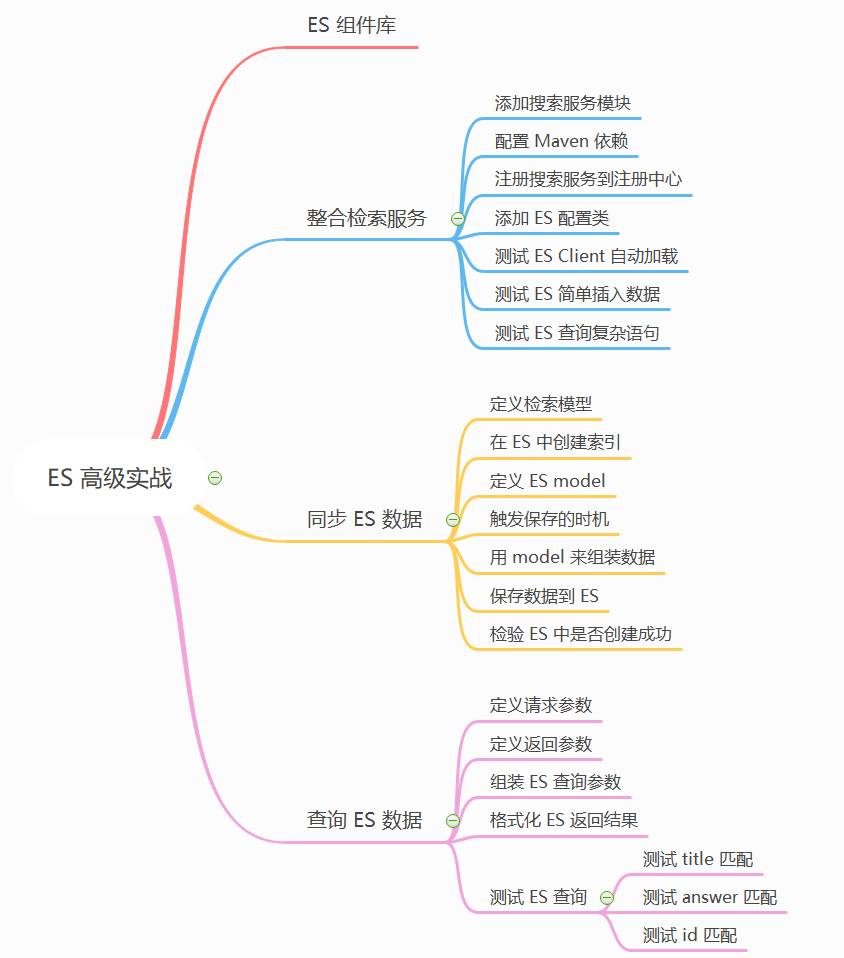
1W字|40 图|硬核 ES 实战
前言
上篇我们讲到了 Elasticsearch 全文检索的原理《别只会搜日志了,求你懂点检索原理吧》,通过在本地搭建一套 ES 服务,以多个案例来分析了 ES 的原理以及基础使用。这次我们来讲下 Spring Boot 中如何整合 ES,以及如何在 Spring Cloud 微服务项目中使用 ES 来实现全文检索。
ES 系列文章:
通过本实战您可以学到如下知识点:
- Spring Boot 如何整合 ES。
- 微服务中 ES 的 API 使用。
- 项目中如何使用 ES 来达到全文检索。
本篇主要内容如下:
本文案例都是基于 PassJava 实战项目来演示的。
为了让大家更清晰地理解 PassJava 项目中 ES 是如何使用的,我画了三个流程图:
- 第一步:创建 question 索引。
首先定义 question 索引,然后在 ES 中创建索引。
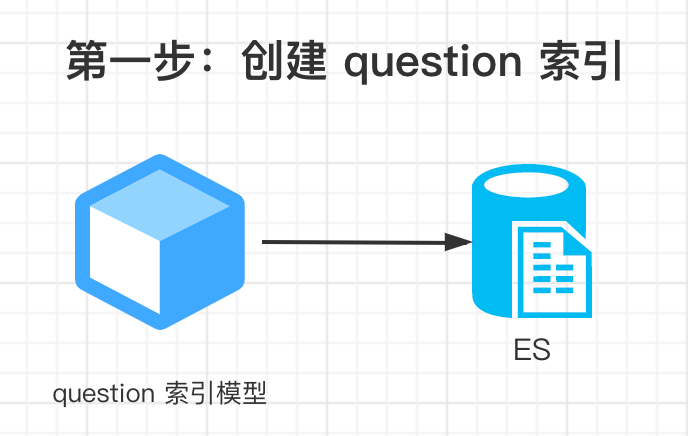
- 第二步:存 question 数据进 ES 。
前端保存数据时,保存的 API 请求先进过网关,然后转发到 passjava-question 微服务,然后远程调用 passjava-search 微服务,将数据保存进 ES 中。

- 第三步:从 ES 中查数据。
前端查询数据时,先经过网关,然后将请求转发给 passjava-search 微服务,然后从 ES 中查询数据。

一、Elasticsearch 组件库介绍
在讲解之前,我在这里再次提下全文检索是什么:
全文检索: 指以全部文本信息作为检索对象的一种信息检索技术。而我们使用的数据库,如 Mysql,MongoDB 对文本信息检索能力特别是中文检索并没有 ES 强大。所以我们来看下 ES 在项目中是如何来代替 SQL 来工作的。
我使用的 Elasticsearch 服务是 7.4.2 的版本,然后采用官方提供的 Elastiscsearch-Rest-Client 库来操作 ES,而且官方库的 API 上手简单。
该组件库的官方文档地址:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
另外这个组件库是支持多种语言的:

注意:Elasticsearch Clients 就是指如何用 API 操作 ES 服务的组件库。
可能有同学会提问,Elasticsearch 的组件库中写着 JavaScript API,是不是可以直接在前端访问 ES 服务?可以是可以,但是会暴露 ES 服务的端口和 IP 地址,会非常不安全。所以我们还是用后端服务来访问 ES 服务。
我们这个项目是 Java 项目,自然就是用上面的两种:Java Rest Client 或者 Java API。我们先看下 Java API,但是会发现已经废弃了。如下图所示:
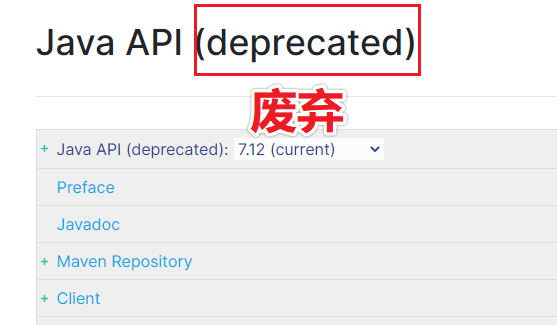
所以我们只能用 Java REST Client 了。而它又分成两种:高级和低级的。高级包含更多的功能,如果把高级比作MyBatis的话,那么低级就相当于JDBC。所以我们用高级的 Client。

二、整合检索服务
我们把检索服务单独作为一个服务。就称作 passjava-search 模块吧。
1.1 添加搜索服务模块
- 创建 passjava-search 模块。
首先我们在 PassJava-Platform 模块创建一个 搜索服务模块 passjava-search。然后勾选 spring web 服务。如下图所示。
第一步:选择 Spring Initializr,然后点击 Next。
第二步:填写模块信息,然后点击 Next。

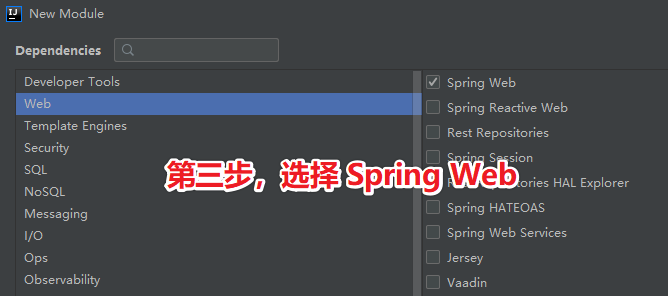
第三步:选择 Web->Spring Web 依赖,然后点击 Next。
1.2 配置 Maven 依赖
- 参照 ES 官网配置。
进入到 ES 官方网站,可以看到有低级和高级的 Rest Client,我们选择高阶的(High Level Rest Client)。然后进入到高阶 Rest Client 的 Maven 仓库。官网地址如下所示:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/index.html

加上 Maven 依赖。
对应文件路径:\passjava-search\pom.xml
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
配置 elasticsearch 的版本为7.4.2
