论文解读(DFCN)《Deep Fusion Clustering Network》
Paper information
Titile:Deep Fusion Clustering Network
Authors:Wenxuan Tu, Sihang Zhou, Xinwang Liu, Xifeng Guo, Zhiping Cai, En Zhu, Jieren Cheng
Sources:2020, AAAI
Code:Download
Paper:Download
Others:4 Citations, 41 References
Abstract
The disadvantage of former literure.
- Lack a dynamic fusion mechanism to selectively integrate and refine the information of graph structure and node attributes for consensus representation learning;
- fail to extract information from both sides for robust target distribution generation.
1 Introduction
Two important factors of deep clustering method:
the optimization objective
the fashion of feature extraction
Deep cluster method can be divide into five categories:
Subspace clustering-based methods
Generative adversarial network-based methods
Spectral clustering-based methods
Gaussian mixture model-based methods
Self-optimizing-based methods.(DFCN的类型)
Recent literature shows a strong tendency in extracting geometrical structure information and then integrates it with attribute information for representation learning.
We fund that the formaer efforts have some problem:
- The existing methods lack an crossmodality dynamic information fusion and processing mechanism. Information from two sources is simply aligned or concatenated, leading to insufficient information interaction and merging;
- The generation of the target distribution in existing literature has seldom used information from both sources, making the guidance of network training less comprehensive and accurate.
To tackle the above issues, we propose a deep fusion clustering network (DFCN).
The main idea of our solution is to design a dynamic information fusion module to finely process the attribute and structure information extracted from autoencoder (AE) and graph autoencoder (GAE) for a more comprehensive and accurate representation construction.
- Firstly, we integrate two kinds of sample embeddings in both the perspective of local and global level for consensus representation learning.
- After that, by estimating the similarity between sample points and pre-calculated cluster centers in the latent embedding space with Students’ t-distribution, we acquire more precise target distribution.
- Finally, we design a triplet selfsupervision mechanism which uses the target distribution to provide more dependable guidance for AE, GAE, and the information fusion part simultaneously.
We develop an improved graph autoencoder (IGAE) with a symmetric structure and reconstruct the adjacency matrix with both the latent representations and the feature representations reconstructed by the graph decoder.(我们开发了一种改进的具有对称结构的图自动编码器(IGAE),并利用图解码器重构的潜在表示和特征表示重构了邻接矩阵。)
The key contributions of this paper are listed as follows:
- We propose a deep fusion clustering network (DFCN).
- We develop a symmetric graph autoencoder.
- Extensive experiment results on six public benchmark datasets have get SOTA.
2 Related Work
2.1 Attributed Graph Clustering
- GCN-based clustering methods that jointly learn graph structure and node attributes.
- Graph autoencoder (GAE) and variational graph autoencoder (VGAE) are proposed to integrate graph structure into node attributes via iteratively aggregating neighborhood representations around each central node.
- SDCN proves that integrate autoencoder and GCN module for better representation learning.
- Autoencoder can help provide complementary attribute information and help relieve the over-smoothing phenomenon of GCN modul.
- GCN module provides high-order structure information to auto encoder.
由于 SDCN 将 GCN model 作为一个正则化技巧,并没有充分利用 self-optimizing network (应该是指AE部分)学习到的表示做修正。所以本文提出一种融合 AE 和 IGAE 的框架。
2.2 Target Distribution Generation
- Many deep clustering methods seek to generate the target distribution for discriminative representation learning in a self-optimizing manner.(生成一个 target network 指导另外一个网络训练,对这个 target network 一般需要高置信度。可以参考《 SDCN 》)
Here, I have some models to recommend:
3 The Proposed Method
Our model can be divided into four part:
- an autoencoder.
- an improved graph autoencoder.
- a fusion module.
