AQS学习(一)自旋锁原理介绍(为什么AQS底层使用自旋锁队列?)
1.什么是自旋锁?
自旋锁作为锁的一种,和互斥锁一样也是为了在并发环境下保护共享资源的一种锁机制。在任意时刻,只有一个执行单元能够获得锁。
互斥锁通常利用操作系统提供的线程阻塞/唤醒机制实现,在争用锁失败时令线程陷入阻塞态而让出cpu,并在获取到锁时再将其唤醒。而自旋锁则是通过加锁程序中的无限循环,由当前尝试加锁的线程反复轮训当前锁的状态直到最终获取到锁。
互斥锁与自旋锁的优缺点
互斥锁的优点是当加锁失败时,线程会及时的让出cpu,从而提高cpu的利用率,但缺点是如果短时间内如果涉及到大量线程的加锁/解锁,则频繁的唤醒/阻塞会因为大量的线程上下文切换而降低系统的性能。因此互斥锁适用于线程会在较长时间内持有锁的场景。
与互斥锁相对的,自旋锁由于一直处于持续不断的轮训中,因此可以非常迅速的感知到锁状态的变化,在两个线程间能够瞬间完成锁的释放与获取。但如果需要争用锁的线程长时间都无法获取到锁,则会造成CPU长时间空转,造成CPU资源极大的浪费。因此自旋锁只适用于线程在加锁成功后会在极短的时间内释放锁的场景(需要保护的临界区非常小)。
自旋锁和互斥锁起到了一个互补的作用,在不同的需求场景下发挥自己的作用。
2.自旋锁的多种实现
本篇博客的重点是自旋锁的工作原理,由于存在许多种拥有不同特性的自旋锁,所以这里只挑选出几种具有代表性的自旋锁:原始版本自旋锁、票锁TicketLock、CLH锁和MCS锁,介绍这几种自选锁的实现原理和各有的优缺点。
本篇博客中的自旋锁是用java实现的。为了方便测试,先抽象并定义了一个通用的自旋锁接口SpinLock。
public interface SpinLock {
/**
* 加锁
* */
void lock();
/**
* 解锁
* */
void unlock();
}
2.1 原始自旋锁
原始版本的自旋锁非常基础,实现思路是所有需要加锁的线程通过cas重试的方式去争用锁,如果cas设置lockOwner成功则代表加锁成功;而解锁的时候则将lockOwner设置为null即可,这样后续需要争用锁的某个线程其lock中无限循环的cas操作就能成功获取到锁了。
原始自旋锁实现:
public class OriginalSpinLock implements SpinLock{
/**
* 标识当前自旋锁的持有线程
*
* AtomicReference类型配合cas
* */
private final AtomicReference<Thread> lockOwner = new AtomicReference<>();
@Override
public void lock() {
Thread currentThread = Thread.currentThread();
// cas争用锁
// 只有当加锁时之前lockOwner为null,才代表加锁成功,结束循环
// 否则说明加锁时已经有其它线程获得了锁,无限循环重试
while (!lockOwner.compareAndSet(null, currentThread)) {
}
}
@Override
public void unlock() {
Thread currentThread = Thread.currentThread();
// cas释放锁
// 只有之前加锁成功的线程才能够将其重新cas的设置为null