因加上 Maven 依赖后,elasticsearch 版本为 7.6.2,所以遇到这种版本不一致的情况时,需要手动改掉。
对应文件路径:\passjava-search\pom.xml
<properties>
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>
刷新 Maven Project 后,可以看到引入的 elasticsearch 都是 7.4.2 版本了,如下图所示:
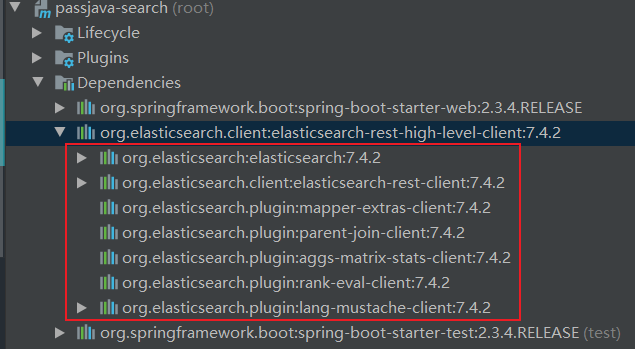
引入 PassJava 的 Common 模块依赖。
Common 模块是 PassJava 项目独立的出来的公共模块,引入了很多公共组件依赖,其他模块引入 Common 模块依赖后,就不需要单独引入这些公共组件了,非常方便。
对应文件路径:\passjava-search\pom.xml
<dependency>
<groupId>com.jackson0714.passjava</groupId>
<artifactId>passjava-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
添加完依赖后,我们就可以将搜索服务注册到 Nacos 注册中心了。 Nacos 注册中心的用法在前面几篇文章中也详细讲解过,这里需要注意的是要先启动 Nacos 注册中心,才能正常注册 passjava-search 服务。
1.3 注册搜索服务到注册中心
修改配置文件:src/main/resources/application.properties。配置应用程序名、注册中心地址、注册中心的命名中间。
spring.application.name=passjava-search
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.cloud.nacos.config.namespace=passjava-search
给启动类添加服务发现注解:@EnableDiscoveryClient。这样 passjava-search 服务就可以被注册中心发现了。
因 Common 模块依赖数据源,但 search 模块不依赖数据源,所以 search 模块需要移除数据源依赖:
exclude = DataSourceAutoConfiguration.class
以上的两个注解如下所示:
@EnableDiscoveryClient
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
public class PassjavaSearchApplication {
public static void main(String[] args) {
SpringApplication.run(PassjavaSearchApplication.class, args);
}
}
接下来我们添加一个 ES 服务的专属配置类,主要目的是自动加载一个 ES Client 来供后续 ES API 使用,不用每次都 new 一个 ES Client。
1.4 添加 ES 配置类
配置类:PassJavaElasticsearchConfig.java
核心方法就是 RestClient.builder 方法,设置好 ES 服务的 IP 地址、端口号、传输协议就可以了。最后自动加载了 RestHighLevelClient。
package com.jackson0714.passjava.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Author: 公众号 | 悟空聊架构
* @Date: 2020/10/8 17:02
* @Site: www.passjava.cn
* @Github: https://github.com/Jackson0714/PassJava-Platform
*/
@Configuration
public class PassJavaElasticsearchConfig {
@Bean
// 给容器注册一个 RestHighLevelClient,用来操作 ES
// 参考官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-getting-started-initialization.html
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.56.10", 9200, "http")));
}
}
接下来我们测试下 ES Client 是否自动加载成功。
1.5 测试 ES Client 自动加载
