list概述
1、list概述
list 是一种双向链表。list 的设计更加复杂一点,好处是每次插入或删除一个元素,就配置或释放一个元素,list 对于空间的运用有绝对的精准,一点也不浪费。而且对于任何位置的元素插入或删除,list 永远是常数空间。注意:list 源码里其实分了两个部分,一个部分是 list 结构,另一部分是 list 节点的结构。也就是说指针变量和数据变量分开定义,目的是是为了给迭代器做铺垫,因为迭代器遍历的时候不需要数据成员的,只需要前后指针就可以遍历该 list。list 的节点结构如下图所示:
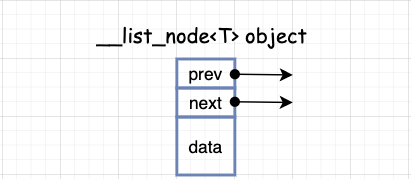
2、list 数据结构-节点
__list_node 用来实现节点,数据结构中就储存前后指针和属性。
template <class T> struct __list_node {
// 前后指针
typedef void* void_pointer;
void_pointer next;
void_pointer prev;
// 属性
T data;
};
基本结构如下图所示:
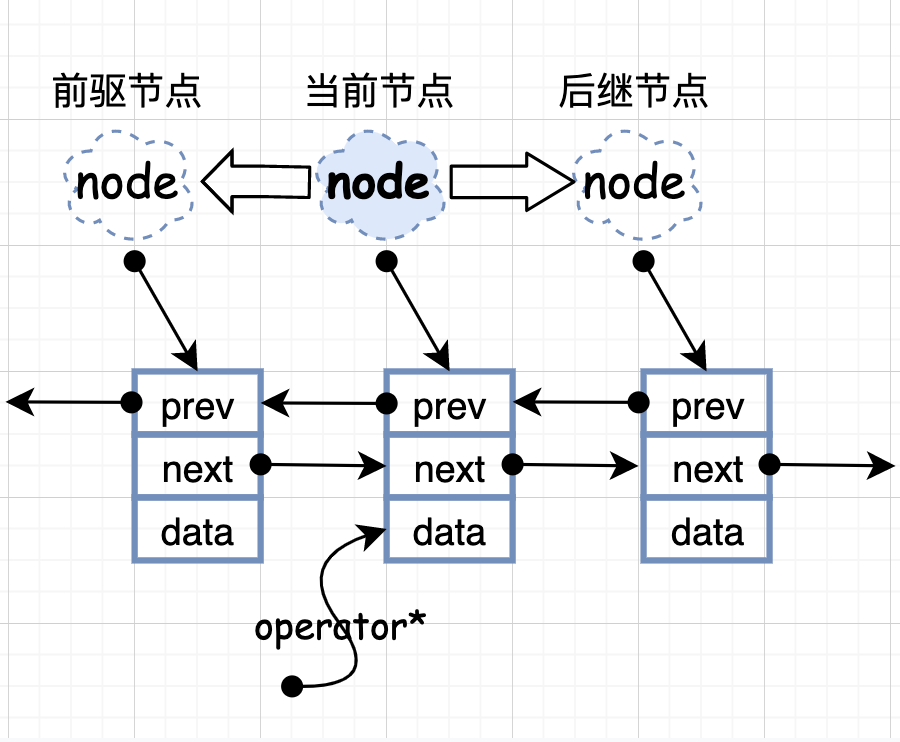
基本类型
template<class T, class Ref, class Ptr> struct __list_iterator {
typedef __list_iterator<T, T&, T*> iterator; // 迭代器
typedef __list_iterator<T, const T&, const T*> const_iterator;
typedef __list_iterator<T, Ref, Ptr> self;
// 迭代器是bidirectional_iterator_tag类型
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
...
};
构造函数
template<class T, class Ref, class Ptr> struct __list_iterator {
...