lockOwner.compareAndSet(currentThread, null);
}
}
原始自旋锁的优点:
1.简单:作为基础版本的自旋锁,无论是性能还是功能上都是最差的,其唯一的优点就是简单了。
原始自旋锁的缺点:
1.非公平:相比其它类型的自旋锁,原始自旋锁的一大缺点是非公平。由于所有的线程都是监听lockOwner这一引用,因此后加锁的线程是很可能比在这之前已经在争用锁的线程先加锁成功的,在大量线程参与加锁的极端情况下会导致先加锁的线程一直无法加锁成功。
2.过多的内存竞争:由于所有的线程都是监听、访问同一内存地址的数据,且AtomicReference中使用volatile关键字修饰value来保证线程间可见性。在多核cpu的架构下,操作系统和硬件底层会使用诸如锁内存总线或者使用缓存一致性协议同步等机制来实现不同线程间的内存可见性,这会在一定程度上影响到系统的内存访问性能。
2.2 票锁(TicketLock)
为了解决原始自旋锁非公平的缺点,在原始自旋锁基础上改进的票锁TicketLock被发明了出来。
票锁在加锁时当前线程会预先原子性的拿到一个逐步递增且唯一的排队服务号,只有当前票锁的服务票号和自己拿到的排队服务号一致时才认为加锁成功。而在解锁时则将当前票锁的服务票号递增,得以让下一个加锁的线程获得锁。
由于服务票号是逐步递增且唯一的,TicketLock中先来申请加锁的线程会拿到更小更靠前的服务号,也能较之后申请加锁的线程更早的获得到锁,保证了公平性。
票锁实现:
public class TicketSpinLock implements SpinLock{
/**
* 排队号发号器
* */
private AtomicInteger ticketNum = new AtomicInteger();
/**
* 当前服务号
* */
private AtomicInteger currentServerNum = new AtomicInteger();
public void lock() {
// 首先获得一个唯一的排队号
int myTicketNum = ticketNum.getAndIncrement();
// 当前服务号与自己持有的服务号不匹配
// 一直无限轮训,直到排队号与自己的服务号一致(等待排队排到自己)
while (currentServerNum.get() != myTicketNum) {
}
}
public void unlock() {
// 释放锁时,代表当前服务已经结束
// 当前服务号自增,使得拿到下一个服务号的线程能够获得锁
currentServerNum.incrementAndGet();
}
}
票锁的优点:
1.公平:相比于原始自旋锁,票锁是一个先来先服务的公平锁,避免了某些线程被其他线程抢先而长时间无法获取锁的问题。
票锁的缺点:
1.过多的内存竞争:和原始自旋锁一样,票锁中每一个线程都会不断的访问当前服务票号(currentServerNum)这一volatile关键字修饰的变量值,在多核CPU架构下性能会受到一定的影响。
2.3 CLH锁
CLH锁是由Craig, Landin, and Hagersten三位计算机科学家共同发明的,这也是CLH锁名字的由来(取名字首字母)。
CLH锁被发明出来的主要原因是为了解决多核cpu体系中全部加锁线程都访问同一内存地址而出现过多内存竞争的问题。CLH锁和票锁一样是先来先服务的公平锁,但CLH锁引入了线程节点的概念,需要加锁的线程不断的从队尾加入队列,构造出了一个逻辑上的单向链表队列;获取锁的顺序也是从队列头部开始,早加入队列的线程便能更早的获得到CLH锁,实现先来先服务的公平性。
