Zookeeper集群搭建及原理
1 概述
1.1 简介
ZooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效、高可用的分布式协调服务,提供了诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知和分布式锁等分布式基础服务。由于 ZooKeeper 便捷的使用方式、卓越的性能(基于内存)和良好的稳定性,被广泛地应用于诸如 Hadoop、HBase、Kafka 和 Dubbo 等大型分布式系统中。
官方地址:https://zookeeper.apache.org
1.2 角色
领导者(leader):负责进行投票的发起和决议,更新系统状态。
跟随者(follower):用于接收客户端请求并给客户端返回结果,在选主过程中进行投票。
观察者(observer):可以接受客户端连接,将写请求转发给 leader,但是observer 不参加投票的过程,只是为了扩展系统,提高读取的速度。

1.3 节点特性
ZooKeeper 节点的生命周期取决于节点的类型。在 ZooKeeper 中,节点根据持续时间可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL),根据是否有序可以分为顺序节点(SEQUENTIAL)、和无序节点(默认是无序的)。每个客户端连接zookeeper会产生一个session,客户端连接关闭时session也会消失。
持久节点一旦被创建,除非主动移除,不然一直会保存在 Zookeeper 中(不会因为创建该节点的客户端的会话失效而消失)。
1.3 数据模型
层次化的目录结构,命名符合常规文件系统规范,类似于文件目录。
每个节点在 Zookeeper 中叫做 Znode,并且其有一个唯一的路径标识。
每个节点中数据存储不能超过1M(不要把Zookeeper当数据库用)。
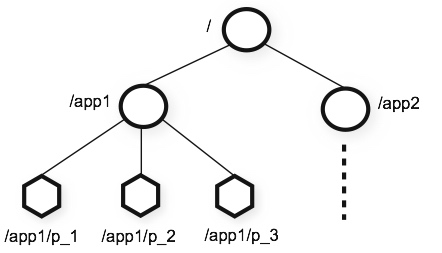
1.4 特性
顺序一致性。客户端的更新将按发送顺序应用。
原子性。要么成功要失败。没有中间状态(最终一致性)。
单个系统映像。由于zookeeper使用复制集群,无论客户端连接哪个节点都能看到相同的数据。
可靠性。即所有节点支持持久化。
及时性。存储在节点中的数据会在较短时间内及时同步。
2 zookeeper集群搭建
2.1 网络拓扑
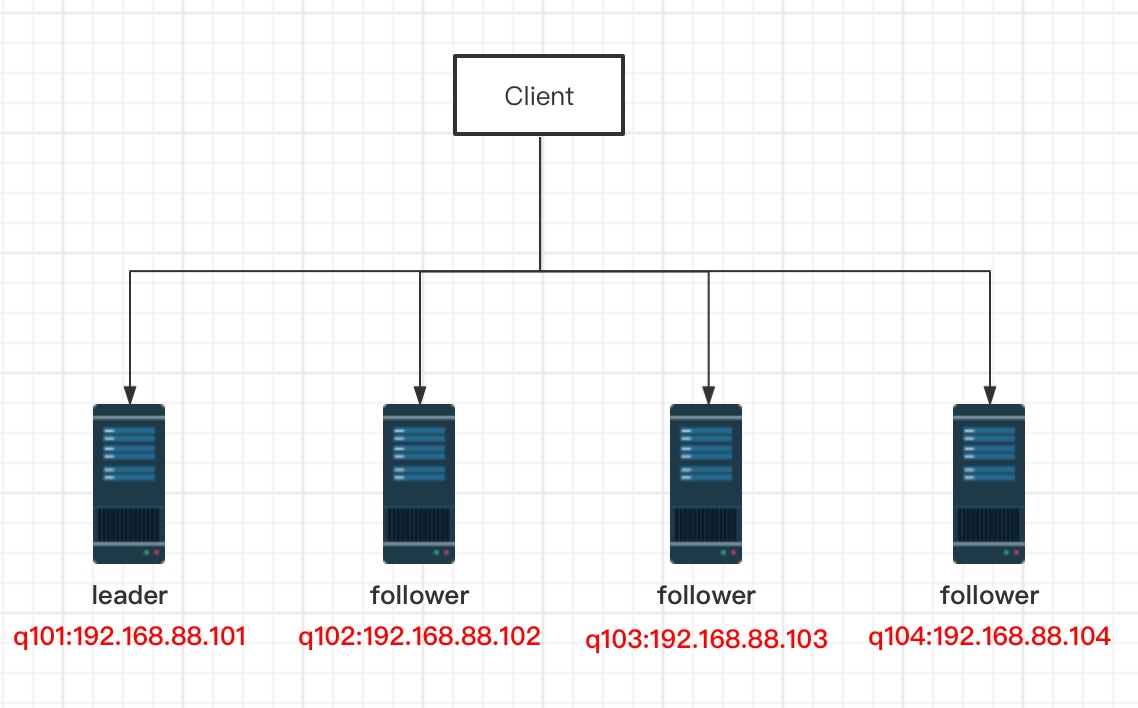
2.2 环境准备
CentOS7 * 4
JDK8
Zookeeper3.6.3
2.3 安装
在q101服务器中配置好后发送到其他服务器。q101操作如下:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz --no-check-certificate
tar xf apache-zookeeper-3.6.3-bin.tar.gz
mv apache-zookeeper-3.6.3-bin /usr/local/zookeepe
cd /usr/local/zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
# 1. 修改dataDir路径为“/var/zookeeper”
# 2. 增加集群节点信息,信息如下
server.4=192.168.88.101:2888:3888
server.3=192.168.88.102:2888:3888
server.2=192.168.88.103:2888:3888
server.1=192.168.88.104:2888:3888
# 3. 保存退出
# 创建配置文件中设置的持久化目录
mkdir /var/zookeeper
# 将节点信息中的节点ID写如myid中
echo 4 > /var/zookeeper/myid
# 修改环境变量 增加zookeeper信息
# export ZOOKEEPER_HOME=/usr/local/zookeeper
# 在export PATH末尾追加 :$ZOOKEEPER_HOME/bin
vi /etc/profile
source /etc/profile

详细配置说明
# leader和follower心跳时间,用于维护节点是否存活。单位毫秒
tickTime=2000
# 初始延迟。当follower追随leader时,leader允许初始延迟时间。
# 用tickTime乘以initLimit,此处为2000*10即20秒
initLimit=10