- the optimization targets
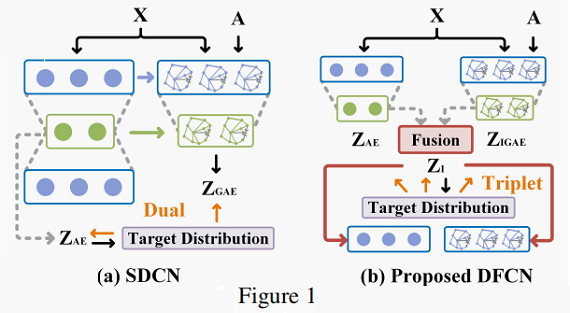
3.1 Notations
- undirected graph $\mathcal{G}=\{\mathcal{V}, \mathcal{E}\}$ with $K$ cluster centers,
- $\mathcal{V}=\left\{v_{1}, v_{2}, \ldots, v_{N}\right\} $ are node set.
- $E$ are the node set and the edge set.
- attribute matrix $\mathbf{X} \in \mathbb{R}^{N \times d}$ .
- original adjacency matrix $\mathbf{A}=\left(a_{i j}\right)_{N \times N} \in \mathbb{R}^{N \times N}$ . Here, $a_{i j}=1$ if $\left(v_{i}, v_{j}\right) \in \mathcal{E} $, otherwise $a_{i j}=0$ .
- degree matrix is $\mathbf{D}=\operatorname{diag}\left(d_{1}, d_{2}, \ldots, d_{N}\right) \in \mathbb{R}^{N \times N}$ and $d_{i}=\sum\limits_{v_{j} \in V} a_{i j} $.
- $\widetilde{\mathbf{A}} \in \mathbb{R}^{N \times N}= \mathbf{D}^{-\frac{1}{2}}(\mathbf{A}+\mathbf{I}) \mathbf{D}^{-\frac{1}{2}} $, where $\mathbf{I} \in \mathbb{R}^{N \times N}$ indicates that each node in $\mathcal{V} $ is linked with a self-loop structure.
All notations are summarized in Table 1.

3.2 Fusion-based Autoencoders
3.2.1 Input of the Decoder.
- In our proposed method, with the compressed representations of AE and GAE, we first integrate the information from both sources for a consensus latent representation.
- Then, with this embedding as an input, both the decoders of AE and GAE reconstruct the inputs of two sub-networks.
3.2.2 Improved Graph Autoencoder.
- The classic AE are usually symmetric, while GCN are usually asymmetric.
- GAE and AE require only the latent representation to reconstruct the adjacency information and overlook that the structure-based attribute information can also be exploited for improving the generalization capability of the corresponding network.
- To solve the problem ,we design a symmetric improved graph autoencoder (IGAE) which need to reconstruct both the weighted attribute matrix and the adjacency matrix simultaneously.
In the proposed IGAE, a layer in the encoder and decoder is formulated as:
$\mathbf{Z}^{(l)}=\sigma\left(\widetilde{\mathbf{A}} \mathbf{Z}^{(l-1)} \mathbf{W}^{(l)}\right)\quad \quad \quad (1)$
$\widehat{\mathbf{Z}}^{(h)}=\sigma\left(\widetilde{\mathbf{A}} \widehat{\mathbf{Z}}^{(h-1)} \widehat{\mathbf{W}}^{(h)}\right)\quad \quad \quad (2)$
Where
- $\mathbf{W}^{(l)}$ and $\widehat{\mathbf{W}}^{(h)}$ denote the learnable parameters of the $l-th$ encoder layer and $h-th$ decoder layer.
- $\sigma$ is a non-linear activation function, such as ReLU or Tanh.
Our IGAE is designed to minimize a hybrid loss function:
$L_{I G A E}=L_{w}+\gamma L_{a}\quad \quad \quad (3)$
Where
- $\gamma$ is a pre-defined hyper-parameter that balances the weight of the two reconstruction loss functions.
