【论文笔记】SamWalker: Social Recommendation with Informative Sampling Strategy
SamWalker: Social Recommendation with Informative Sampling Strategy
Authors: Jiawei Chen, Can Wang, Sheng Zhou, Qihao Shi, Yan Feng, Chun Chen
WWW'19 浙江大学
0. 总结
这篇文章提出了一个利用社交网络信息的推荐模型SamWalker。SamWalker可以建模用户和物品之间的曝光概率,并提出用社交网络随机游走进行负采样的方式来替代曝光概率的计算,降低模型计算复杂度。此外,模型还可以利用等效的卷积神经网络来优化社交连接强度。在三个数据集上,SamWalker都取得了超过所有baseline的性能,并结合Ablation study等实验证明了模型的性能。
1. 研究目标
利用社交信息建模曝光概率,提高推荐准确率和模型稳定性。
2. 问题背景
在隐式反馈数据中,一个用户没有与一个物品发生交互,可能是因为用户对物品没有兴趣,也可能是因为用户没有看到这个物品。因此,将所有未观测到的交互都作为负样本进行采样,会损害推荐系统的性能,这也被称为推荐系统中的exposure bias。现有的方法通过对未观测数据进行降权来缓解exposure bias,但这些方法存在两个问题:(1)权重通常是人工赋予的,缺乏灵活性和准确性。(2)数据中包含的信息很少,难以准确预测曝光概率。
3. 方法
为了解决上述问题,本文提出了SamWalker,利用社交信息来推断曝光概率,并指导采样过程。
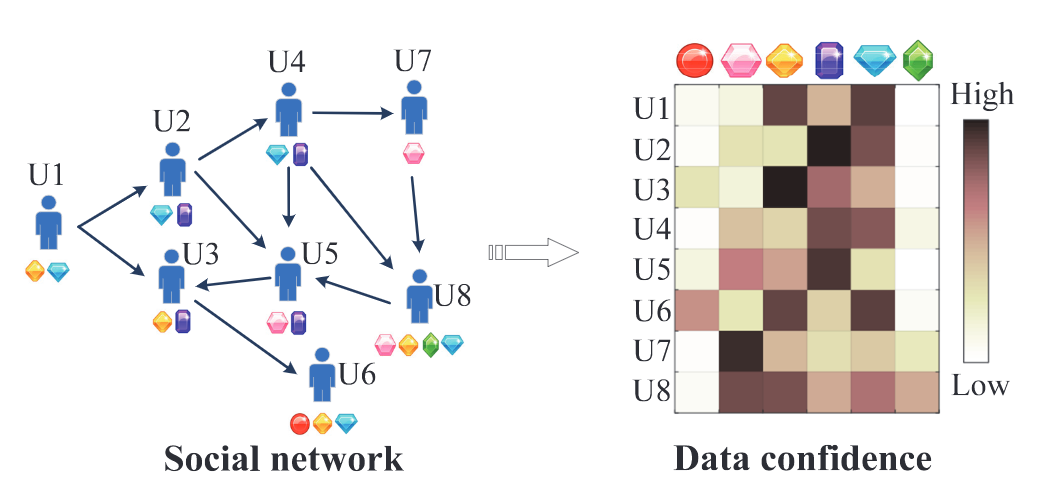
用户会从朋友/关注的人那里获得有关物品的信息(例如朋友之间的推荐),因此,用户的社交信息会影响物品对用户的曝光概率。一个物品在用户的社交网络中越流行,用户看到这个物品的概率就越高。
由于社交网络很复杂,基于社交网络计算所有user-item对的曝光概率复杂度很高。本文采用在社交网络上随机游走的方式指导负采样。
3.1 问题定义
假设我们有用户集U,包含n个用户;物品集I,包含m个物品;隐式反馈交互记录X,矩阵维度为\(n*m\),其中每个元素\(x_{ij}\)表示用户i与物品j是否发生了交互(1或0);社交信息矩阵T,矩阵维度为\(n*n\),其中每行元素\(\tau_i\)表示用户i的社交链接,\(\tau_{ij}\)表示用户i与用户j是否有社交联系。