// 定义节点指针
typedef __list_node<T>* link_type;
link_type node;
// 构造函数
__list_iterator(link_type x) : node(x) {}
__list_iterator() {}
__list_iterator(const iterator& x) : node(x.node) {}
...
};
重载
template<class T, class Ref, class Ptr> struct __list_iterator {
...
// 重载
bool operator==(const self& x) const { return node == x.node; }
bool operator!=(const self& x) const { return node != x.node; }
...
// ++和--是直接操作的指针指向next还是prev, 因为list是一个双向链表
self& operator++() {
node = (link_type)((*node).next);
return *this;
}
self operator++(int) {
self tmp = *this;
++*this;
return tmp;
}
self& operator--() {
node = (link_type)((*node).prev);
return *this;
}
self operator--(int) {
self tmp = *this;
--*this;
return tmp;
}
};
3、list 结构
list 自己定义了嵌套类型满足 traits 编程, list 迭代器是 bidirectional_iterator_tag 类型,并不是一个普通指针。

list 在定义 node 节点时, 定义的不是一个指针:
template <class T, class Alloc = alloc>
class list {
protected:
typedef void* void_pointer;
typedef __list_node<T> list_node; // 节点 就是前面分析过的
typedef simple_alloc<list_node, Alloc> list_node_allocator; // 空间配置器
public:
// 定义嵌套类型
typedef T value_type;
typedef value_type* pointer;
typedef const value_type* const_pointer;
typedef value_type& reference;
typedef const value_type& const_reference;
typedef list_node* link_type;
typedef size_t size_type;
typedef ptrdiff_t difference_type; protected:
// 定义一个节点, 这里节点并不是一个指针.
link_type node; public:
// 定义迭代器
typedef __list_iterator<T, T&, T*> iterator;
typedef __list_iterator<T, const T&, const T*> const_iterator;
...
};
4、list 构造和析构函数实现
每个构造函数都会创造一个空的 node 节点,为了保证我们在执行任何操作都不会修改迭代器。list 默认使用 alloc 作为空间配置器,并根据这个另外定义了一个 list_node_allocator,目的是更加方便以节点大小来配置单元。
template <class T, class Alloc = alloc>
class list {
protected:
typedef void* void_pointer;
typedef __list_node<T> list_node; // 节点
typedef simple_alloc<list_node, Alloc> list_node_allocator; // 空间配置器
其中,list_node_allocator(n) 表示配置 n 个节点空间。以下四个函数,分别用来配置,释放,构造,销毁一个节点。
class list {
protected:
// 配置一个节点并返回
link_type get_node() { return list_node_allocator::allocate(); }
// 释放一个节点
void put_node(link_type p) { list_node_allocator::deallocate(p); }
// 产生(配置并构造)一个节点带有元素初始值
link_type create_node(const T& x) {
link_type p = get_node();
__STL_TRY {
construct(&p->data, x);
}
__STL_UNWIND(put_node(p));
return p;
}
//销毁(析构并释放)一个节点
void destroy_node(link_type p) {
destroy(&p->data);
put_node(p);
}
// 对节点初始化
void empty_initialize() {
node = get_node();
node->next = node;
node->prev = node;
}
};
5、基本属性获取
template <class T, class Alloc = alloc>
class list {
...
public:
iterator begin() { return (link_type)((*node).next); } // 返回指向头的指针
const_iterator begin() const { return (link_type)((*node).next); }
iterator end() { return node; } // 返回最后一个元素的后一个的地址
const_iterator end() const { return node; } // 这里是为旋转做准备, rbegin返回最后一个地址, rend返回第一个地址. 我们放在配接器里面分析
reverse_iterator rbegin() { return reverse_iterator(end()); }
const_reverse_iterator rbegin() const {
return const_reverse_iterator(end());
}
reverse_iterator rend() { return reverse_iterator(begin()); }
const_reverse_iterator rend() const {
return const_reverse_iterator(begin());
} // 判断是否为空链表, 这是判断只有一个空node来表示链表为空.
bool empty() const { return node->next == node; }
// 因为这个链表, 地址并不连续, 所以要自己迭代计算链表的长度.
size_type size() const {
size_type result = 0;
distance(begin(), end(), result);
return result;
}
size_type max_size() const { return size_type(-1); }
// 返回第一个元素的值
reference front() { return *begin(); }
const_reference front() const { return *begin(); }
// 返回最后一个元素的值
reference back() { return *(--end()); }
const_reference back() const { return *(--end()); } // 交换
void swap(list<T, Alloc>& x) { __STD::swap(node, x.node); }
...
