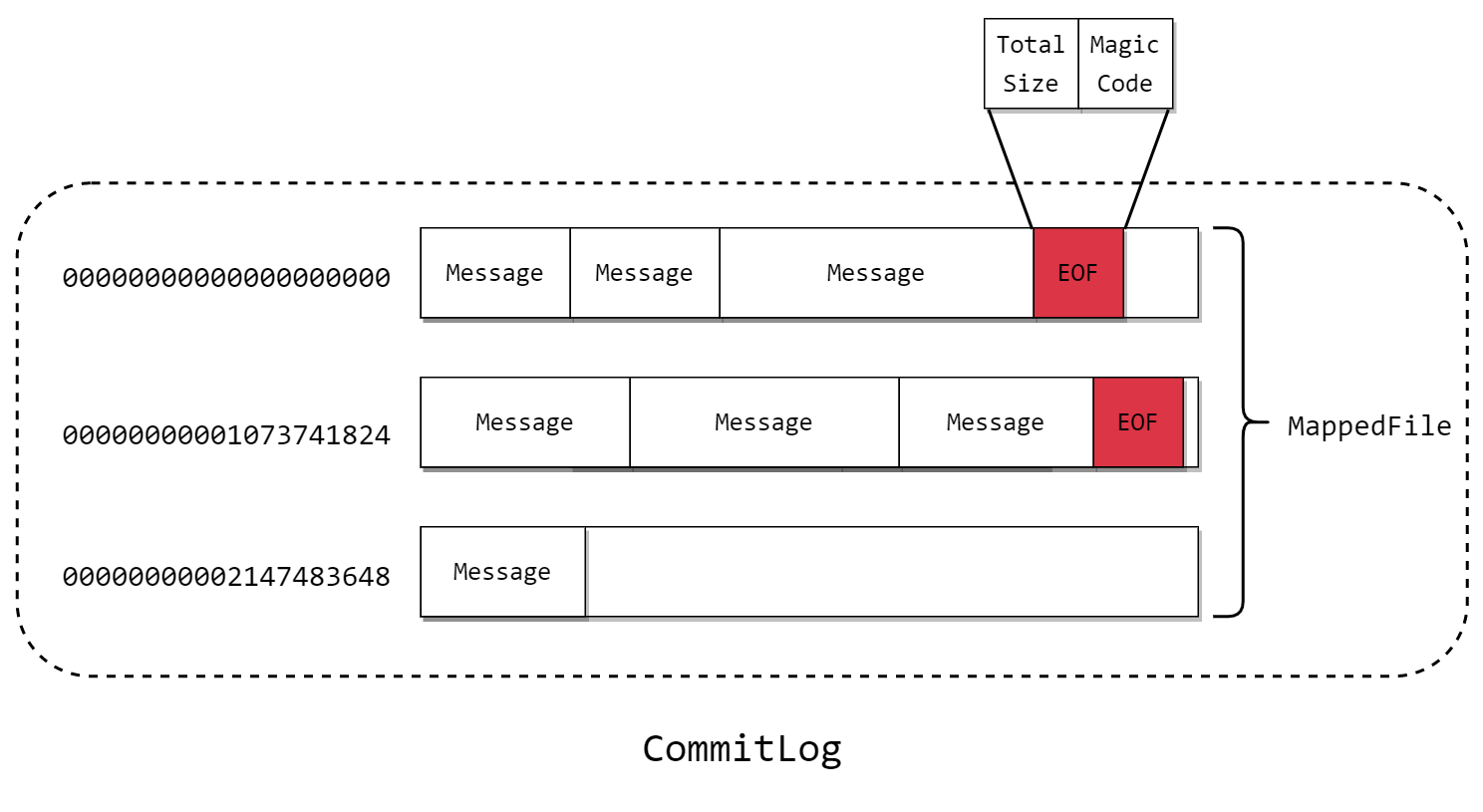
它的长度默认是固定为 1G,文件名为开头的 offset,其中消息是不定长的,在尾部发现新的消息写不下的时候,会新开文件。且在旧的文件写入 当前文件的总长和魔数。
IndexFile
RocketMQ 通过建立 IndexFile 以提供一种能够通过 时间范围 或 Key 值 来查询 Message 的方法。
IndexFile 的文件结构如下:
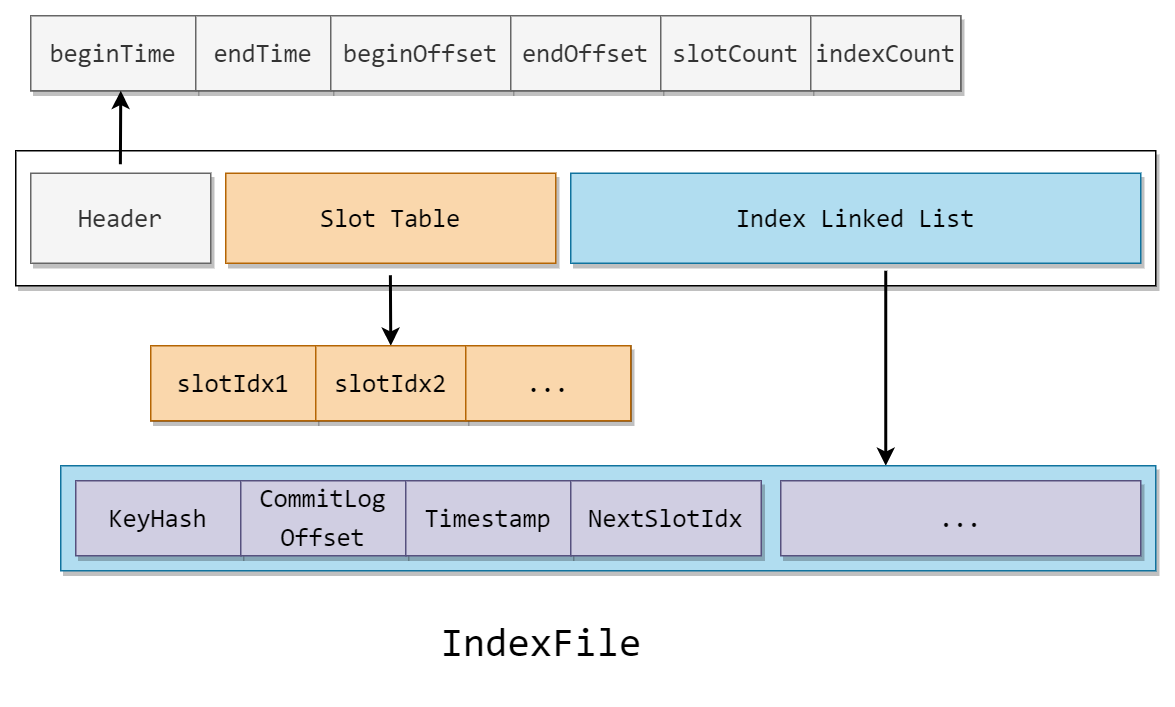
IndexFile 可以分为三部分
Header
头部记录了记录消息的开始(最小)时间,结束(最大)时间,开始(最小)偏移量,结束(最大)偏移量,和槽的个数与节点个数
Slot Table
table 的槽记录了指向当前槽中尾节点的指针
Index Linked List
记录了所有节点的索引信息
由结构可以看出,IndexFile 是标准的 hash 索引,如果了解过 hash 索引的话,根据上文马上就能猜到到 IndexFile 的运行机制了。
接下来进入源码部分
CommitLogDispatcher
ReputMessageService 是在 DefaultMessageStore 类下启动的一个服务,也就是存储组件层。这个服务会每隔一秒就执行一次 deReput
private void doReput() {
if (this.reputFromOffset < DefaultMessageStore.this.commitLog.getMinOffset()) {
// 重放队列落后太多导致 未重放的 commitLog 过期
log.warn("The reputFromOffset={} is smaller than minPyOffset={}, this usually indicate that the dispatch behind too much and the commitlog has expired.",
this.reputFromOffset, DefaultMessageStore.this.commitLog.getMinOffset());
this.reputFromOffset = DefaultMessageStore.this.commitLog.getMinOffset();
}
for (boolean doNext = true; this.isCommitLogAvailable() && doNext; ) {
/*
* 当系统重启的时候,会根据 duplicationEnable 来决定是否从头开始处理
* 消息还是只处理新来的消息。在其打开的情况下,还需要设置 CommitLog.confirmOffset
* 才能从头开始处理消息,因为默认情况下系统启动以后 CommitLog.confirmOffset
* 和ReputMessageService.reputFromOffset是相等的
*/
if (DefaultMessageStore.this.getMessageStoreConfig().isDuplicationEnable()
&& this.reputFromOffset >= DefaultMessageStore.this.getConfirmOffset()) {
break;
}
// 切片以当前 reputed 指针为起点的 ByteBuffer,长度为到当前 wrote 指针
SelectMappedBufferResult result = DefaultMessageStore.this.commitLog.getData(reputFromOffset);
if (result != null) {
try {
this.reputFromOffset = result.getStartOffset();
for (int readSize = 0; readSize < result.getSize() && doNext; ) {
// 构建分发用的请求
DispatchRequest dispatchRequest =
DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false);
int size = dispatchRequest.getBufferSize() == -1 ? dispatchRequest.getMsgSize() : dispatchRequest.getBufferSize();
if (dispatchRequest.isSuccess()) {
if (size > 0) {
// 进行分发,将请求分发到所有的处理器上
DefaultMessageStore.this.doDispatch(dispatchRequest);
// 对长轮询的处理
if (BrokerRole.SLAVE != DefaultMessageStore.this.getMessageStoreConfig().getBrokerRole()
&& DefaultMessageStore.this.brokerConfig.isLongPollingEnable()
&& DefaultMessageStore.this.messageArrivingListener != null) {
DefaultMessageStore.this.messageArrivingListener.arriving(dispatchRequest.getTopic(),
dispatchRequest.getQueueId(), dispatchRequest.getConsumeQueueOffset() + 1,
dispatchRequest.getTagsCode(), dispatchRequest.getStoreTimestamp(),
dispatchRequest.getBitMap(), dispatchRequest.getPropertiesMap());
}
// 完成,可以将重放指针的偏移量向前推进
this.reputFromOffset += size;
readSize += size;
// 更新度量信息
if (DefaultMessageStore.this.getMessageStoreConfig().getBrokerRole() == BrokerRole.SLAVE) {
DefaultMessageStore.this.storeStatsService
.getSinglePutMessageTopicTimesTotal(dispatchRequest.getTopic()).incrementAndGet();
DefaultMessageStore.this.storeStatsService
.getSinglePutMessageTopicSizeTotal(dispatchRequest.getTopic()).addAndGet(dispatchRequest.getMsgSize());
}
} else if (size == 0) {
// 当前文件已读完,跳到下一个文件
this.reputFromOffset = DefaultMessageStore.this.commitLog.rollNextFile(this.reputFromOffset);
readSize = result.getSize();
}
} else if (!dispatchRequest.isSuccess()) {
/* pass */
}
}
} finally {
result.release();
}
} else {
doNext = false;
}
}
}
构建了分发数据后,就交给了每一个 CommitLogDispatcher 处理,而在 Index 中,则是调用了 IndexService 的 buildIndex 方法。
我们主要关心的是 hash 索引的各种操作,所以接下来先看 put 方法
IndexFile#putKey
首先得到 Slot Table 中,Key 所在的槽号
int keyHash = indexKeyHashMethod(key);
// 得到哈希槽号