# 数据同步时间,及超过时间数据同步失败。
# 用tickTime乘以syncLimit,此处为2000*5即10秒
syncLimit=5
# 持久化目录,不建议存在tmp下
dataDir=/var/zookeeper
# 客户端连接zookeeper端口号
clientPort=2181
# 允许客户端连接最大连接数
#maxClientCnxns=60
# dataDir中保留快照数量
#autopurge.snapRetainCount=3
# 清除任务时间间隔,单位小时。0表示禁用自动清楚功能
#autopurge.purgeInterval=1
# 自定义监控
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
# 此处为自己添加的配置。集群信息,投票过半数量=(集群节点行数 除以 2)+1
# 数字1,2,3,4为节点ID,用于谦让出leader,投票过半后数字最大的为leader
# 端口说明:当leader挂掉后(或第一次启动没有leader时候)其他节点通过3888建立连接进行投票选出leader,
# 选中leader后,leader会通过2888端口来与follower进行工作
server.4=192.168.88.101:2888:3888
server.3=192.168.88.102:2888:3888
server.2=192.168.88.103:2888:3888
server.1=192.168.88.104:2888:3888
将q101相关文件传到q102并修改myid
scp -r /usr/local/zookeeper 192.168.88.102:/usr/local/
scp -r /var/zookeeper 192.168.88.102:/var/
scp /etc/profile 192.168.88.102:/etc
# 切换到q102服务器执行,数字与配置文件中的节点ID数据一致
echo 3 > /var/zookeeper/myid
# q102执行 使环境变量生效
source /etc/profile
将q101相关文件传到q103并修改myid
scp -r /usr/local/zookeeper 192.168.88.103:/usr/local/
scp -r /var/zookeeper 192.168.88.102:/var/
scp /etc/profile 192.168.88.103:/etc
# 切换到q103服务器执行
echo 2 > /var/zookeeper/myid
source /etc/profile
将q101相关文件传到q104并修改myid
scp -r /usr/local/zookeeper 192.168.88.103:/usr/local/
scp -r /var/zookeeper 192.168.88.102:/var/
scp /etc/profile 192.168.88.104:/etc
# 切换到q104服务器执行
echo 1 > /var/zookeeper/myid
source /etc/profile
2.4 启动
为了测试我们采用前台启动,4台节点分别执行
zkServer.sh start-foreground
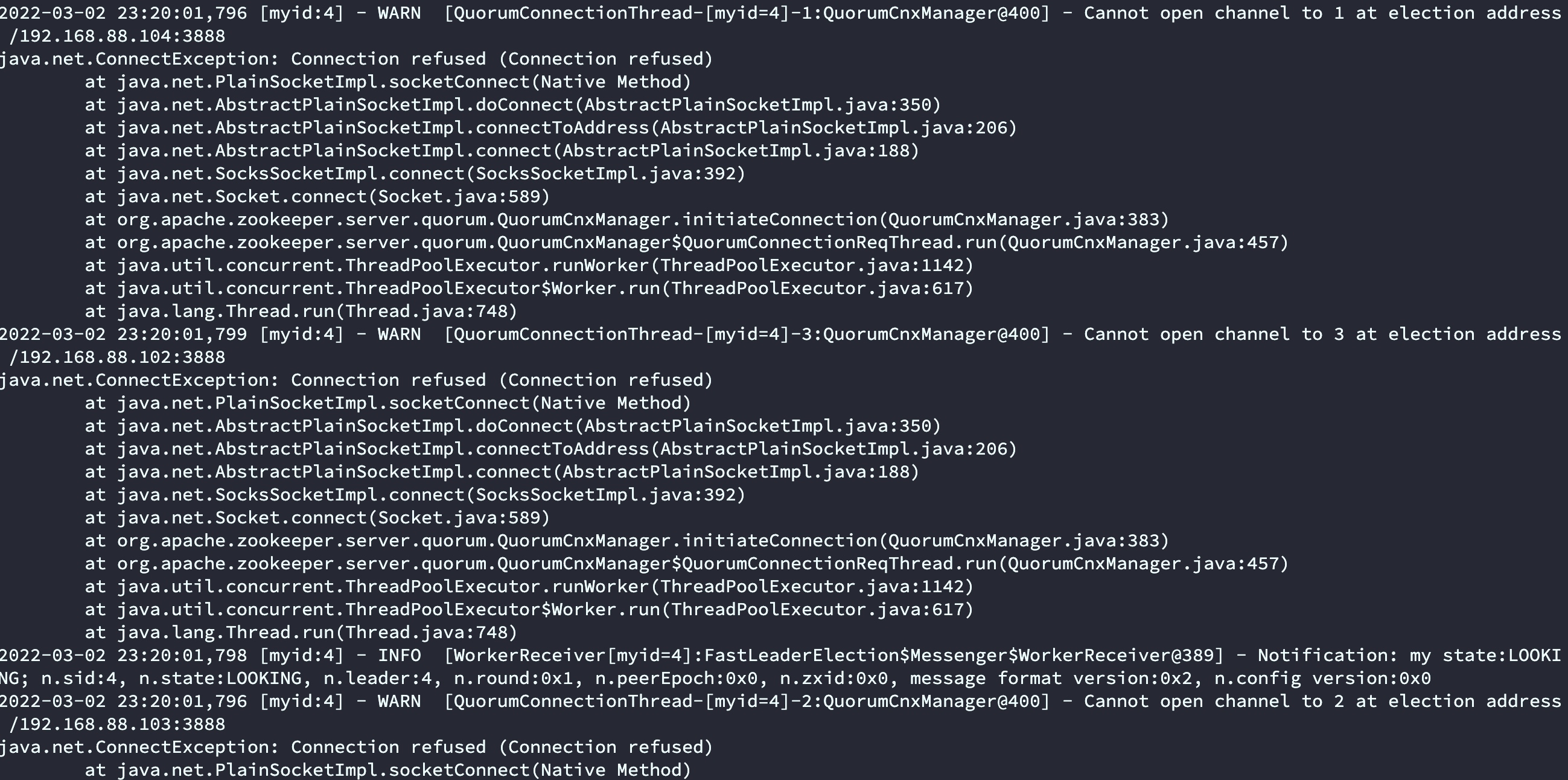
启动前3台的时候会发现报错,连接其他节点失败,属于正常情况,当启动最后一台的时候发现没有发错了。原因是启动前2台的时候没有leader。当第3台启动完成的时候,此时节点数量已经超过半数,所以开始根据zoo.cfg配置文件中的服务ID进行选举,因为q101服务器ID 设置的4,按节点谦让规则q101为leader。
启动错误信息如下:
节点角色验证
在q101执行
zkServer.sh status

3 zookeeper常用功能
3.1 常用命令
启动关闭
后台启动:zkServer.sh start
前台启动:zkServer.sh start-foreground
停止:zkServer.sh stop
重启:zkServer.sh restart
查看版本:zkServer.sh version
查看状态:zkServer.sh status
连接与退出
连接zookeeper客户端:zkCli.sh -server 127.0.0.1:2181 连接本机可以直接输入zkCli.sh