};
template <class T, class Alloc>
inline void swap(list<T, Alloc>& x, list<T, Alloc>& y) {
x.swap(y);
}
6、list 的头插和尾插
因为 list 是一个循环的双链表, 所以 push 和 pop 就必须实现是在头插入,删除还是在尾插入和删除。在 list 中,push 操作都调用 insert 函数, pop 操作都调用 erase 函数。
template <class T, class Alloc = alloc>
class list {
...
// 直接在头部或尾部插入
void push_front(const T& x) { insert(begin(), x); }
void push_back(const T& x) { insert(end(), x); }
// 直接在头部或尾部删除
void pop_front() { erase(begin()); }
void pop_back() {
iterator tmp = end();
erase(--tmp);
}
...
};
上面的两个插入函数内部调用的 insert 函数。
class list {
...
public:
// 最基本的insert操作, 之插入一个元素
iterator insert(iterator position, const T& x) {
// 将元素插入指定位置的前一个地址
link_type tmp = create_node(x);
tmp->next = position.node;
tmp->prev = position.node->prev;
(link_type(position.node->prev))->next = tmp;
position.node->prev = tmp;
return tmp;
}
注意:
- 节点实际是以 node 空节点开始的。
- 插入操作是将元素插入到指定位置的前一个地址进行插入的。
7、删除操作
删除元素的操作大都是由 erase 函数来实现的,其他的所有函数都是直接或间接调用 erase。
list 是链表,所以链表怎么实现删除元素, list 就在怎么操作:很简单,先保留前驱和后继节点, 再调整指针位置即可。
由于它是双向环状链表,只要把边界条件处理好,那么在头部或者尾部插入元素操作几乎是一样的,同样的道理,在头部或者尾部删除元素也是一样的。
template <class T, class Alloc = alloc>
class list {
...
iterator erase(iterator first, iterator last);
void clear();
// 参数是一个迭代器 修改该元素的前后指针指向再单独释放节点就行了
iterator erase(iterator position) {
link_type next_node = link_type(position.node->next);
link_type prev_node = link_type(position.node->prev);
prev_node->next = next_node;
next_node->prev = prev_node;
destroy_node(position.node);
return iterator(next_node);
}
...
};
...
}
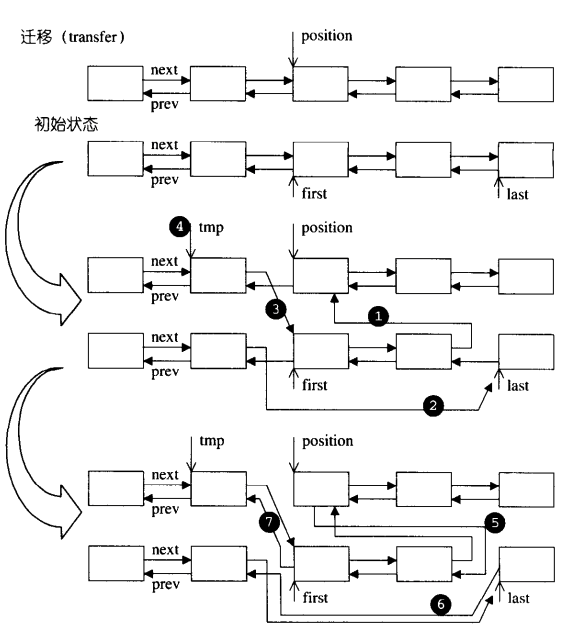
list 内部提供一种所谓的迁移操作(transfer):将某连续范围的元素迁移到某个特定位置之前,技术上实现其实不难,就是节点之间的指针移动,只要明白了这个函数的原理,后面的 splice,sort,merge 函数也就一一知晓了,我们来看一下 transfer 的源码:
template <class T, class Alloc = alloc>
class list {
...
