分库分表框架ShardingSphere入门学习1

背景
传统的将数据集中存储至单一数据节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足互联网的海量数据场景。
从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
从可用性的方面来讲,服务化的无状态型,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于 DBA 的运维压力就会增大。数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在 1TB 之内,是比较合理的范围。
在传统的关系型数据库无法满足互联网场景需要的情况下,将数据存储至原生支持分布式的 NoSQL 的尝试越来越多。 但 NoSQL 对 SQL 的不兼容性以及生态圈的不完善,使得它们在与关系型数据库的博弈中始终无法完成致命一击,而关系型数据库的地位却依然不可撼动。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
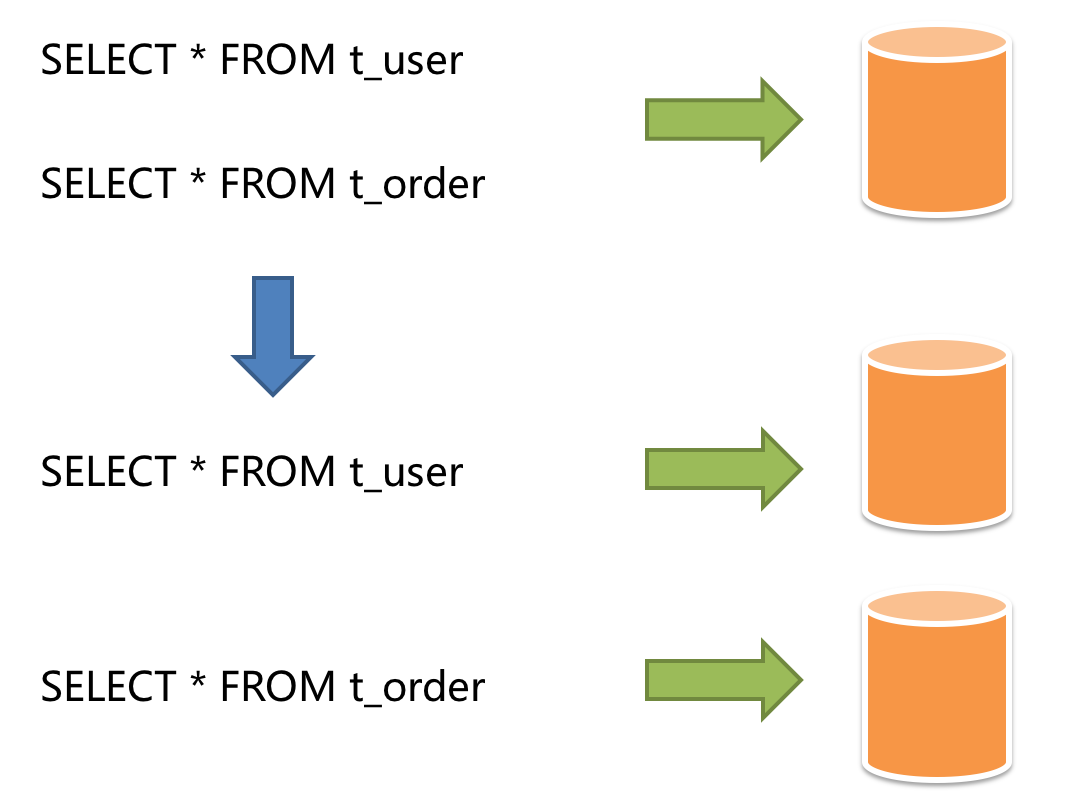
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
垂直分片
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
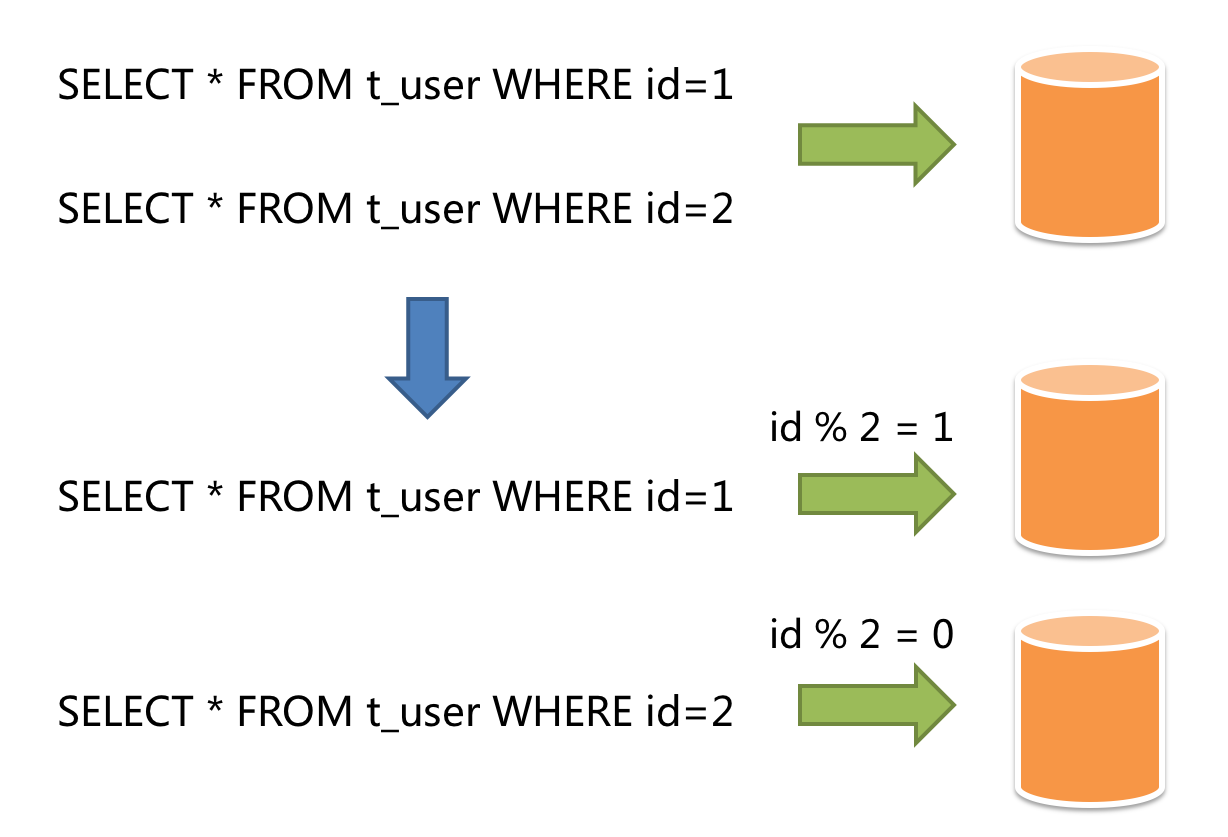
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
水平分片
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案。
挑战
虽然数据分片解决了性能、可用性以及单点备份恢复等问题,但分布式的架构在获得了收益的同时,也引入了新的问题。
面对如此散乱的分库分表之后的数据,应用开发工程师和数据库管理员对数据库的操作变得异常繁重就是其中的重要挑战之一。他们需要知道数据需要从哪个具体的数据库的分表中获取。
另一个挑战则是,能够正确的运行在单节点数据库中的 SQL,在分片之后的数据库中并不一定能够正确运行。例如,分表导致表名称的修改,或者分页、排序、聚合分组等操作的不正确处理。
跨库事务也是分布式的数据库集群要面对的棘手事情。 合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。 在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于 XA 的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。
目标
尽量透明化分库分表所带来的影响,让使用方尽量像使用一个数据库一样使用水平分片之后的数据库集群,是 Apache ShardingSphere 数据分片模块的主要设计目标。
Hello World Demo
