简述LSM-Tree
LSM-Tree
1. 什么是LSM-Tree
LSM-Tree 即 Log Structrued Merge Tree,这是一种分层有序,硬盘友好的数据结构。核心思想是利用磁盘顺序写性能远高于随机写。
LSM-Tree 并不是一种严格的树结构,而是一种内存+磁盘的多层存储结构。HBase、LevelDB、RocksDB这些 NoSQL 存储都使用了 LSM-Tree。
2. LSM的组成部分
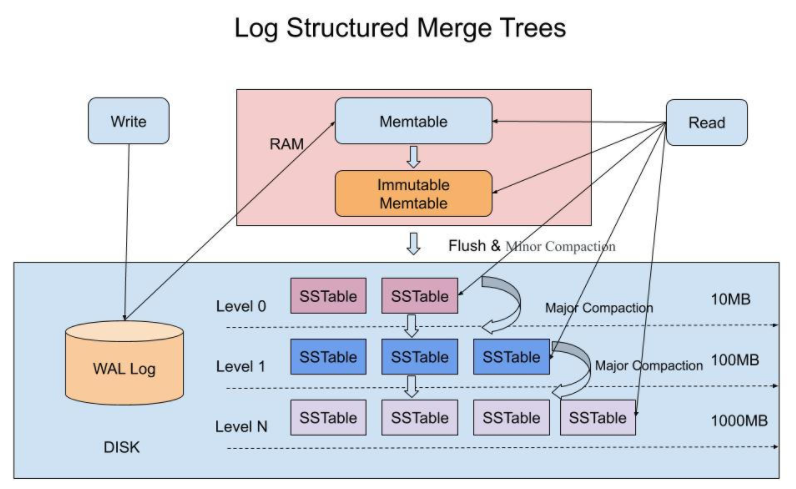
2.1 MemTable
MemTable 是 LSM-Tree 在内存中的数据结构,只用于保存最新的数据,按照 Key 有序地组织这些数据。
LSM-Tree 没有规定用怎样的数据结构实现 MemTable,例如 HBase 使用跳表来保证内存中 Key 的有序性。
存在内存中的数据会因为断电丢失,所以我们通常使用 WAL,即预写日志的方式来保证数据的可靠。
WAL:预写日志,即事务的所有修改在提交之前要先写入 log 文件中
2.2 Immutable MemTable
MemTable 达到一定大小后,会转化为 Immutable MemTable。Immutable MemTable 是将 MemTable 转为磁盘上的 SSTable 的一种中间状态。
转化过程中写操作由新的 MemTable 处理,过程中不阻塞数据更新操作。
2.3 SSTable
SSTable 是有序键值对集合,是 LSM 树在磁盘中的数据结构。它是一种持久化、有序且不可变的键值村存储结构
SSTable 内部包含一系列可配置大小的 Block 块。这些 Block 的 index 会被存储在 SSTable 的尾部,用于帮助快速查找特定的 Block。当一个 SSTable 被打开时,index 表会被加载到内存,然后根据 key 在内存 index 中进行一个二分查找,查到该 key 对应的磁盘的 offset 后,去磁盘把响应的块数据读取出来。

当然,如果内存足够大,可以直接利用 MMAP 的技术把 SSTable 映射到内存中,提供更快的查找。
MemTable 达到一定大小会被 flush 到硬盘中变成 SSTable。在不同的 SSTable 中可能存在相同的 Key 记录。但这样会带来一些问题:
- 冗余存储。对于某个 Key,除了最新的记录,其他记录都是冗余无用的。所以我们需要进行 Compact 操作(合并多个 SSTable),来清除冗余的记录。
- 读取时需要从最新的 SSTable 出发进行查询,最坏情况下药查询完所有的 SSTable。可以通过索引或布隆过滤器来优化查找速度。
3. LSM-Tree读写数据
3.1 LSM-Tree写数据流程
LSM 树中,我们按照下面的步骤处理写数据请求。
- 当收到写请求,先将数据记录在 WAL Log 中,用作故障恢复。
- 将数据写入内存的 MemTable 中。为了有序,我们往往用跳表或红黑树实现。
- 如果是删除,则做墓碑标记
- 如果是更新,则新记录一条数据。
- MemTable 达到一定大小后,在内存中冻结,成为不可变的 ImmuTable MemTable。同时也要生成新的 MemTable 来提供服务。
- 内存中不可变的 MemTable 被 dump 到硬盘上的 SSTable 中,这也称为 Minor Compaction。注意 L0 层的 SSTable 是没有合并的,所以 key 在多个 SSTable 中往往会重叠、冗余。
- 当每层 SSTable 超过一定大小,就会周期性的进行合并,这也称为 Major Compaction。这个阶段回清除掉荣誉的数据,防止浪费空间。由于 SSTable 都是有序的,可以使用归并排序进行高效合并。
3.2 LSM-Tree读数据流程
- 当收到读请求,现在内存中查询,查询到就返回。
- 如果没有查询到,由内存到磁盘,在各级 SSTable 中依次下沉,直到得到结果。
4. LSM-Tree的Compact策略
Compact 是 LSM 树中的关键操作,只有 Compact 的策略合理,才能及时有效地清除冗余的数据。
先介绍以下几个概念:
- 读放大。读取数据时实际读取的数据量大于真正的数据量。例如在不同层次的 Table 中查找。
- 写放大。写入数据时实际写入的数据量大于真正的数据量。例如写入时触发 Compact,导致写入大量数据。
- 空间放大。数据占用的磁盘空间比真正的数据大小要大很多。即冗余存储。
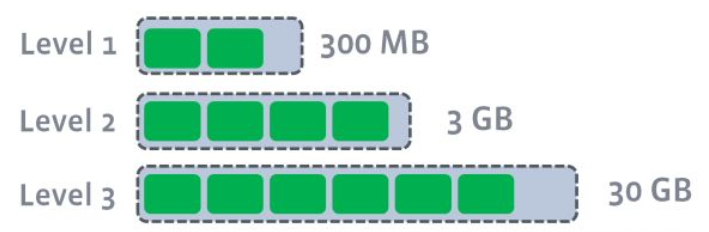
4.1 size-tiered策略

size-tiered 策略保证每层中每个 SSTable 的大小相近,同时限制每一层 SSTable 的数量。