Specially, $ L_{w} $ and $ L_{a} $ are defined as follows:
$L_{w} =\frac{1}{2 N}\|\widetilde{\mathbf{A}} \mathbf{X}-\widehat{\mathbf{Z}}\|_{F}^{2}\quad \quad \quad (4)$
$L_{a} =\frac{1}{2 N}\|\widetilde{\mathbf{A}}-\widehat{\mathbf{A}}\|_{F}^{2}\quad \quad \quad (5)$
- In Eq.(4), $\widehat{\mathbf{Z}} \in \mathbb{R}^{N \times d}$ is the reconstructed weighted attribute matrix.
- In Eq.( 5 ), $\widehat{\mathbf{A}} \in \mathbb{R}^{N \times N}$ is the reconstructed adjacency matrix generated by an inner product operation with multi-level representations of the network.
IGAE is termed to minimize the reconstruction loss over the weighted attribute matrix and the adjacency matrix at the same time.
3.2.3 Structure and Attribute Information Fusion
Structure and attribute information fusion (SAIF) module. It has two parts:
- a crossmodality dynamic fusion mechanism.
- a triplet selfsupervised strategy.
The overall structure of SAIF is illustrated in Fig. 2.

Part 1 :Cross-modality Dynamic Fusion Mechanism.
This modul includes four Steps:
- First, we combine the latent embedding of $\mathrm{AE} \left(\mathbf{Z}_{A E} \in \mathbb{R}^{N \times d^{\prime}}\right)$ and IGAE $\left(\mathbf{Z}_{I G A E} \in \mathbb{R}^{N \times d^{\prime}}\right)$ with a linear combination operation:
$\mathbf{Z}_{I}=\alpha \mathbf{Z}_{A E}+(1-\alpha) \mathbf{Z}_{I G A E}\quad \quad \quad (6)$
In Eq.(6)
- $d^{\prime}$ is the latent embedding dimension, and
- $\alpha$ is a learnable coefficient and $\alpha$ is initialized as $0.5$ and then tuned automatically with a gradient decent method.
- Secondly, we process the combined information $\mathbf{Z}_{I}$ with a graph convolution-like operation. With this operation, we enhance the initial fused embedding $\mathbf{Z}_{I} \in \mathbb{R}^{N \times d^{\prime}}$ by considering the local structure within data:
$ \mathbf{Z}_{L}=\widetilde{\mathbf{A}} \mathbf{Z}_{I}\quad \quad \quad (7)$
In Eq.(7)
- $\mathbf{Z}_{L} \in \mathbb{R}^{N \times d^{\prime}}$ denotes the local structure enhanced $\mathbf{Z}_{I}$ .
- Thirdly, we further introduce a self-correlated learning mechanism to exploit the non-local relationship in the preliminary information fusion space among samples.We first calculate the normalized self-correlation matrix $\mathbf{S} \in \mathbb{R}^{N \times N}$ through Eq.(8):
${\large \mathbf{S}_{i j}=\frac{e^{\left(\mathbf{Z}_{L} \mathbf{Z}_{L}^{\mathrm{T}}\right)_{i j}}}{\sum\limits _{k=1}^{N} e^{\left(\mathbf{Z}_{L} \mathbf{Z}_{L}^{\mathrm{T}}\right)_{i k}}}} \quad \quad \quad (8)$
And then ,caculate the global correlation:
$\mathbf{Z}_{G}=\mathbf{S} \mathbf{Z}_{L}$ .
- Finally,we adopt a skip connection to encourage information to pass smoothly within the fusion mechanism:
$\widetilde{\mathbf{Z}}=\beta \mathbf{Z}_{G}+\mathbf{Z}_{L} \quad \quad \quad (9)$
In Eq.(9)
- $\beta$ is a scale parameter. We initialize it as $0$ and learn its weight while training the network.
Conclusion of this Part
- Technically, our cross-modality dynamic fusion mechanism considers the sample correlation in both the perspective of the local and global level. Thus, it has potential benefit on finely fusing and refining the information from both $\mathrm{AE}$ and IGAE for learning consensus latent representations.
