python版的MCScan绘图
最近发现了python版的MCScan,是个大宝藏。由于走了不少弯路,终于画出美图,赶紧记录下来。
github地址 https://github.com/tanghaibao/jcvi/wiki/MCscan-(Python-version)
软件安装
- 1 ## 安装lastal
- 2 网址:http://last.cbrc.jp
- 3 unzip last-1060.zip
- 4 cd last-1060
- 5 make
- 6
- 7 # 把scripts, src 添加到环境变量
- 8
- 9 ## jcvi
- 10 pip install jcvi
- 11
- 12 ## 若出现 from rillib.parse import urlparse 缺少parse模块,则装parse模块,然后将urllib.parse 改为urlparse; 因为urlparse模块在Python 3中重命名为urllib.parse,所以模块在Python 2.7下应该使用urlparse。
- 1 ## 安装lastal
输入数据
gff文件转bed格式
- 1 ## 以spinach,和sugar为例子
- 2 python -m jcvi.formats.gff bed --type=mRNA --key=ID spinach_gene_v1.gff3 -o spinach.bed
- 3 python -m jcvi.formats.gff bed --type=mRNA --key=ID BeetSet-2.unfiltered_genes.1408.gff3.txt -o sugar.bed
- 4
- 5 ##参数
- 6 --type:gff文件中第三列
- 7 --key:type对应的第九列信息前缀
- 8
- 9 我们分析只需要用到每个基因最长的转录本就行,在sugar中是以多个转录本进行存储,因为需要获取最长转录本
- 10
- 11 ## 将sugar中bed进行去重复
- 12 python -m jcvi.formats.bed uniq sugar.bed
- 1 ## 以spinach,和sugar为例子
获取cds/pep序列
- 1 ## cds和pep序列均可以进行共线性分析
- 2 ## 根据上述得到的.bed文件调取对应cds和蛋白序列
- 3 # spinach
- 4 seqkit grep -f <(cut -f4 spianch.bed) spinach.cds.fa | seqkit seq -I >spinach.cds
- 5 seqkit grep -f <(cut -f4 spianch.bed) spinach.pep.fa | seqkit seq -I >spinach.pep
- 6
- 7 # sugar
- 8 seqkit grep -f <(cut -f4 sugar.uniq.bed) BeetSet-2.genes.1408.cds.fa | seqkit seq -i >sugar.cds
- 9 seqkit grep -f <(cut -f4 sugar.uniq.bed) BeetSet-2.genes.1408.pep.fa | seqkit seq -i >sugar.pep
- 1 ## cds和pep序列均可以进行共线性分析
小知识:也可以根据gff文件,基因组ref.fa文件中直接调取cds,和pep序列
- 1 ## 需要安装cufflinks
- 2
- 3 ## 提取cds
- 4 gffread in.gff3 -g ref.fa -x cds.fa
- 5
- 6 ## 提取pep
- 7 gffread in.gff3 -g ref.fa -y pep.fa
- 1 ## 需要安装cufflinks
共线性分析
- 1 ## 新建一个文件夹,方便在报错的时候,把全部都给删了
- 2 mkdir cds && cd cds
- 3 ln -s ../sugar.cd ./
- 4 ln -s ../sugar.uniq.bed ./sugar.bed
- 5 ln -s ../spinach.cds ./
- 6 ln -s ../spinch.bed ./
- 7
- 8 ## 运行代码
- 9 python -m jcvi.compara.catalog ortholog (--dbtype prot[蛋白分析]) --no_strip_names spinach sugar
- 10
- 11 结果:
- 12 spinach.sugar.anchors:共线性block区块(高质量)
- 13 spinach.sugar.last:原始的last输出
- 14 spinach.sugar.last.filtered:过滤后的last输出
- 15 spinach.sugar.pdf:点阵图
- 16
- 17 ## 如果遇到报错,多半是要安装python包,更新Latex
- 1 ## 新建一个文件夹,方便在报错的时候,把全部都给删了
可视化
共线性图
- 1 ## 首先生成.sinple文件
- 2 python -m jcvi.compara.synteny screen --minspan=30 --simple spinach.sugar.anchors spinach.sugar.anchors.new
- 3
- 4 ## 编辑配置文件seqids 和layout
- 5
- 6 #设置需要展示染色体号
- 7 vi seqids
- 8 chr1,chr2,chr3,chr4,chr5,chr6 #spinach
- 9 Bvchr1.sca001,Bvchr2.sca001,Bvchr3.sca001 #sugar
- 10
- 11 # 设置颜色,长宽等
- 12 vi layout
