Pytorch系列:(六)自然语言处理NLP
这篇文章主要介绍Pytorch中常用的几个循环神经网络模型,包括RNN,LSTM,GRU,以及其他相关知识点。
nn.Embedding
在使用各种NLP模型之前,需要将单词进行向量化,其中,pytorch自带一个Embedding层,用来实现单词的编码。Embedding层 随机初始化了一个查询表,他可以将一个词转换成一个词向量。需要注意的是,Embedding层输入的是一个tensor long 类型,表示读取第多少个tensor,等于token的数量。
import torch.nn as nn
embeds = nn.Embedding(2,5)
word_to_ix = {"one":0,"hot":1}
token_id = torch.tensor([word_to_ix["one"]],dtype=torch.long)
one_embed = embeds(token_id)
RNN
计算公式如下:
\]
Pytorch中的RNN
nn.RNN(
input_size,
hidden_size,
num_layers,
nonlinearity,
bias,
batch_first,
dropout,
bidirectional
)
input_size: 输入维度
hidden_size:隐层维度,在RNN中也是输出的维度
num_layers :RNN的层数,默认为1
nonlinearity :非线性函数,默认为'tanh' , 也可以设置为'relu'
bias : 偏置参数,默认为True
batch_first : 输入向量第一维度是batch 还是 seq(序列长度), 默认为False
dropout :默认为0,设置是否在RNN层的末尾增加dropout操作
bidirectional : 是否为双向RNN,默认为False
RNN 中的输入与输出
out 等于所有step 中h 的输出的拼接
x : ( batch, seq , input_size) 当btach_first = True
h0 / ht : (num_layers, batch, hidden_size)
out : (batch, seq, hidden_size)
out , ht = RNN(x, h0)
举个例子,假设我们输入为 (3,10,100),表示3个batch,长度为10,每个单词表征为100维度。设置hidden_size 为20,这个时候,h的尺寸为[1,3,20]表示1层rnn,3个batch,20是隐层,然后out是[3,10,20].
rnn = nn.RNN(input_size =100,hidden_size = 20,batch_first=True)
x = torch.randn(3,10,100)
out, h = rnn(x,torch.zeros(1,3,20))
print(out.shape)
print(h.shape)
# [3,10,20]
# [1,3,20 ]
也可以直接查看RNN中的参数的尺寸
rnn = nn.RNN(100,20)
# rnn的参数名为:
# odict_keys(['weight_ih_l0','weight_hh_l0','bias_ih_l0','bias_hh_l0'])
print(rnn.weight_hh_l0.shape)
# [20,20]
多层RNN要注意的是要这是layer的双向设置,如何layer设置是双向的,那么 计算方式如下:
x : ( batch, seq , input_size) 当btach_first = True
h0 / ht : (num_layers2, batch, hidden_size) #只有这里有区别,num_layers2
out : (batch, seq, hidden_size)
RNNCell
RNNCell 计算公式和RNN一样,不过RNNCell每次运行只执行一步,因此,RNNCell的尺寸计算方式也会有所区别
RNNCell(
input_size,
hidden_size,
bias=True,
nonlinearity='tanh',
device=None,
dtype=None
)
输入输出尺寸:
xt : [batch, wordvec]
ht_1 / ht : [batch, hidden_size]
举个例子:
cell1 = nn.RNNCell(100,20)
xt = torch.randn(3,100)
h1 = cell1(xt, torch.randn(3,20))
print(h1.shape)
# [3,20]
LSTM
LSTM 的计算公式和结构图如下所示:包含四个门,输入门 i 控制多少信息可以输入,遗忘门f作用在先前的记忆c^{t-1} 上,作用是过滤一部分之前的记忆,输出门作用在新的记忆c^{t} 上,得到最终的输出h
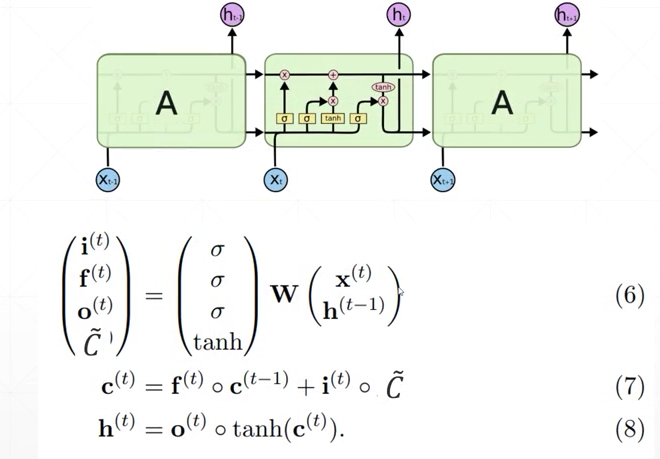