退出zookeeper客户端:quit
操作命令
查看zookeeper所有命令:连接到zookeeper客户端后输入help
查看根目录下包含的节点:ls /
查看节点状态信息:ls2 / 或者使用 ls -s /
创建一个非顺序的持久化节点:create [-s] [-e] path data acl 比如 create /test test-1
创建一个临时节点:create -e /test/tmp tem-data
创建一个顺序节点:create -s /test/aaa aaa-data
删除一个节点:delete /test
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] create /abc
Created /abc
[zk: localhost:2181(CONNECTED) 3] ls /
[abc, zookeeper]
# 创建节点后默认数据为null
[zk: localhost:2181(CONNECTED) 9] get /abc
null
[zk: localhost:2181(CONNECTED) 4] create /abc/abcd
Created /abc/abcd
[zk: localhost:2181(CONNECTED) 15] set /abc/abcd hello
[zk: localhost:2181(CONNECTED) 16] get /abc/abcd
hello
3.2 stat结构
Zookeeper每个znode都有一个与之关联的stat结构,类似于Unix/Linux文件系统中文件的stat结构。通过stat /xxx/xxx查看
[zk: localhost:2181(CONNECTED) 17] stat /abc/abcd
cZxid = 0x100000003
ctime = Wed Mar 02 23:41:34 CST 2022
mZxid = 0x100000006
mtime = Wed Mar 02 23:43:32 CST 2022
pZxid = 0x100000003
cversion = 0
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
字段含义:
cZxid:创建节点znode时的事务ID由leader维护的递增计数器,共64位,其中前32为表示leader纪元,即leader革新换代次数,比如上面的0x1表示目前leader为做变更,如当前leader关闭后重新选举的leader此处会变成0x2,并且后32位的事务ID重新开始;后32为表示所有的增删改操作次数。
mZxid:修改节点znode更改的事务ID。
pZxid:添加或删除子节点znode更改的事务ID。
ctime:表示从1970-01-01T00:00:00Z开始以毫秒为单位的znode创建时间。
mtime:表示从1970-01-01T00:00:00Z开始以毫秒为单位的znode最近修改时间。
dataVersion:表示对该znode的数据所做的更改次数。
cversion:表示对此znode的子节点进行的更改次数。
aclVersion:版本号,即znode的ACL进行更改的次数。
ephemeralOwner:如果znode是ephemeral类型节点,则这是znode所有者的 session ID。 如果znode不是ephemeral节点,则该字段设置为零。
dataLength:这是znode数据字段的长度。
numChildren:这表示znode的子节点的数量。
3.3 临时节点
临时节点伴随着session会话,当会话结束后临时节点销毁
- 通过q101连接zookeeper客户端查看日志

通过日志发现sessionID为:0x400000595cc0001
2. 创建临时节点 create -e /xxxx
create -e /aaa
- 通过stat查看发现刚创建的临时节点“bbbb”的ephemeralOwner正是连接时候的sessionID
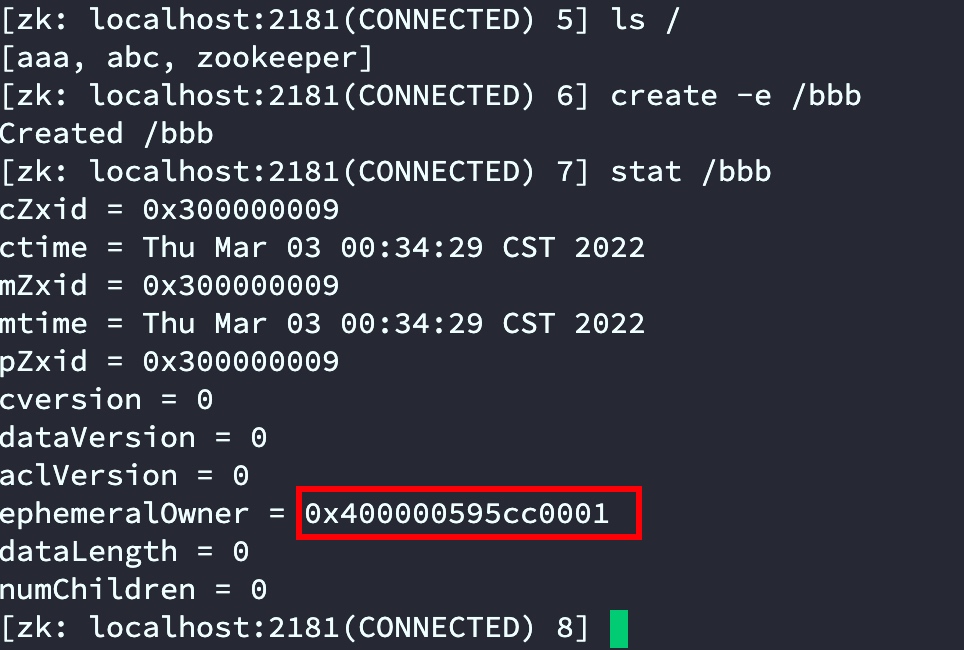
当使用另一台服务器q102连接zkCli后查看aaa节点stat sessionID依旧是q101连接的sessionID。
3.4 持久序列
通过create -s path data可以创建持久序列,znode被创建后,znode名称会自动添加一个编号,编号会自动递增。编号的递增和节点名称无关.