protected:
void transfer(iterator position, iterator first, iterator last) {
if (position != last) {
(*(link_type((*last.node).prev))).next = position.node;
(*(link_type((*first.node).prev))).next = last.node;
(*(link_type((*position.node).prev))).next = first.node;
link_type tmp = link_type((*position.node).prev);
(*position.node).prev = (*last.node).prev;
(*last.node).prev = (*first.node).prev;
(*first.node).prev = tmp;
}
}
...
};
上面代码的七行分别对应下图的七个步骤:
splice函数: 将两个链表进行合并:内部就是调用的 transfer 函数。
merge 函数: 将传入的 list 链表 x 与原链表按从小到大合并到原链表中(前提是两个链表都是已经从小到大排序了). 这里 merge 的核心就是 transfer 函数。
reverse 函数: 实现将链表翻转的功能:主要是 list 的迭代器基本不会改变的特点, 将每一个元素一个个插入到 begin 之前。
sort 函数: list 这个容器居然还自己实现一个排序,看一眼源码就发现其实内部调用的 merge 函数,用了一个数组链表用来存储 2^i 个元素, 当上一个元素存储满了之后继续往下一个链表存储, 最后将所有的链表进行 merge归并(合并), 从而实现了链表的排序。
赋值操作: 需要考虑两个链表的实际大小不一样时的操作:如果原链表大 : 复制完后要删除掉原链表多余的元素;如果原链表小 : 复制完后要还要将x链表的剩余元素以插入的方式插入到原链表中。
resize 操作: 重新修改 list 的大小,传入一个 new_size,如果链表旧长度大于 new_size 的大小, 那就删除后面多余的节点。
clear 操作: 清除所有节点:遍历每一个节点,销毁(析构并释放)一个节点。
remove 操作: 清除指定值的元素:遍历每一个节点,找到就移除。
unique 操作: 清除数值相同的连续元素,注意只有“连续而相同的元素”,才会被移除剩一个:遍历每一个节点,如果在此区间段有相同的元素就移除之。
8、list 总结
list 是一种双向链表。每个结点都包含一个数据域、一个前驱指针 prev 和一个后驱指针 next。
由于其链表特性,实现同样的操作,相对于 STL 中的通用算法, list 的成员函数通常有更高的效率,内部仅需做一些指针的操作,因此尽可能选择 list 成员函数。
优点
- 在内部方便进行插入删除操作。
- 可在两端进行push和pop操作。
缺点
- 不支持随机访问,即下标操作和.at()。
- 相对于 vector 占用内存多。
list概述的更多相关文章
- 【AR实验室】ARToolKit之概述篇
0x00 - 前言 我从去年就开始对AR(Augmented Reality)技术比较关注,但是去年AR行业一直处于偶尔发声的状态,丝毫没有其"异姓同名"的兄弟VR(Virtual ...
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Swift3.0服务端开发(一) 完整示例概述及Perfect环境搭建与配置(服务端+iOS端)
本篇博客算是一个开头,接下来会持续更新使用Swift3.0开发服务端相关的博客.当然,我们使用目前使用Swift开发服务端较为成熟的框架Perfect来实现.Perfect框架是加拿大一个创业团队开发 ...
- .Net 大型分布式基础服务架构横向演变概述
一. 业务背景 构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支持用户,订单,采购,物流,配送,财务等多个项目的协作,便于后续运营报表,分析,便于运维及监控. 二. 基础 ...