Pytorch 中的LSTM
在Pytorch中LSTM的使用跟RNN一样,区别是LSTM中的output有两个,一个是c一个是h,这里的c和h的尺寸大小是一样的。
nn.LSTM(
input_size,
hidden_size,
num_layers,
bias,
batch_first,
dropout,
bidirectional
)
input_size: 输入维度
hidden_size:隐层维度,在RNN中也是输出的维度
num_layers :RNN的层数,默认为1
nonlinearity :非线性函数,默认为'tanh' , 也可以设置为'relu'
bias : 偏置参数,默认为True
batch_first : 输入向量第一维度是batch 还是 seq(序列长度), 默认为False
dropout :默认为0,设置是否在RNN层的末尾增加dropout操作
bidirectional : 是否为双向RNN,默认为False
用法示例:
>>> rnn = nn.LSTM(10, 20, 2)
>>> input = torch.randn(5, 3, 10)
>>> h0 = torch.randn(2, 3, 20)
>>> c0 = torch.randn(2, 3, 20)
>>> output, (hn, cn) = rnn(input, (h0, c0))
LSTM 中的输入与输出
与RNN不一样的是,LSTM 中多了一个记忆参数c, 所以输入输出都多了c, 这里的c 和 h 的尺寸一模一样。
output, (hn, cn) = rnn(input, (h0, c0))
x : ( batch, seq , input_size) 当btach_first = True
h / c : (num_layers, batch, hidden_size)
output : (batch, seq, hidden_size) # h的拼接
一个例子:
lstm = nn.LSTM(input_size = 100,hidden_size=20,num_layer=4,batch_first=True)
x = torch.randn(3,10,100)
out, (h,c) = lstm(x)
print(out.shape,h.shape,c.shape)
# [3,10,20] [4,3,20] [4,3,20]
LSTMCell
同样的LSTM也有Cell版本,和上述RNNCell原理一样,都是只执行一个时间步
nn.LSTMCell(
input_size,
hidden_size,
bias=True,
device=None,
dtype=None
)
尺寸计算:
xt : [batch, wordvec]
h / c : [batch, hidden_size]
举个例子:
cell = nn.LSTMCell(100,20)
xt = torch.randn(3,100)
h = torch.zeros(3,20)
c = torch.zeros(3,20)
h_out, c_out = cell(xt, [h,c])
print(h_out.shape)
# [3,20]
通过LSTMCell 构建多层LSTM
cell1 = nn.LSTMCell(100,30)
cell2 = nn.LSTMCell(30,20)
h1 = torch.zeros(3,30)
c1 = torch.zeros(3,30)
h2 = torch.zeros(3,30)
c2 = torch.zeros(3,30)
for xt in x:
h1,c1 = cell1(xt,[h1,c1])
h2,c2 = cell2(h1,[h2,c2])
print(h2.shape,c2.shape)
# [3,20] [3,20]
GRU
GRU的工作原理如下图所示,其中,重置门rt 用于过滤一部分过去的信息,更新门zt 用来控制多少保留多少旧信息和输出多少新信息
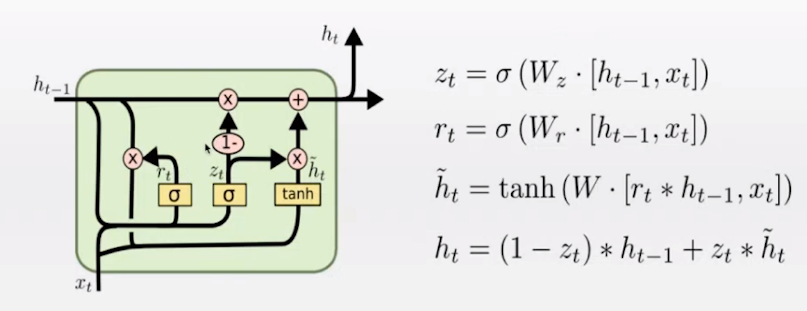
Pytorch 中的GRU
这里GRU的参数跟RNN的参数基本一样,区别是GRU中不能设置激活函数。
nn.GRU(
input_size,
hidden_size,
num_layers,
bias,
batch_first,
dropout,
bidirectional
)
input_size: 输入维度
hidden_size:隐层维度,在RNN中也是输出的维度
num_layers :RNN的层数,默认为1
bias : 偏置参数,默认为True
batch_first : 输入向量第一维度是batch 还是 seq(序列长度), 默认为False
dropout :默认为0,设置是否在RNN层的末尾增加dropout操作
bidirectional : 是否为双向RNN,默认为False
序列模型采样方法