如上图,每层限制有 N 个 SSTable,每层数量达到 N 后,触发 Compact 操作来合并这些 SSTable,放入下一层成为更大的 SSTable
当层数越来越大,单个 SSTable 的大小也会越来越大。该策略会导致空间放大比较严重。对每一层的 SSTable 来说,每个 key 的记录也可能存在多份。只有该层执行 Compact 操作才会消除这些冗余记录。
4.2 leveled策略
leveled 策略限制每一层总文件的大小。
leveld 同样将每一层划分为大小相近的 SSTable。并保证在一层内全局有序。这意味着与一个 Key 在每一层至多只有一条记录,不存在冗余记录。
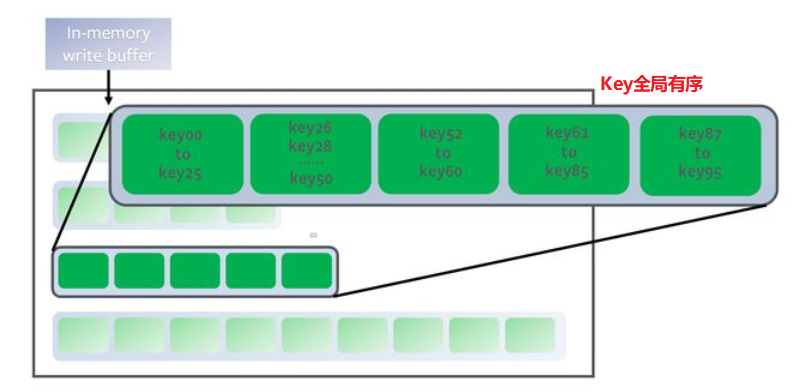
下面展示 leveled 的 Compact 策略
Ⅰ. L1 总大小超过 L1 本身大小限制。
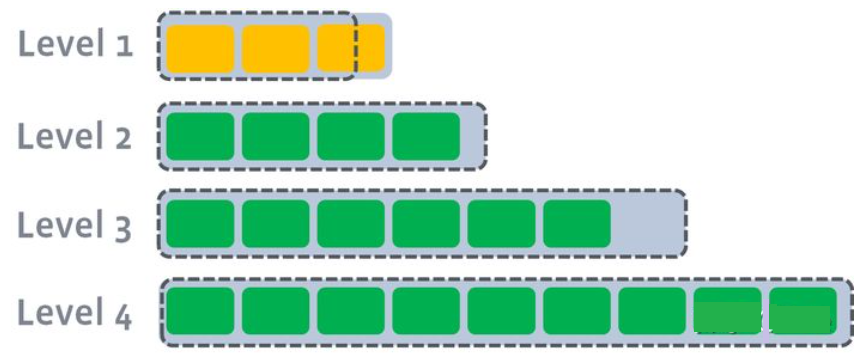
Ⅱ. LSM 树从 L1 中选择至少一个文件,然后把他和 L2 有交集的部分进行合并。生成的文件放在 L2。
如下图,L1 第二个 SSTable 的 Key 的范围覆盖了 L2 中前三个 SSTable,那么就需要将 L1 中第二个 SSTable 与 L2 中前三个 SSTable 执行 Compact。
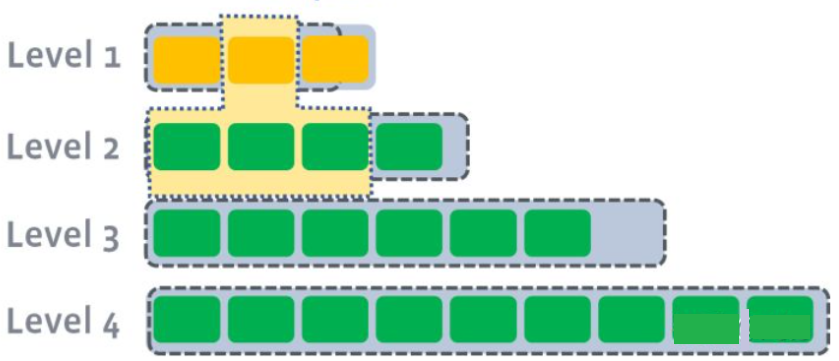
Ⅲ. 如果 L2 合并后的大小超过 L2 的限制大小。则重复之前的操作,选至少一个文件然后合并到下一层。
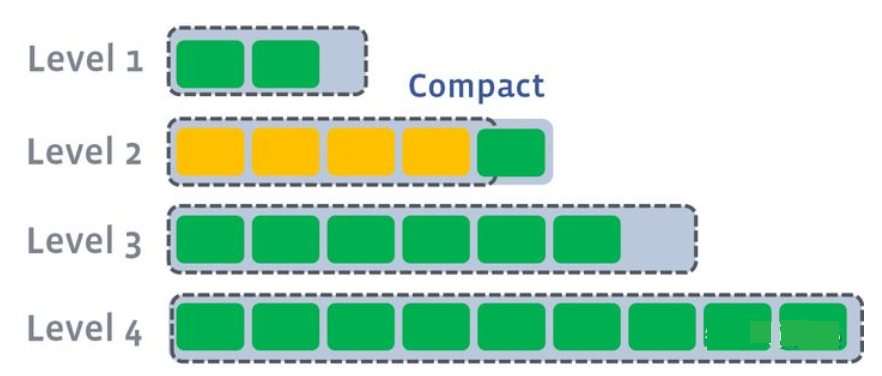
多个不相干的合并可以并发进行
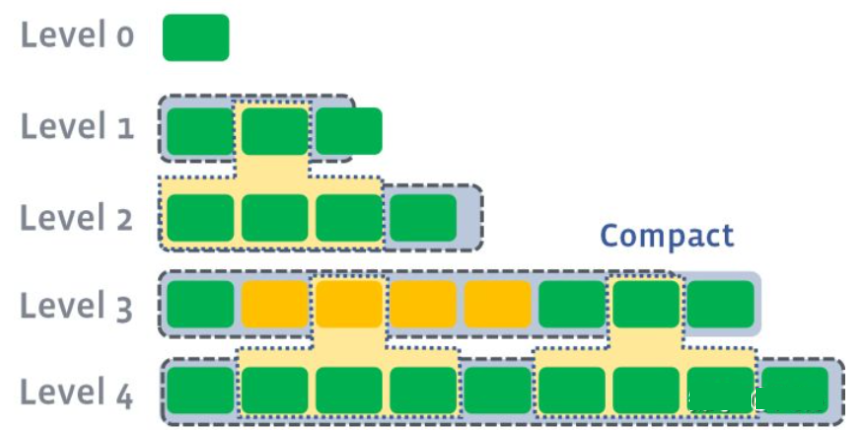
leveled 策略相比 size-tiered 策略来说,每层内的 Key 是有序、不重复的。这样就很好地控制了冗余 Key 的量。
5. 查询优化
查询过程中我们发现,在原始情况下,我们需要遍历所有的 SSTable。我们考虑以下方式,尝试优化查询的效率。
- 压缩。SSTable可以进行压缩,而且不是压缩整个 SSTable。而是根据局部性原理将数据分组。每个分组分别压缩。这样读取数据的时候我们就不需要解压缩整个文件,而是解压缩部分 Group 即可读取。