3.2 EXMF分析
EXMF是2016年提出的建模曝光概率的推荐模型,具体请参考博文【论文笔记】Modeling User Exposure in Recommendation。
(3.3变分分析这部分我还没看明白,等后面懂了再来写详细过程orz)
EXMF的缺点
- EXMF建模曝光概率的参数过多(m*n),工业场景下不可实现;且大部分曝光概率都很小,对模型优化贡献很小。
- EXMF认为曝光概率与用户的特征无关,但实际上用户的社交网络对曝光概率也有着极大的影响。
3.3 SamWalker 概述
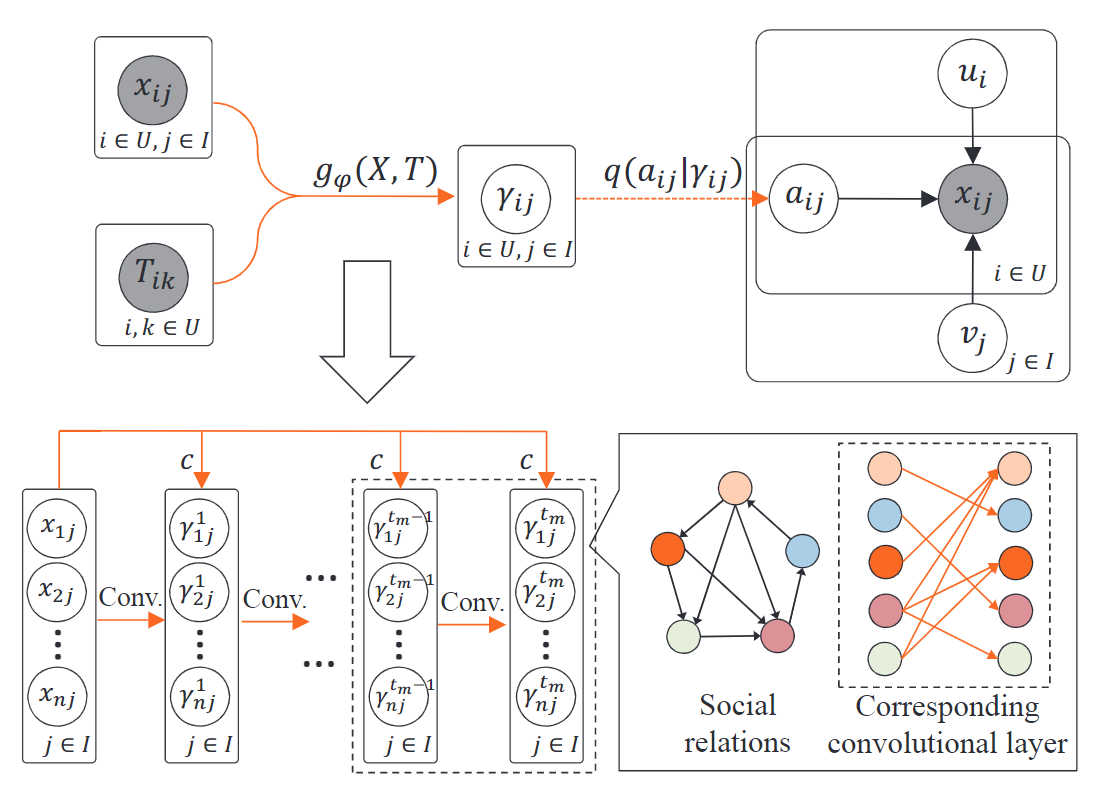
为了降低参数量,使用一个传播模型来建模社交信息对曝光概率的影响,从第t步到第t+1步的曝光概率传播方式如下:
\gamma_{i j}^{(t+1)}=(1-c) x_{i j}+\sum_{k \in \mathcal{T}_{i}} c \varphi_{i k} \gamma_{k j}^{(t)}
\end{align}
\]
其中i表示用户i,j表示物品j,\(\gamma_{i j}^{(t+1)}\)表示第t+1步的曝光概率,\(x_{ij}\)表示训练集的标签(0或1,表示是否交互),\(\varphi_{i k}\)表示用户i和用户k之间的连接强度,满足\(\sum_{k\in\tau_i}\varphi_{ik} = 1\),c是调节社交信息权重的参数。
总的来说,曝光概率收敛公式为:
Y=g_{\varphi}(X, T) \equiv \lim _{t \rightarrow \infty} Y^{(t)}=(I-c \Phi)^{-1}(1-c) X
\end{align}
\]
\(Y^{(t)}_{ij}\) = \(\gamma_{i j}^{(t)}\),是第t步的曝光概率矩阵;\(\phi_{ij} = \varphi_{ij}\),是社交连接强度矩阵 。
3.4 基于随机游走的个性化负采样方法
作者证明了当采样概率\(p_{ij}\)正比于曝光概率\(\gamma_{i j}^{(t)}\)时,采样方差更小,且梯度估计更快(就是用负采样阶段的设计来替代loss函数中的曝光概率计算)。
那怎样能够做到正比于曝光概率\(\gamma_{i j}^{(t)}\)的负采样呢?
一个直观的想法就是计算出所有的曝光概率,再进行负采样,但这样计算复杂度太高。