CLH锁结构图: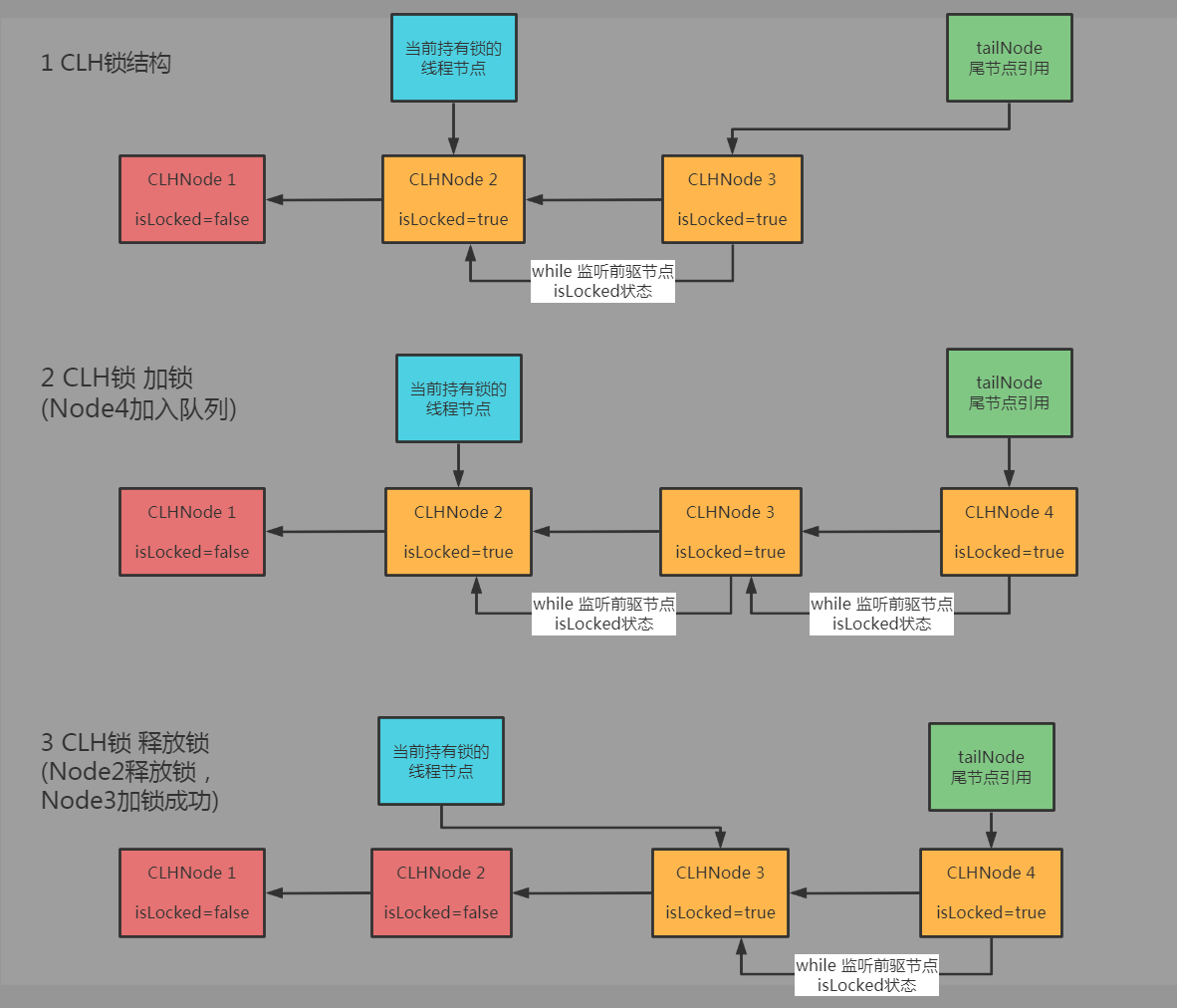
CLH锁中加锁的线程不再是统一的监听同一个标识锁状态的内存地址,而是只监听队列中当前线程节点其前驱线程节点的锁状态。如此一来,便分散了不同线程加锁时所要访问的内存变量地址,相比起前面介绍的原始自旋锁和票锁减少了大量的内存访问竞争,减少了底层为了实现线程间内存数据可见性同步时的性能开销。
加锁时,先cas的入队获取前驱节点后,便不断的循环监听前驱节点锁的状态,当发现前驱节点释放了锁时,当前节点便获得了锁。
而解锁时则很简单,将当前线程自己的锁状态更改为已释放即可。标识为已释放时,存在的后继加锁节点便能感知到这一变化,从而获得锁。
CLH锁实现:
/**
* 原始版CLH锁(无显式prev前驱节点引用,无法支持取消加锁等场景)
*/
public class CLHLockV1 implements SpinLock{
private static class CLHNode {
/**
* 获取到锁的线程其后继争用锁的节点会持续不断的查询isLocked的值
* 使用volatile修饰,使得释放锁修改isLocked时不会出现线程间变量不可见的问题
* */
private volatile boolean isLocked;
} private final AtomicReference<CLHNode> tailNode;
private final ThreadLocal<CLHNode> curNode; public CLHLockV1() {
// 初始化时尾结点指向一个空的CLH节点
tailNode = new AtomicReference<>(new CLHNode());
// 设置threadLocal的初始化方法
curNode = ThreadLocal.withInitial(CLHNode::new);
} @Override
public void lock() {
CLHNode currNode = curNode.get();
currNode.isLocked = true; // cas的设置当前节点为tail尾节点,并且获取到设置前的老tail节点
// 老的tail节点是当前加锁节点的前驱节点(隐式前驱节点),当前节点通过监听其isLocked状态来判断其是否已经解锁
CLHNode preNode = tailNode.getAndSet(currNode);
while (preNode.isLocked) {
// 无限循环,等待获得锁
} // 循环结束,说明其前驱已经释放了锁,当前线程加锁成功
} @Override
public void unlock() {
CLHNode node = curNode.get();
// 清除当前threadLocal中的节点,避免再次Lock加锁时获取到之前的节点
curNode.remove();
node.isLocked = false;
}
}
CLH锁的优点:
1.公平:FIFO的线程队列保证了先加锁的线程能更早一步的获得锁,不会被后加锁的线程抢先,保证了公平性。
2.分散了内存竞争:由于每个需要加锁的线程监听的是其前驱节点的锁状态,所以不同线程监听的是不同的内存数据,避免了所有线程都监听同一内存数据的性能问题。