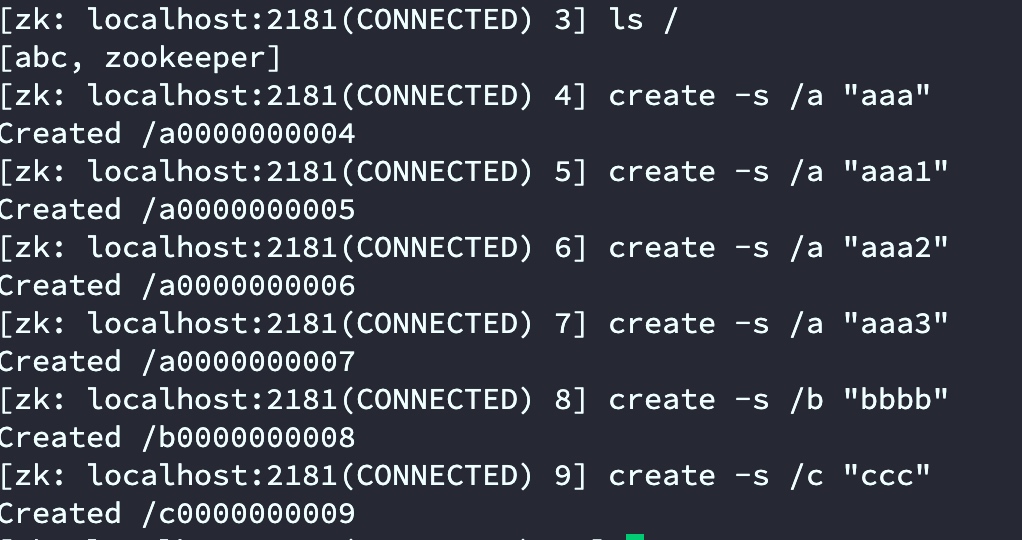
编号的递增不会因为断开而重置,也不会因为zookeeper重启而重置
4 zookeeper原理
4.1 Paxos算法
它是一个基于消息传递的一致性算法,Leslie Lamport在1990年提出,近几年被广泛应用于分布式计算中,Google的Chubby,Apache的Zookeeper都是基于它的理论来实现的,Paxos还被认为是到目前为止唯一的分布式一致性算法,其它的算法都是Paxos的改进或简化。有个问题要提一下,Paxos有一个前提:Paxos只有在一个可信的计算环境中才能成立,这个环境是不会被入侵所破坏的。
关于Paxos的具体描述可以参考:https://baike.baidu.com/item/Paxos算法
4.2 ZAB协议
ZAB(ZooKeeper Atomic broadcast)即ZooKeeper原子消息广播协议,类似于一个二阶段提交过程(2PC)属于最终一致性。是zookeeper基于Paxos算法的简化实现。
所有事务请求必须由一个全局唯一的服务器来协调处理,这样的服务器被称为 Leader服务器,而余下的其他服务器则成为 Follower服务器。 Leader服务器负责将一个客户端事务请求转换成一个事务 Proposal(提议),并将该 Proposal分发給集群中所有的Follower服务器。之后 Leader服务器需要等待所有 Follower服务器的反馈,一旦超过半数的 Follower服务器进行了正确的反馈后,那么 Leader就会再次向所有的 Follower服务器分发 Commit消息,要求其将前一个 Proposal进行提交。
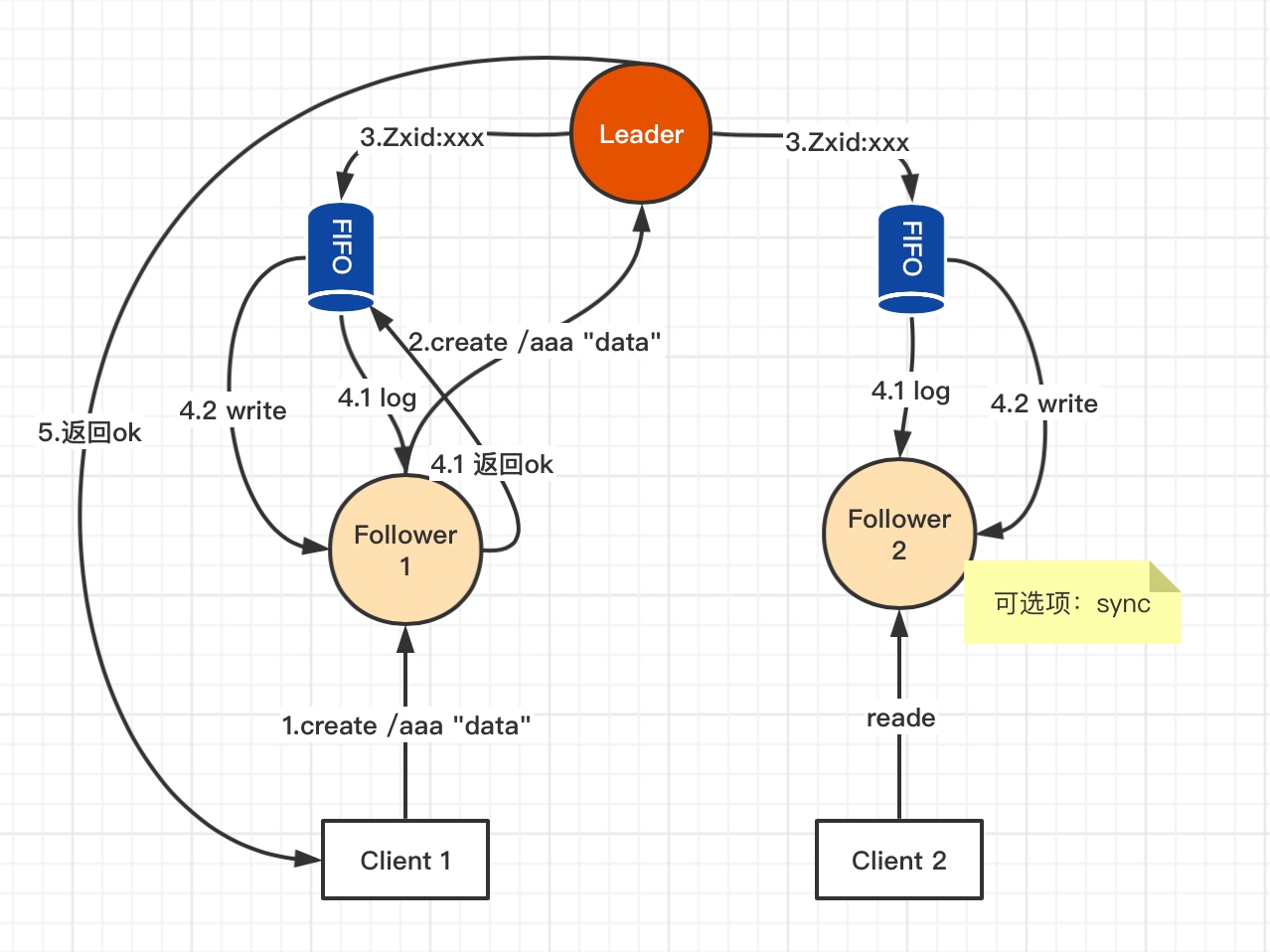
上图说明:
1:Client向Follower发出写操作;
2:Follower将收到的写请求转发给Leader处理;
3:Leader收到请求后分配一个全局单调递增的唯一的事务ID(即ZXID,按其先后顺序来进行排序与处理);
4.1:Leader服务器会为每一个 Follower服务器都各自分配一个单独的队列,然后将需要广播的事务Proposal依次放入这些队列中去,并且根据FIFO策略进行消息发送;每一个 Follower服务器在接收到这个事务 Proposal之后,都会首先将其以事务日志的形式写入到本地磁盘中去,并且在成功写入后反馈给 Leader服务器个Ack响应。Leader自己也会将事务日志写入磁盘;
4.2:当 Leader服务器接收到超过半数Follower的Ack响应后,就会广播一个Commit消息给所有的 Follower服务器以通知其进行事务提交(写入内存),同时 Leader自身也会完成对事务的提交。