- 13 # y, xstart, xend, rotation, color, label, va, bed
- 14 .6, .1, .8, 0, red, spinach, top, spinach.bed
- 15 .4, .1, ,8, 0, blue, sugar, top, sugar.bed
- 16 # edges
- 17 e, 0, 1, spinach.sugar.anchors.simple
- 18
- 19 注意, #edges下的每一行开头都不能有空格
- 20
- 21 ## 运行代码
- 22 python -m jcvi.graphics.karyotype seqids layout
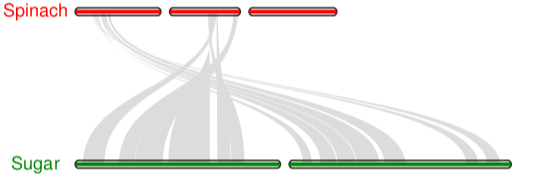
- 1 ## 首先生成.sinple文件
若要突出显示某一共线性则可以在对应的位置添加g*
- 1 vi spinach.sugar.anchors.simple
- 2 g*Spo03717 Spo03716 Bv3_048620_odzi.t1 Bv3_049090_cxmm.t1 46 +
- 3 Spo17356 Spo17350 Bv1_001140_tedw.t1 Bv1_001540_xzdn.t1 41 -
- 4 Spo13685 Spo13730 Bv5_123480_yfcy.t1 Bv5_123900_rucq.t1 46 -
- 5 Spo26250 Spo26280 Bv5_117270_qhwj.t1 Bv5_117680_iykf.t1 36 +
- 6 Spo19005 Spo06982 Bv7_173830_frmo.t1 Bv7_174150_pckw.t1 37 +
- 7 Spo19374 Spo20559 Bv4_081440_riqq.t1 Bv4_081750_yeuy.t1 32 -
- 8
- 9 #运行
- 10 python -m jcvi.graphics.karyotype seqids layout
- 1 vi spinach.sugar.anchors.simple
若要显示3个物种的共线性,则应两两比对,得到两个*.simple文件,并对其进行配置(来自https://www.jianshu.com/p/39448b970287)
- 1 $ vi layout
- 2 # y, xstart, xend, rotation, color, label, va, bed
- 3 .7, .1, .8, 15, , Grape, top, grape.bed
- 4 .5, .1, .8, 0, , Peach, top, peach.bed
- 5 .3, .1, .8, -15, , Cacao, bottom, cacao.bed
- 6 # edges
- 7 e, 0, 1, grape.peach.anchors.simple
- 8 e, 1, 2, peach.cacao.anchors.simple
- 9
- 10 $ vi seqids
- 11 chr1,chr2,chr3,chr4,chr5,chr6,chr7,chr8,chr9,chr10,chr11,chr12,chr13,chr14,chr15,chr16,chr17,chr18,chr19
- 12 scaffold_1,scaffold_2,scaffold_3,scaffold_4,scaffold_5,scaffold_6,scaffold_7,scaffold_8
- 13 scaffold_1,scaffold_2,scaffold_3,scaffold_4,scaffold_5,scaffold_6,scaffold_7,scaffold_8,scaffold_9,scaffold_10r
- 14
- 15 $ python -m jcvi.graphics.karyotype seqids layout
- 1 $ vi layout

3个物种三角形排序配置文件(来自https://www.jianshu.com/p/f7971dbf5f85)
- 1 # y, xstart, xend, rotation, color, label, va, bed
- 2 .5, 0.025, 0.625, 60, , Grape, top, grape.bed
- 3 .2, 0.2, .8, 0, , Peach, top, peach.bed
- 4 .5, 0.375, 0.975, -60, , Cacao, top, cacao.bed
- 5 # edges
- 6 e, 0, 1, grape.peach.anchors.simple
- 7 e, 1, 2, peach.cacao.anchors.simple
- 8
- 9 #运行
- 10 python -m jcvi.graphics.karyotype seqids layout
- 1 # y, xstart, xend, rotation, color, label, va, bed

除此之外,Tbtools也可以完成类似图片,对于新手来说更加容易上手,具体可查看以下内容
参考
1、其实MCScan画图也可以很好看
2、「JCVI教程」如何绘制CNS级别的共线性图(上)
3、「JCVI教程」如何绘制CNS级别的共线性图(中)
关注下方公众号可获得更多精彩

python版的MCScan绘图的更多相关文章
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 数据结构:顺序表(python版)
顺序表python版的实现(部分功能未实现) #!/usr/bin/env python # -*- coding:utf-8 -*- class SeqList(object): def __ini ...