CLH锁的缺点:
1.不支持取消加锁的场景:当前示例中的CLH锁是基础版的,没有显式的链接前驱节点,无法支持超时等取消锁的场景。
2.4 MCS锁
MCS锁也是得名于其发明者的名字,John Mellor-Crummey和Michael Scott。
MCS锁的实现思路和CLH锁类似,也是通过构建一个单向链表来分摊内存竞争的并实现先来先服务的公平性。
MCS锁结构图:

MCS锁实现:
public class MCSLock implements SpinLock{
private static class MCSNode {
/**
* 获取到锁的线程其后继争用锁的节点会持续不断的查询isLocked的值
* 使用volatile修饰,使得释放锁修改isLocked时不会出现线程间变量不可见的问题
* */
private volatile boolean isLocked;
private MCSNode next;
}
private final AtomicReference<MCSNode> tailNode;
private final ThreadLocal<MCSNode> curNode;
public MCSLock() {
// MCS锁的tailNode初始化时为空,代表初始化时没有任何线程持有锁
tailNode = new AtomicReference<>();
// 设置threadLocal的初始化方法
curNode = ThreadLocal.withInitial(MCSNode::new);
}
@Override
public void lock() {
MCSNode currNode = curNode.get();
currNode.isLocked = true;
MCSNode preNode = tailNode.getAndSet(currNode);
if(preNode == null){
// 当前线程加锁之前并不存在tail节点,则代表当前线程为最新的节点,直接认为是加锁成功
currNode.isLocked = false;
}else{
// 之前的节点存在,令前驱节点next指向当前节点,以便后续前驱节点释放锁时能够找到currNode
// 前驱节点释放锁时,会主动的更新currNode.isLocked(令currNode.isLocked=false)
preNode.next = currNode;
while (currNode.isLocked) {
// 自旋等待当前节点自己的isLocked变为false
}
}
}
@Override
public void unlock() {
MCSNode currNode = curNode.get();
if (currNode == null || currNode.isLocked) {
// 前置防御性校验,如果当前线程节点为空或者当前线程自身没有成功获得锁,则直接返回,加锁失败
return;
}
if(currNode.next == null){
// 当前节点的next为空,说明其是MCS的最后一个节点
// 以cas的形式将tailNode设置为null(防止此时有线程并发加锁 => lock方法中的tailNode.getAndSet())
boolean casSuccess = tailNode.compareAndSet(currNode,null);
