Pytorch系列:(五)CNN
卷积
Conv2d
2D卷积函数和参数如下
nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros'
)
参数说明:
in_channels: 输入通道数,RGB图片一般是3
out_channels: 输出通道,也可以理解为kernel的数量
kernel_size:kernel的和宽设置
kernel 输出尺寸计算:
\(\lfloor(n_h -k_h+p_h)/s_h+1\rfloor *\lfloor(n_w -k_w+p_w)/s_w+1\rfloor\)
stride:kernel移动的步伐
padding:在四周加入padding的数量,默认补0
dilation:
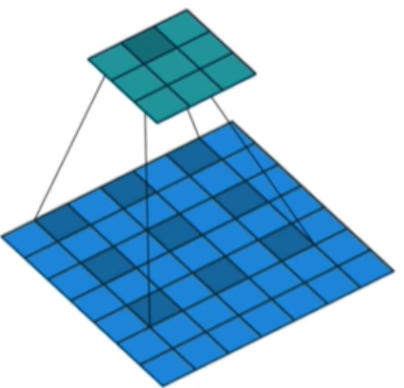
空洞就是计算的时候,对输入层进行挖空操作,如下图所示(图片来源于网络)
group:
分组计算,输出的feature map数量还是一样,只不过,每一个输出feature map 并不是用所有的输入feature map 计算的,而是分组计算,这样可以并行化并且减少计算成本
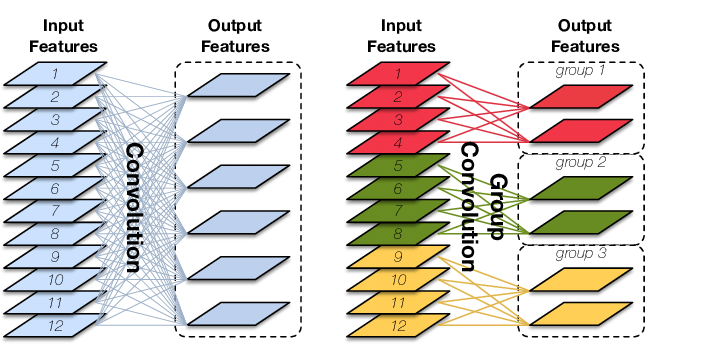
假设输入为12个feature map , 输出为6个通道,常规卷积Conv参数\(6*12*k^2\),但是假设goup=3,那么参数为 3个 \(2*4*k^2\),这是因为计算的时候,输入的feature map 和 计算的kernel 都要分成3组(如下图所示,图片来源网络)。

bias: 如果bias=True,添加偏置
Conv1d
一维卷积的特点是,卷积核有一个维度和特征的维度是保持一致的,卷积核的另外一个维度是作用在sequenc length上面。
Conv1d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True
)
in_channels: – 输入信号的通道。即为词向量的维度。2维RGB图像卷积中,为3, 一般用在序列模型中,例如一句话中的单词表征为300,那么输入就设置为300
out_channels: 输出多少个channel
kernel_size:设置卷积尺寸,其中一个维度为in_channels,所以实际上卷积大小为kernel_size*in_channels
stride:卷积步长,作用在sequence len上面
padding:在序列两边补0
dilation:卷积核元素之间的间距,同上面conv2d
groups: 同上面conv2d
bias: 如果bias=True,添加偏置
尺寸计算方法
