数仓day03-----日志预处理
1. 为什么要构建一个地理位置维表(字典)
在埋点日志中,有用户的地理位置信息,但是原始数据形式是GPS坐标,而GPS坐标在后续(地理位置维度分析)的分析中不好使用。gps坐标的匹配,不应该做这种精确匹配,应该做范围匹配,直接去匹配两个哪怕距离很近的gps坐标,很可能匹配不上,所以需要一个地理位置维表
2. 地理位置维表的设计模型(构建思想)是什么?
使用一种算法,将GPS坐标转换成一个字符串,并且当两个GPS坐标靠的越近,字符串的的吻合度会更大,这样就能通过GPS得到的字符串的吻合情况判断出该GPS的地理位置。
3. geohash地理位置字典构建的流程你能描述一下吗?
首先通过mysql中一系列的sql语句,得到包含经纬度信息,以及对应的省市区信息的表,然后在这个基础上,使用spark读取这个表中的数据,并调用geohash算法,将经纬度转换成转成字符串,然后将结果保存到指定文件中去,由于此处是用spark处理的,所以一般是保存到parquet文件中。
4. geohah编码的算法思想能够描述一下?
不断地将地球的经度、纬度范围,进行二分,输出1/0比特,形成一串二进制码(二分的次数越多,输出的bit串越长)。
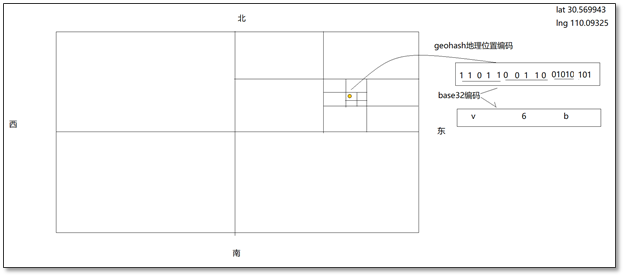
然后将这一串二进制码,按照5bit一组合查base32码表,
输出最终结果!
5. idmapping是什么含义?为什么要做idmapping?
idmapping其实就是对每条行为日志数据按照其内部的一些标识(比如uid/imei码/imsi码/mac/androidid/uuid),确定该条数据的所属用户。
- 现实的无奈
在现实的日志数据中,由于,用户可能使用各种各样的设备,有着各种各样的前端入口,甚至同一个用户拥有多个设备以及使用多种前端入口,就会导致,日志数据中对同一个人,不同时间段所收集到的日志数据中,可能取到的标识个数、种类各不相同;
比如:
用户可能使用各种各样的设备:
1)手机、平板电脑
2)安卓手机、ios手机、winphone手机
3)安卓系统有各种版本 ( 5.0 6.0 7.0 8.0 9.0 )
4)ios系统也有各种版本(3.x 4.x 5.x 6.x 7.x .... 12.x )
产生问题:
用户设备的标识,没办法轻易定制一个规则来取某个作为唯一标识:
mac:手机网卡物理地址, 若干早期版本的ios,winphone,android可取到
imei(入网许可证序号):安卓系统可取到,若干早期版本的ios,winphone可取到,运营商可取到
imsi(手机SIM卡序号):安卓系统可取到,若干早期版本的ios,winphone可取到,运营商可取到
androidid :安卓系统id
openuuid(app自己生成的序号) :卸载重装app就会变更
idfa(广告跟踪码)
deviceid(app日志采集埋点开发人员自己定义一种逻辑id,可能取自android,imei,openudid等):逻辑上的id
- 从而导致:
有一些数据中,用户有登录账号,而有些没有;
有一些数据中,有imei码,mac地址;而有些则有mac地址和android;
前一日的数据中,有uid,android,而后一日数据中有android,mac地址
在这些情况中,如果按照之前的方案来生成数据的唯一标识,显然错漏百出!
如下图:

要从这些纷繁复杂的各类id中,分辨出哪些id属于同一个受众(设备),用普通的“where x=y”这种简单条件逻辑很难实现。
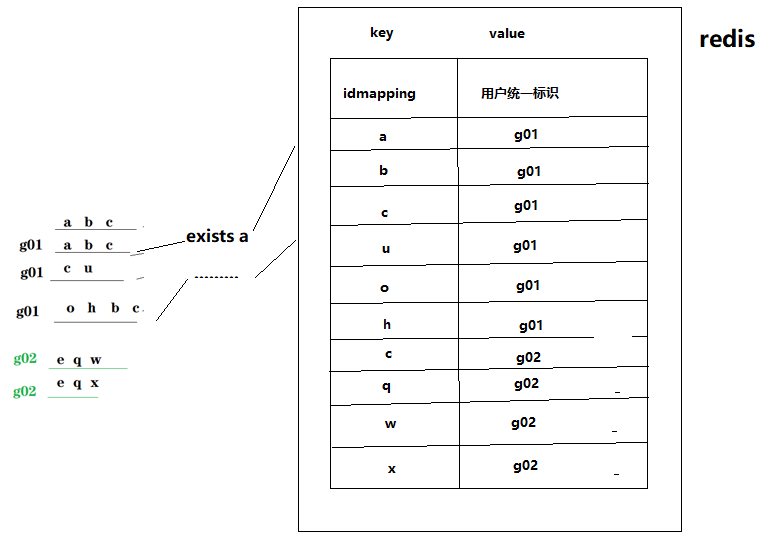
6. 利用redis来实现idmapping的思想、流程?