- [C#] 进阶 - LINQ 标准查询操作概述
LINQ 标准查询操作概述 序 “标准查询运算符”是组成语言集成查询 (LINQ) 模式的方法.大多数这些方法都在序列上运行,其中的序列是一个对象,其类型实现了IEnumerable<T> ...
- 【基于WinForm+Access局域网共享数据库的项目总结】之篇一:WinForm开发总体概述与技术实现
篇一:WinForm开发总体概述与技术实现 篇二:WinForm开发扇形图统计和Excel数据导出 篇三:Access远程连接数据库和窗体打包部署 [小记]:最近基于WinForm+Access数据库 ...
- Java消息队列--JMS概述
1.什么是JMS JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送 ...
- [AlwaysOn Availability Groups]健康模型 Part 1——概述
健康模型概述 在成功部署AG之后,跟踪和维护健康状况是很重要的. 1.AG健康模型概述 AG的健康模型是基于策略管理(Policy Based Management PBM)的.如果不熟悉这个特性,可 ...
- μCos-ii学习笔记1_概述
一.μCos-ii _概述 网上关于μCosii的文章多不胜数,本人学习的过程中也参考了很多人的理解和想法,看的是卢有亮老师的<嵌入式实时操作系统-μC/OS原理与实践>(第2版),同时也 ...
- Android快乐贪吃蛇游戏实战项目开发教程-01项目概述与目录
一.项目简介 贪吃蛇是一个很经典的游戏,也很适合用来学习.本教程将和大家一起做一个Android版的贪吃蛇游戏. 我已经将做好的案例上传到了应用宝,无病毒.无广告,大家可以放心下载下来把玩一下.应用宝 ...
随机推荐
- 【剑指Offer】删除链表中重复的结点 解题报告(Python)
[剑指Offer]删除链表中重复的结点 解题报告(Python) 标签(空格分隔): 剑指Offer 题目地址:https://www.nowcoder.com/ta/coding-interview ...
- 1036 - A Refining Company
1036 - A Refining Company PDF (English) Statistics Forum Time Limit: 3 second(s) Memory Limit: 32 ...
- Travelling(hdu3001)
Travelling Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- 1017 - Brush (III)
1017 - Brush (III) PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB Sami ...
- 15 - Vue3 UI Framework - 完工部署
项目官网也基本完成了,接下来我们再讲一下如何将项目官网部署到 GitHub Pages 上 返回阅读列表点击 这里 项目配置 常见的模式有三种,即 History 模式 Hash 模式 Memory ...
- 解决"The remote SSH server rejected X11 forwarding request"问题
今天突然想起来好久没有登录我的vps了,于是下载了xshell,填入地址登录后,看到提示"WARNING! The remote SSH server rejected X11 forwar ...
- Spring Boot + MyBatis + MySQL 实现读写分离
读写分离要做的事情就是对于一条SQL该选择哪个数据库去执行,至于谁来做选择数据库这件事儿,无非两个,要么中间件帮我们做,要么程序自己做. 读写分离有两种实现方式: 第一种是依靠中间件(比如:MyCat ...
- 「算法笔记」Link-Cut Tree
一.简介 Link-Cut Tree (简称 LCT) 是一种用来维护动态森林连通性的数据结构,适用于动态树问题. 类比树剖,树剖是通过静态地把一棵树剖成若干条链然后用一种支持区间操作的数据结构维护, ...
- 【优雅代码】01-lombok精选注解及原理
[优雅代码]01-lombok精选注解及原理 欢迎关注b站账号/公众号[六边形战士夏宁],一个要把各项指标拉满的男人.该文章已在github目录收录. 屏幕前的大帅比和大漂亮如果有帮助到你的话请顺手点 ...
- CSS3的nth-child() 选择器,表格奇偶行变色
nth-child() 应用背景 CSS3的nth-child() 选择器,我之前很少用,在做表格偶数行变色的时候,我通常在绑定的时候,做一个js判断,来加一个css,从而使表格偶数行和奇数行颜色不一 ...