Part 2 :Triplet Self-supervised Strategy
To generate more reliable guidance for clustering network training.
The target distribution generation steps as following:
- Step1:In Eq. (10), we calculate the similarity between the $i -th$ sample $\left(\tilde{z}_{i}\right)$ and the $j -th$ precalculated clustering center $\left(u_{j}\right)$ in the fused embedding space using Student's t -distribution as kernel.
${\large q_{i j}=\frac{\left(1+\left\|\tilde{z}_{i}-u_{j}\right\|^{2} / v\right)^{-\frac{v+1}{2}}}{\sum_{j^{\prime}}\left(1+\left\|\tilde{z}_{i}-u_{j^{\prime}}\right\|^{2} / v\right)^{-\frac{v+1}{2}}}}\quad \quad \quad (10)$
Where
- $v$ is the degree of freedom for Student's t -distribution.
- $q_{i j}$ indicates the probability of assigning the $i -th$ node to the $j- th$ center.
The soft assignment matrix $\mathbf{Q} \in \mathbb{R}^{N \times K}$ reflects the distribution of all samples.
- Step2:To increase the confidence of cluster assignment, we introduce Eq.(11) to drive all samples to get closer to cluster centers.
${\large p_{i j}=\frac{q_{i j}^{2} / \sum\limits _{i} q_{i j}}{\sum\limits _{j^{\prime}}\left(q_{i j^{\prime}}^{2} / \sum\limits _{i} q_{i j^{\prime}}\right)}} \quad \quad \quad (11)$
Where
- $0 \leq p_{i j} \leq 1$ is an element of the generated target distribution $\mathbf{P} \in \mathbb{R}^{N \times K} $.
We then calculate the soft assignment distribution of $\mathrm{AE}$ and IGAE by using Eq. 10 over the latent embeddings of two subnetworks, respectively. We denote the soft assignment distribution of IGAE and $\mathrm{AE}$ as $\mathrm{Q}^{\prime}$ and $\mathrm{Q}^{\prime \prime} $.
Unified training framework:To improve the representative capability of each component, we design a triplet clustering loss by adapting the KL-divergence in the following form:
$L_{K L}=\sum\limits _{i} \sum\limits_{j} p_{i j} \log \frac{p_{i j}}{\left(q_{i j}+q_{i j}^{\prime}+q_{i j}^{\prime \prime}\right) / 3}\quad \quad \quad (12)$
3.2.4 Joint loss and Optimization
The overall learning objective consists of two main parts, i.e., the reconstruction loss of AE and IGAE, and the clustering loss which is correlated with the target distribution:
$L=\underbrace{L_{\text {AE }}+L_{\text {IGAE }}}_{\text {Reconstruction }}+\underbrace{\lambda L_{K L}}_{\text {Clustering }} .\quad \quad \quad (13)$
Where
- $L_{AE}$ is the mean square error (MSE) reconstruction loss of AE.
The detailed learning procedure of the proposed DFCN is shown in Algorithm 1.

4 Experiments
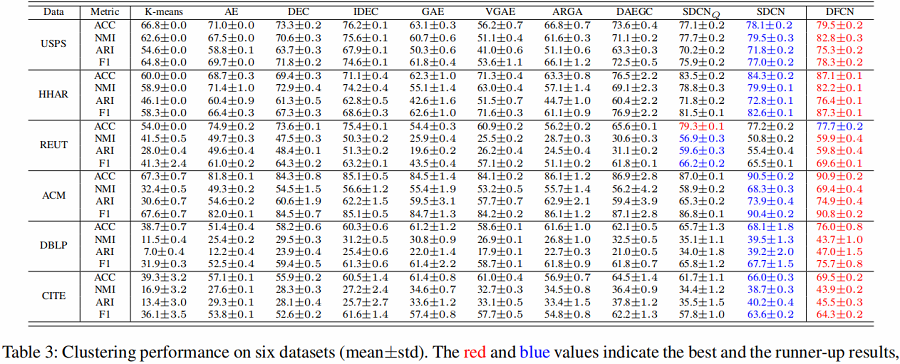
The clustering performance of our method and 10 baseline methods on six benchmark datasets are summarized in Table 3. Based on the results, we have the following observations:
- DFCN shows superior performance against the compared methods in most circumstances.