int slotPos = keyHash % this.hashSlotNum;
// 得到槽的物理偏移量
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
然后获取目标槽的头节点的地址,和当前时间与在 Header 中的 beginTime 的差值
// 获取桶的头节点
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
在 Index Linked List 中的空桶上添加节点
// 添加索引节点
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
可以看到这里在时间戳上存放的是与开始时间的偏移值,是一个很好的节省空间的方法。然后将原来的头节点的地址存储
最后更新元信息
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
if (invalidIndex == slotValue) {
this.indexHeader.incHashSlotCount();
}
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
知道了 put 的原理以后,那 get 也不在话下了
IndexFile#selectPhyOffset
首先还是获取 Slot Table 中 Key 的头节点的位置
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
然后在 Index Linked List 中遍历这条链表,直到尾节点
if (phyOffsets.size() >= maxNum) {
break;
}
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);
不过和一般的 Hash 表不同的是,由于时间是有序的,所以在发现遍历到目标节点开始时间的前面的时候,就不会继续遍历了。
且由于相同 Key 是不会覆盖的,所以会把所有和 key 的 hash 相同的 CommitLog 偏移量返回。
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
if (keyHash == keyHashRead && timeMatched) {
phyOffsets.add(phyOffsetRead);
}
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
nextIndexToRead = prevIndexRead;
至于如何在多个 IndexFile 中查找的方法也很简单,只需要在 Header 中根据时间戳来判断是否需要访问即可。
ConsumerQueue

ConsumerQueue 的文件结构较为简单,其由 30W 个的上图中的结构体组成。
通过 CommitLogDispatcherBuildConsumeQueue 分发的消息会在找到对应 Queue 后直接在 MappedFile 文件追加写入这个结构。
而在查找过程也比较简单,这里的查找分为按消息逻辑偏移量查找和按时间戳查找。
对于按消息逻辑偏移量查找,可以通过计算下标来进行随机读取。
而按时间戳查找则是一个比较有趣的部分,它使用了二分法来加速查找:
public long getOffsetInQueueByTime(final long timestamp) {
// 通过时间戳获取刚好在这之前的 MappedFile
MappedFile mappedFile = this.mappedFileQueue.getMappedFileByTime(timestamp);
if (mappedFile != null) {
long offset = 0;
// 低位为 消息队列最小偏移量 与 该文件最小偏移量 中的最小值
int low = minLogicOffset > mappedFile.getFileFromOffset() ? (int) (minLogicOffset - mappedFile.getFileFromOffset()) : 0;