在测试类 PassjavaSearchApplicationTests 中编写测试方法,打印出自动加载的 ES Client。期望结果是一个 RestHighLevelClient 对象。
package com.jackson0714.passjava.search;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class PassjavaSearchApplicationTests {
@Qualifier("restHighLevelClient")
@Autowired
private RestHighLevelClient client;
@Test
public void contextLoads() {
System.out.println(client);
}
}
运行结果如下所示,打印出了 RestHighLevelClient。说明自定义的 ES Client 自动装载成功。

1.6 测试 ES 简单插入数据
测试方法 testIndexData,省略 User 类。users 索引在我的 ES 中是没有记录的,所以期望结果是 ES 中新增了一条 users 数据。
/**
* 测试存储数据到 ES。
* */
@Test
public void testIndexData() throws IOException {
IndexRequest request = new IndexRequest("users");
request.id("1"); // 文档的 id
//构造 User 对象
User user = new User();
user.setUserName("PassJava");
user.setAge("18");
user.setGender("Man");
//User 对象转为 JSON 数据
String jsonString = JSON.toJSONString(user);
// JSON 数据放入 request 中
request.source(jsonString, XContentType.JSON);
// 执行插入操作
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response);
}
执行 test 方法,我们可以看到控制台输出以下结果,说明数据插入到 ES 成功。另外需要注意的是结果中的 result 字段为 updated,是因为我本地为了截图,多执行了几次插入操作,但因为 id = 1,所以做的都是 updated 操作,而不是 created 操作。
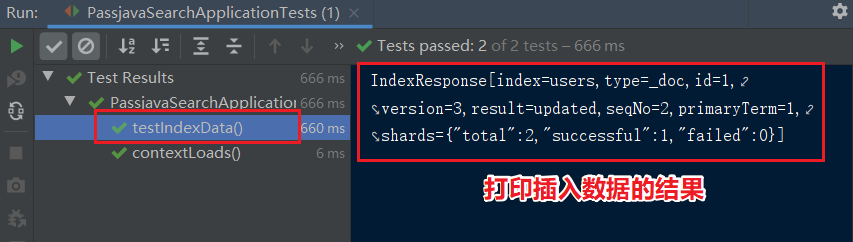
我们再来到 ES 中看下 users 索引中数据。查询 users 索引:
GET users/_search
结果如下所示:
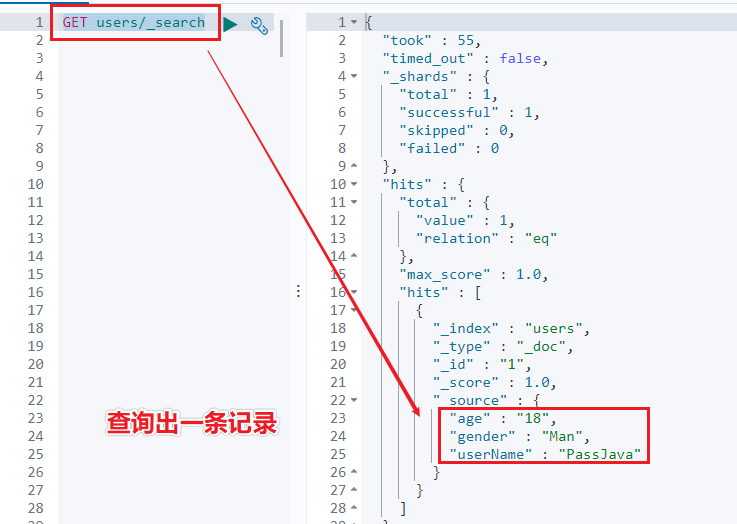
可以从图中看到有一条记录被查询出来,查询出来的数据的 _id = 1,和插入的文档 id 一致。另外几个字段的值也是一致的。说明插入的数据没有问题。
"age" : "18",
"gender" : "Man",
"userName" : "PassJava"
1.7 测试 ES 查询复杂语句
示例:搜索 bank 索引,address 字段中包含 big 的所有人的年龄分布 ( 前 10 条 ) 以及平均年龄,以及平均薪资。
1.7.1 构造检索条件
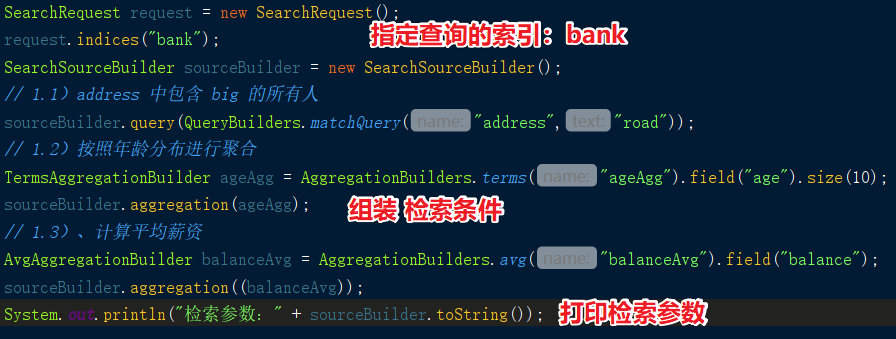
我们可以参照官方文档给出的示例来创建一个 SearchRequest 对象,指定要查询的索引为 bank,然后创建一个 SearchSourceBuilder 来组装查询条件。总共有三种条件需要组装:
- address 中包含 road 的所有人。
- 按照年龄分布进行聚合。
- 计算平均薪资。
代码如下所示,需要源码请到我的 Github/PassJava 上下载。
将打印出来的检索参数复制出来,然后放到 JSON 格式化工具中格式化一下,再粘贴到 ES 控制台执行,发现执行结果是正确的。
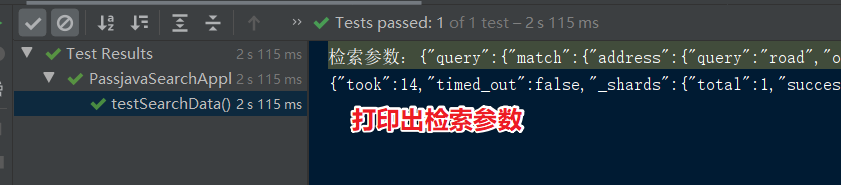
用在线工具格式化 JSON 字符串,结果如下所示:

然后我们去掉其中的一些默认参数,最后简化后的检索参数放到 Kibana 中执行。
Kibana Dev Tools 控制台中执行检索语句如下图所示,检索结果如下图所示:
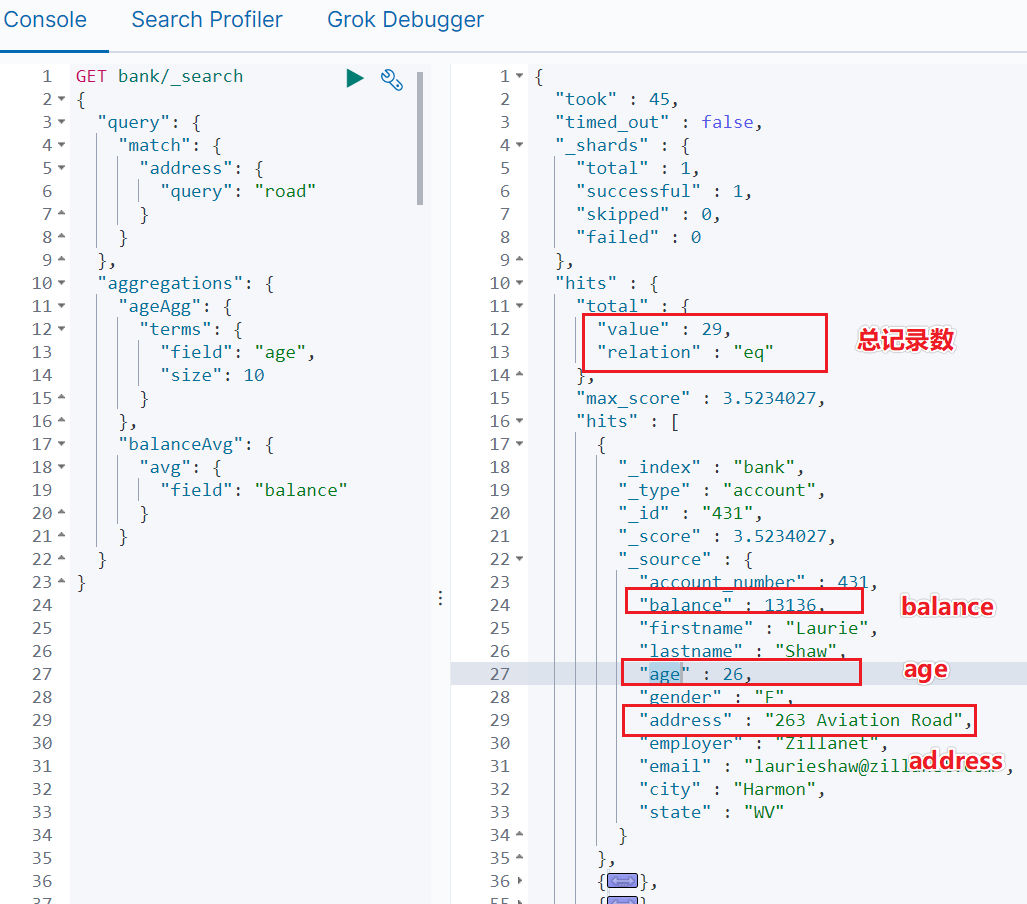
找到总记录数:29 条。
第一条命中记录的详情如下:
平均 balance:13136。
平均年龄:26。