以下为一个demo简单示例。我们将user水平切分为3张表,根据id hash存储到对应的表中。
准备环境
准备mysql。这里采用docker(https://github.com/Ryan-Miao/docker-china-source/tree/master/docker-mysql)创建一个mysql实例。
git clone https://github.com/Ryan-Miao/docker-china-source.git
cd docker-mysql
sudo docker-compose up
连接mysql并创建表:
show databases;
drop database if exists test0;
drop database if exists test1;
drop database if exists test2;
create database test0;
create database test1;
create database test2;
use test0;
drop table if exists user0;
drop table if exists user1;
drop table if exists user2;
create table user0(
id bigint(11) not null auto_increment primary key ,
name varchar(11) not null default '',
city_name varchar(11) not null default ''
);
create table user1 like user0;
create table user2 like user0;
use test1;
drop table if exists user0;
drop table if exists user1;
drop table if exists user2;
create table user0(
id bigint(11) not null auto_increment primary key ,
name varchar(11) not null default '',
city_name varchar(11) not null default ''
);
create table user1 like user0;
create table user2 like user0;
准备一个Springboot工程
这里简单创建一个Springboot项目。见https://github.com/Ryan-Miao/sharding-demo
简单引入web, mysql, mybatis-plus, sharding-sphere
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
启动类DemoApplication
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@MapperScan(basePackages = {
"com.example.demo.user.mapper"