- 缓存。SSTable 除了进行 Compaction,其他情况下是不可变的。所以我们可以将一次扫描到的 Block 进行缓存,提高下一次检索的效率。
- 索引/布隆过滤器。正常情况下,一次读操作需要读取所有 SSTable,再将结果合并后返回。但是对某些 Key 而言,有些 SSTable 根本不包含对应数据。所以我们可以为每个 SSTable 添加布隆过滤器。来判断当前 SSTable 有没有我们需要的 Key。
- 合并。合并本身肯定可以优化数据的组织情况,提高查询效率。但是也要注意查询是非常消耗 CPU 和磁盘 IO 的操作。一般我们选在业务量不大的凌晨等情况进行合并。
6. LSM-Tree和B-Tree的比较
- LSM-Tree 的写放大问题比 B-Tree 要好一些。因为 B 树写入的页分裂操作实在太消耗磁盘 IO。
- LSM-Tree 可以支持更好的压缩。由于碎片,B-Tree 无法使用某些磁盘空间,而 LSM-Tree 会定期重写来消除碎片。
- LSM_Tree 在执行压缩操作时,很容易发生读写请求等待的问题。而 B-Tree 的响应延迟则更具确定性。
- B-Tree 中的每个键都位于索引中的每个位置,而日志结构的存储引擎可能在不同的段中有相同键的多个副本。如果数据库希望提供严格的事务语义,B-Tree 要更容易实现一些,因为锁可以定义到树中。
简述LSM-Tree的更多相关文章
- LSM Tree存储组织结构介绍
LSM Tree(Log Structured Merge Trees)数据组织方式被应用于多种数据库,如LevelDB.HBase.Cassandra等,下面我们从为什么使用LSM tree.LSM ...
- LSM Tree解析
引言 众所周知传统磁盘I/O是比较耗性能的,优化系统性能往往需要和磁盘I/O打交道,而磁盘I/O产生的时延主要由下面3个因素决定: 寻道时间(将磁盘臂移动到适当的柱面上所需要的时间,寻道时移动到相邻柱 ...
- LSM Tree 学习笔记——本质是将随机的写放在内存里形成有序的小memtable,然后定期合并成大的table flush到磁盘
The Sorted String Table (SSTable) is one of the most popular outputs for storing, processing, and ex ...