假设输入尺寸为 (batch, sequence len, feature_len) 需要将维度转换为( batch , feature_len, sequence len),卷积核的尺寸为(feature_len, kernel_size) , 输出为( batch, kernel_size, Lout) ,其中Lout的计算方法如下:
\(L_{out} = \lfloor(feature\_len -k_h+p_h)/s_h+1\rfloor\)
转置卷积
反卷积(转置卷积)和正常卷积相反,具有尺寸扩张作用,也可以理解为带参数学习的上采样功能,主要可以用到GAN中的。
转置卷积的操作如下图所示:
相当于将被卷积的2*2 feature map进行padding,之后再做卷积操作。
设卷积核大小为k*k,输入为方形矩阵
对输入进行四边补零,单边补零的数量为k-1
将卷积核旋转180°,在新的输入上进行直接卷积 (上下翻转,左右翻转)
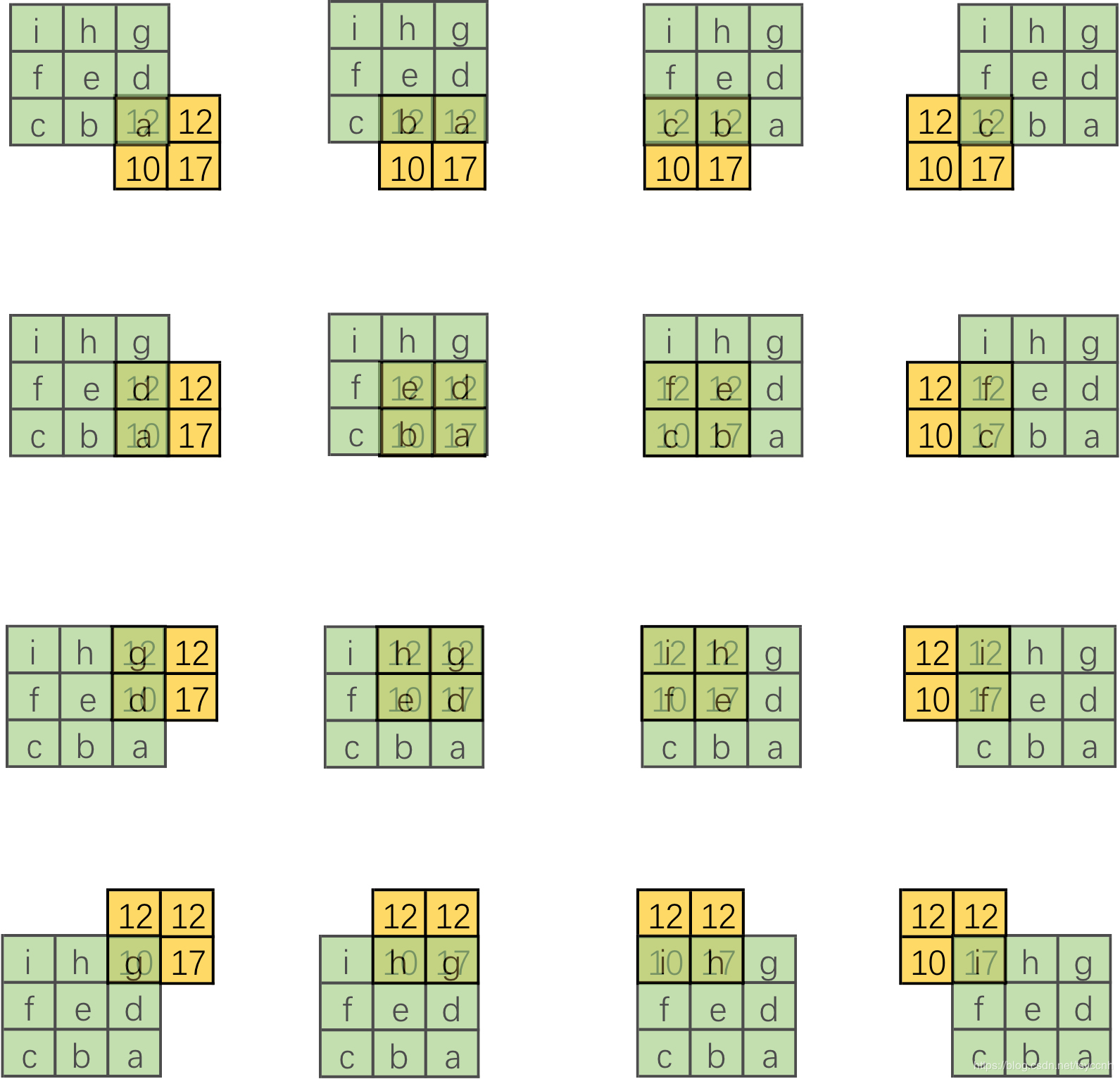
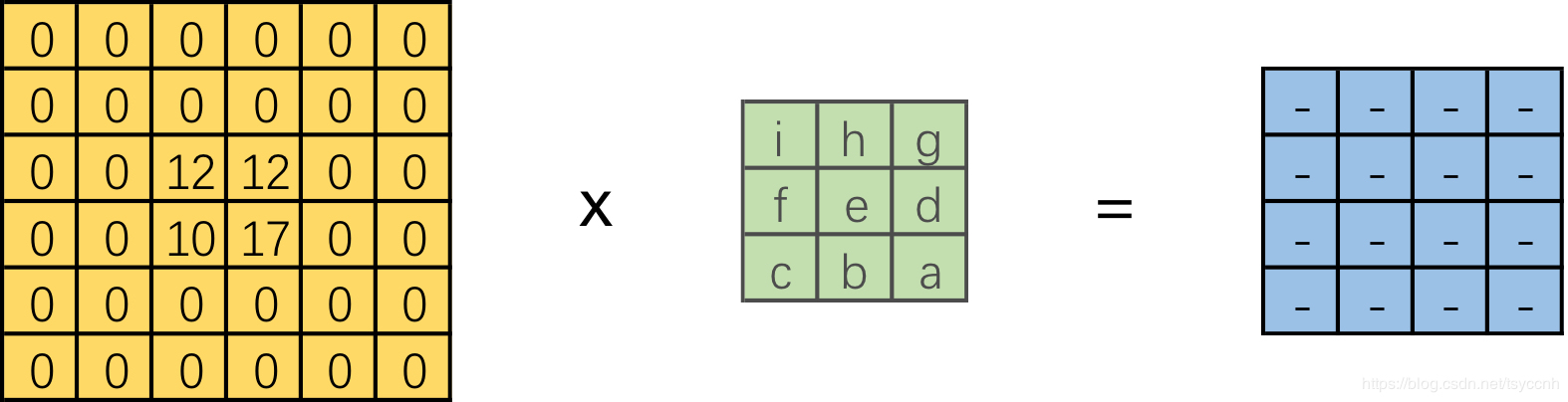
在pytorch中转置卷积函数如下,其中参数和传统卷积基本一致
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
output_padding=0,
groups=1,
bias=True,
dilation=1,
padding_mode='zeros'
)
尺寸计算方法
简化版
\(out = (in\_{channel}-1) * stride + kernel\_size\)
完整版
\(out = (in\_{channel}-1) * stride -2*padding_size + dilation * (kernel\_size-1)+output\_padding +1\)
推荐一个细致讲解转置卷积的帖子:https://blog.csdn.net/tsyccnh/article/details/87357447
池化函数
nn.MaxPool2d
nn.MaxPool2d(
kernel_size,
stride=None,
padding=0,
dilation=1,
return_indices=False,
ceil_mode=False
)
其中,
return_indices: 可以返回池化的位置,主要用于自编码其中池化上采样(最大池化)
ceil_mode: 表示尺寸向上取整,主要用于kernel_size无法被长宽整除的时候。
其他参数和上述卷积参数含义一样。
主要功能是进行特征缩减,同时保留最大信息,2*2的MaxPoold执行操作如下图所示(来源于cs231n )