})
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
创建entity对象User
/**
* @author Ryan Miao
* @since 2021-06-18
*/
@Data
@EqualsAndHashCode(callSuper = false)
@ApiModel(value = "User对象", description = "")
@TableName("user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String name;
private String cityName;
}
核心重点配置文件如下application.yml
spring:
shardingsphere:
datasource:
names: test0,test1
test0:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: "jdbc:mysql://localhost:3306/test0?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&serverTimezone=Asia/Shanghai"
username: root
password: 123456
test1:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: "jdbc:mysql://localhost:3306/test1?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&serverTimezone=Asia/Shanghai"
username: root
password: 123456
sharding:
# 默认分库策略 根据id分库, 这里暂且全部默认为test0
default-database-strategy:
inline:
sharding-column: id
algorithm-expression: test0
tables:
user:
# 表为db.table $->{0..2}表示0到2。
actualDataNodes: test$->{0..1}.user$->{0..2}
# 分表策略 根据id分表 3个表
table-strategy:
inline:
shardingColumn: id
algorithmExpression: user$->{id % 3}
# 分布式id生成方案: 雪花算法
keyGenerator:
type: SNOWFLAKE
column: id
props:
sql.show: true
mybatis-plus:
mapper-locations: "classpath*:/mapper/**/*.xml"
创建UserMapper