(1)思想:
将用户的各种id标识在redis作为key存储,而对应的value为用户的统一标识,这样只要查看redis中的key就能得出用户的信息
(2)流程:
在redis创建idmapping表,其中标识id为key,对应用户的统一标识为value===>从日志数据中抽取一条数据的所有标识id===>判断提取出来的标识id是否存在一个为idmapping表的key===>若不存在,则将这些标识id作为key,value为该批标识id中按字典排序最小的标识id,并存到idmapping表中,若存在,则取出key对应的值,并将其余的标识id都作为key,value为刚取出的值,存入idmapping表。
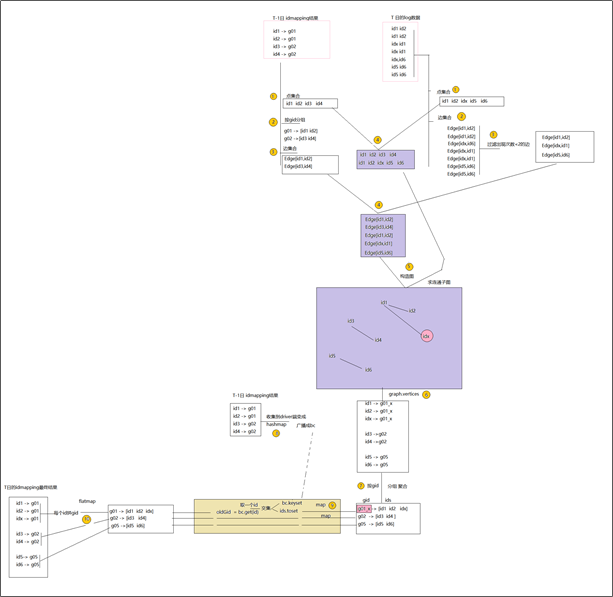
7. 利用图计算来实现idmapping的思想、流程?
(1)思想
采用图计算手段,找到各种id标识之间的关联关系,从而识别出哪些id标识属于同一个人
(2)流程
- 将当日数据中的所有用户标识字段,及标志字段之间的关联,生成点集合、边集合
将上一日的ids->guid的映射关系,也生成点集合、边集合
- 将上面两类点集合、边集合合并到一起生成一个图
再对上述的图执行“最大连通子图”算法,得到一个连通子图结果
在从结果图中取到哪些id属于同一组,并生成一个唯一标识
将上面步骤生成的唯一标识去比对前日的ids->guid映射表(如果一个人已经存在guid,则沿用原来的guid)
8. 目前的方案中都存在哪些问题?可能会造成什么样的影响?
方案一:借助redis实现idmapping
(1)这种形式的idmapping会将同一个人的日志行为识别成多个人的,但是回溯,将以前某天是同一个guid的多人合并,修改key-value时,计算量会很大,一般是不去做的
(2)这种形式会造成将单个用户识别成多个用户,影响后续的数据分析
方案二:使用图计算实现idmapping
(1)该方式可以通过将当日的id映射字典与前一日的id映射字典进行结合的方式,解决一个用户被当作多个用户的行为。但其又带来了另外一个问题,比如T-1天一个用户被识别成多个人(即存在多个用户统一标识:guid),并且在T天发现其为1个人,这时T天的guid就只能选择前一天多个guid的之一了,这样以来guid的延续性就不能保证了
(2)当进行数据分析时,比如对前几天的数据进行统计分析时,其还是会将diT-1天的数据识别成多个人,就会造成数据分析的不准确,
9. 项目中前一日的id映射字典和当日的id映射字典如何结合?
(1)将上一日的idmap映射字典,解析成点、边集合
(2)构造当日图计算中的点集合以及边集合
(3)分别将装有上一日的点集合的rdd与当日的点集合的rdd,上一日的边集合的rdd与当日的边集合的rdd进行union
数仓day03-----日志预处理的更多相关文章
- 数仓day04----日志预处理2
1.详细描述idmap的整个计算方案 (1)使用SparkSession对象读取用户不同类别的埋点日志,解析并抽取出相应的标识id,使用union进行合并,得到装有汇总标识id的rdd(ids) (2 ...