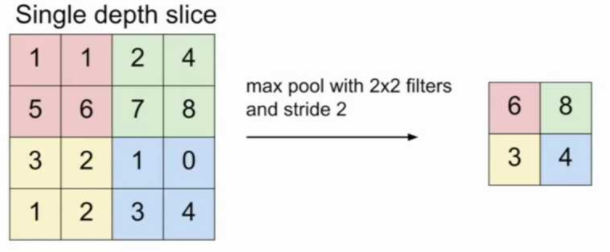
pytorch中的pooling函数,默认kernel size和stride是一样的
pool2d = nn.MaxPool2d(3) # 这里省略stride设置 pool2d(X)
# 也可以手动设置更详细的:
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
nn.AvgPool2d
nn.AvgPool2d(
kernel_size,
stride=None,
padding=0,
ceil_mode=False,
count_include_pad=True,
divisor_override=None
)
其中:
count_include_pad:求平均值的时候,是否考虑将padding加入计算,divisor_override:可以设置分母,例如2*2均值就是除以4,但是我们可以设置其他值
其他参数和上述nn.MaxPool2d含义一样
主要操作和nn.MaxPool2d一样,不同的是,这里做的是求平均操作。
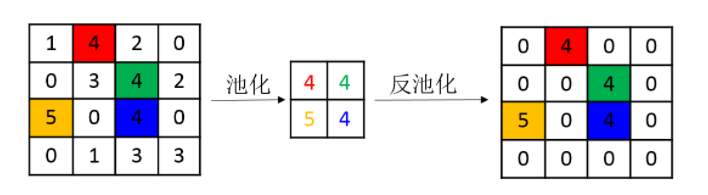
nn.MaxUnpool2d
反池化操作,就是池化的反向操作,具体如下图所示(图片来源网络):
nn.MaxUnpool2d(
kernel_size,
stride=None,
padding=0
)
一个例子,首先使用MaxPool2d采样,然后保留采样位置,最后使用采样位置indices来进行反池化操作。
img = torch.randn((28,28))
max_pool_l = nn.MaxPool2d((2,2),stride=(2,2),return_indices=True)
img_pool,indices = max_pool_l(img)
maxUpPool_l = nn.MaxUnpooled((2,2),stride=(2,2))
img_Up = maxUpPool_l(input_i , indices)
Pytorch系列:(五)CNN的更多相关文章
- CSS 魔法系列:纯 CSS 绘制各种图形《系列五》
我们的网页因为 CSS 而呈现千变万化的风格.这一看似简单的样式语言在使用中非常灵活,只要你发挥创意就能实现很多比人想象不到的效果.特别是随着 CSS3 的广泛使用,更多新奇的 CSS 作品涌现出来. ...
- Netty4.x中文教程系列(五)编解码器Codec
Netty4.x中文教程系列(五)编解码器Codec 上一篇文章详细解释了ChannelHandler的相关构架设计,版本和设计逻辑变更等等. 这篇文章主要在于讲述Handler里面的Codec,也就 ...