int high = 0;
int midOffset = -1, targetOffset = -1, leftOffset = -1, rightOffset = -1;
long leftIndexValue = -1L, rightIndexValue = -1L;
long minPhysicOffset = this.defaultMessageStore.getMinPhyOffset();
SelectMappedBufferResult sbr = mappedFile.selectMappedBuffer(0);
if (null != sbr) {
ByteBuffer byteBuffer = sbr.getByteBuffer();
high = byteBuffer.limit() - CQ_STORE_UNIT_SIZE;
try {
while (high >= low) {
// ? 奇怪的写法,先除以 CQ_STORE_UNIT_SIZE 再乘以 CQ_STORE_UNIT_SIZE
midOffset = (low + high) / (2 * CQ_STORE_UNIT_SIZE) * CQ_STORE_UNIT_SIZE;
byteBuffer.position(midOffset);
// 获取找到桶在 CommitLog 中的偏移量
long phyOffset = byteBuffer.getLong();
// 获取该消息大小
int size = byteBuffer.getInt();
if (phyOffset < minPhysicOffset) {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
continue;
}
long storeTime =
this.defaultMessageStore.getCommitLog().pickupStoreTimestamp(phyOffset, size);
// 根据持久化时间进行二分查找
if (storeTime < 0) {
return 0;
} else if (storeTime == timestamp) {
targetOffset = midOffset;
break;
} else if (storeTime > timestamp) {
high = midOffset - CQ_STORE_UNIT_SIZE;
rightOffset = midOffset;
rightIndexValue = storeTime;
} else {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
leftIndexValue = storeTime;
}
}
if (targetOffset != -1) {
offset = targetOffset;
} else {
if (leftIndexValue == -1) {
offset = rightOffset;
} else if (rightIndexValue == -1) {
offset = leftOffset;
} else {
offset =
Math.abs(timestamp - leftIndexValue) >
Math.abs(timestamp - rightIndexValue) ? rightOffset : leftOffset;
}
}
return (mappedFile.getFileFromOffset() + offset) / CQ_STORE_UNIT_SIZE;
} finally {
sbr.release();
}
}
}
return 0;
}
但是我们发现,消息需要消费的时候,只靠 ComsumerQueue 是不够的,因为在这个结构中并没有记录每一个消费者组的消费进度。
这是因为 Broker 端是将消费进度维护在内存的一个 Map 中,同时会定时的将该 Map 转为 json 格式持久化到磁盘。