针对一段长文本,如果要使用循环神经网络去训练,必须要做采样,因为循环神经网络无法做长序列学习,这里常用的采样方式有两种。
- 随机采样
随机的选取一段样本用来训练,这个时候,每一个batch中的尾巴和下一个batch 的头部是没有任何关联的,所以需要训练的时候,每一个batch后,需要重新初始化一下隐层,此外还需要对隐层进行detach,中断计算图。
- 相邻采样
令相邻的两个随机小批量在原始序列上的位置相毗邻, 这样由于相邻的batch是连接起来的,所以这个时候,只需要在第一个batch前初始化一个隐藏状态,无需在每个batch结束后初始化。另外,由于模型串联使得梯度计算开销增大,所以在这里依然还是要在每个batch 结束后进行detach操作,中断计算图。
完整示例
一个lstm网络示例,注意这里使用Glove来初始化Embedding权重,然后取LSTM最后一层的输出,喂入到线性层中。
class BLSTM(nn.Module):
def __init__(self,USE_GLOVE,pretrained_emb,token_size,batch_size,device):
super(BLSTM, self).__init__()
self.embedding = nn.Embedding(
num_embeddings=token_size,
embedding_dim=300
)
self.device = device
# Loading the GloVe embedding weights
if USE_GLOVE:
self.embedding.weight.data.copy_(torch.from_numpy(pretrained_emb))
self.text_lstm = nn.LSTM(300,150,num_layers=1,batch_first=True) #b,n,150
self.linear = nn.Sequential(
nn.Linear(150,125),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(125,32),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(32,1)
)
def forward(self,text_feat):
text_emb = self.embedding(text_feat)
first_lstm_out = []
init_h = torch.full((1,text_feat.shape[0],150),0).float().to(self.device)
init_c = torch.full((1,text_feat.shape[0],150),0).float().to(self.device)
out,_ = self.text_lstm(text_emb,[init_h,init_c])
out_pre = out[:,-1,:] # get last representation
output = self.linear(out)
return output
Pytorch系列:(六)自然语言处理NLP的更多相关文章
- 自然语言处理(NLP) - 数学基础(1) - 总述
正如我在<2019年总结>里说提到的, 我将开始一系列自然语言处理(NLP)的笔记. 很多人都说, AI并不难啊, 调现有库和云的API就可以啦. 然而实际上并不是这样的. 首先, AI这 ...
- 自然语言处理(NLP) - 数学基础(1) - 排列组合
正如我在<自然语言处理(NLP) - 数学基础(1) - 总述>一文中所提到的NLP所关联的概率论(Probability Theory)知识点是如此的多, 饭只能一口一口地吃了, 我们先 ...
- CSS 魔法系列:纯 CSS 绘制各种图形《系列六》
我们的网页因为 CSS 而呈现千变万化的风格.这一看似简单的样式语言在使用中非常灵活,只要你发挥创意就能实现很多比人想象不到的效果.特别是随着 CSS3 的广泛使用,更多新奇的 CSS 作品涌现出来. ...
- WCF编程系列(六)以编程方式配置终结点
WCF编程系列(六)以编程方式配置终结点 示例一中我们的宿主程序非常简单:只是简单的实例化了一个ServiceHost对象,然后调用open方法来启动服务.而关于终结点的配置我们都是通过配置文件来 ...
- SQL Server 2008空间数据应用系列六:基于SQLCRL的空间数据可编程性
原文:SQL Server 2008空间数据应用系列六:基于SQLCRL的空间数据可编程性 友情提示,您阅读本篇博文的先决条件如下: 1.本文示例基于Microsoft SQL Server 2008 ...
- R语言数据分析系列六
R语言数据分析系列六 -- by comaple.zhang 上一节讲了R语言作图,本节来讲讲当你拿到一个数据集的时候怎样下手分析,数据分析的第一步.探索性数据分析. 统计量,即统计学里面关注的数据集 ...