地址中包含 Road 的:263 Aviation Road。
和 IDEA 中执行的测试结果一致,说明复杂检索的功能已经成功实现。
17.2 获取命中记录的详情
而获取命中记录的详情数据,则需要通过两次 getHists() 方法拿到,如下所示:
// 3.1)获取查到的数据。
SearchHits hits = response.getHits();
// 3.2)获取真正命中的结果
SearchHit[] searchHits = hits.getHits();
我们可以通过遍历 searchHits 的方式打印出所有命中结果的详情。
// 3.3)、遍历命中结果
for (SearchHit hit: searchHits) {
String hitStr = hit.getSourceAsString();
BankMember bankMember = JSON.parseObject(hitStr, BankMember.class);
}
拿到每条记录的 hitStr 是个 JSON 数据,如下所示:
{
"account_number": 431,
"balance": 13136,
"firstname": "Laurie",
"lastname": "Shaw",
"age": 26,
"gender": "F",
"address": "263 Aviation Road",
"employer": "Zillanet",
"email": "laurieshaw@zillanet.com",
"city": "Harmon",
"state": "WV"
}
而 BankMember 是根据返回的结果详情定义的的 JavaBean。可以通过工具自动生成。在线生成 JavaBean 的网站如下:
https://www.bejson.com/json2javapojo/new/
把这个 JavaBean 加到 PassjavaSearchApplicationTests 类中:
@ToString
@Data
static class BankMember {
private int account_number;
private int balance;
private String firstname;
private String lastname;
private int age;
private String gender;
private String address;
private String employer;
private String email;
private String city;
private String state;
}
然后将 bankMember 打印出来:
System.out.println(bankMember);
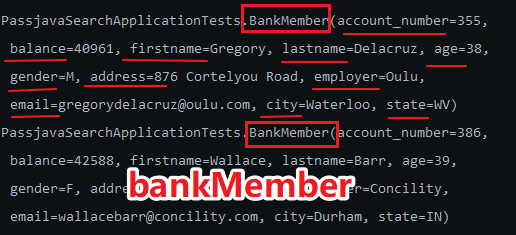
得到的结果确实是我们封装的 BankMember 对象,而且里面的属性值也都拿到了。
1.7.3 获取年龄分布聚合信息
ES 返回的 response 中,年龄分布的数据是按照 ES 的格式返回的,如果想按照我们自己的格式来返回,就需要将 response 进行处理。
如下图所示,这个是查询到的年龄分布结果,我们需要将其中某些字段取出来,比如 buckets,它代表了分布在 21 岁的有 4 个。
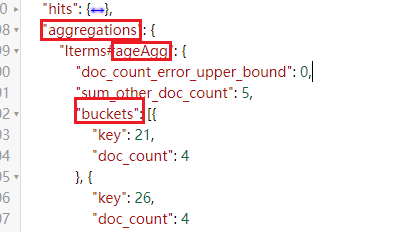
下面是代码实现:
Aggregations aggregations = response.getAggregations();
Terms ageAgg1 = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg1.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
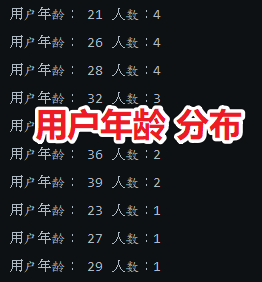
System.out.println("用户年龄: " + keyAsString + " 人数:" + bucket.getDocCount());
}
最后打印的结果如下,21 岁的有 4 人,26 岁的有 4 人,等等。
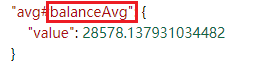
1.7.4 获取平均薪资聚合信息
现在来看看平均薪资如何按照所需的格式返回,ES 返回的结果如下图所示,我们需要获取 balanceAvg 字段的 value 值。
代码实现:
Avg balanceAvg1 = aggregations.get("balanceAvg");
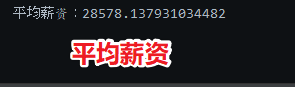