if(casSuccess){
// 如果cas设置tailNode成功为null成功,则释放锁结束
return;
}else{
// 如果cas设置失败,说明此时又有了新的线程节点入队了
while (currNode.next == null) {
// 自旋等待,并发lock的线程执行(preNode.next = currNode),设置currNode的next引用
}
}
}
// 如果currNode.next存在,按照约定则释放锁时需要将其next的isLocked修改,令next节点线程结束自旋从而获得锁
currNode.next.isLocked = false;
// 方便GC,断开next引用
currNode.next = null;
}
}
MCS锁的优点:
1.公平:FIFO的线程队列保证了先加锁的线程能更早一步的获得锁,不会被后加锁的线程抢先,保证了公平性。
2.分散了内存竞争:由于每个需要加锁的线程监听的是其前驱节点的锁状态,所以不同线程监听的是不同的内存数据,避免了所有线程都监听同一内存数据的性能问题。
3.NUMA架构下性能更好:NUMA架构下MCS锁的性能略优于CLH锁。
MCS锁的缺点:
1..不支持取消加锁的场景:和基础版的CLH锁一样,无法支持超时等取消锁的场景。
3.为什么CLH锁在NUMA的CPU架构下性能会略低于MCS锁?
从上述CLH锁和MCS锁的实现中可以看到,MCS锁的链表队列方向和CLH锁是相反的,CLH锁是一个从尾节点出发通过prev关联前驱节点的队列,后继节点通过无限循环监听并感知其前驱节点的锁状态变化;而MCS锁是一个从头节点出发通过next关联后继节点的单向队列,在前驱节点释放锁时通过修改后继节点的锁状态来通知后继节点。
两种锁的实现方式看起来大同小异,但细小的区别却使得MCS锁在NUMA架构下的性能要高于CLH锁。
3.1 什么是NUMA架构?
NUMA架构是多核CPU体系架构的一种,与之相对的则是SMP架构。
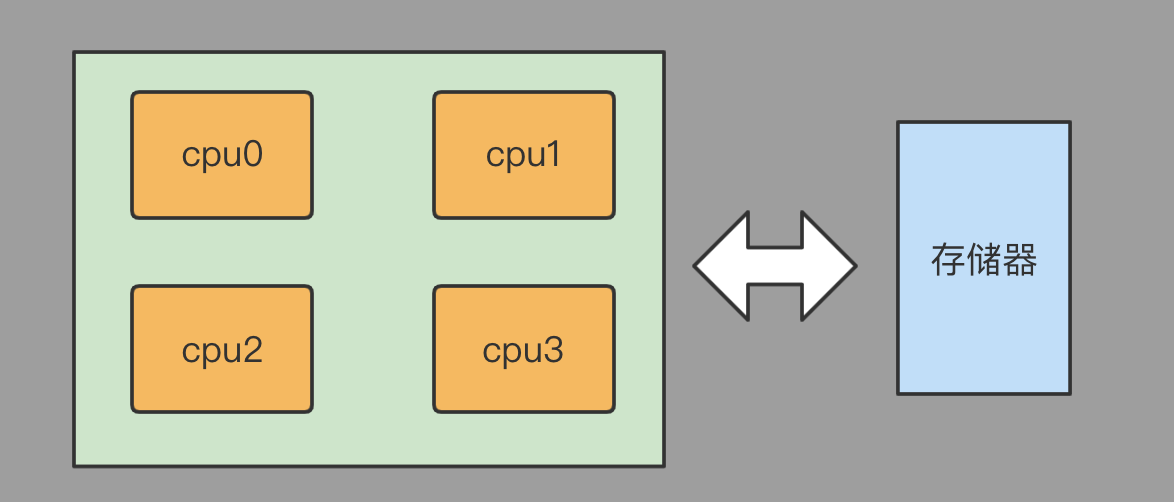
SMP(Sysmmetric Multi-Processor System,对称多处理器系统)架构顾名思义,多个cpu核心通过统一的方式共享访问同一个集中式的存储器,每个cpu并无主从之分被分配同样大小的时间片平均的访问存储器。
SMP架构比起NUMA架构简单,早期的多核CPU都是采用这种架构。但SMP架构受限于存储器总线的带宽,核心数过多容易导致部分核心无法得到足够的访问时间片而陷入饥饿,因此SMP架构其所能支持的CPU核心数受到了很大的限制。
SMP结构示意图:
为了解决SMP架构下存储器带宽有限的问题,计算机科学家提出了一种新的CPU体系架构即NUMA架构(Non-Uniform Memory Access,非一致性存储器访问)。与SMP架构不同,NUMA架构下的存储器是分布式的,其将cpu核心和存储器平均分割为了多个NUMA节点(NUMA Node),不同节点之间通过QPI总线等机制进行互联。
NUMA架构下任意的cpu核心依然可以访问全量的存储器,cpu核心如果访问的是位于同一节点内的存储器会很快,但访问其它NUMA节点内的存储器则由于需要通过QPI总线访问而会有一定的延迟,这也是其被称为非一致存储器访问的原因。