- java基础解析系列(六)---深入注解原理及使用
java基础解析系列(六)---注解原理及使用 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)---Integer ja ...
- Pytorch系列教程
介绍 不久前Pytorch发布了1.0版本,官网的doc页也更新了.这里说下官网的教程很实用,边学pytorch搭网络边学NLP-图像等领域的先进技术. 官网的教程都是英文的,本人就用这个系列博客做个 ...
- 【转载】PyTorch系列 (二):pytorch数据读取
原文:https://likewind.top/2019/02/01/Pytorch-dataprocess/ Pytorch系列: PyTorch系列(一) - PyTorch使用总览 PyTorc ...
- 自然语言处理NLP快速入门
自然语言处理NLP快速入门 https://mp.weixin.qq.com/s/J-vndnycZgwVrSlDCefHZA [导读]自然语言处理已经成为人工智能领域一个重要的分支,它研究能实现人与 ...
随机推荐
- IndentationError:unexpected indent”、“IndentationError:unindent does not match any outer indetation level”以及“IndentationError:expected an indented block Python常见错误
错误的使用缩进量 记住缩进增加只用在以:结束的语句之后,而之后必须恢复到之前的缩进格式. 经典错误,一定要注意缩进,尤其是在非界面化下环境的代码修改
- Jmeter(四十一) - 从入门到精通进阶篇 - Jmeter配置文件的刨根问底 - 下篇(详解教程)
1.简介 为什么宏哥要对Jmeter的配置文件进行一下讲解了,因为有的童鞋或者小伙伴在测试中遇到一些需要修改配置文件的问题不是很清楚也不是很懂,就算修改了也是模模糊糊的.更有甚者觉得那是禁地神圣不可轻 ...
- A. 【例题1】奶牛晒衣服
A . [ 例 题 1 ] 奶 牛 晒 衣 服 A. [例题1]奶牛晒衣服 A.[例题1]奶牛晒衣服 关于很水的题解 既然是最少时间,那么就是由最湿的衣服来决定的.那么考虑烘干机对最湿的衣服进行操作 ...
- 如何用 Electron + WebRTC 开发一个跨平台的视频会议应用
在搭建在线教育.医疗.视频会议等场景时,很多中小型公司常常面临 PC 客户端和 Web 端二选一的抉择.Electron 技术的出现解决了这一难题,只需前端开发就能完成一个跨平台的 PC 端应用.本文 ...
- Unity2D项目-平台、解谜、战斗! 0.1 序言:团队、项目提出、初步设计、剧情大纲
各位看官老爷们,这里是RuaiRuai工作室(以下简称RR社),一个做单机游戏的兴趣作坊. 本文跟大家聊一下社团内第一个游戏项目.算是从萌新项目组长的角度,从第一个里程碑的结点处,往前看总结一下项目之 ...
- 痞子衡嵌入式:在i.MXRT启动头FDCB里调整Flash工作频率也需同步设Dummy Cycle
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是Flash工作频率与Dummy Cycle的联系. 上一篇文章 <从头开始认识i.MXRT启动头FDCB里的lookupTable ...
- 期末考试复习c#时总结的抽象类与接口的一些区别
抽象类: (1)抽象类中可以定义抽象方法,属性,变量 (2)抽象类的派生类必须实现所有的抽象方法.要求所有的派生非抽象类都要用override重写实现抽象方法. (3)抽象类可以存放抽象方法,属性,也 ...
- linux安装cmake
1 概述 linux下安装cmake,目前最新的版本为3.17.0-rc2,安装的方式一共有三种:通过软件包仓库安装,通过编译好的版本进行安装,从源码手动编译安装. 2 仓库安装 笔者的是deepin ...
- Salesforce学习之路(六)利用Visualforce Page实现页面的动态刷新功能
Visualforce是一个Web开发框架,允许开发人员构建可以在Lightning平台上本地托管的自定义用户界面.其框架包含:前端的界面设计,使用的类似于HTML的标记语言:以及后端的控制器,使用类 ...
- JAVAEE_02_BS/CS架构
BS/CS架构 系统构架分为? C/S: Client/Server B/S: Browser/Server B/S的优缺点? 优点: 1. 不需要安装特定的客户端软件,只需要浏览器. 2. 升级只需 ...