曝光概率的计算迭代公式可以展开为:
Y &=(I-c \Phi)^{-1}(1-c) X \\
&=\left(1+c \Phi+(c \Phi)^{2}+(c \Phi)^{3} \ldots\right)(1-c) X
\end{aligned}
\]
基于上式,对于user i,我们给出如下随机游走规则进行负采样,使得负采样概率正比于推导出的曝光概率:
在第t步随机游走时,假设我们游走到了user u。
我们有两种选择:
- (1)这一步不进行游走,随机选择u的一定比例(\(\beta\))的邻居物品i作为负样本。概率为c。
- (2)根据社交连接强度\(\varphi_{uv}\)进行随机游走,游走至用户节点v,并随机选择v的一定比例(\(\beta\))的邻居物品i作为负样本。概率为(1-c)。
直至游走\(\alpha\)步,随机游走结束,负采样结束。
在每次随机游走过程中,如果游走到距离很远的user,社交信息就变得很少了。具体来说,如果当前节点与初始节点i的距离\(t>t_m\),则直接在所有user中随机选择,进行游走。
3.5 社交连接强度\(\varphi\)的优化
由于不同的社交连接对用户的影响是不同的,例如由于朋友之间联系的密切程度不同,朋友之间的推荐频率和推荐强度也不同。而曝光概率\(\gamma_{i j}^{(t)}\)的推导是基于社交连接强度矩阵的,而这个矩阵需要我们进行优化。
为了优化连接强度,设计一个卷积神经网络来计算曝光概率,网络中的权重就是user之间的连接强度。这样可以在优化推荐loss的时候回传梯度,达到优化连接强度的目的。
3.6 方法讨论
由于用户不仅会受到直接好友的影响,还会受到大众舆论的影响。因此,可以在模型中加入一个节点,代表所有用户对一个用户行为的影响。随机游走的设计也需要做出响应改变,即增加一个直接在所有用户中随机选择节点的概率。
4. 实验
4.1 数据集
实验采用了Epinions、Ciao和LastFM三个数据集。其中Epinions和Ciao是从产品评论网站抓取的信息,含有用户之间的“信任”信息;LastFM是从音乐网站爬取的,含有用户之间的好友数据。
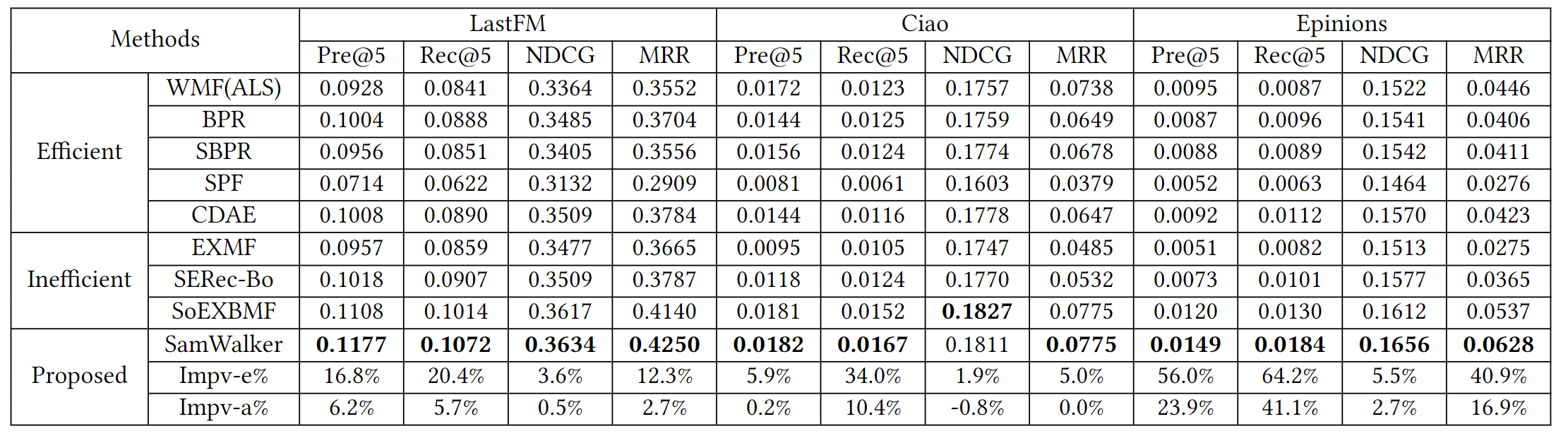
4.2 推荐性能
实验结果表明,在三个数据集上,SamWalker都优于所有baseline。
4.3 采样器性能
实验结果表明,SamWalker设计的社交网络随机游走采样器可以降低梯度的方差,获得更稳定的模型。