- 数仓day01
1. 该项目适用哪些行业? 主营业务在线上进行的一些公司,比如外卖公司,各类app(比如:下厨房,头条,安居客,斗鱼,每日优鲜,淘宝网等等) 这类公司通常要针对用户的线上访问行为.消费行为.业务操作行 ...
- 数仓1.4 |业务数仓搭建| 拉链表| Presto
电商业务及数据结构 SKU库存量,剩余多少SPU商品聚集的最小单位,,,这类商品的抽象,提取公共的内容 订单表:周期性状态变化(order_info) id 订单编号 total_amount 订单金 ...
- 数仓1.1 分层| ODS& DWD层
数仓分层 ODS:Operation Data Store原始数据 DWD(数据清洗/DWI) data warehouse detail数据明细详情,去除空值,脏数据,超过极限范围的明细解析具体表 ...
- 【云+社区极客说】新一代大数据技术:构建PB级云端数仓实践
本文来自腾讯云技术沙龙,本次沙龙主题为构建PB级云端数仓实践 在现代社会中,随着4G和光纤网络的普及.智能终端更清晰的摄像头和更灵敏的传感器.物联网设备入网等等而产生的数据,导致了PB级储存的需求加大 ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
- 数仓建设中最常用模型--Kimball维度建模详解
数仓建模首推书籍<数据仓库工具箱:维度建模权威指南>,本篇文章参考此书而作.文章首发公众号:五分钟学大数据,公众号中发送"维度建模"即可获取此书籍第三版电子书 先来介绍 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Hive篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈--现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边 ...
随机推荐
- Luogu P3758 [TJOI2017]可乐 | 矩阵乘法
题目链接 让我们先来思考一个问题,在一张包含$n$个点的图上,如何求走两步后从任意一点$i$到任意一点$j$的方案数. 我们用$F_p(i,j)$来表示走$p$步后从$i$到$j$的方案数,如果存储原 ...
- 51nod_1001 数组中和等于K的数对(二分)
题意: 给出一个整数K和一个无序数组A,A的元素为N个互不相同的整数,找出数组A中所有和等于K的数对.例如K = 8,数组A:{-1,6,5,3,4,2,9,0,8},所有和等于8的数对包括(-1,9 ...
- JAVA笔记12__字节、字符缓冲流/打印流/对象流/
/** * !!:以后写流的时候一定要加入缓冲!! * 对文件或其它目标频繁的读写操作,效率低,性能差. * 缓冲流:好处是能更高效地读写信息,原理是将数据先缓冲起来,然后一起写入或读取出来. * * ...
- 【mysql1】如何删除MySQL内存|不再跟新系列
完全卸载mysql的具体步骤: 包括停止服务 + 卸载相关程序 + 删除注册表等等 步骤一: windows键+R-->Control-->程序和功能:所有MySQL程序点击右键 ...
- elasticsearch7.x配置文件
前言: 以下配置文件基于elasticsearch-7.13.4版本,当然也适用于其它7.x版本 集群环境: 部署3个节点的集群,各个节点不做角色区分,既是master,也是data,在性能 上这种方 ...
- ORACLE,mysql中替换like的函数
数据库中存储了海量的数据,当查询时使用like,速度明显变慢.我在做项目时,发现使用内部函数INSTR,代替传统的LIKE方式查询,并且速度更快. INSTR()函数返回字符串中子字符串第一次出现的位 ...
- 高德地图API中折线polyline不能跨越180度经度线的解决方案
1.问题 最近在使用高德地图的API,有一个需求是画出对象的历史轨迹,采用了高德地图API中的折线polyline函数.但如果需要跨180度经度线的折线,会出现不能跨越的情况,如下图所示: 图中有三个 ...
- Part 29 AngularJS intellisense in visual studio
In the previous videos if you have noticed as we were typing the angular code in Script.js file we w ...
- 记录线上APP一个排序比较引发的崩溃 Comparison method violates its general contract!
最近在做产品需求的时候上线了一个新的产品需求,给用户多了一种新的排序排序规则,更加方便用户找到自己想要的东西.新版本发布后,QA 给我发了一个 线上崩溃 bug 链接,具体内容如下: 看到上面的链接, ...
- C 语言基础,来喽!
前言 C 语言是一门抽象的.面向过程的语言,C 语言广泛应用于底层开发,C 语言在计算机体系中占据着不可替代的作用,可以说 C 语言是编程的基础,也就是说,不管你学习任何语言,都应该把 C 语言放在首 ...