再看Lambda架构
最*看了一本《大数据系统构建》的书,发现之前对于Lambda架构的理解还是不够深入和清晰。
之前对Lambda架构的理解
Azure文档上有一张Lambda架构的图,
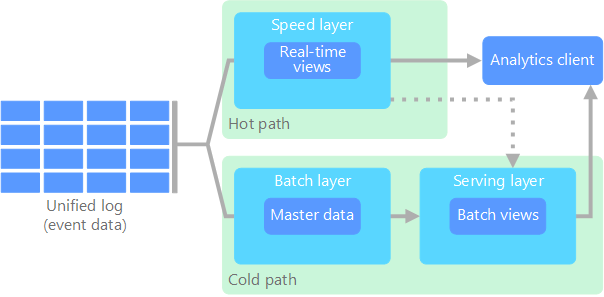
同时也配有对Lambda架构最基本的理解:
批处理层(冷路径)以原始形式存储所有传入数据,对数据进行批处理。 该处理的结果作为 批处理视图 存储。
速度层(热路径)可实时分析数据。 设计此层是为了降低延迟,但代价是准确性也会降低。
当初看Lambda架构的时候,更在意的点其实是将数据处理分成批处理层 和速度层 两个部分,批处理层 在处理大批量数据的时候是有性能优势的,而速度层 虽然在性能和准确性上会差一些,但是在时效性上有着无可取代的地位。
当初看的时候,会没有那么关注以原始形式存储 这几个关键字,虽然有概念,但是却没有那么在意。
现在对Lambda架构的理解
以原始形式存储
但是最*看完《大数据系统构建》之后,发现以原始形式存储 才是精华。
以原始形式存储 给我们带来了很好的容错能力,一个最简单的例子就是,如果是一个计算页面浏览量的分析任务,如果我们采用全增量架构 ,也就是在数据库中维护一个count来记录页面的访问量,那么一旦某一个版本,计算函数出错了,把一个页面计算了两遍,那么这些数据就会一直错误下去了。而如果我们只是存下了原始形式 的数据,那么只需要在改正bug后全量计算一遍,就可以将错误恢复了。
这个能力其实在Lambda架构中很重要,其实将数据处理分成批处理层 和速度层 两个部分,并不主要是因为他们处理速度的快慢,而是因为我们首先在思想上将大数据处理分成两种处理,一种是我可以牺牲时效性,但是要保证准确性、容错能力、算法的简洁性的批处理层 。一种是我如果还要时效性,那么就引入一个算法更复杂、准确性稍差的速度层 ,但这一切的前提是,我可以用批处理层 兜底,即使这一刻的数据是不太准确的,甚至由于代码的bug导致了数据是错误的,也没有太大影响,因为最终,都会通过批处理层 重新计算。
在洞悉了这一设计理念之后,书中的三层划分其实就很自然了,我们可以再引入一个增量批处理层 也就是将批处理再划分成2部分,一个是全量重新计算层 ,一个是增量计算层 ,增量计算的算法会同速度层 差不多,不过由于是批计算,所以吞吐量会更高一些,这一层才是当初我所理解的批处理层 。
联系Event Sourcing
再提一点,其实Event Sourcing也有以原始形式存储 的优势所在,如果业务系统采用Event Sourcing的方式来构建,那么一旦某个版本的bug导致了快照出现了问题,可以很轻易地通过无bug的新版本来更正快照。
同时Event Sourcing也为后续的Lambda架构提供了很充分的支持。
做数据接入避免不了选择接入的方式:全量接入、增量接入、WAL接入。它们又分别有着自己的优缺点:
全量接入:
每天使用select * from tableXXX来获取tableXXX的数据
优点:
- 可以捕获所有的数据变化,包括硬删除。
- 对业务侧的表设计没有任何要求。
缺点:
- 对业务侧的造成的压力大。
- 存储压力大,重复的数据多(这一点可以可以通过一些处理手段,将数据处理成增量形式)。
- 如果一条数据一天内变更了多次,只能获取到每天的最新状态。
所以全量接入只能考虑全表数据量比较小的一些表。
增量接入:
通过修改时间的字段来确定每天需要接入的数据。比如select * from tableXXX where date_format(optime,'%Y%m%d')='20000101'
优点:
- 对业务侧造成的压力小,只需要获取部分数据。
缺点:
- 业务侧硬删除的数据无法感知到,要求业务侧只进行软删除。
- 如果一条数据一天内变更了多次,只能获取到每天的最新状态。
- 要求业务侧记录数据变更的时间字段
WAL接入
通过同步Write-Ahead Log,并通过这些log来接入数据。比如MySQL的所有操作都会先写binlog,再更新数据,我们只需要订阅binlog,就可以还原数据了。
优点:
- 不像前两种接入,WAL接入能捕获所有的更新。
- 数据延迟小,可以达到秒级延
缺点:
- 技术门槛较高,需要理解binlog、考虑数据传输过程中端到端的一致性
- 业务表中需要有主键
Event Sourcing + 增量接入 + Lambda 架构
看完这几种接入方式,如果这个时候我们将增量接入配合上Event Sourcing。会发现这个方案真香:
针对缺点业务侧硬删除的数据无法感知到,要求业务侧只进行软删除。 ,由于Event Sourcing中,删除也是以事件的形式存储的,所以完美契合了。
针对缺点如果一条数据一天内变更了多次,只能获取到每天的最新状态。 ,由于所有的变更也都是以时间的形式存储的,所以没有变更会丢失。
同时,Lambda架构中想要的以原始形式存储的前提也被一并满足了。
联系推荐系统
推荐系统中,最典型的架构就是Netflix的离线、*线、在线三层架构。
其实其中的思想是类似的,用离线数据进行离线模型训练,用增量学*进行*线层处理,在线层 则处理一些预测、排序等实时性要求高的操作。
再看Lambda架构的更多相关文章
- web前端体系-了解前端,深入前端,架构前端,再看前端。大体系-知识-小细节
1.了解前端,深入前端,架构前端,再看前端.大体系-知识-小细节 个人认为:前端发展最终的导向是前端工程化,智能化,模块化,组件化,层次化. 2.面试第一关:理论知识. 2-1.http标准 2-2. ...