- It is obvious that GCN-based methods such as GAE, VGAE, ARGA, and DAEGC are not comparable to ours, because these methods under-utilize abundant information from data itself and might be limited to the oversmoothing phenomenon.
- DFCN achieves better clustering results than the strongest baseline methods $SDCN_{Q}$ and SDCN in the majority of cases, especially on HHAR, DBLP, and CITE datasets.
4.1 Ablation Studies
Effectiveness of IGAE

We conduct ablation studies to verify the effectiveness of IGAE and report the results in Fig. 3
$GAE- \mathrm{L}_{w}$ or $GAE- \mathrm{L}_{a}$ denotes the method optimized by the reconstruction loss function of weighted attribute matrix or adjacency matrix only.
We can find out that
- $GAE-L _{w}$ consistently performs better than $GAE-L _{a}$ on six datasets.
- IGAE clearly improves the clustering performance over the method which constructs the adjacency matrix only.
Both observations illustrate that our proposed reconstruction measure is able to exploit more comprehensive information for improving the generalization capability of the deep clustering network. By this means, the latent embedding inherits more properties from the attribute space of the original graph, preserving representative features that generate better clustering decisions.
Analysis of the SAIF Module

As summarized in Fig. 4, we observe that
- Compared with the baseline, Baseline-C method has about 0.5% to 5.0% performance improvements, indicating that exploring graph structure and node attributes in both the perspective of the local and global level is helpful to learn consensus latent representations for better clustering;
- The performance of Baseline-C-T method is consistently better than that of Baseline-C-S method on all datasets. The reason is that our triplet self-supervised strategy successfully generates more reliable guidance for the training of AE, IGAE, and the fusion part, making them benefit from each other.
Influence of Exploiting Both-source Information
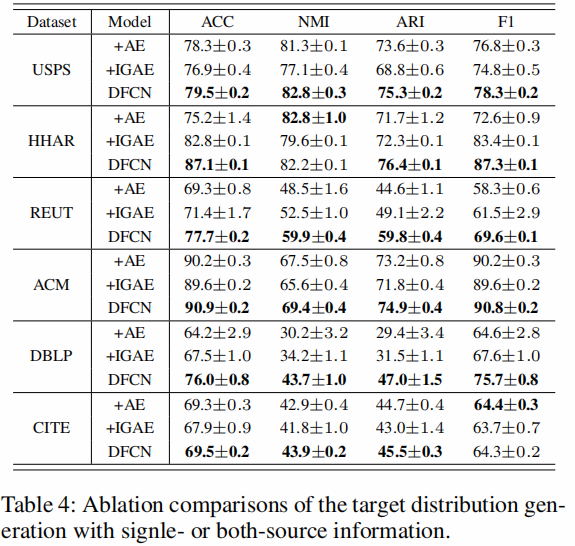
We compare our method with two variants to validate the effectiveness of complementary two-modality (structure and attribute) information learning for target distribution generation.
As reported in Table 4, +AE or +IGAE refers to the DFCN with only AE or IGAE part, respectively.
We found that:
- +AE and +IGRE achieve better performance on different datasets, it indicates that information from either AE or IGAE cannot consistently outperform that of their counterparts, combining the both-source information can potentially improve the robustness of the hybrid method.
- DFCN encodes both DNN- and GCN-based representations and consistently outperforms the singlesource methods. This shows that 1) both-source information is equally essential for the performance improvement of DFCN; 2) DFCN can facilitate the complementary twomodality information to make the target distribution more reliable and robust for better clustering.
