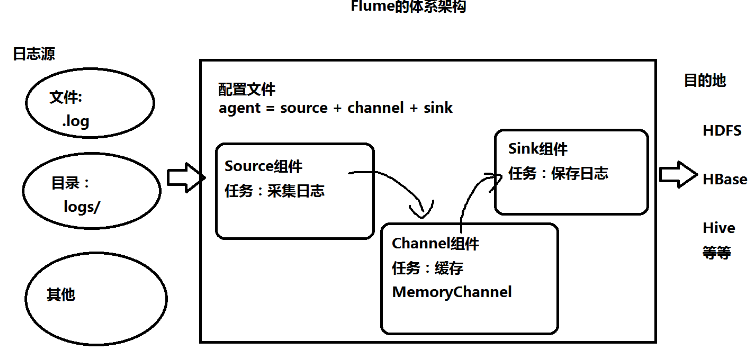
[BD] Flume
什么是Flume
- 采集日志,存在HDFS上
- 分布式、高可用、高可靠的海量日志采集、聚合和传输系统
- 支持在日志系统中定制各类数据发送方,用于收集数据
- 支持对数据进行简单处理,写到数据接收方
组件
- source:数据的来源
- avro:接收另一个flume的数据
- taildir:监控不断追加的日志文件
- channel:数据传输通道
- sink:数据落盘处
配置
- 配置文件


1 #bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
2 #定义agent名, source、channel、sink的名称
3 a4.sources = r1
4 a4.channels = c1
5 a4.sinks = k1
6
7 #具体定义source
8 a4.sources.r1.type = spooldir
9 a4.sources.r1.spoolDir = /root/training/logs
10
11 #具体定义channel
12 a4.channels.c1.type = memory
13 a4.channels.c1.capacity = 10000
14 a4.channels.c1.transactionCapacity = 100
15
16 #定义拦截器,为消息添加时间戳
17 a4.sources.r1.interceptors = i1
18 a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
19
20
21 #具体定义sink
22 a4.sinks.k1.type = hdfs
23 a4.sinks.k1.hdfs.path = hdfs://192.168.56.111:9000/flume/%Y%m%d
24 a4.sinks.k1.hdfs.filePrefix = events-
25 a4.sinks.k1.hdfs.fileType = DataStream
26
27 #不按照条数生成文件
28 a4.sinks.k1.hdfs.rollCount = 0
29 #HDFS上的文件达到128M时生成一个文件
30 a4.sinks.k1.hdfs.rollSize = 134217728
31 #HDFS上的文件达到60秒生成一个文件
32 a4.sinks.k1.hdfs.rollInterval = 60
33
34 #组装source、channel、sink
35 a4.sources.r1.channels = c1
36 a4.sinks.k1.channel = c1
命令
- 启动:bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
应用
- 采集网络传输信息
- node01安装flume,写配置文件,开启flume
- node02中telnet给node01发送信息
- 采集特定目录下新文件内容到HDFS
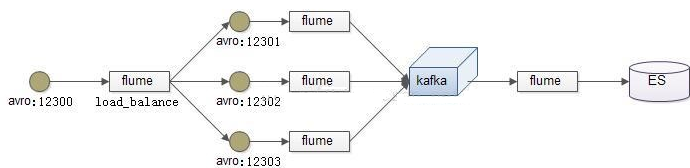
- 高可用(failover)
- agent1.sinkgroups.g1.processor.type = failover
- 停掉node02的agent,自动切换到node03上的agent
- 启动node02的agent,由于node02优先级高,自动切换回node02上的agent

- 负载均衡(load balancer)
- a1.sinkgroups.g1.processor.type = load_balance
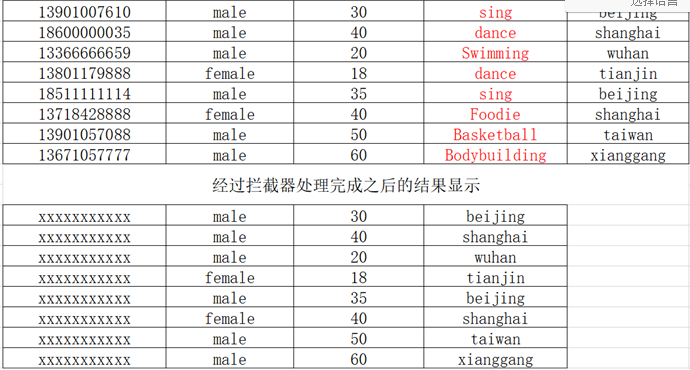
- 静态拦截器
- 将不同数据源的数据放在不同目录
- 自定义拦截器
- 数据采集后,将不需要的数据过滤掉,并将指定的第一个字段进行加密,再存到hdfs上
- a1.sources.r1.interceptors.i1.type =com.kkb.flume.interceptor.MyInterceptor$MyBuilder
- a1.sources.r1.interceptors.i1.encrypted_field_index=0
- a1.sources.r1.interceptors.i1.out_index=3