5:由Leader将结果返回给Client1
上图中4.1和4.2步骤,由于Leader自身也计一票,如果Follower2 由于网络等原因没有给Leader Ack响应,但Leader和Follower 1 两票已超过半数,所以结果依然会成功。此时Client2请求Follower2获取“/aaa”数据时,可以通过sync 让Follower 2向Leader同步后再返回数据。
4.3 选举机制
4.3.1 节点网络
基于上面的第2章集群搭建,查看每台节点网络连接情况
yum install net-tools
netstat -natp | egrep '(2888|3888)'
查看结果如下:
# q101信息
[root@q101 ~]# netstat -natp | egrep '(2888|3888)'
tcp6 0 0 192.168.88.101:3888 :::* LISTEN 1924/java
tcp6 0 0 192.168.88.101:58052 192.168.88.102:3888 ESTABLISHED 1924/java
tcp6 0 0 192.168.88.101:39738 192.168.88.103:3888 ESTABLISHED 1924/java
tcp6 0 0 192.168.88.101:54174 192.168.88.102:2888 ESTABLISHED 1924/java
tcp6 0 0 192.168.88.101:47726 192.168.88.104:3888 ESTABLISHED 1924/java
# q102信息
[root@q102 ~]# netstat -natp | egrep '(2888|3888)'
tcp6 0 0 192.168.88.102:2888 :::* LISTEN 1661/java
tcp6 0 0 192.168.88.102:3888 :::* LISTEN 1661/java
tcp6 0 0 192.168.88.102:3888 192.168.88.101:58052 ESTABLISHED 1661/java
tcp6 0 0 192.168.88.102:2888 192.168.88.103:38244 ESTABLISHED 1661/java
tcp6 0 0 192.168.88.102:50104 192.168.88.104:3888 ESTABLISHED 1661/java
tcp6 0 0 192.168.88.102:2888 192.168.88.104:48034 ESTABLISHED 1661/java