NUMA架构下cpu核心访问本地节点内存快,访问远程节点内存慢。理想情况下,每个节点如果都只访问本地节点的内存,那么理论上其数据吞吐量将会是SMP架构的N倍(N为节点数)。
NUMA结构示意图: 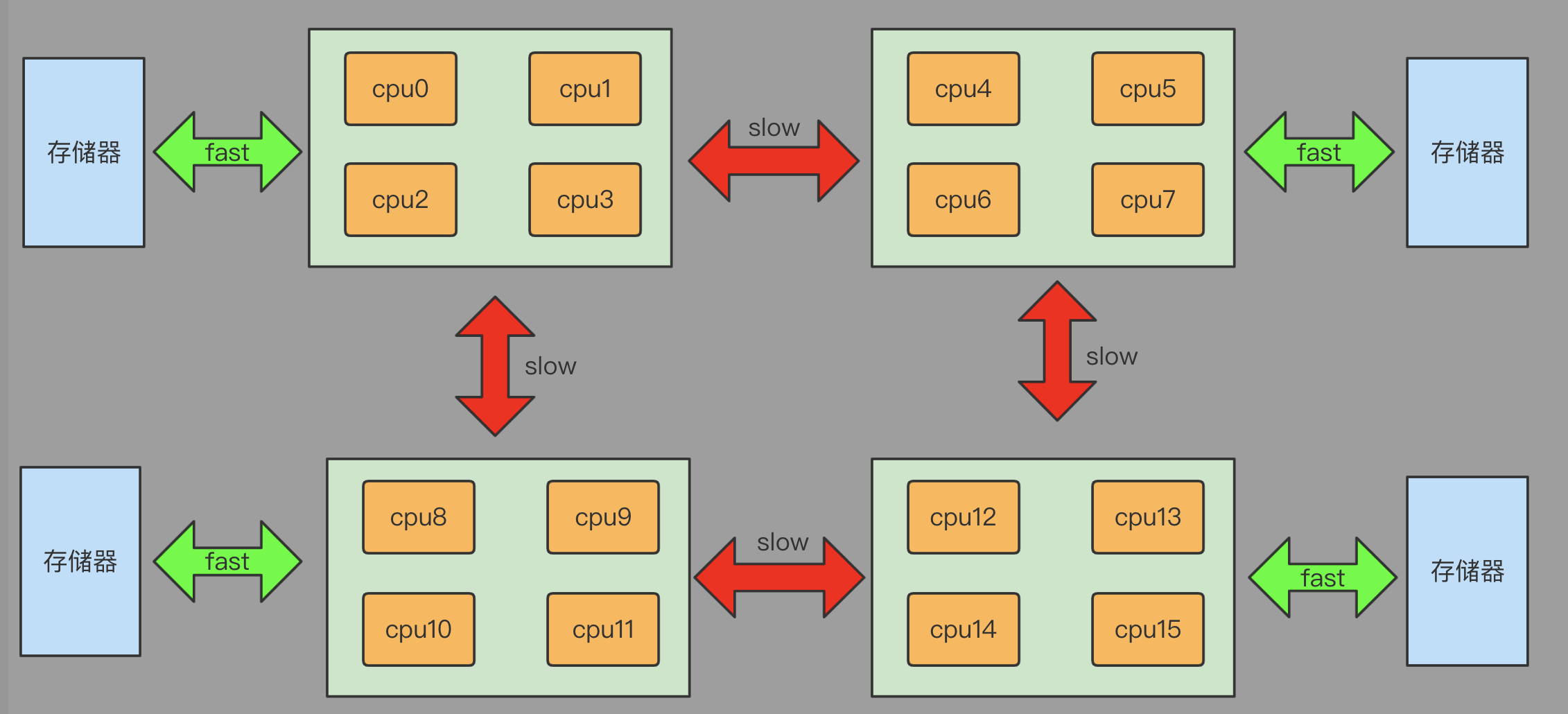
3.2 CLH锁在NUMA架构下低于MCS锁的原因
在简单了解了NUMA架构后,下面开始说明CLH锁在NUMA架构下低于MCS锁的原因。
由于NUMA架构下访问本地节点内存和远程节点内存性能存在差异,操作系统在为线程分配内存时需要尽可能的让线程访问的内存与执行线程的cpu分配到同一个NUMA节点中,一个简单的策略便是将对应线程所申请的内存分配到对应线程cpu所在的同一NUMA节点中。(实际的NUMA结构下内存分配与平衡机制很复杂,因为内存分配后如果线程发生上下文切换后可能就在其它节点的cpu核心上了,这里举的例子极大的简化了复杂度)
观察CLH锁和MCS锁在NUMA架构下的行为:CLH锁和MCS锁为线程节点分配的内存通常都会分配到与对应线程执行cpu核心绑定的NUMA节点的存储器中,而不同线程对应的cpu则可能位于不同的NUMA节点中。CLH锁会无限轮训前驱节点的isLocked状态,这一操作在前驱节点线程与当前线程不位于同一NUMA节点时,会不断的进行远程节点访问,性能较低;而MCS锁中,当前线程则是无限轮训自己线程节点的isLocked,这种情况下都是本地NUMA节点内存的访问。
当前驱节点线程与当前节点线程不在同一NUMA节点内时,CLH锁在lock时会进行N次远程节点访问,在unLock时进行一次本地节点访问;而MCS锁则在lock时会进行N次本地节点访问,并在unLock时进行一次远程节点访问。
综上所述,由于NUMA节点下本地节点访问性能是优于远程节点访问的,因此MCS锁的性能在NUMA架构下会略优于CLH锁。
4.为什么AQS框架底层使用CLH队列结构作为基础?
这个问题可以被分解为两个更细节的问题,即为什么AQS底层使用自旋锁队列作为基础以及为什么在自旋锁队列中选择了CLH锁队列而不是MCS锁队列作为基础?
4.1 为什么AQS底层使用自旋锁队列作为基础?
AQS是jdk的juc并发工具包下提供的抽象同步器框架,可作为可重入锁、信号量等各类型同步器的实现基础。
由于AQS中需要让大量并发争用锁的线程频繁的被阻塞和唤醒,出于性能的考虑,为避免过多的线程上下文切换,AQS本身没有再利用操作系统底层提供的线程阻塞/唤醒机制通过互斥锁来保证同步队列的并发安全,而是使用基于CAS的乐观重试机制来构造一个无锁,并发安全的同步队列。
AQS论文原文:These days, there is little controversy that the most appropriate choices for synchronization queues are non-blocking data structures that do not themselves need to be constructed using lower-level locks.(如今,构造同步队列最合适的选择是使用自身构造不依赖底层锁的无锁数据结构,这在业界是几乎没有争议的)
从AQS的作者Doug Lea的论文中可以看到,AQS作为一个用于控制线程并发的底层框架,为避免互斥锁同步机制下过多的线程上下文切换而影响性能,所以才使用不需要阻塞线程的自旋锁队列作为基础来实现线程安全的。
4.2 为什么AQS使用CLH锁队列而不是MCS锁队列作为基础呢?