- Lambda架构
转载:https://blog.csdn.net/brucesea/article/details/45937875 1.Lambda架构背景介绍 Lambda架构是由Storm的作者Nathan M ...
- lambda架构简介
1.Lambda架构背景介绍 Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架.Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lamb ...
- 大数据处理中的Lambda架构和Kappa架构
首先我们来看一个典型的互联网大数据平台的架构,如下图所示: 在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使 ...
- 深入理解大数据架构之——Lambda架构
目录 传统系统的问题 Lambda架构简介 Lambda架构关键特性 数据系统的本质 Lambda的三层架构 Lambda架构组件选型 总结 原文链接:https://jiang-hao.com/ar ...
- 聊聊Lambda架构
定义 在数据分析场景中,我们可能会遇到这样的问题.例如,我们要做一个推荐系统,如果我们用批处理任务去做,一天或者一小时的推荐频次明显延迟太大.如果用流处理任务,虽然延迟的问题解决了,然而只用实时数据而 ...
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- Others-大数据平台Lambda架构浅析(全量计算+增量计算)
大数据平台Lambda架构浅析(全量计算+增量计算) 2016年12月23日 22:50:53 scuter_victor 阅读数:1642 标签: spark大数据lambda 更多 个人分类: 造 ...
- 带有Apache Spark的Lambda架构
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 目标 市场上的许多玩家已经建立了成功的MapReduce工作流程来每天处理以TB计的历史数据.但是谁愿意等待24小时才能获得最新的分析结果? ...
随机推荐
- BUUCTF(十一)[极客大挑战 2019]Knife
BUUCTF系列 想着应该不会这么简单吧... 结果就是这么简单ee 疯狂暗示... url:xxx/index.php 密码:Syc 连接成功... cd / ls cat flag
- node.js module初步理解-(转载)
在开发一个复杂的应用程序的时候,我们需要把各个功能拆分.封装到不同的文件,在需要的时候引用该文件.没人会写一个几万行代码的文件,这样在可读性.复用性和维护性上都很差,几乎所有的编程语言都有自己的模块组 ...
- 下面附上top和sar的使用方法,方便参考! "top"工具
下面附上top和sar的使用方法,方便参考! "top"工具 使用方式:top [-] [d delay] [q] [c] [S] [s] [i] [n] [b] 说明:即时显示 ...
- mysql基础之数据库备份和恢复的基础知识
备份数据的最终目的是为了在出现一些意外情况时,能够通过备份将数据还原,所以单单的备份数据往往是无法满足还原时的需求的,所以在备份数据库时,除了要备份数据本身,还要备份相关的数据库环境,如配置文件,定时 ...
- 聊聊 Spring 的 XML Schema 扩展机制的使用方式
前言 在当前Java生态,Spring算的上是最核心的框架,所有的开发组件想要得到大范围更便捷的使用,都要和Spring进行整合,比如我们熟知的Mybatis.Dubbo等,以及内部封装的各类组件包括 ...
- 在 Android 使用 QuickJS JavaScript 引擎教程
quickjs-android 是 QuickJS JavaScript 引擎的 Android 接口框架,整体基于面向对象设计,提供了自动GC功能,使用简单.armeabi-v7a 的大小仅 350 ...
- 在windows上 使用celery 报错
在windows上 使用celery 报错 在windows上 使用celery 报错 ValueError: not enough values to unpack (expected ...
- Deep Learning部署TVM Golang运行时Runtime
Deep Learning部署TVM Golang运行时Runtime 介绍 TVM是一个开放式深度学习编译器堆栈,用于编译从不同框架到CPU,GPU或专用加速器的各种深度学习模型.TVM支持来自Te ...
- VAE变分自编码器实现
变分自编码器(VAE)组合了神经网络和贝叶斯推理这两种最好的方法,是最酷的神经网络,已经成为无监督学习的流行方法之一. 变分自编码器是一个扭曲的自编码器.同自编码器的传统编码器和解码器网络一起,具有附 ...
- 服务化部署框架Paddle Serving
服务化部署框架Paddle Serving 概述 常见的深度学习模型开发流程需要经过问题定义.数据准备.特征提取.建模.训练过程,以及最后一个环--将训练出来的模型部署应用到实际业务中.如图1所示,当 ...