- 自定义source
- MySql数据采集到HDFS
参考
官方文档
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
快速入门
https://www.iteye.com/blog/manzhizhen-2298394
flume插件
https://www.cnblogs.com/mingfengshan/p/6853777.html
flume监控spoolDir日志到HDFS
https://blog.csdn.net/qq_20641565/article/details/52807776
avro sink 扩展
https://segmentfault.com/q/1010000023286882
source:avro
https://zhidao.baidu.com/question/373286862006114404.html
source:taildir
http://lxw1234.com/archives/2015/10/524.htm
[BD] Flume的更多相关文章
- flume的使用
1.flume的安装和配置 1.1 配置java_home,修改/opt/cdh/flume-1.5.0-cdh5.3.6/conf/flume-env.sh文件
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
- Flume(3)source组件之NetcatSource使用介绍
一.概述: 本节首先提供一个基于netcat的source+channel(memory)+sink(logger)的数据传输过程.然后剖析一下NetcatSource中的代码执行逻辑. 二.flum ...
- Flume(2)组件概述与列表
上一节搭建了flume的简单运行环境,并提供了一个基于netcat的演示.这一节继续对flume的整个流程进行进一步的说明. 一.flume的基本架构图: 下面这个图基本说明了flume的作用,以及f ...
- Flume(1)使用入门
一.概述: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统. 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- flume使用示例
flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受 ...
随机推荐
- kubernetes dashboard 2.0 部署
dashboard 可以从微软中国提供的 gcr.io :http://mirror.azure.cn/help/gcr-proxy-cache.html免费代理下载被墙的镜像 docker pull ...
- [2020年10月28日普级组]1408.MSWORLD
1408. M S W O R L D 1408.MSWORLD 1408.MSWORLD 题目描述 Bessie , Farmer John 的优选牛,刚刚获得了一个牛科动物选美比赛的冠军!并得到了 ...
- 2020 OO 第四单元总结 UML
title: 2020 OO 第四单元总结 date: 2020-06-14 19:10:06 tags: OO categories: 学习 1. 本单元三次作业的架构设计 本单元的代码编写与第三单 ...
- BUAA_OO_2020_第二单元总结
BUAA_OO_2020_第二单元总结 第一次 设计策略 本次作业采用生产者.消费者模式设计,大致框架如图所示: 生产者:输入线程 消费者:电梯线程 托盘:Dispatcher调度器 线程安全方面,调 ...
- 解决Deepin-wine-wechat-arch 文件不能正常发送
1 问题描述 系统Manjaro,使用Deepin-wine微信,目前最新的版本为2.9.5.56-1,发送图片时,会发送不成功,经常在转圈,对于发送其他文件会出现红色感叹号发送失败. 2 解决方法 ...
- Hive千亿级数据倾斜解决方案
数据倾斜问题剖析 数据倾斜是分布式系统不可避免的问题,任何分布式系统都有几率发生数据倾斜,但有些小伙伴在平时工作中感知不是很明显,这里要注意本篇文章的标题-"千亿级数据",为什么说 ...
- 安全高效跨平台的. NET 模板引擎 Fluid 使用文档
Liquid 是一门开源的模板语言,由 Shopify 创造并用 Ruby 实现.它是 Shopify 主题的主要构成部分,并且被用于加载店铺系统的动态内容.它是一种安全的模板语言,对于非程序员的受众 ...
- 11- client测试
client是客户端,软件分为客户端与服务端,客户端就是我们使用的软件,比如浏览器,QQ,抖音等.服务端就是客户端使用操作,服务端给你响应的请求.
- hdu4122 制作月饼完成订单的最小花费
题意: 有一个加工厂加工月饼的,这个工厂一共开业m小时,2000年1月1日0点是开业的第一个小时,每个小时加工月饼的价钱也不一样,然后每个月饼的保质期都是t天,因为要放在冰箱里保存,所以在 ...
- [CTF]ROT5/13/18/47编码
[CTF]ROT5/13/18/47编码 --------------------- 作者:adversity` 来源:CSDN 原文:https://blog.csdn.net/qq_4083 ...