System.out.println("平均薪资:" + balanceAvg1.getValue());
打印结果如下,平均薪资 28578 元。
三、实战:同步 ES 数据
3.1 定义检索模型
PassJava 这个项目可以用来配置题库,如果我们想通过关键字来搜索题库,该怎么做呢?
类似于百度搜索,输入几个关键字就可以搜到关联的结果,我们这个功能也是类似,通过 Elasticsearch 做检索引擎,后台管理界面和小程序作为搜索入口,只需要在小程序上输入关键字,就可以检索相关的题目和答案。
首先我们需要把题目和答案保存到 ES 中,在存之前,第一步是定义索引的模型,如下所示,模型中有 title 和 answer 字段,表示题目和答案。
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_smart"
},
"answer": {
"type": "text",
"analyzer": "ik_smart"
},
"typeName": {
"type": "keyword"
}
3.2 在 ES 中创建索引
上面我们已经定义了索引结构,接着就是在 ES 中创建索引。
在 Kibana 控制台中执行以下语句:
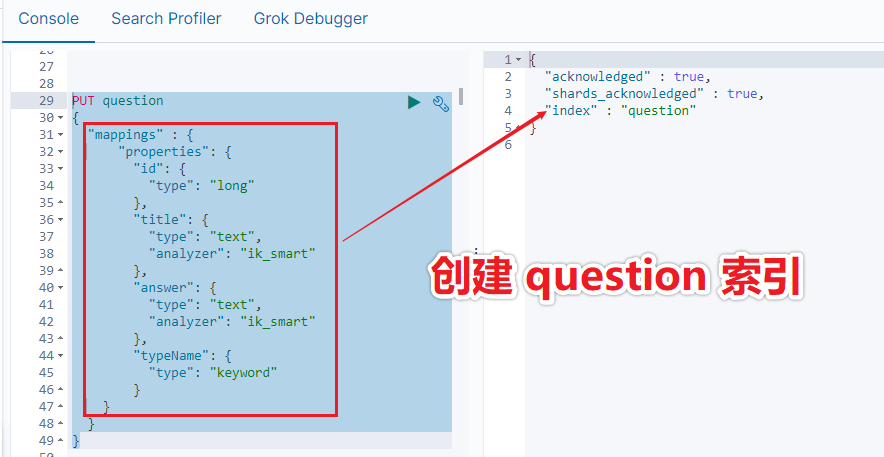
PUT question
{
"mappings" : {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_smart"
},
"answer": {
"type": "text",
"analyzer": "ik_smart"
},
"typeName": {
"type": "keyword"
}
}
}
}
执行结果如下所示:
我们可以通过以下命令来查看 question 索引是否在 ES 中:
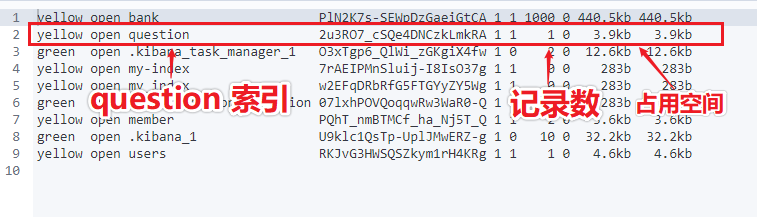
GET _cat/indices
执行结果如下图所示:
3.3 定义 ES model
上面我们定义 ES 的索引,接着就是定义索引对应的模型,将数据存到这个模型中,然后再存到 ES 中。
ES 模型如下,共四个字段:id、title、answer、typeName。和 ES 索引是相互对应的。
@Data
public class QuestionEsModel {
private Long id;
private String title;
private String answer;
private String typeName;
}
3.4 触发保存的时机
当我们在后台创建题目或保存题目时,先将数据保存到 mysql 数据库,然后再保存到 ES 中。
如下图所示,在管理后台创建题目时,触发保存数据到 ES 。
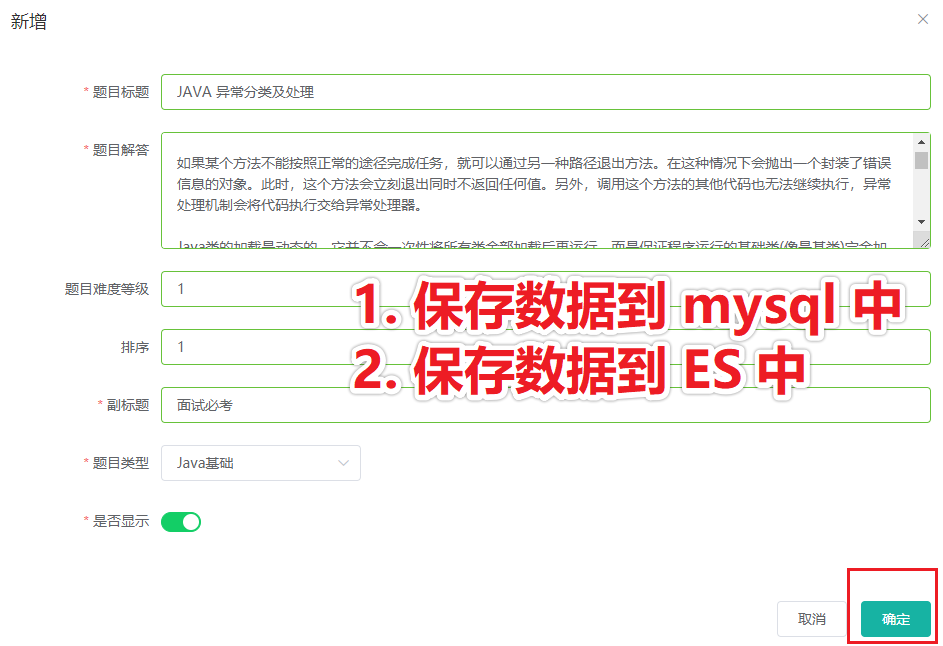
第一步,保存数据到 mysql 中,项目中已经包含此功能,就不再讲解了,直接进入第二步:保存数据到 ES 中。
而保存数据到 ES 中,需要将数据组装成 ES 索引对应的数据,所以我用了一个 ES model,先将数据保存到 ES model 中。
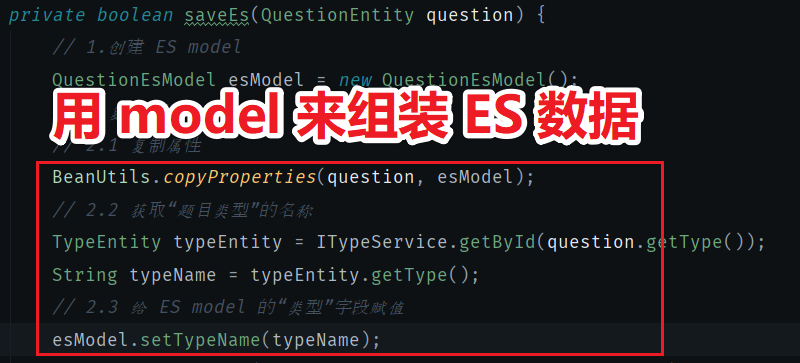
3.5 用 model 来组装数据
这里的关键代码时 copyProperties,可以将 question 对象的数据取出,然后赋值到 ES model 中。不过 ES model 中还有些字段是 question 中没有的,所以需要单独拎出来赋值,比如 typeName 字段,question 对象中没有这个字段,它对应的字段是 question.type,所以我们把 type 取出来赋值到 ES model 的 typeName 字段上。如下图所示:
3.6 保存数据到 ES
我在 passjava-search 微服务中写了一个保存题目的 api 用来保存数据到 ES 中。
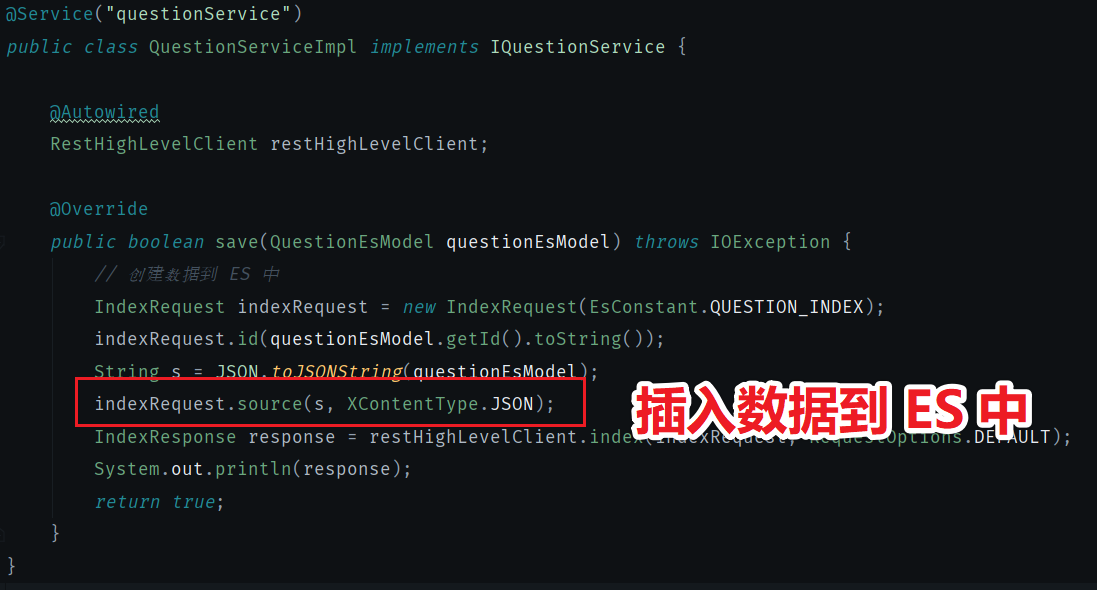
然后在 passjava-question 微服务中调用 search 微服务的保存 ES 的方法就可以了。
// 调用 passjava-search 服务,将数据发送到 ES 中保存。
searchFeignService.saveQuestion(esModel);
3.7 检验 ES 中是否创建成功
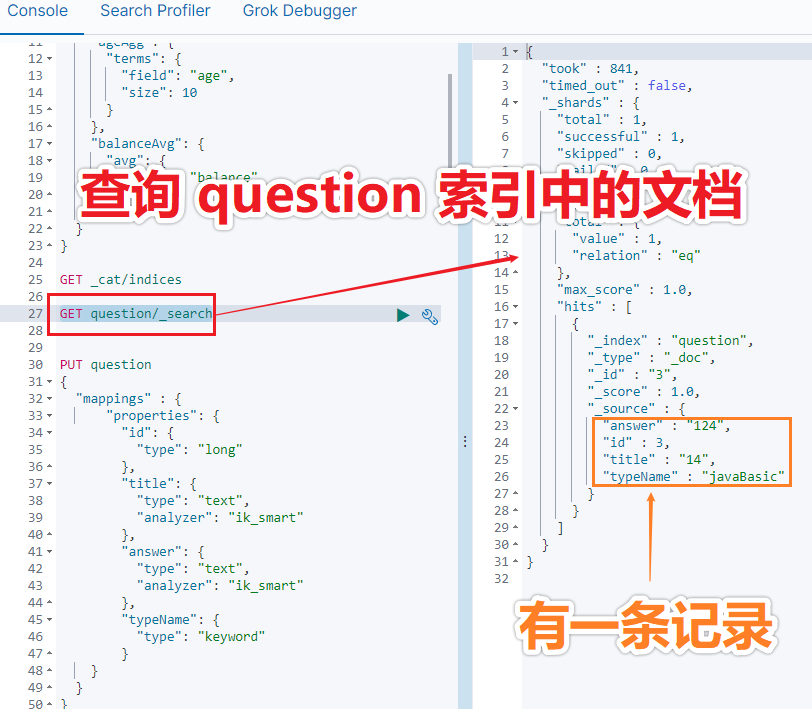
我们可以通过 kibana 的控制台来查看 question 索引中的文档。通过以下命令来查看:
GET question/_search
执行结果如下图所示,有一条记录:
另外大家有没有疑问:可以重复更新题目吗?