Kafka 与 RocketMQ 的对比
最后来对比下 Kafka 和 RocketMQ 的持久化方式。
在 Kafka 中,文件类型主要有:
log 文件
消息的存储文件
index 文件
位置索引。通过逻辑偏移量寻找到在 log 文件中的物理偏移量
timeindex 文件
时间戳索引。可以通过时间戳寻找到在 log 文件中的物理偏移量
从索引上,Kafka 和 RocketMQ 都可以根据位置和时间戳来寻找消息。
但是在存储方法上,Kafka 是直接将每一个 Topic 的分区在物理上通过不同的文件来进行管理,而 RocketMQ 则选择了逻辑的将 Topic 和 Queue 进行划分,写入的位置则是一个单独的文件。
直觉上看,Kafka 的方案由于在物理上进行了划分,而 RocketMQ 还需要维护 Consumer 文件,而两者都是顺序写入,那毫无疑问前者更能减少额外维护的工作。
但实际上,RocketMQ 的底层设计方式是优于 Kafka 的。以下为两者在多个 Topic 的情况下的 TPS 的测量
| 产品 | Topic数量 | 发送端并发数 | 发送端RT | 发送端TPS | 消费端TPS |
|---|---|---|---|---|---|
| RocketMQ | 64 | 800 | 8 | 9w | 8.6w |
| 128 | 800 | 9 | 7.8w | 7.7w | |
| 256 | 800 | 10 | 7.5w | 7.5w | |
| Kafka | 64 | 800 | 5 | 13.6w | 13.6w |
| 128 | 256 | 23 | 8500 | 8500 | |
| 256 | 256 | 133 | 2215 | 2352 |
可以看出,在 Topic 较少的情况下,Kafka 是可以击败 RocketMQ 的,但一旦 Topic 增加,Kafka 的 TPS 将会断崖式的下降。
原因在于, Kafka 的内存里的顺序写在多 Topic 多 Queue 下被转化为实际上的随机写。
我们都知道,RocketMQ 和 Kafka 都使用了 Page Cache 来加速文件的访问,同时如果在生产后立刻消费的话,消息都是在 Page Cache 中就被发送到网卡缓冲区中(这被称为零拷贝)。但是,内存是有限的, Page Cache 的大小也是有限的,但内存中的页过多,便会触发"换出"。
Topic 和分区多的情况下,打开的文件句柄也变多,被 mmap 映射到内存中的文件也会变多,因此在写入时,多个文件的页轮流被"换入"和"换出",当然就比不过直接顺序写入到内存中的速度了。
而对于读取,两者都需要将所需要的页换入到内存中,故都是随机读,区别不大。
RocketMQ源码详解 | Broker篇 · 其三:CommitLog、索引、消费队列的更多相关文章
- RocketMQ源码详解 | Broker篇 · 其四:事务消息、批量消息、延迟消息
概述 在上文中,我们讨论了消费者对于消息拉取的实现,对于 RocketMQ 这个黑盒的心脏部分,我们顺着消息的发送流程已经将其剖析了大半部分.本章我们不妨乘胜追击,接着讨论各种不同的消息的原理与实现. ...
- RocketMQ源码详解 | Broker篇 · 其一:线程模型与接收链路
概述 在上一节 RocketMQ源码详解 | Producer篇 · 其二:消息组成.发送链路 中,我们终于将消息发送出了 Producer,在短暂的 tcp 握手后,很快它就会进入目的 Broker ...
- RocketMQ源码详解 | Broker篇 · 其五:高可用之主从架构
概述 对于一个消息中间件来讲,高可用功能是极其重要的,RocketMQ 当然也具有其对应的高可用方案. 在 RocketMQ 中,有主从架构和 Dledger 两种高可用方案: 第一种通过主 Brok ...
- RocketMQ源码详解 | Broker篇 · 其二:文件系统
概述 在 Broker 的通用请求处理器将一个消息进行分发后,就来到了 Broker 的专门处理消息存储的业务处理器部分.本篇文章,我们将要探讨关于 RocketMQ 高效的原因之一:文件结构的良好设 ...