- python版恶俗古风自动生成器.py
python版恶俗古风自动生成器.py """ python版恶俗古风自动生成器.py 模仿自: http://www.jianshu.com/p/f893291674c ...
- LAMP一键安装包(Python版)
去年有出一个python整的LAMP自动安装,不过比较傻,直接调用的yum 去安装了XXX...不过这次一样有用shell..我也想如何不调用shell 来弄一个LAMP自动安装部署啥啥的..不过尼玛 ...
- 编码的秘密(python版)
编码(python版) 最近在学习python的过程中,被不同的编码搞得有点晕,于是看了前人的留下的文档,加上自己的理解,准备写下来,分享给正在为编码苦苦了挣扎的你. 编码的概念 编码就是将信息从一种 ...
- Zabbix 微信报警Python版(带监控项波动图片)
#!/usr/bin/python # -*- coding: UTF- -*- #Function: 微信报警python版(带波动图) #Environment: python import ur ...
- 豆瓣top250(go版以及python版)
最近学习go,就找了一个例子练习[go语言爬虫]go语言爬取豆瓣电影top250,思路大概就是获取网页,然后根据页面元素,用正则表达式匹配电影名称.评分.评论人数.原文有个地方需要修改下patte ...
- python版接口自动化测试框架源码完整版(requests + unittest)
python版接口自动化测试框架:https://gitee.com/UncleYong/my_rf [框架目录结构介绍] bin: 可执行文件,程序入口 conf: 配置文件 core: 核心文件 ...
- python中利用matplotlib绘图可视化知识归纳
python中利用matplotlib绘图可视化知识归纳: (1)matplotlib图标正常显示中文 import matplotlib.pyplot as plt plt.rcParams['fo ...
随机推荐
- 80. 删除有序数组中的重复项 II
题目 给你一个有序数组 nums ,请你原地删除重复出现的元素(不需要考虑数组中超出新长度后面的元素),使每个元素最多出现两次 ,返回删除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入 ...
- the Agiles Scrum Meeting 7
会议时间:2020.4.15 21:00 1.每个人的工作 根据项目进度,我们将原先的完善组和debug组合并,成为团队项目增量开发组,原增量组成为个人结对项目增量开发组. 今天已完成的工作 个人结对 ...
- 零基础小白要如何跟好的学习嵌入式Linux
作为一个新人,怎样学习嵌入式Linux?被问过太多次,特写这篇文章来回答一下. 在学习嵌入式Linux之前,肯定要有C语言基础.汇编基础有没有无所谓(就那么几条汇编指令,用到了一看就会). C语言要学 ...
- 嵌入式物联网之SPI接口原理与配置
本实验采用W25Q64芯片 W25Q64是华邦公司推出的大容量SPI FLASH产品,其容量为64Mb.该25Q系列的器件在灵活性和性能方面远远超过普通的串行闪存器件.W25Q64将8M字节的容量分为 ...
- 基础篇:JAVA集合,面试专用
没啥好说的,在座的各位都是靓仔 List 数组 Vector 向量 Stack 栈 Map 映射字典 Set 集合 Queue 队列 Deque 双向队列 关注公众号,一起交流,微信搜一搜: 潜行前行 ...
- Python展示文件下载进度条
前言 大家在用Python写一些小程序的时候,经常都会用到文件下载,对于一些较小的文件,大家可能不太在乎文件的下载进度,因为一会就下载完毕了. 但是当文件较大,比如下载chromedriver的时候, ...
- 使用jax加速Hamming Distance的计算
技术背景 一般认为Jax是谷歌为了取代TensorFlow而推出的一款全新的端到端可微的框架,但是Jax同时也集成了绝大部分的numpy函数,这就使得我们可以更加简便的从numpy的计算习惯中切换到G ...
- Linux&C open creat read write lseek 函数用法总结
一:五个函数的参数以及返回值. 函数 参数 返回值 open (文件名,打开方式以及读 ...
- Linux&C网络编程————“聊天室”
从上周到现在一直在完成最后的项目,自己的聊天室,所以博客就没怎么跟了,今天晚上自己的聊天室基本实现,让学长检查了,也有好些bug,自己还算满意,主要实现的功能有: 登录注册 附近的人(服务器端全部在线 ...
- 【java+selenium3】JavaScript的调用执行 (十)
JavaScript的调用 在web自动化操作页面的时候,有些特殊的情况selenium的api无法完成,需要通过执行一段js来实现的DOM操作: //执行方式 JavascriptExecutor ...