答案是可以的,保存到 ES 的数据是幂等的,因为保存的时候带了一个类似数据库主键的 id。
四、实战:查询 ES 数据
我们已经将数据同步到了 ES 中,现在就是前端怎么去查询 ES 数据中,这里我们还是使用 Postman 来模拟前端查询请求。
4.1 定义请求参数
请求参数我定义了三个:
- keyword:用来匹配问题或者答案。
- id:用来匹配题目 id。
- pageNum:用来分页查询数据。
这里我将这三个参数定义为一个类:
@Data
public class SearchParam {
private String keyword; // 全文匹配的关键字
private String id; // 题目 id
private Integer pageNum; // 查询第几页数据
}
4.2 定义返回参数
返回的 response 我也定义了四个字段:
- questionList:查询到的题目列表。
- pageNum:第几页数据。
- total:查询到的总条数。
- totalPages:总页数。
定义的类如下所示:
@Data
public class SearchQuestionResponse {
private List<QuestionEsModel> questionList; // 题目列表
private Integer pageNum; // 查询第几页数据
private Long total; // 总条数
private Integer totalPages; // 总页数
}
4.3 组装 ES 查询参数
调用 ES 的查询 API 时,需要构建查询参数。
组装查询参数的核心代码如下所示:
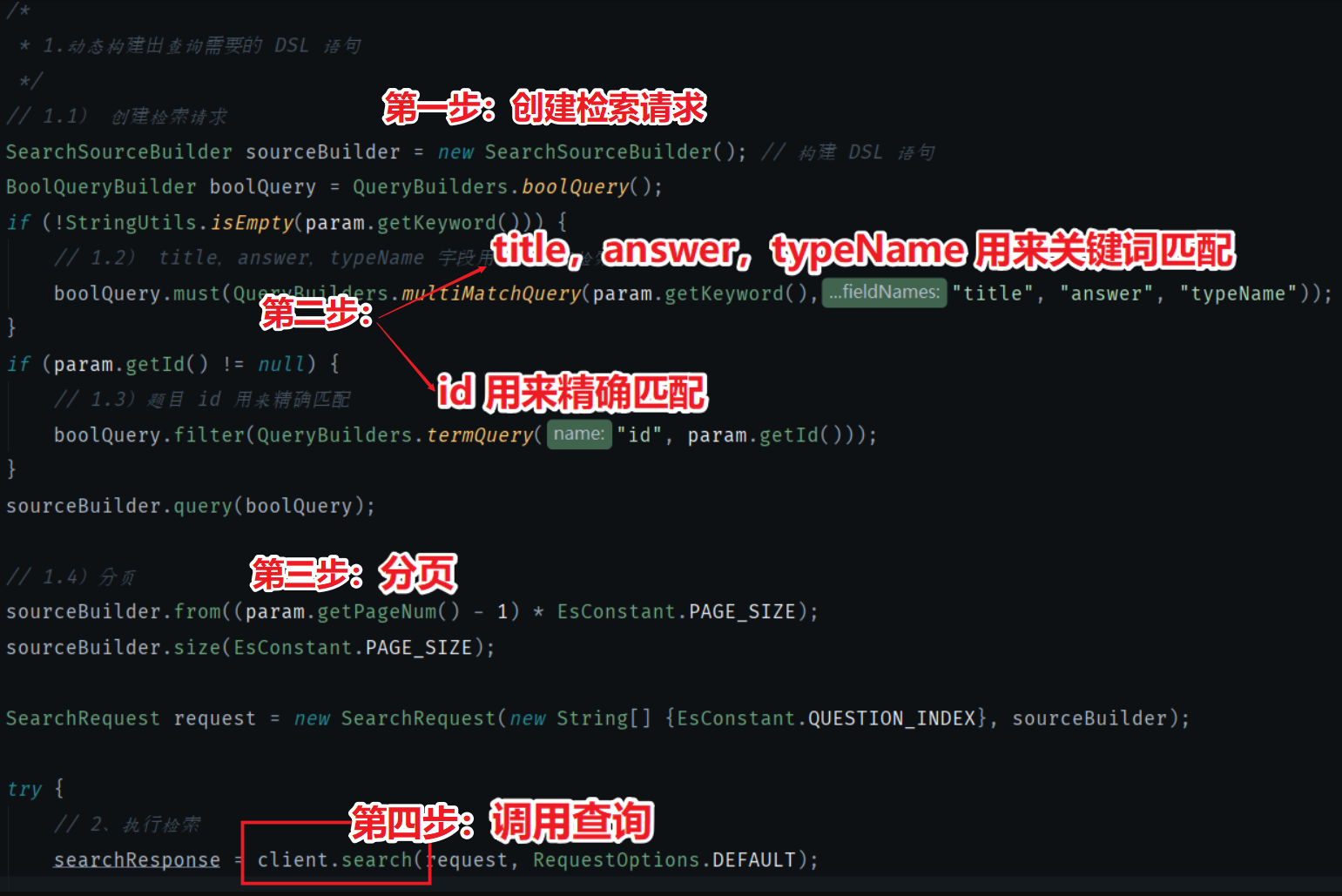
第一步:创建检索请求。
第二步:设置哪些字段需要模糊匹配。这里有三个字段:title,answer,typeName。
第三步:设置如何分页。这里分页大小是 5 个。
第四步:调用查询 api。
4.4 格式化 ES 返回结果
ES 返回的数据是 ES 定义的格式,真正的数据被嵌套在 ES 的 response 中,所以需要格式化返回的数据。
核心代码如下图所示:
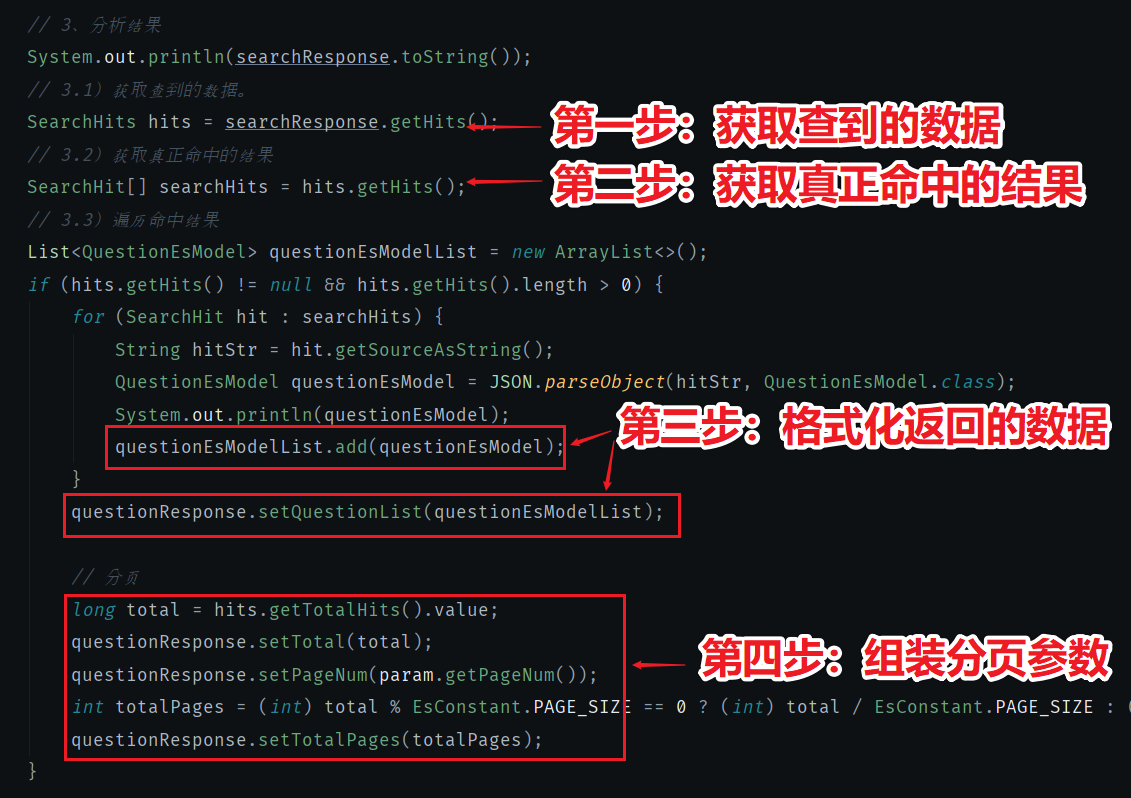
- 第一步:获取查到的数据。
- 第二步:获取真正命中的结果。
- 第三步:格式化返回的数据。
- 第四步:组装分页参数。
4.5 测试 ES 查询
4.5.1 实验一:测试 title 匹配
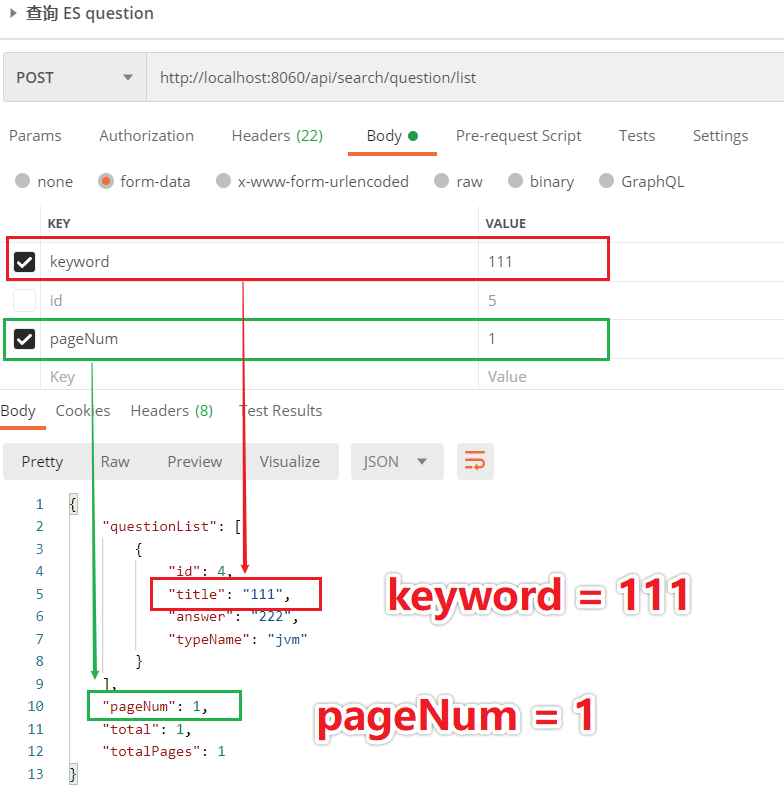
我们现在想要验证 title 字段是否能匹配到,传的请求参数 keyword = 111,匹配到了 title = 111 的数据,且只有一条。页码 pageNum 我传的 1,表示返回第一页数据。如下图所示:
4.5.2 实验二:测试 answer 匹配
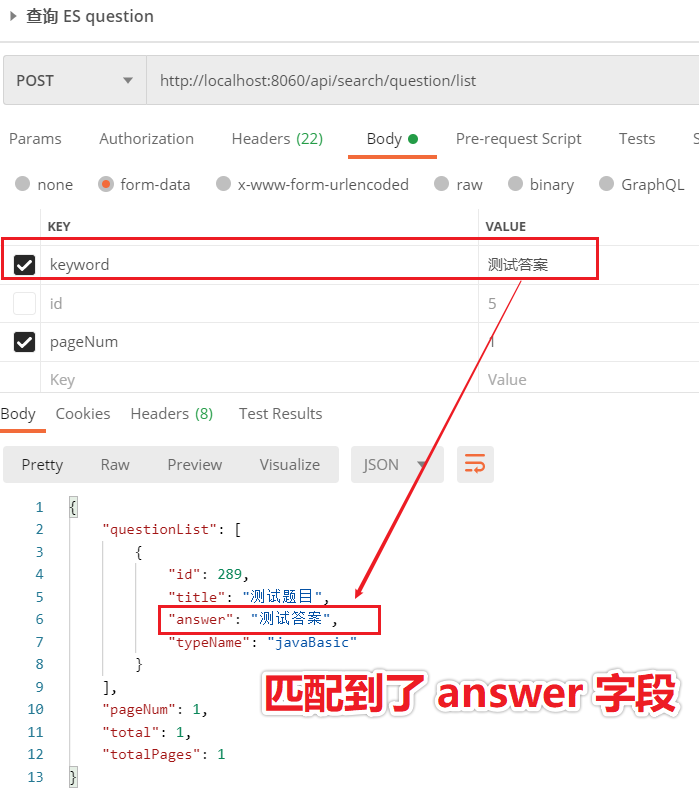
我们现在想要验证 answer 字段是否能匹配到,传的请求参数 keyword = 测试答案,匹配到了 title = 测试答案的数据,且只有一条,说明查询成功。如下图所示:
4.5.2 实验三:测试 id 匹配
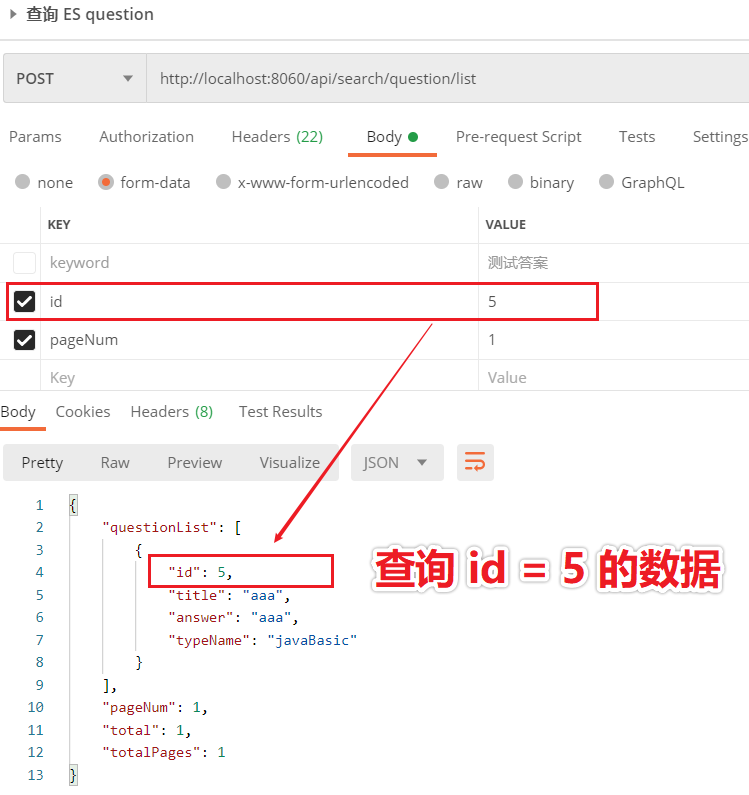
我们现在想要匹配题目 id 的话,需要传请求参数 id,而且 id 是精确匹配。另外 id 和 keyword 是取并集,所以不能传 keyword 字段。
请求参数 id = 5,返回结果也是 id =5 的数据,说明查询成功。如下图所示:
五、总结
本文通过我的开源项目 passjava 来讲解 ES 的整合,ES 的 API 使用以及测试。非常详细地讲解了每一步该如何做,相信通过阅读本篇后,再加上自己的实践,一定能掌握前后端该如何使用 ES 来达到高效搜索的目的。
当然,ES API 还有很多功能未在本文实践,有兴趣的同学可以到 ES 官网进行查阅和学习。
再次强调:本文的代码都是辛苦调试出来的,请不要忘记点赞和转发哦~
1W字|40 图|硬核 ES 实战的更多相关文章
- 【开源我写的富文本】打造全网最劲富文本技术选型之经典OOP仍是魅力硬核。
套路--先贴图 demo : http://www.vvui.net/editor/index.html gitee : https://gitee.com/kevin-huang/Bui-Edit ...