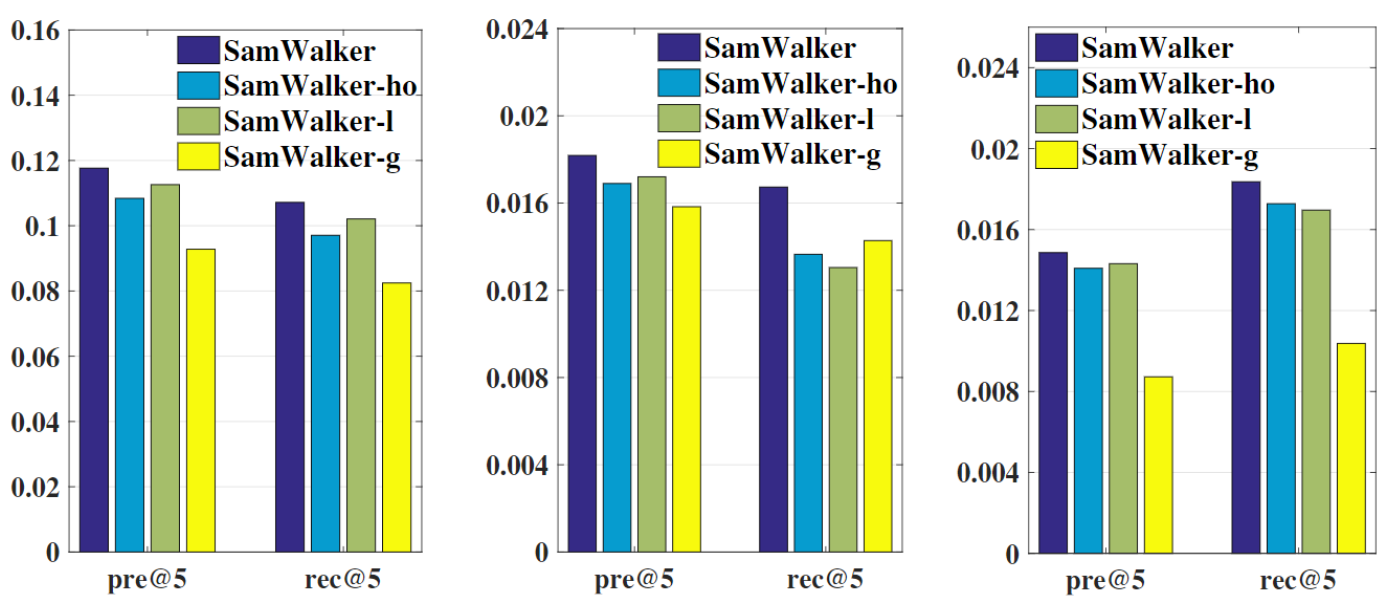
4.4 Ablation study
实验表明,学习个性化的连接强度、引入社交信息和全局社交信息都有助于提升模型性能。图中SamWalker-ho表示所有社交连接强度都是一样的;SamWalker-l表示只考虑社交信息,不考虑全局user;SamWalker-g表示只考虑全局user,不考虑社交信息。
4.5 \(t_m\)对模型性能的影响
\(t_m\)表示随机游走的最大长度,当随机游走超过此长度时,会在所有用户中随机选择节点进行游走。
随着\(t_m\)的增加,性能呈现先上升后下降的特点。在\(t_m\)比较小的时候,增加\(t_m\)可以提供更广的社交信息。但随着\(t_m\)的进一步增大,带来的有用社交信息开始减少,噪声开始增多,模型性能会开始出现下降。实际上,在社交网络中,从一个节点出发,6跳就可以基本覆盖所有人,因此过长的随机游走效果不好。

5. 不懂的问题
变分法
6. 进一步阅读
[5] Rocío Cañamares and Pablo Castells. 2018. Should i follow the crowd?: A probabilistic analysis of the effectiveness of popularity in recommender systems. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. ACM, 415–424
[6]Pablo Castells, Neil J Hurley, and Saul Vargas. 2015. Novelty and diversity in recommender systems. In Recommender Systems Handbook. Springer, 881–918.
[12]Jingtao Ding, Fuli Feng, Xiangnan He, Guanghui Yu, Yong Li, and Depeng Jin. 2018. An improved sampler for bayesian personalized ranking by leveraging view data. In Companion of the The Web Conference 2018 on The Web Conference 2018. International World Wide Web Conferences Steering Committee, 13–14.
[17]Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 173–182.
[18]Xiangnan He, Hanwang Zhang, Min-Yen Kan, and Tat-Seng Chua. 2016. Fast matrix factorization for online recommendation with implicit feedback. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 549–558.
[26]Chen Jiawei, Feng Yan, Ester Martin, Zhou Sheng, Chen Chun, and Can Wang. 2018. Modeling Users’ Exposure with Social Knowledge Influence and Consumption Influence for Recommendation. In Proceedings of the 27th ACM International on Conference on Information and Knowledge Management. ACM, 953–962
【论文笔记】SamWalker: Social Recommendation with Informative Sampling Strategy的更多相关文章
- 【论文笔记】Social Role-Aware Emotion Contagion in Image Social Networks
Social Role-Aware Emotion Contagion in Image Social Networks 社会角色意识情绪在形象社交网络中的传染 1.摘要: 心理学理论认为,情绪代表了 ...
- 【论文笔记】用反事实推断方法缓解标题党内容对推荐系统的影响 Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue
Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue Authors: 王文杰,冯福利 ...