AQS作为一个通用的同步器框架,是需要支持超时、中断等取消加锁的,而前面提到基础版的CLH锁和MCS锁都存在一个缺陷,即无法很好的支持超时、中断等取消加锁的场景。
引入了显式前驱节点引用的CLH锁比起MCS锁可以更加简单的实现超时、中断等加锁过程中临时退出加锁的场景。而由于AQS中的线程在征用锁失败时不会占用CPU一直自旋等待,而是被设置为阻塞态让出CPU(LockSupport.park),因此MCS锁在NUMA架构下性能略高的优点也就不是那么重要了。
AQS论文原文:Historically, CLH locks have been used only in spinlocks. However, they appeared more amenable than MCS for use in the synchronizer framework because they are more easily adapted to handle cancellation and timeouts, so were chosen as a basis. The resulting design is far enough removed from the original CLH structure to require explanation.(一直以来,CLH锁仅被用于自旋锁。然而,在这个框架中,CLH锁显然比MCS锁更合适。因为CLH锁可以更容易地去实现“取消”和“超时”功能,因此我们选择了CLH锁作为实现的基础。但是最终的设计已经与原来的CLH锁结构有较大的出入)
引入显示前驱节点的CLH锁实现:
public class CLHLockV2 implements SpinLock{
private static class CLHNode {
private volatile CLHNode prev;
private volatile boolean isLocked;
public CLHNode() {
}
public CLHNode(CLHNode prev, boolean isLocked) {
this.prev = prev;
this.isLocked = isLocked;
}
}
private static final CLHNode DUMMY_NODE = new CLHNode(null,false);
private final CLHNode head;
private final AtomicReference<CLHNode> tail;
private final ThreadLocal<CLHNode> curNode;
public CLHLockV2() {
head = DUMMY_NODE;
tail = new AtomicReference<>(DUMMY_NODE);
curNode = ThreadLocal.withInitial(CLHNode::new);
}
@Override
public void lock() {
CLHNode currentNode = curNode.get();
currentNode.isLocked = true;
// cas的设置为当前tail为新的tail节点
currentNode.prev = tail.getAndSet(currentNode);
while(true){
while(currentNode.prev.isLocked){
}
// 内层while循环结束,说明前驱节点已经释放了锁
CLHNode prevNode = currentNode.prev;
if(prevNode == head){
// 如果前驱节点为head(Dummy节点)
return;
}else{
currentNode.prev = prevNode.prev;
}
}
}
@Override
public void unlock() {
CLHNode currentNode = curNode.get();
curNode.remove();
currentNode.isLocked = false;
}
}
熟悉AQS实现的读者可以看到,引入了显式前驱节点引用的CLH锁改良版和AQS的同步队列实现已经有了几分相似。不过由于AQS中加锁失败的节点不是通过自旋来感知能否获取到锁,而是依赖其同步队列的前驱节点来唤醒它,因此AQS和用于自旋锁的CLH锁在最终实现上存在一定差异。(The wait queue is a variant of a "CLH" (Craig, Landin, and Hagersten) lock queue. CLH locks are normally used for spinlocks)。
5.总结
作为AQS框架学习的第一篇博客,之所以决定从自旋锁的工作原理开始展开,是因为AQS框架的底层是CLH锁队列的一个变种。如果能理解CLH锁队列的工作模式,可以为AQS的学习提供很大的帮助。由于AQS需要能够为互斥锁、共享锁和条件变量等多种不同类型的同步器提供基础支持,代码量较多;且其基于乐观锁重试的特点,使得代码中存在着不少处理临界区无锁并发的晦涩逻辑,源码读起来比较吃力。因此在学习的过程中转换思维,尝试着站在AQS设计者的角度来理解其工作原理,参考着AQS的实现思路自己动手写一个简易版的AQS,在这个过程中将自己的实现和AQS的源码进行比较,结合网上关于AQS原理解析的博客,反复琢磨和体会作者Doug Lea实现的巧妙之处。
自己实现的AQS会按照顺序通过支持互斥锁、支持共享锁、支持取消加锁(中断、超时退出)和支持条件变量这几个功能模块为基础逐步完成,后续会以博客的形式分享出来。
希望这篇博客能帮助到对自旋锁、AQS工作原理感兴趣的人,如有错误,还请多多指教。
参考书籍:
《多处理器编程的艺术》
参考博客:
https://www.cnblogs.com/dennyzhangdd/p/7218510.htmlAQS框架论文翻译
https://www.cnblogs.com/stevenczp/p/7136416.html多种自旋锁实现
https://felord.blog.csdn.net/article/details/108313803 CLH锁的实现
https://javazhiyin.blog.csdn.net/article/details/108332477 CLH锁详解
https://www.cnblogs.com/xingzheanan/p/10547387.html NUMA架构介绍
AQS学习(一)自旋锁原理介绍(为什么AQS底层使用自旋锁队列?)的更多相关文章
- AQS学习(二) AQS互斥模式与ReenterLock可重入锁原理解析
1. MyAQS介绍 在这个系列博客中,我们会参考着jdk的AbstractQueuedLongSynchronizer,从零开始自己动手实现一个AQS(MyAQS).通过模仿,自己造轮子来学习 ...
- Mysql锁机制介绍
Mysql锁机制介绍 一.概况MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制.比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking ...