- 程序员需要了解的硬核知识之CPU
大家都是程序员,大家都是和计算机打交道的程序员,大家都是和计算机中软件硬件打交道的程序员,大家都是和CPU打交道的程序员,所以,不管你是玩儿硬件的还是做软件的,你的世界都少不了计算机最核心的 - CP ...
- 【Nginx】冰河又一本超硬核Nginx PDF教程免费开源!!
写在前面 在 [冰河技术] 微信公众号中的[Nginx]专题,更新了不少文章,有些读者反馈说,在公众号中刷 历史文章不太方便,有时会忘记自己看到哪一篇了,当打开一篇文章时,似乎之前已经看过了, 但就是 ...
- 【硬核摄影2.0】用线性CCD器件制作扫描相机
本文参考资料:[1] (Strongly Recommend!) Fundamentals and Experiments of Line Scan Camera: http://www.elm-ch ...
- 从0开始手把手带你入门Vue3-全网最全(1.1w字)
天命不足畏,祖宗不足法. --王安石 前言 本文并非标题党,而是实实在在的硬核文章,如果有想要学习Vue3的网友,可以大致的浏览一下本文,总体来说本篇博客涵盖了Vue3中绝大部分内容,包含常用的Com ...
- 重磅硬核 | 一文聊透对象在 JVM 中的内存布局,以及内存对齐和压缩指针的原理及应用
欢迎关注公众号:bin的技术小屋 大家好,我是bin,又到了每周我们见面的时刻了,我的公众号在1月10号那天发布了第一篇文章<从内核角度看IO模型的演变>,在这篇文章中我们通过图解的方式以 ...
- Colder框架硬核更新(Sharding+IOC)
目录 引言 控制反转 读写分离分库分表 理论基础 设计目标 现状调研 设计思路 实现之过五关斩六将 动态对象 动态模型缓存 数据源移植 查询表达式树深度移植 数据合并算法 事务支持 实际使用 展望未来 ...
- 阿里P7整理“硬核”面试文档:Java基础+数据库+算法+框架技术等
现在的程序员越来越多,大部分的程序员都想着自己能够进入大厂工作,但每个人的能力都是有差距的,所以并不是人人都能跨进BATJ.即使如此,但身在职场的我们一刻也不能懈怠,既然对BATJ好奇,那么就要朝这个 ...
- 可编程逻辑(FPGA)与硬核处理器(HPS)之间互联的结构
本周我想进一步探究可编程逻辑(FPGA)与硬核处理器(HPS)之间互联的结构.我发现了三种主要方式,它们是如何映射并处理通信的,哪些组件需要管控时序并且有访问权限. AXI Bridge 为了能够实现 ...
随机推荐
- Datahero Inc利用区块链溯源,造福各行各业
近些年来,随着区块链技术的不断崛起以及快速发展,越多越多的人提出将区块链技术引入到溯源系统当中,溯源也成为了区块链技术的重要应用场景之一. 目前,Datahero inc已建设一整套的溯源平台系统,基 ...
- django学习-27.admin管理后台里:对列表展示页面的数据展示进行相关优化
目录结构 1.前言 2.完整的操作步骤 2.1.第一步:查看ModelAdmin类和BaseModelAdmin类的源码 2.2.第二步:查看表animal对应的列表展示页面默认的数据展示 2.3.第 ...
- .net使用CSRedis操作Redis缓存的简单笔记(新手教程)
0.介绍 .NET Core or .NET Framework 4.0+ client for Redis and Redis Sentinel (2.8) and Cluster. Include ...
- Python算法_斐波那契数列(10)
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项.斐波那契数列的定义如下: F(0) = 0, F(1) = 1F(N) = F(N - 1) + F(N - 2), 其中 ...
- 生成类库项目时同时生成的pdb文件是什么东东?
英文全称:Program Database File Debug里的PDB是full,保存着调试和项目状态信息.有断言.堆栈检查等代码.可以对程序的调试配置进行增量链接.Release 里的PDB是p ...
- 【死磕JVM】JVM快速入门之前戏篇
简介 Java是一门可以跨平台的语言,但是Java本身是不可以实现跨平台的,需要JVM实现跨平台.javac编译好后的class文件,在Windows.Linux.Mac等系统上,只要该系统安装对应的 ...
- 运行maven遇到的坑,差点崩溃了。
参考链接1:https://blog.csdn.net/lch_cn/article/details/8225448/ 参考链接2:https://jingyan.baidu.com/article/ ...
- SpringCloud(一):微服务架构概述
1-1. 系统进化理论概述 在系统架构与设计的实践中,经历了两个阶段,一个阶段是早些年常见的集中式系统,一个阶段是近年来流行的分布式系统: 集中式系统: 集中式系统也叫单体应用,就是把所有的程序.功 ...
- 手把手教你集成华为机器学习服务(ML Kit)人脸检测功能
当给自己拍一张美美的自拍照时,却发现照片中自己的脸不够瘦.眼睛不够大.表情不够丰富可爱-如果此时能够一键美颜瘦脸并且添加可爱的贴纸的话,是不是很棒? 当家里的小孩观看iPad屏幕时间过长或者眼睛离屏幕 ...
- Oracle数据库搬家牵扯出的一些知识点记录
Oracle数据库迁移过程中的一些记录 工作原因,对开发服务器的数据库进行了迁移,实际执行操作之前查了一下迁移oracle数据库的可行方案,最后用了 exp/imp 进行导出导入(这个比较简单),以及 ...