- WCF编程系列(五)元数据
WCF编程系列(五)元数据 示例一中我们使用了scvutil命令自动生成了服务的客户端代理类: svcutil http://localhost:8000/?wsdl /o:FirstServic ...
- JVM系列五:JVM监测&工具
JVM系列五:JVM监测&工具[整理中] http://www.cnblogs.com/redcreen/archive/2011/05/09/2040977.html 前几篇篇文章介绍了介 ...
- SQL Server 2008空间数据应用系列五:数据表中使用空间数据类型
原文:SQL Server 2008空间数据应用系列五:数据表中使用空间数据类型 友情提示,您阅读本篇博文的先决条件如下: 1.本文示例基于Microsoft SQL Server 2008 R2调测 ...
- VSTO之旅系列(五):创建Outlook解决方案
原文:VSTO之旅系列(五):创建Outlook解决方案 本专题概要 引言 Outlook对象模型 自定义Outlook窗体 小结 一.引言 在上一个专题中,为大家简单介绍了下如何创建Word解决方案 ...
- 系列五AnkhSvn
原文:系列五AnkhSvn AnkhSvn介绍 AnkhSVN是一款在VS中管理Subversion的插件,您可以在VS中轻松的提交.更新.添加文件,而不用在命令行或资源管理器中提交.而且该插件属于开 ...
- java多线程系列(五)---synchronized ReentrantLock volatile Atomic 原理分析
java多线程系列(五)---synchronized ReentrantLock volatile Atomic 原理分析 前言:如有不正确的地方,还望指正. 目录 认识cpu.核心与线程 java ...
- java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别
java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别 目录 java基础解析系列(一)---String.StringBuffer.St ...
- Pytorch系列教程
介绍 不久前Pytorch发布了1.0版本,官网的doc页也更新了.这里说下官网的教程很实用,边学pytorch搭网络边学NLP-图像等领域的先进技术. 官网的教程都是英文的,本人就用这个系列博客做个 ...
随机推荐
- (2)MySQL进阶篇SQL优化(show status、explain分析)
1.概述 在应用系统开发过程中,由于初期数据量小,开发人员写SQL语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多SQL语句开始逐渐显露出性能问题,对生产环境的影响也 ...
- unbutu系统扩展磁盘大小
建议下载一个可视化工具,这样的话就更不容易出错 sudo apt install gparted 在终端中运行这条命令就可安装可视化工具 fdisk -l 在终端中输入这条命令来查看自己系统所挂载的磁 ...
- 记录Java注解在JavaWeb中的一个应用实例
概述 在学习注解的时候,学了个懵懵懂懂.学了JavaWeb之后,在做Demo项目的过程中,借助注解和反射实现了对页面按钮的权限控制,对于注解才算咂摸出了点味儿来. 需求 以"角色列表&quo ...
- 递归实现1-n的全排列(JAVA语言)
思路: For example: 123的全排列= 1在最前面 23的全排列 + 2在最前面 13的全排列 + 3最前面 12的全排列 所以只需交换和最前面元素的位置,生成剩余元素的全排列即可. im ...
- P1426 小鱼会有危险吗(JAVA语言)
题目描述 有一次,小鱼要从A处沿直线往右边游,小鱼第一秒可以游7米,从第二秒开始每秒游的距离只有前一秒的98%.有个极其邪恶的猎人在距离A处右边s米的地方,安装了一个隐蔽的探测器,探测器左右x米之内是 ...
- .net core 和 WPF 开发升讯威在线客服系统【私有化部署免费版】发布
希望 .net 和 WPF 技术时至今日,还能有一些存在感. 这个项目源于2015年前后,当时开发的初版,我使用了 ASP.NET MVC 做为后端,数据库使用原生 ADO.NET 进行操作.WPF ...
- IT培训有哪些坑(一)?
IT行业资薪很高,每年都有很多同学冲着高薪去,去各个培训机构学习,期望将来能找个高薪的工作,有个好的出路.我们先不说你选多好,多靠谱的机构,我先来告诉大家有哪些不靠谱,不能选,选了就入坑了的. IT培 ...
- Istio 生产环境用户流量接入方案
总结Istio 生产环境用户流量接入方案 方案1 Client -> istioGateway域名(微服务) -> VritualService匹配路由并绑定网关 -> Destin ...
- 【2020.8.23NOIP模拟赛】失落
[ 2020.8.23 N O I P 模 拟 赛 ] 失 落 [2020.8.23NOIP模拟赛]失落 [2020.8.23NOIP模拟赛]失落 题目描述 出题人心情很失落,于是他直接告诉你让你求出 ...
- [单调栈]Imbalanced Array
I m b a l a n c e d A r r a y Imbalanced Array ImbalancedArray 题目描述 You are given an array a a a con ...