package com.example.demo.user.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.demo.user.entity.User;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* <p>
* Mapper 接口
* </p>
*
* @author Ryan
* @since 2021-06-18
*/
@Component
public interface UserMapper extends BaseMapper<User> {
}
编写一个Unit Test类, 我们制造一批数据:
package com.example.demo;
import com.example.demo.user.entity.User;
import com.example.demo.user.service.IUserService;
import org.junit.jupiter.api.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {DemoApplication.class})
class DemoApplicationTests {
@Autowired
private IUserService userService;
@Test
void insert() {
List<String> cityList = Arrays.asList("北京市", "深圳市", "重庆市", "上海市", "武汉市", "成都市", "广州市");
int initialCapacity = 10000;
Random random = new Random();
List<User> list = new ArrayList<>(initialCapacity);
for (int i = 0; i < initialCapacity; i++) {
User user = new User();
user.setName("a_" + i);
int index = random.nextInt(7);
user.setCityName(cityList.get(index));
list.add(user);
}
userService.saveBatch(list);
}
}
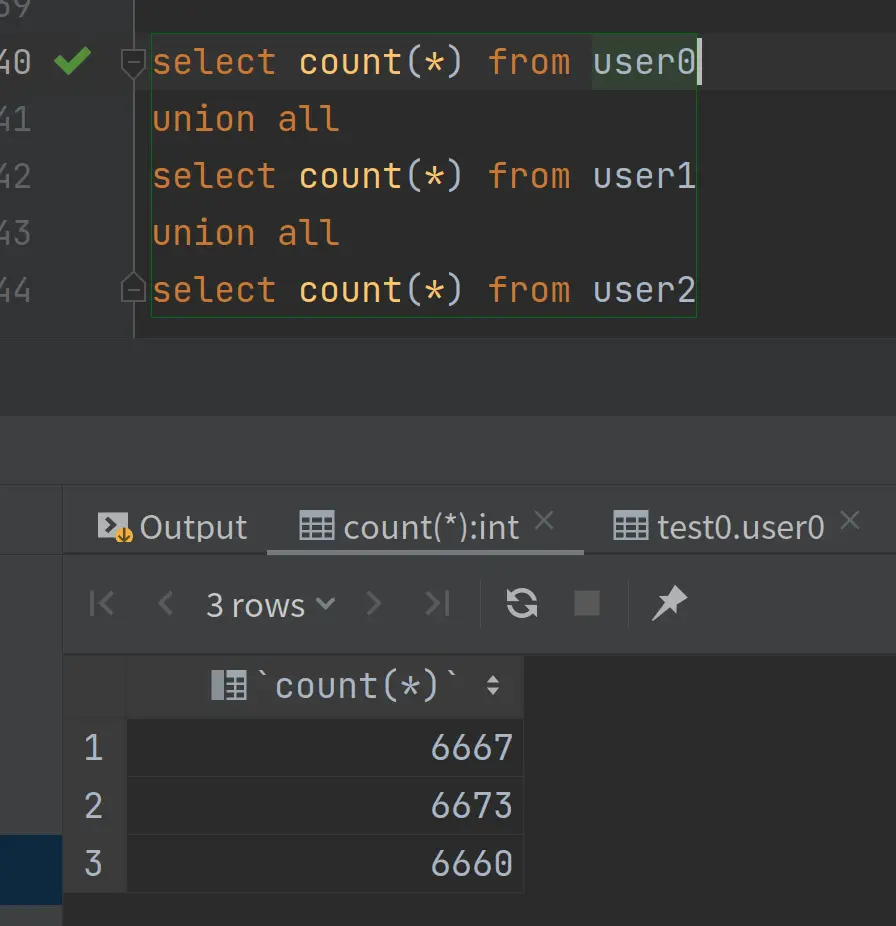
数据库查询:
接口查询:
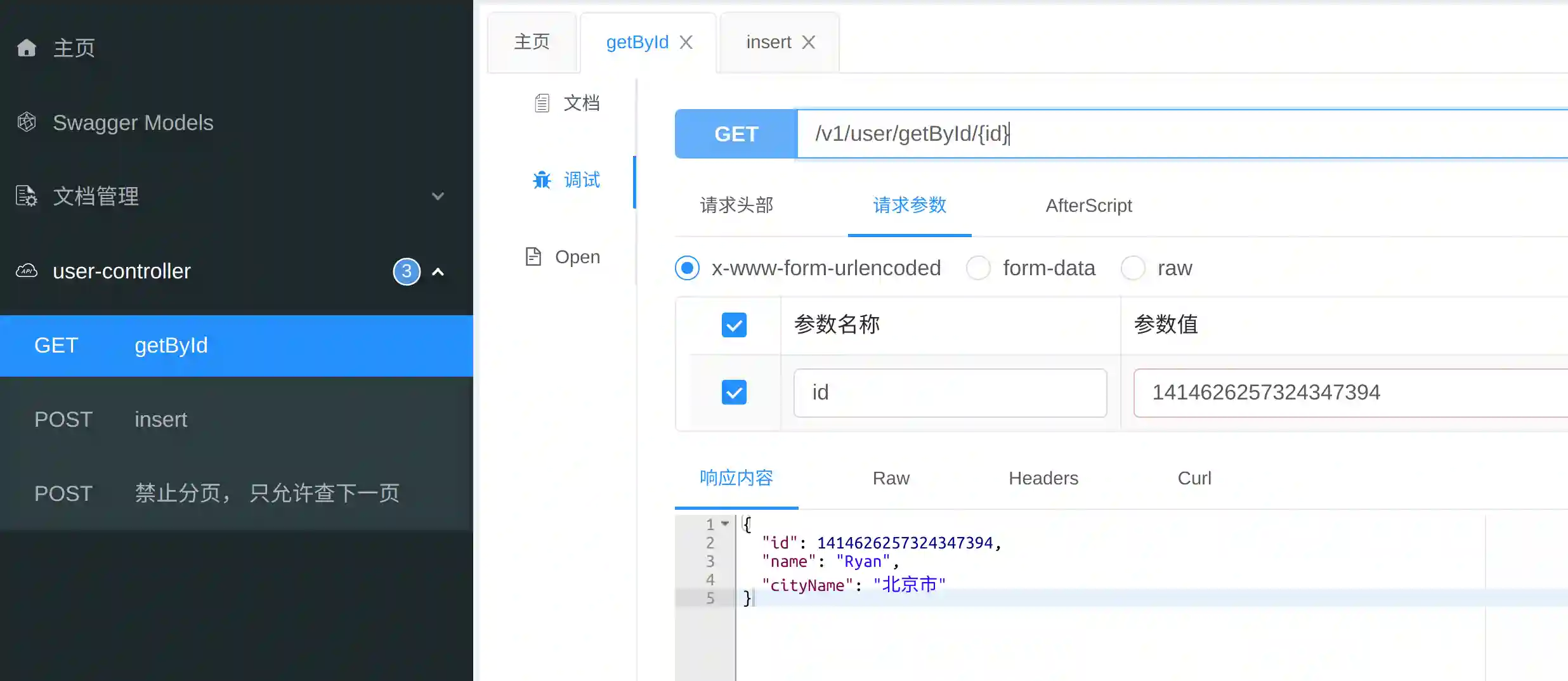
上述demo,基本实现了分表算法:按id hash。插入的时候自动生成分布式id,自动计算路由存储到对应的表。查询的时候自动计算路由,返回查询结果。
注意,上述demo采用inline的分表策略,目前只支持按id=来查询。复杂的查询应该走es查询id,再反查全部。
参考
分库分表框架ShardingSphere入门学习1的更多相关文章
- 分库分表利器——sharding-sphere
背景 得不到的东西让你彻夜难眠,没有尝试过的技术让我跃跃欲试. 本着杀鸡焉用牛刀的准则,我们倡导够用就行,不跟风,不盲从. 所以,结果就是我们一直没有真正使用分库分表.曾经好几次,感觉没有分库分表(起 ...