tcp6 0 0 192.168.88.102:2888 192.168.88.101:54174 ESTABLISHED 1661/java
tcp6 0 0 192.168.88.102:37466 192.168.88.103:3888 ESTABLISHED 1661/java
# q103信息
[root@q103 ~]# netstat -natp | egrep '(2888|3888)'
tcp6 0 0 192.168.88.103:3888 :::* LISTEN 1415/java
tcp6 0 0 192.168.88.103:38244 192.168.88.102:2888 ESTABLISHED 1415/java
tcp6 0 0 192.168.88.103:3888 192.168.88.101:39738 ESTABLISHED 1415/java
tcp6 0 0 192.168.88.103:3888 192.168.88.102:37466 ESTABLISHED 1415/java
tcp6 0 0 192.168.88.103:58344 192.168.88.104:3888 ESTABLISHED 1415/java
# q104信息
[root@q104 ~]# netstat -natp | egrep '(2888|3888)'
tcp6 0 0 192.168.88.104:3888 :::* LISTEN 1333/java
tcp6 0 0 192.168.88.104:3888 192.168.88.101:47726 ESTABLISHED 1333/java
tcp6 0 0 192.168.88.104:3888 192.168.88.102:50104 ESTABLISHED 1333/java
tcp6 0 0 192.168.88.104:3888 192.168.88.103:58344 ESTABLISHED 1333/java
tcp6 0 0 192.168.88.104:48034 192.168.88.102:2888 ESTABLISHED 1333/java
通过上面的网络信息整体网络连接图如下
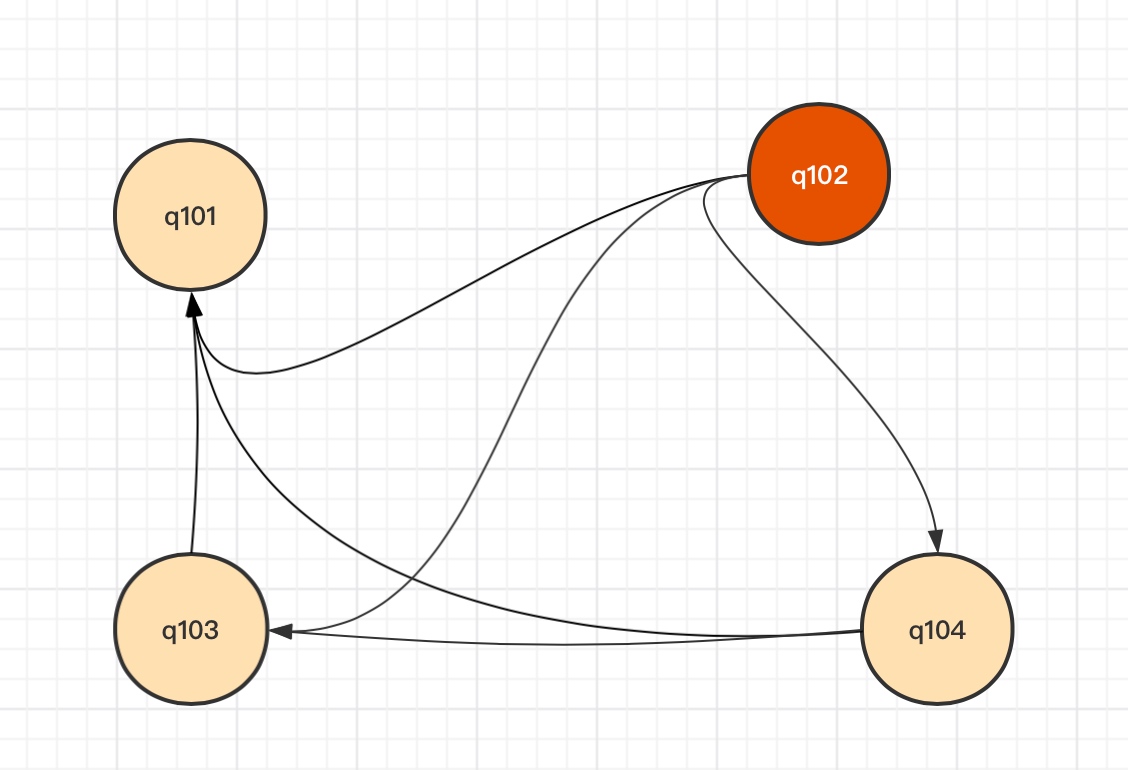
上图说明:
zookeeper Leader和Follower连接主要通过2888和3888,2888主要用于leader与follower进行工作,3888用于Leader选举。每个zookeeper节点都会与其他节点建立连接。
4.3.2 选举流程
情况一:第一次启动
以上面我们搭好的4台节点为例,myid和zxid情况如下:
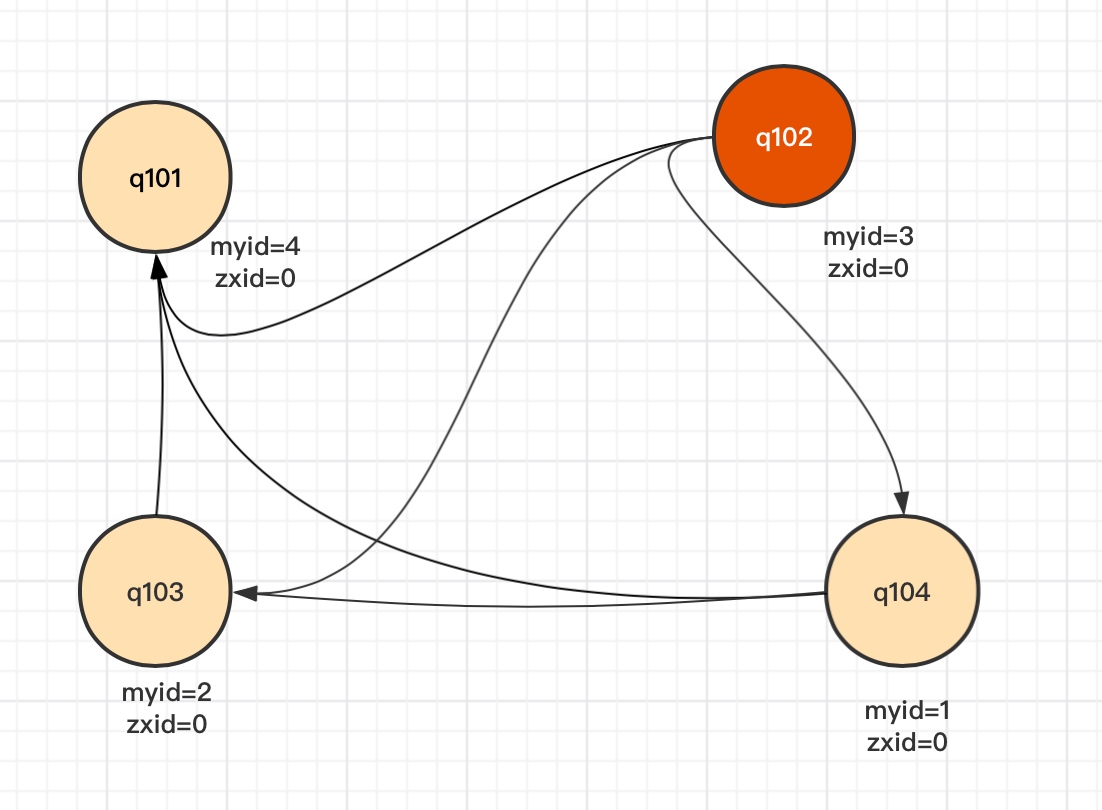
| 节点名称 | myid | zxid |
|---|---|---|
| q101 | 4 | 0 |
| q102 | 3 | 0 |
| q103 | 2 | 0 |
| q104 | 1 | 0 |
| 选举前提当投票数量超过半数时才有效,此处4台节点,当第一次启动时候zxid都为0。只要有3台节点启动就可以选举出Leader。虽然说q101的myid=4但是如果最后启动q101,那么第一次启动时一定是q102成为Leader。 |
情况二:zxid不为0时,当集群重启,或Leader挂了的时候
当Leader挂了后,zookeeper集群会进行推选制选举,会优先选举数据最全的节点作为Leader(通过比较zxid,zxid越大代表该节点数据最全),如果zxid相同再比较myid。
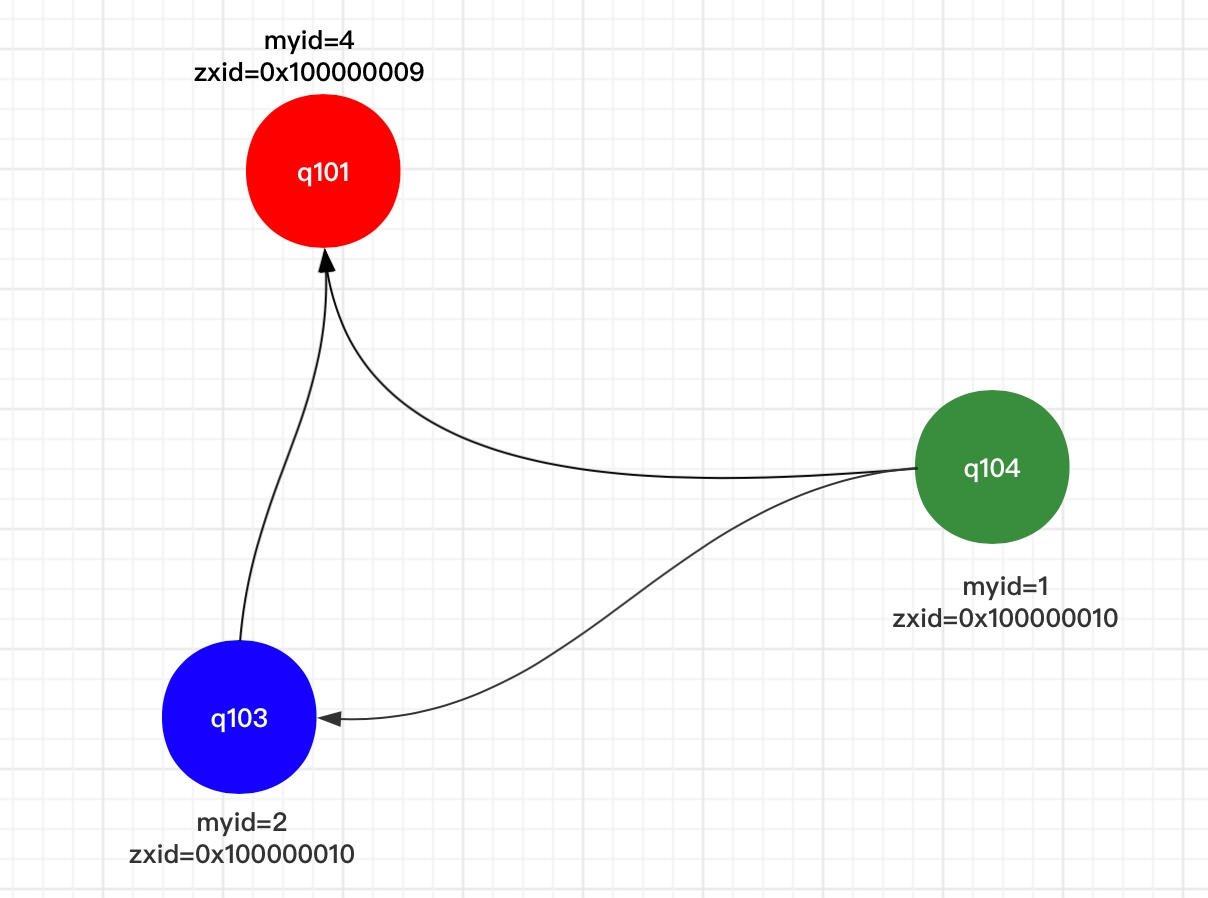
| 节点名称 | myid | zxid |
|---|---|---|
| q101 | 4 | 0x100000009 |
| q103 | 2 | 0x100000010 |
| q104 | 1 | 0x100000010 |
原Leader q102挂掉后无论哪个节点先发现Leader挂掉,都会推选zxid最大的节点,q103和q104 zxid 都为xxx10再比较myid。所以此处q103最终会被选为新的Leader。
5 watch
- Watch是轻量级的,其实就是本地JVM的Callback,服务器端只是存了是否有设置了Watcher的布尔类型。
- 在服务端,在FinalRequestProcessor处理对应的Znode操作时,会根据客户端传递的watcher变量,添加到对应的ZKDatabase(org.apache.zookeeper.server.ZKDatabase)中进行持久化存储,同时将自己NIOServerCnxn做为一个Watcher callback,监听服务端事件变化
- Leader通过投票通过了某次Znode变化的请求后,然后通知对应的Follower,Follower根据自己内存中的zkDataBase信息,发送notification信息给zookeeper客户端。
- Zookeeper客户端接收到notification信息后,找到对应变化path的watcher列表,挨个进行触发回调。
Zookeeper集群搭建及原理的更多相关文章
- Zookeeper集群搭建以及python操作zk
一.Zookeeper原理简介 ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper设计目 ...