- 深入介绍Java中的锁[原理、锁优化、CAS、AQS]
1.为什么要用锁? 锁-是为了解决并发操作引起的脏读.数据不一致的问题. 2.锁实现的基本原理 2.1.volatile Java编程语言允许线程访问共享变量, 为了确保共享变量能被准确和一致地更新, ...
- 面经手册 · 第17篇《码农会锁,ReentrantLock之AQS原理分析和实践使用》
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 如果你相信你做什么都能成,你会自信的多! 千万不要总自我否定,尤其是职场的打工人.如 ...
- 关于分布式锁原理的一些学习与思考-redis分布式锁,zookeeper分布式锁
首先分布式锁和我们平常讲到的锁原理基本一样,目的就是确保,在多个线程并发时,只有一个线程在同一刻操作这个业务或者说方法.变量. 在一个进程中,也就是一个jvm 或者说应用中,我们很容易去处理控制,在j ...
- Java 中15种锁的介绍:公平锁,可重入锁,独享锁,互斥锁,乐观锁,分段锁,自旋锁等等
Java 中15种锁的介绍 Java 中15种锁的介绍:公平锁,可重入锁,独享锁,互斥锁,乐观锁,分段锁,自旋锁等等,在读很多并发文章中,会提及各种各样锁如公平锁,乐观锁等等,这篇文章介绍各种锁的分类 ...
- 图解AQS原理之ReentrantLock详解-非公平锁
概述 并发编程中,ReentrantLock的使用是比较多的,包括之前讲的LinkedBlockingQueue和ArrayBlockQueue的内部都是使用的ReentrantLock,谈到它又不能 ...
- Java中的锁[原理、锁优化、CAS、AQS]
1.为什么要用锁? 锁-是为了解决并发操作引起的脏读.数据不一致的问题. 2.锁实现的基本原理 2.1.volatile Java编程语言允许线程访问共享变量, 为了确保共享变量能被准确和一致地更新, ...
- Java中的锁原理、锁优化、CAS、AQS详解!
阅读本文大概需要 2.8 分钟. 来源:jianshu.com/p/e674ee68fd3f 一.为什么要用锁? 锁-是为了解决并发操作引起的脏读.数据不一致的问题. 二.锁实现的基本原理 2.1.v ...
随机推荐
- Vue3全家桶升级指南二ref、toRef、toRefs的区别
ref是对原始数据的拷贝,当修改ref数据时,模板中的视图会发生改变,但是原始数据并不会改变. toRef是对原始数据的引用,修改toRef数据时,原始数据也会发生改变,但是视图并不会更新. 在vue ...
- layui checkbox 样式
layui checkbox扩展插件: 一.新建 checkbox.css 样式文件 .checkBox .block{float:left; margin:5px;padding:6px 6p ...
- 柔性数组(Redis源码学习)
柔性数组(Redis源码学习) 1. 问题背景 在阅读Redis源码中的字符串有如下结构,在sizeof(struct sdshdr)得到结果为8,在后续内存申请和计算中也用到.其实在工作中有遇到过这 ...
- 小程序开发 access_token 统一管理
TOKEN 定时刷新器 一.背景 对于使用过公众平台的API功能的开发者来说,access_token绝对不会陌生,它就像一个打开家门的钥匙,只要拿着它,就能使用公众平台绝大部分的API功能.因此,对 ...
- DawgCTF wp(re和crypto)
简单写写思路,想看详解的..我脚本有些丢失了..师傅请移步. 挂了个vpn,算正式打这种国际赛,全是英文.上去打了两天,昨晚晚上划水了一晚上补作业...,re那时候写出来三道,Potentially ...
- 虚拟机centos7环境搭建,系统分区,静态IP配置
文章目录 1.虚拟机安装centos7 2.系统分区 3.配置静态IP centos7下载地址 http://mirrors.aliyun.com/centos/7/isos/x86_64/ Cent ...
- ESP32智能配网笔记
基于ESP-IDF4.1 #include <string.h> #include <stdlib.h> #include "freertos/FreeRTOS.h& ...
- 传统.NET 4.x应用容器化体验(1)
我们都知道.NET Core应用可以跑在Docker上,那.NET Framework 4.x应用呢?借助阿里云ECS主机(Windows Server 2019 with Container版本), ...
- CTF-safer-than-rot13-writeup
safer-than-rot13 题目信息 附件: cry100 XMVZGC RGC AMG RVMG HGFGMQYCD VT VWM BYNO, NSVWDS NSGO RAO XG UWFN ...
- python之数据驱动Txt操作
一.新建数据Mail163.txt文本 二.Txt_Mail163.py脚本如下: import unittestfrom selenium import webdriverfrom selenium ...