- A Neural Influence Diffusion Model for Social Recommendation 笔记
目录 一.摘言 二.杂记 三.问题定义和一些准备工作 四.模型真思想 五.实验部分 六.参考文献 一.摘言 之前协同过滤利用user-item交互历史很好的表示了user和item.但是由于用户行为的 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- Video Frame Synthesis using Deep Voxel Flow 论文笔记
Video Frame Synthesis using Deep Voxel Flow 论文笔记 arXiv 摘要:本文解决了模拟新的视频帧的问题,要么是现有视频帧之间的插值,要么是紧跟着他们的探索. ...
- 论文笔记:Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go with deep neural networks and tree search Nature 2015 这是本人论文笔记系列第二篇 Nature ...
- Self-paced Clustering Ensemble自步聚类集成论文笔记
Self-paced Clustering Ensemble自步聚类集成论文笔记 2019-06-23 22:20:40 zpainter 阅读数 174 收藏 更多 分类专栏: 论文 版权声明 ...
- 深度学习论文笔记:Fast R-CNN
知识点 mAP:detection quality. Abstract 本文提出一种基于快速区域的卷积网络方法(快速R-CNN)用于对象检测. 快速R-CNN采用多项创新技术来提高训练和测试速度,同时 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
随机推荐
- python实现超大图像的二值化方法
一,分块处理超大图像的二值化问题 (1) 全局阈值处理 (2) 局部阈值 二,空白区域过滤 三,先缩放进行二值化,然后还原大小 np.mean() 返回数组元素的平均值 np.std() 返回数 ...
- [loj2494]寻宝游戏
将$n+1$个数字(还有0)标号为$[0,n]$,那么定义$a_{i,j}$表示第j个数上第i位上的值,如果第$i-1$个数与第$i$个数之间的运算符为与,那么令$b_{i}=1$,否则$b_{i}= ...
- [luogu5423]Valleys
先考虑不要求有洞,那么可以将所有权值排序,然后不断插入,那么一个连通块就是一个答案,加上连通块大小即可考虑并查集如何判断是否有洞,可以发现对于任意一个无洞的直角多边形,都有$90度内角-90度外角=4 ...
- [ Skill ] 图形化组件在注册 User Trigger 时需要注意的事情
https://www.cnblogs.com/yeungchie/ 使用 deRegUserTriggers 可以用来配置:当打开一个新窗口时,自动集成自定义的菜单.工具栏等等. 使用格式如下: d ...
- APIO2020 打铁记
Day (-3) - 2020.8.11 马上要 APIO 了,不管三七二十一先刷一套历年的 APIO 再说. 花了 3h 写了 APIO2019,爆零150左右,然后查看了一下去年的分数线,Cu 1 ...
- 【2020五校联考NOIP #7】伟大的卫国战争
题面传送门 题意: 数轴上有 \(n\) 个点,现在要在它们之间连 \(m\) 条边,第 \(i\) 条边连接 \(a_i,b_i\) 两个点. 现在你要钦定每条边连在数轴的上方还是下方,使得任意两条 ...
- 【2020五校联考NOIP #6】最佳观影
题意: 给出一个 \(k \times k\) 的网格和 \(n\) 次操作.其中 \(k\) 为奇数. 每次操作给出一个数 \(m\).每次你要找出一个三元组 \((x,l,r)\) 使得: \(r ...
- Codeforces 985G - Team Players(三元环)
Codeforces 题目传送门 & 洛谷题目传送门 真·ycx 做啥题我就做啥题 考虑枚举 \(j\),我们预处理出 \(c1_i\) 表示与 \(i\) 相连的编号 \(<i\) 的 ...
- Hosts文件详解
一.缘由 关于我们工作室项目配置过程中,有一个重要但却容易被忽略的环节 - hosts文件的修改. 之前配置hosts文件的时候,只知道那么做就可以了,但并不知道其中的原因,由于开发任务的急迫,也就未 ...
- Oracle-trunc函数、round 函数、ceil函数和floor函数---处理数字函数使用
0.round函数 按照指定小数位数进行四舍五入运算. SELECT ROUND( number, [ decimal_places ] ) FROM DUAL #number : 待处理数值 de ...