- Kafka学习之(五)搭建kafka集群之Zookeeper集群搭建
Zookeeper是一种在分布式系统中被广泛用来作为:分布式状态管理.分布式协调管理.分布式配置管理.和分布式锁服务的集群.kafka增加和减少服务器都会在Zookeeper节点上触发相应的事件kaf ...
- ZooKeeper集群搭建过程
ZooKeeper集群搭建过程 提纲 1.ZooKeeper简介 2.ZooKeeper的下载和安装 3.部署3个节点的ZK伪分布式集群 3.1.解压ZooKeeper安装包 3.2.为每个节点建立d ...
- Linux下zookeeper集群搭建
Linux下zookeeper集群搭建 部署前准备 下载zookeeper的安装包 http://zookeeper.apache.org/releases.html 我下载的版本是zookeeper ...
- java 学习笔记(三)ZooKeeper集群搭建实例,以及集成dubbo时的配置 (转)
ZooKeeper集群搭建实例,以及集成dubbo时的配置 zookeeper是什么: Zookeeper,一种分布式应用的协作服务,是Google的Chubby一个开源的实现,是Hadoop的分布式 ...
- 分布式架构中一致性解决方案——Zookeeper集群搭建
当我们的项目在不知不觉中做大了之后,各种问题就出来了,真jb头疼,比如性能,业务系统的并行计算的一致性协调问题,比如分布式架构的事务问题, 我们需要多台机器共同commit事务,经典的案例当然是银行转 ...
- kafka学习(二)-zookeeper集群搭建
zookeeper概念 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名 服务等.Zookeeper是h ...
- 分布式协调服务Zookeeper集群搭建
分布式协调服务Zookeeper集群搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装jdk环境 1>.操作环境 [root@node101.yinzhengjie ...
- Zookeeper 集群搭建--单机伪分布式集群
一. zk集群,主从节点,心跳机制(选举模式) 二.Zookeeper集群搭建注意点 1.配置数据文件 myid 1/2/3 对应 server.1/2/3 2.通过./zkCli.sh -serve ...
随机推荐
- BAT经典面试题之redis的热KEY问题怎么解决
引言 讲了几天的数据库系列的文章,大家一定看烦了,其实还没讲完...(以下省略一万字).今天我们换换口味,来写redis方面的内容,谈谈热key问题如何解决.其实热key问题说来也很简单,就是瞬间有几 ...
- golang中数组指针和指针数组当做函数参数如何修改数组中的值
先理解:数组指针它的类型时指针,指针数组它的类型时数组 1. 数组指针当做函数的参数 package main import "fmt" func changeData(dataA ...
- Excel与MySQL数据库的导入与导出
应用场景 在许多时候,我们希望数据能够很好地在各个系统之间转移,同时便于非专业人员阅读,如果程序员一点点打字导出的话,不知道要打到什么时候,于是我们便采用日常工作中常用的Excel表格来作为媒介,将数 ...
- html+css+js(登录页)
直接上代码 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- Oracle AWR报告采样分析
DB time可以用来判断数据库整体是否繁忙,如果Elapsed*CPU个数小于DB time,代表数据库整体比较繁忙,CPU负载会比较高. Report Summary分为8个部分,最主要的是loa ...
- Shell 脚本进阶,经典用法及其案例
一.条件选择.判断 1.条件选择if (1)用法格式 if 判断条件 1 ; then 条件为真的分支代码 elif 判断条件 2 ; then 条件为真的分支代码 elif 判断条件 3 ; the ...
- python引用列表--10
#!/usr/bin/python #coding=utf-8 #好好学习,天天向上 python=["a","b","c","d ...
- Redis 源码简洁剖析 04 - Sorted Set 有序集合
Sorted Set 是什么 Sorted Set 命令及实现方法 Sorted Set 数据结构 跳表(skiplist) 跳表节点的结构定义 跳表的定义 跳表节点查询 层数设置 跳表插入节点 zs ...
- String Reversal
Educational Codeforces Round 96 (Rated for Div. 2) - E. String Reversal 跳转链接 题目描述 定义一个操作为交换字符串中相邻的两个 ...
- VsCode配置C/C++开发环境
Visual Studio Code(VS Code)是基于 Electron 开发,支持 Windows.Linux 和 macOS 操作系统.内置了对JavaScript,TypeScript和N ...