- RocketMQ源码详解 | Consumer篇 · 其一:消息的 Pull 和 Push
概述 当消息被存储后,消费者就会将其消费. 这句话简要的概述了一条消息的最总去向,也引出了本文将讨论的问题: 消息什么时候才对被消费者可见? 是在 page cache 中吗?还是在落盘后?还是像 K ...
- RocketMQ源码详解 | Producer篇 · 其二:消息组成、发送链路
概述 在上一节 RocketMQ源码详解 | Producer篇 · 其一:Start,然后 Send 一条消息 中,我们了解了 Producer 在发送消息的流程.这次我们再来具体下看消息的构成与其 ...
- RocketMQ源码详解 | Producer篇 · 其一:Start,然后 Send 一条消息
概述 DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name"); ...
- Linux内核源码详解——命令篇之iostat[zz]
本文主要分析了Linux的iostat命令的源码,iostat的主要功能见博客:性能测试进阶指南——基础篇之磁盘IO iostat源码共563行,应该算是Linux系统命令代码比较少的了.源代码中主要 ...
- [转]Linux内核源码详解--iostat
Linux内核源码详解——命令篇之iostat 转自:http://www.cnblogs.com/york-hust/p/4846497.html 本文主要分析了Linux的iostat命令的源码, ...
随机推荐
- Jmeter系列(6)- 分析源码,创建登录、浏览商品接口请求
前言简介 接口的压力测试有个二八原则:线上80%的用户量在一天24小时20%(即4.8个小时)的时间里可以平稳运行,这个接口就算是通过压力测试了 源码分析 登录 浏览商品 创建请求 登录 浏览菜单 C ...
- hadoop报错
19/11/24 08:29:08 INFO qlh.MyMapreduce: ================this is job================= 19/11/24 08:29: ...
- re.findall用法
其中,re.findall() 函数可以遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表. 在python源代码中,展示如下: 搜索string,返回一个顺序访问每一个匹配结果(Match对象 ...
- P4320-道路相遇,P5058-[ZJOI2004]嗅探器【圆方树,LCA】
两题差不多就一起写了 P4320-道路相遇 题目链接:https://www.luogu.com.cn/problem/P4320 题目大意 \(n\)个点\(m\)条边的一张图,\(q\)次询问两个 ...
- 踩坑系列《五》 Incorrect datetime value: 时间添加失败原因
在进行单元测试中通过 new Date() 方式添加时间时,报了 Data truncation: Incorrect datetime value:这样的错误(我数据库表的时间类型是 datetim ...
- MD5加密算法的实现方式
MD5加密算法 MD5在我们平时项目中运用比较多,尤其是在用户注册的时候,密码存入数据库时可以利用MD5算法加密后存入,可以保证数据的安全性. 代码实现 public final class Md5U ...
- 在Windows Server 2012R2离线安装.net framework3.5
最近新装了一台Windows Server 2012 R2的服务器,安装数据库时,出现了提示安装不上 .net framework3.5的情况,经过网络上多次的资料查找及反复试验终于找到了一个可以解决 ...
- Java String的探讨
关于String相关内容的学习,历来都是Java学习必不可少的一个经历. 以前一直想要好好总结一下String的相关的知识点,苦于没有时间,终于在今天有一个闲暇的时间来好好总结一下,也希望这文章能够加 ...
- Java初步学习——2021.09.24每日总结,第三周周五
(1)今天做了什么: (2)明天准备做什么? (3)遇到的问题,如何解决? 今天学了将数组传递给方法和方法返回数组,其中传递的是数组的引用. 明天把例子做了,尽量把查找也学习了. 遇到了两个问题: 1 ...
- 北鲲云超算如何让仿真技术、HPC和人工智能之间的深度融合?
在CAE领域,随着仿真技术在多个行业的深度应用,也带来了仿真模型日益复杂.仿真过程数据倍增.仿真计算费用昂贵等问题,降阶模型.人工智能.云计算等多种技术和仿真技术的深度融合,成为了仿真技术的重要发展趋 ...