Analysis of Hyper-parameter λ
As can be seen in Eq. 13 , DFCN introduces a hyperparameter $\lambda$ to make a trade-off between the reconstruction and clustering.
Fig. 5 illustrates the performance variation of DFCN when $\lambda$ varies from $0.01$ to $100$ .
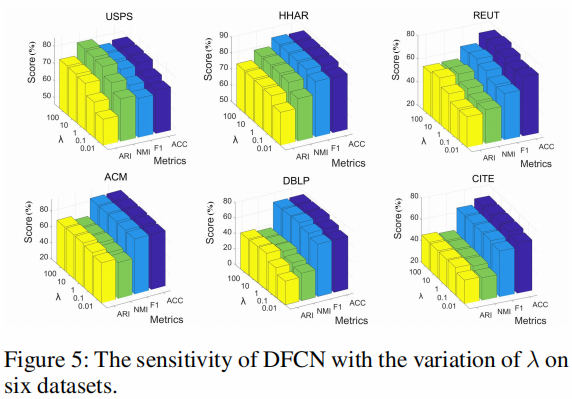
From these figures, we observe that
- the hyper-parameter $\lambda$ is effective in improving the clustering performance;
- the performance of the method is stable in a wide range of $\lambda$ ;
- $ \mathrm{DFCN}$ tends to perform well by setting $\lambda$ to $10$ across all datasets.
Visualization of Clustering Results
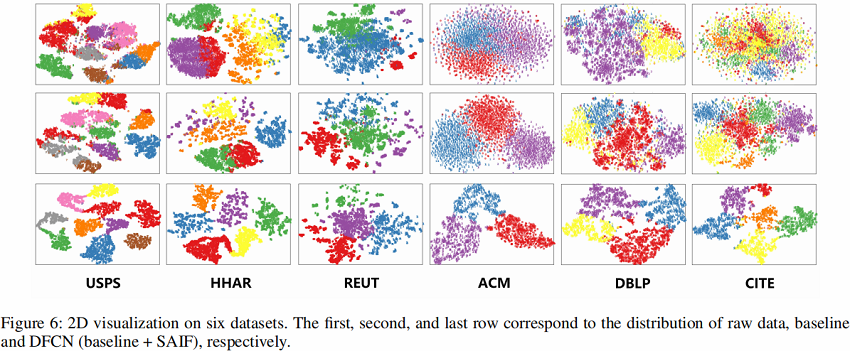
To intuitively verify the effectiveness of DFCN, we visualize the distribution of the learned clustering embedding $\widetilde{\mathbf{Z}}$ in two-dimensional space by employing t -SNE algorithm (Maaten and Hinton 2008). As illustrated in Fig. 6, DFCN can better reveal the intrinsic clustering structure among data.
Conclusion
本文提出了一种新的基于神经网络的聚类方法,即深度融合聚类网络(DFCN)。
在我们的方法中,SAIF 模块通过动态交叉模态融合机制和三重自监督策略来利用图的结构和节点属性。这样,对双方更多的共识和鉴别信息进行编码,构建鲁棒目标分布,有效地提供精确的网络训练指导。此外,所提出的IGAE能够帮助提高该方法的泛化能力。在6个基准数据集上的实验表明,DFCN始终优于最先进的基线方法。在未来,我们计划进一步改进我们的方法,使其适应于多视图图聚类和不完全多视图图聚类的应用。
Last modify :2022-01-27 17:59:09
『总结不易,加个关注呗!』

论文解读(DFCN)《Deep Fusion Clustering Network》的更多相关文章
- 论文解读《Deep Attention-guided Graph Clustering with Dual Self-supervision》
论文信息 论文标题:Deep Attention-guided Graph Clustering with Dual Self-supervision论文作者:Zhihao Peng, Hui Liu ...