- 基于代理的数据库分库分表框架 Mycat实践
192.168.199.75 MySQL . MyCAT master 192.168.199.74 MySQL slave 192.168.199.76 MySQL standby master 如 ...
- 分库分表之ShardingSphere
目录 分库分表诞生的前景 分库分表的方式(垂直拆分,水平复制) 1.垂直拆分 1.1 垂直分库 1.2 垂直分表 2.水平拆分 2.1 水平分库 2.2 水平分表 分库分库中间件 ShardingSp ...
- 分库分表(2) --- ShardingSphere(理论)
ShardingSphere---理论 ShardingSphere在中小企业需要分库分表的时候用的会比较多,因为它维护成本低,不需要额外增派人手;而且目前社区也还一直在开发和维护,还算是比较活跃. ...
- 数据量大了一定要分表,分库分表组件Sharding-JDBC入门与项目实战
最近项目中不少表的数据量越来越大,并且导致了一些数据库的性能问题.因此想借助一些分库分表的中间件,实现自动化分库分表实现.调研下来,发现Sharding-JDBC目前成熟度最高并且应用最广的Java分 ...
- 数据库分库分表中间件ShardingSphere推荐
官网链接:http://shardingsphere.io/document/current/cn/overview/ 源起: 我今天首先去了解了一下国内好像是比较火的一个叫"MyCat&q ...
- 一文快速入门分库分表中间件 Sharding-JDBC (必修课)
书接上文 <一文快速入门分库分表(必修课)>,这篇拖了好长的时间,本来计划在一周前就该写完的,结果家庭内部突然人事调整,领导层进行权利交接,随之宣布我正式当爹,紧接着家庭地位滑落至第三名, ...
- 分库分表(3) ---SpringBoot + ShardingSphere 实现读写分离
分库分表(3)---ShardingSphere实现读写分离 有关ShardingSphere概念前面写了两篇博客: 1.分库分表(1) --- 理论 2. 分库分表(2) --- ShardingS ...
- 分库分表(4) ---SpringBoot + ShardingSphere 实现分表
分库分表(4)--- ShardingSphere实现分表 有关分库分表前面写了三篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3.分库 ...
随机推荐
- String 是一个奇怪的引用类型
开局两张图,内容全靠刷! 马甲哥看到这样的现象,一开始还是有点懵逼. 这个例子,string是纯粹的引用类型,但是在函数传值时类似于值传递: 我之前给前后示例的内存变化图吧: 根因就是大多数高级语言都 ...
- Step By Step(Lua表达式和语句)
Step By Step(Lua表达式和语句) 一.表达式: 1. 算术操作符: Lua支持常规算术操作符有:二元的"+"."-"."*& ...
- 使用Git下载指定分支命令为
使用Git下载指定分支命令为: git clone -b 分支名 仓库地址 例如: git clone -b dev https://github.com/xxx.git 将下载分支名为2D- ...
- 基于Jittor框架实现LSGAN图像生成对抗网络
基于Jittor框架实现LSGAN图像生成对抗网络 生成对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的 ...
- 用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割 Accelerating Medical Image Segmentation with NVIDIA Tensor ...
- 尚硅谷Java——宋红康笔记【day6-day10】
day6 一.数组的概述 1.数组的理解:数组(Array),是多个相同类型数据按一定顺序排列的集合,并使用一个名字命名,并通过编号的方式对这些数据进行统一管理. 2.数组相关的概念: 数组名 元素 ...
- Atcoder rc122-c Calculator 斐波那契
传送门 题解 先说结论: 任意正整数可以拆分成若干个斐波那契数 斐波那契数列: 1 1 2 3 5 8 13 21 34 例 17 = 13 + 3 + 1 看上去是对的,怎么证明呢? 首先假如每一个 ...
- Task05:SQL高级处理
5.1 窗口函数 5.1.1 窗口函数概念及基本的使用方法 窗口函数也称为OLAP函数.OLAP 是OnLine AnalyticalProcessing 的简称,意思是对数据库数据进行实时分析处理. ...
- anaconda安装VSCODE后,python报错
重新用anaconda时遇到了一点问题. 测试anaconda捆绑安装的VSCODE时写了一行print(1),然后报错. 后来发现用anaconda下载vscdoe时并不会给python一个路径,这 ...
- vue keep-alive从列表页进入详情页,再返回列表页时,还是之前滚动的位置
//router.js { path: '/oppo-music', component: () => import('@/views/OppoMusic.vue'), meta: { titl ...