- LSM Tree 学习笔记——MemTable通常用 SkipList 来实现
最近发现很多数据库都使用了 LSM Tree 的存储模型,包括 LevelDB,HBase,Google BigTable,Cassandra,InfluxDB 等.之前还没有留意这么设计的原因,最近 ...
- Log-Structured Merge Tree (LSM Tree)
一种树,适合于写多读少的场景.主要是利用了延迟更新.批量写.顺序写磁盘(磁盘sequence access比random access快). 背景 回顾数据存储的两个“极端”发展方向 加快读:加索引( ...
- 数据映射-LSM Tree和SSTable
Coming from http://blog.sina.com.cn/s/blog_693f08470101njc7.html 今天来聊聊lsm tree,它的全称是log structured m ...
- 【万字长文】使用 LSM Tree 思想实现一个 KV 数据库
目录 设计思路 何为 LSM-Treee 参考资料 整体结构 内存表 WAL SSTable 的结构 SSTable 元素和索引的结构 SSTable Tree 内存中的 SSTable 数据查找过程 ...
- InfluxDB存储引擎Time Structured Merge Tree——本质上和LSM无异,只是结合了列存储压缩,其中引入fb的float压缩,字串字典压缩等
The New InfluxDB Storage Engine: Time Structured Merge Tree by Paul Dix | Oct 7, 2015 | InfluxDB | 0 ...
- sstable, bigtable,leveldb,cassandra,hbase的lsm基础
先看懂文献1和2 1. 先了解sstable.SSTable: Sorted String Table [2] [10] WiscKey: 类似myisam, key value分离, 根据ssd优 ...
- NoSQL生态系统——事务机制,行锁,LSM,缓存多次写操作,RWN
13.2.4 事务机制 NoSQL系统通常注重性能和扩展性,而非事务机制. 传统的SQL数据库的事务通常都是支持ACID的强事务机制.要保证数据的一致性,通常多个事务是不可能交叉执行的,这样就导致了可 ...
随机推荐
- 《剑指offer》面试题57. 和为s的两个数字
问题描述 输入一个递增排序的数组和一个数字s,在数组中查找两个数,使得它们的和正好是s.如果有多对数字的和等于s,则输出任意一对即可. 示例 1: 输入:nums = [2,7,11,15], tar ...
- 【记录一个问题】golang中copy []byte类型的slice无效,为什么?
有这样一段代码: src := []byte{xxxxx} dst := make([]byte, 0, len(src)) copy(dst, src) //这一行居然没生效! // dst = a ...
- 【测试数据】android下CPU核与线程数的关系
测试方法 24MB的一张4K图片,连续计算5次直方图. 小米mix2s, 高通骁龙 845.4大核,4小核. 数据表格 线程数 绝对时间(s) 累计CPU时间(s) 每线程平均耗时(us) 每线程最大 ...
- golang中math常见数据数学运算
package main import ( "fmt" "math" ) func main() { fmt.Println(math.Abs(-19)) // ...
- postgresql安装(windows)
官网: https://www.postgresql.org/ 下载页面:https://www.enterprisedb.com/downloads/postgres-postgresql-down ...
- 手把手教你丨小熊派移植华为 LiteOS-M
摘要:本文详细讲解如何移植 LiteOS 到小熊派. 本文分享自华为云社区<小熊派移植华为 LiteOS-M(基于MDK)>,作者: JeckXu666. 前言 之前使用小熊派实现了鸿蒙动 ...
- hadoop面试
hadoop.apache.orgspark.apache.orgflink.apache.orghadoop :HDFS/YARN/MAPREDUCE HDFS读写流程 NameNode DataN ...
- react直接使用bootstrap失效的原因
react用的是className!而不是class~
- 2022.02.04 Day1
前言 为日后的算法面试做准备,自己也很喜欢算法这个东西,每天3~5道题. 刷题 1.leetcode 209 长度最下的子数组 题目 长度最下的子数组 大致的意思是从数组中找到长度最小的数组,并且数组 ...
- 用Json给表单赋值
$.extend({ setForm :function(frm,jsonValue) { var obj=$(frm); $.each(jsonValue, function (name, ival ...