- 论文解读《Bilinear Graph Neural Network with Neighbor Interactions》
论文信息 论文标题:Bilinear Graph Neural Network with Neighbor Interactions论文作者:Hongmin Zhu, Fuli Feng, Xiang ...
- 论文解读《Deep Resdual Learning for Image Recognition》
总的来说这篇论文提出了ResNet架构,让训练非常深的神经网络(NN)成为了可能. 什么是残差? "残差在数理统计中是指实际观察值与估计值(拟合值)之间的差."如果回归模型正确的话 ...
- 论文解读《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernel》
Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels: 一旦退化模型被定义,下一步就是使用公式表示能量函数(energy fun ...
- 论文解读(DCRN)《Deep Graph Clustering via Dual Correlation Reduction》
论文信息 论文标题:Deep Graph Clustering via Dual Correlation Reduction论文作者:Yue Liu, Wenxuan Tu, Sihang Zhou, ...
- 论文解读(GMIM)《Deep Graph Clustering via Mutual Information Maximization and Mixture Model》
论文信息 论文标题:Deep Graph Clustering via Mutual Information Maximization and Mixture Model论文作者:Maedeh Ahm ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 论文解读(DCN)《Towards K-means-friendly Spaces: Simultaneous Deep Learning and Clustering》
论文信息 论文标题:Towards K-means-friendly Spaces: Simultaneous Deep Learning and Clustering论文作者:Bo Yang, Xi ...
- 论文解读(SDNE)《Structural Deep Network Embedding》
论文题目:<Structural Deep Network Embedding>发表时间: KDD 2016 论文作者: Aditya Grover;Aditya Grover; Ju ...
随机推荐
- 【LeetCode】567. Permutation in String 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址:https://leetcode.com/problems/permutati ...
- 1145 - Dice (I)
1145 - Dice (I) PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB You hav ...
- 【云开发】10分钟零基础学会做一个快递查询微信小程序,快速掌握微信小程序开发技能(轮播图、API请求)
大家好,我叫小秃僧 这次分享的是10分钟零基础学会做一个快递查询微信小程序,快速掌握开发微信小程序技能. 这篇文章偏基础,特别适合还没有开发过微信小程序的童鞋,一些概念和逻辑我会讲细一点,尽可能用图说 ...
- 基于Spring MVC + Spring + MyBatis的【物流系统 - 公司信息管理】
资源下载:https://download.csdn.net/download/weixin_44893902/45601768 练习点设计:模糊查询.删除.新增 一.语言和环境 实现语言:JAVA语 ...
- Java Swing 如何设置图片大小
如下两行代码搞定: Image image = new ImageIcon("Img/ackground.jpg").getImage();// 这是背景图片 .png .jpg ...
- 使用.NET 6开发TodoList应用(17)——实现数据塑形
系列导航及源代码 使用.NET 6开发TodoList应用文章索引 需求 在查询的场景中,还有一类需求不是很常见,就是在前端请求中指定返回的字段,所以关于搜索的最后一个主题我们就来演示一下关于数据塑形 ...
- Windows下安装配置ant
1.ant安装 请从官网下载ant的*.zip格式的安装包, Windows建议下载*.zip版本, Linux建议下载*.gz版本. 2.配置环境变量 解压之后,在Windows中配置环境变量, 在 ...
- 字符串的展开expand
A. 字符串的展开(expand.cpp) 内存限制:64 MiB 时间限制:1000 ms 标准输入输出 题目类型:传统 评测方式:文本比较 题目描述 在初赛普及组的"阅读程序写结果&qu ...
- Python + Selenium 上传元素为button类型的文件的解决办法
工具:winspy Python所需安装模块:pywin32 (安装语句:pip install -i https://pypi.douban.com/simple pywin32) 元素位置: 对应 ...
- 在使用django admin的后台搜索时报错
在使用django admin的后台搜索时报错 百度说在search_fields中定义了非字符串字段,最后发现author引用了外键 解决办法: 有外健时应写成: 本表外键字段__外键所在表所需要查 ...